Po celém světě je stránka pracovního portálu dobře známým prvkem na internetu. Velcí hráči jako Indeed a Monster proměnili hledání práce a nábor ve skutečný online průmysl. Pojďme se ponořit do základních funkcí využívaných pracovními portály a vytvořit datový model, který je může podporovat.
Lidé milují úsporu času používáním technologických inovací; online pracovní portál je další verzí práce chytřeji, nikoli tvrději. Uchazeči o zaměstnání i společnosti si uvědomují hodnotu vyhledávání online:získají lepší dosah při vyšších rychlostech a nižších nákladech.
Odvětví pracovních portálů je nyní celkem stabilizované, alespoň co se týče objemu návštěvnosti. Lovci pracovních příležitostí využívají tyto portály k hledání pozic v mnoha průmyslových odvětvích, posouvají se mimo IT do odvětví, jako je strojírenství, prodej, výroba a finanční služby. Dostávají se však do tvrdé konkurence sociálních médií a profesionálních sítí, jako je LinkedIn. Stále však existují příležitosti k prozkoumání, jako je rozšíření jejich pronikání do venkovských oblastí a menších měst.
Takže jak jsme řekli, prozkoumáme toto téma z pohledu návrhu databáze. Začněme výčtem základních očekávání od pracovního portálu.
Co lidé očekávají od online pracovního portálu?
Zaměstnavatelé i uchazeči o zaměstnání očekávají od online pracovního místa následující funkce:
- Lidé se mohou zaregistrovat jako uchazeči o zaměstnání, vytvořit si profily a hledat zaměstnání odpovídající jejich dovednostem.
- Uživatelé mohou nahrávat své stávající životopisy. Pokud žádný nemají, měli by být schopni vyplnit formulář a nechat si sestavit životopis.
- Lidé se mohou hlásit přímo na zveřejněné nabídky.
- Společnosti se mohou registrovat, zveřejňovat nabídky práce a vyhledávat profily uchazečů o zaměstnání.
- Více zástupců společnosti by mělo mít možnost registrovat a zveřejňovat nabídky.
- Zástupci společnosti mohou zobrazit seznam uchazečů o zaměstnání a mohou je kontaktovat, zahájit pohovor nebo provést nějakou jinou akci související s jejich pozicí.
- Registrovaní uživatelé by měli mít možnost vyhledávat pracovní místa a filtrovat výsledky podle místa, požadovaných dovedností, platu, úrovně zkušeností atd.
Vytvoření datového modelu
Po zvážení výše uvedených požadavků jsem přišel se třemi širokými funkčními kategoriemi:
- Správa uživatelů – Jak portál spravuje uživatele, tedy uchazeče o zaměstnání, personalisty a nezávislé nebo poradenské náboráře. (Pro účely tohoto modelu jsou jednotliví zástupci HR a nezávislí nebo poradenskí náboráři považováni za společnosti, alespoň pokud jde o způsob používání portálu.)
- Vytváření profilů – Jak portál umožňuje uchazečům o zaměstnání a organizacím vytvářet profily a životopisy.
- Zveřejňování a vyhledávání pracovních míst – Jak portál usnadňuje proces zveřejňování, vyhledávání a ucházení se o zaměstnání.
Podívejme se na každou z těchto oblastí zvlášť.
