Jako konzultant pracující s SQL Serverem jsem mnohokrát požádán, abych se podíval na server, který vypadá, že má problémy s výkonem. Při provádění třídění na serveru se ptám na určité otázky, jako například:jaké je vaše běžné využití CPU, jaké jsou vaše průměrné latence disku, jaké je vaše běžné využití paměti a tak dále. Odpověď obvykle zní:„nevíme“ nebo „tyto informace pravidelně nezachycujeme“. Neexistence aktuální výchozí hodnoty velmi ztěžuje zjištění, jak abnormální chování vypadá. Pokud nevíte, co je normální chování, jak s jistotou víte, zda jsou věci lepší nebo horší? Často používám výrazy „pokud to nesledujete, nemůžete to měřit“ a „pokud to neměříte, nemůžete to řídit“.
Z hlediska monitorování by organizace měly minimálně monitorovat neúspěšné úlohy, jako je zálohování, údržba indexů, DBCC CHECKDB a jakékoli další důležité úlohy. Je snadné pro ně nastavit upozornění na selhání; musíte však také zavést proces, který zajistí, že úlohy běží podle očekávání. Viděl jsem zakázky, které visí a nikdy nejsou dokončeny. Oznámení o selhání by nespustilo alarm, protože úloha nikdy neuspěje ani se nezdaří.
Od základní linie výkonu existuje několik klíčových metrik, které by měly být zachyceny. Vytvořil jsem proces, který používám s klienty a který pravidelně zachycuje klíčové metriky a ukládá tyto hodnoty do databáze uživatelů. Můj postup je jednoduchý:vyhrazená databáze s uloženými procedurami, které používají běžné skripty, které vkládají sady výsledků do tabulek. Mám úlohy SQL Agent pro spouštění uložených procedur v pravidelných intervalech a čistící skript pro čištění dat starších než X dní. Mezi metriky, které vždy zaznamenávám, patří:
Předpokládaná životnost stránky :PLE je pravděpodobně jedním z nejlepších způsobů, jak zjistit, zda je váš systém pod tlakem vnitřní paměti. Většina systémů má hodnoty PLE, které při běžné zátěži kolísají. Rád tyto hodnoty trenduji, abych věděl, jaké jsou minimální, průměrné a maximální hodnoty. Rád se snažím pochopit, co způsobilo pokles PLE v určitých denních dobách, abych zjistil, zda lze tyto procesy vyladit. Mnohokrát někdo provádí skenování tabulky a vyprázdnění fondu vyrovnávacích pamětí. Schopnost správně indexovat tyto dotazy může pomoci. Jen se ujistěte, že sledujete správné počítadlo PLE – viz zde .
Využití CPU :Mít základní čáru pro využití CPU vám dá vědět, jestli je váš systém náhle pod tlakem CPU. Když si uživatel stěžuje na problémy s výkonem, často zjistí, že CPU vypadá vysoko. Pokud se například CPU pohybuje kolem 80 %, mohli by to zjistit, ale pokud byl CPU také 80 % ve stejnou dobu v předchozích týdnech, kdy nebyly hlášeny žádné problémy, je pravděpodobnost, že problémem je CPU, velmi nízká. Trendy CPU neslouží pouze k zachycení, když CPU naroste a zůstane na trvale vysoké hodnotě. Mám mnoho příběhů o tom, jak jsem se dostal do konferenčního mostu se závažností one, protože došlo k problému s aplikací. Jako DBA jsem nosil klobouk „Default Blame Acceptor“. Když aplikační tým řekl, že je problém s databází, bylo na mně, abych dokázal, že tomu tak není, databázový server byl vinen, dokud se neprokázala jeho nevina. Živě si vzpomínám na incident, kdy si byl aplikační tým jistý, že databázový server má problémy, protože se uživatelé nemohli připojit. Na internetu se dočetli, že SQL Server by mohl trpět hladověním fondu vláken, pokud by odmítal připojení. Skočil jsem na server a začal jsem se dívat na zdroje a jaké procesy aktuálně běží. Během několika minut jsem hlásil, že se dotyčný server velmi nudí. Na základě našich základních metrik byl CPU obvykle 60 % a nečinný kolem 20 %, očekávaná životnost stránky byla znatelně vyšší než normálně a nedocházelo k žádnému zamykání nebo blokování, I/O vypadaly skvěle, žádné chyby v protokolech a počty relací byly asi 1/3 jejich normálního počtu. Pak jsem poznamenal:„Zdá se, že uživatelé ani nedosahují databázového serveru. To upoutalo pozornost lidí ze sítě a uvědomili si, že změna, kterou provedli v nástroji pro vyrovnávání zátěže, nefungovala správně a zjistili, že více než 50 % připojení je směrováno nesprávně a nedostává se k databázovému serveru. Kdybych nevěděl, jaká je základní linie, trvalo by nám mnohem déle, než bychom dosáhli řešení.