1. Správa uživatelů
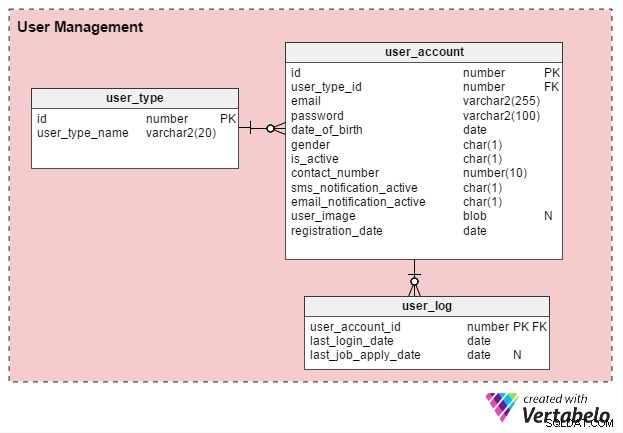
Existují především dva typy uživatelů online pracovních portálů:jednotliví uchazeči o zaměstnání a personalisté (nebo nezávislí konzultanti náboru). Vytvořme tabulku s názvem user_type k uložení těchto záznamů. Pro začátek bude mít dva záznamy – jeden pro uchazeče o zaměstnání a druhý pro náboráře. (Vždy můžeme podle potřeby vytvořit další typy záznamů.)
Uživatelé se musí zaregistrovat, než budou moci portál používat. user_account tabulka ukládá jejich základní údaje o účtu. Dříve jsem zvažoval pojmenovat tuto tabulku „user“, ale protože uživatel je téměř ve všech databázích systémem definované klíčové slovo, raději zůstanu u „user_account“.
user_account tabulka má následující sloupce:
- id – Jedná se jak o primární klíč tabulky, tak o jedinečný identifikátor pro každého uživatele. Na toto ID budou odkazovat další tabulky v datovém modelu.
- id_typu_uživatele – To znamená, zda je uživatel uchazečem o zaměstnání nebo náborářem.
- e-mail – Tento sloupec obsahuje e-mailovou adresu uživatele. Funguje jako další ID uživatele portálu.
- heslo – Zde je uloženo zašifrované heslo účtu (vytvořené uživateli během registrace).
- datum_narození a pohlaví – Jak jejich název napovídá, tyto sloupce obsahují datum narození a pohlaví uživatelů.
- je_aktivní – Zpočátku bude tento sloupec „Y“, ale uživatelé mohou svůj profil nastavit jako neaktivní nebo „N“. Tento sloupec ukládá jejich výběr.
- contact_number – Toto je telefonní číslo (obvykle mobilní) zadané při registraci. Na toto číslo mohou uživatelé dostávat SMS (textová) upozornění. Může to být stejné číslo (nebo ne), jaké mají uchazeči o zaměstnání ve svém profilu nebo životopisu.
- sms_notification_active a email_notification_active – Tyto sloupce ukládají předvolby uživatelů týkající se přijímání oznámení prostřednictvím textu a/nebo e-mailu.
- user_image – Toto je atribut typu BLOB, který ukládá profilový obrázek každého uživatele. Vzhledem k tomu, že tento portál umožňuje pouze jeden profilový obrázek na uživatele, má smysl jej zde ukládat.
- datum_registrace – Tento sloupec uchovává záznam o tom, kdy se uživatel na portálu zaregistroval.
Vytvoříme ještě jednu tabulku, user_log , která uchovává záznam data posledního přihlášení uživatelů a data jejich poslední žádosti o zaměstnání. Existuje mnoho funkcí, které lze z těchto znalostí vytvořit. Tyto informace můžeme použít například k zodpovězení otázky Hledá uživatel X aktivně práci ? Pokud ano, může jim být nabídnut produkt pro vytvoření efektivního životopisu. Uživatelé, kteří aktivně nehledají práci, by takovou nabídku nedostali.
2. Vytváření profilů
Tuto sekci můžeme dále rozdělit na dvě oblasti:firemní nebo organizační profily a profily uchazečů o zaměstnání.