Vstup/výstup disku :Zachycení metrik disku je velmi důležité. DMV sys.dm_io_virtual_file_stats je kumulativní od posledního restartování serveru. Zachycení I/O latence v průběhu časového intervalu vám poskytne základní linii toho, co je během této doby normální. Spoléhání se na kumulativní hodnotu vám může poskytnout zkreslená data z činností po pracovní době nebo z dlouhých období, kdy byl systém nečinný. Pavel o tom diskutoval zde .
Velikost souborů databáze :Mít inventář databází, který zahrnuje velikost souboru, použitou velikost, volné místo a další, vám může pomoci předpovídat růst databáze. Často jsem požádán, abych předpověděl, kolik úložiště bude potřeba pro databázový server v nadcházejícím roce. Bez znalosti týdenního nebo měsíčního trendu růstu nemám žádný způsob, jak inteligentně přijít s číslem. Jakmile začnu sledovat tyto hodnoty, mohu to správně trendovat. Kromě trendování jsem také mohl najít, kdy došlo k neočekávanému nárůstu databáze. Když vidím neočekávaný růst a zkoumám, obvykle zjistím, že někdo buď zkopíroval tabulku, aby provedl nějaké testování (ano, ve výrobě!), nebo provedl nějaký jiný jednorázový proces. Sledování tohoto typu dat a schopnost reagovat, když se objeví anomálie, pomáhá ukázat, že jste proaktivní a dohlížíte na své systémy.
Statistika čekání :Sledování statistik čekání vám může pomoci začít zjišťovat příčinu určitých problémů s výkonem. Mnoho nových správců databází se znepokojuje, když poprvé začnou zkoumat statistiky čekání a neuvědomí si, že k čekání dochází vždy, a to je přesně způsob, jakým systém plánování SQL Server funguje. Existuje také spousta čekání, která lze považovat za benigní, nebo většinou neškodná. Paul Randal ve svém oblíbeném skriptu statistiky čekání vylučuje tato většinou neškodná čekání. Paul také vybudoval rozsáhlou knihovnu různých typů čekání a uchycení tříd s popisy a dalšími informacemi o odstraňování problémů s čekáním a blokováním.
Zdokumentoval jsem svůj proces shromažďování dat a kód najdete na mém blogu . V závislosti na situaci a typech problémů, které klient může mít, mohu také chtít zachytit další metriky. Glenn Berry napsal blog o procesu, který dal dohromady a který zachycuje průměrný počet úloh, průměrný počet spustitelných úloh, průměrný počet čekajících I/O, využití procesoru SQL Serveru a průměrnou očekávanou životnost stránky napříč všemi uzly NUMA. Rychlé vyhledávání na internetu zobrazí několik dalších procesů shromažďování dat, které lidé sdíleli, dokonce i tým SQL Server Tiger má proces, který využívá T-SQL a PowerShell.
Použití vlastní databáze a vytvoření vlastního balíčku pro shromažďování dat je platným řešením pro zachycení základní linie, ale většina z nás se nezabývá budováním plnohodnotných řešení monitorování SQL Server. Je toho mnohem víc, co by bylo užitečné zachytit, věci jako dlouhotrvající dotazy, hlavní dotazy a uložené procedury založené na paměti, I/O a CPU, uváznutí, fragmentace indexu, transakce za sekundu a mnoho dalšího. K tomu vždy doporučuji klientům zakoupit si monitorovací nástroj třetí strany. Tito dodavatelé se specializují na to, aby udrželi přehled o nejnovějších trendech a funkcích SQL Serveru, abyste se mohli soustředit na to, aby byl SQL Server co nejstabilnější a nejrychlejší.
Řešení jako SQL Sentry (pro SQL Server) a DB Sentry (pro Azure SQL Database) zachytí všechny tyto metriky a umožní vám snadno vytvářet různé základní linie. Můžete mít normální výchozí stav, konec měsíce, konec čtvrtletí a další. Poté můžete použít základní linii a vizuálně vidět, jak se věci liší. Ještě důležitější je, že můžete nakonfigurovat libovolný počet upozornění pro různé podmínky a být upozorněni, když metriky překročí vaše prahové hodnoty.
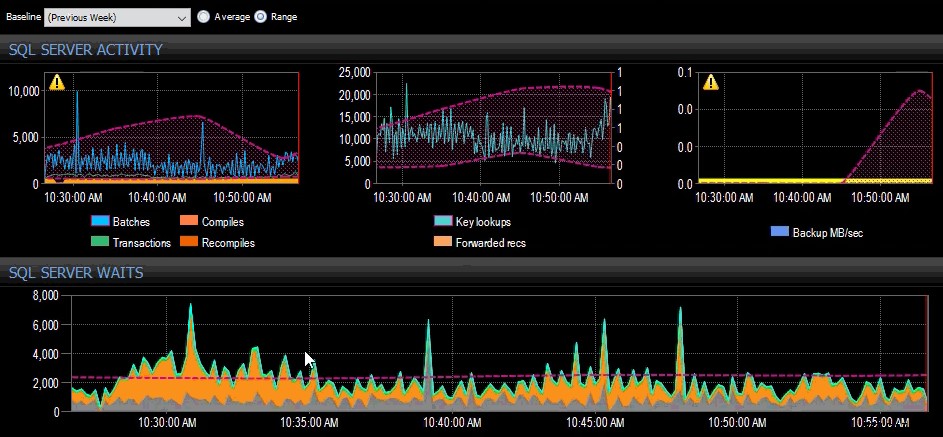 Východ z minulého týdne byl použit na několik metrik SQL Server na řídicím panelu SQL Sentry.
Východ z minulého týdne byl použit na několik metrik SQL Server na řídicím panelu SQL Sentry.
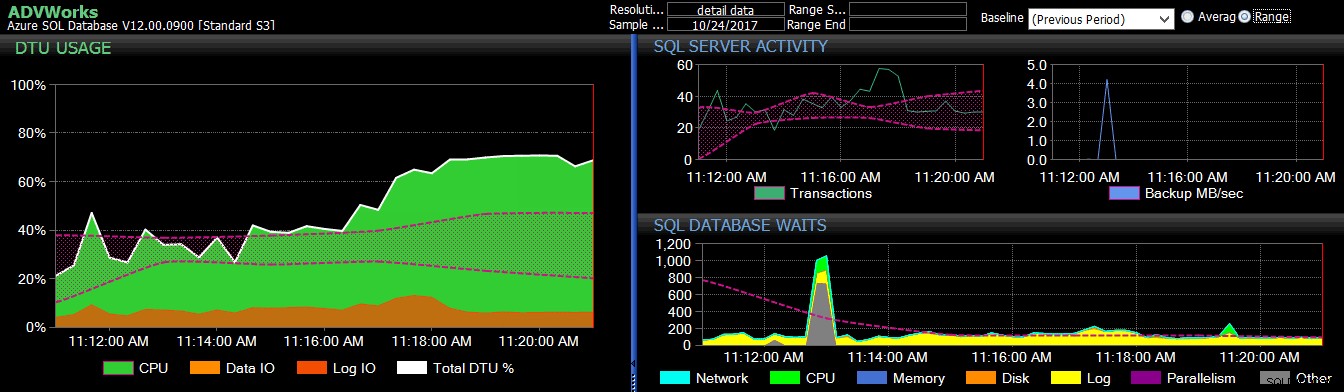 Východ z předchozího období se použil na několik metrik Azure SQL Database na řídicím panelu DB Sentry.
Východ z předchozího období se použil na několik metrik Azure SQL Database na řídicím panelu DB Sentry.
Další informace o základních liniích v SentryOne naleznete v těchto příspěvcích na jejich týmovém blogu nebo v tomto dvouminutovém úterním videu . Máte zájem o stažení zkušební verze? Tam vás také pokryli .