Profily společnosti
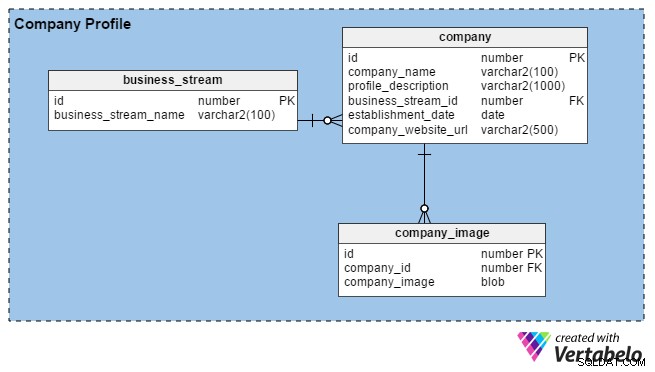
HR týmy obvykle vytvářejí firemní profily tak, že zadávají podrobnosti o své organizaci a obrázky jejich kanceláří, budov atd. Jejich hlavním cílem je přilákat dobré talenty. Když se náboráři zaregistrují na portálu, mohou si také vytvořit profily svých společností (nebo své osobní značky, pokud jsou nezávislí) poskytnutím některých základních údajů, jako je délka jejich podnikání, jejich umístění a hlavní obchodní proud ( např. výroba, IT služby, finance atd.).
Portál umožňuje personalistům a náborářům v oblasti poradenství nahrát libovolný počet obrázků (na rozdíl od uchazečů o zaměstnání, kteří mohou nahrát pouze jeden). Proto jsme vytvořili company_image tabulka pro uložení více obrázků pro každý náborový účet. id_společnosti sloupec v této tabulce je cizí klíč, který odkazuje na jedinečný identifikátor používaný ve company tabulka.
Ve company tabulky, máme následující sloupce:
- id – Primární klíč této tabulky se také používá k jednoznačné identifikaci společností.
- název_společnosti – Jak název sloupce napovídá, jedná se o právní název společnosti.
- popis_profilu – Obsahuje stručný popis každé společnosti.
- id_business_stream_id – Tento sloupec zobrazuje, do kterého obchodního proudu společnost patří. Například společnost zabývající se těžbou ropy a zemního plynu může najmout IT inženýry, ale jejich hlavním obchodním proudem zůstává „ropa a plyn“.
- datum_založení – Tento sloupec uvádí, jak stará je společnost.
- adresa_webu_společnosti – Toto je povinný sloupec (bez možnosti null). Obsahuje odkaz na oficiální web společnosti, takže uchazeči o zaměstnání mohou najít další informace.
Nakonec business_stream tabulka má pouze dva atributy, id, které je primárním klíčem pro tuto tabulku, a popis hlavního obchodního proudu společnosti (business_stream_name ).
Profily uchazečů o zaměstnání
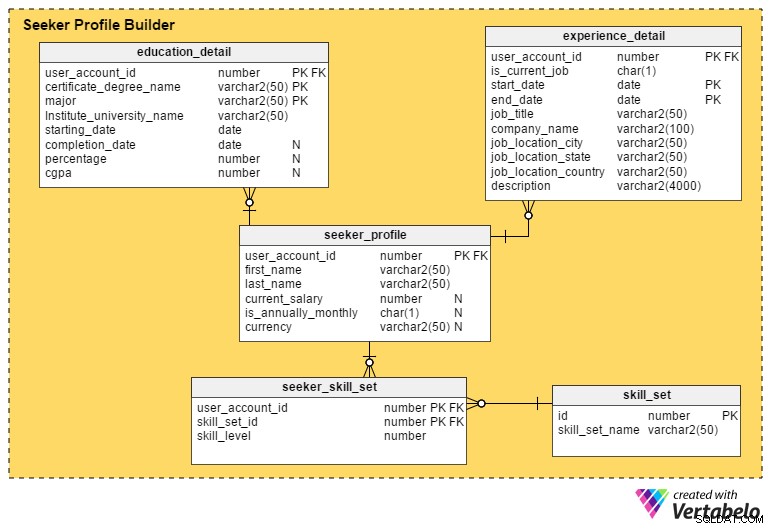
Toto je nejkritičtější část pracovního portálu. Pokud portál nezachytí co nejvíce podrobností o uchazečích o zaměstnání, je pro náboráře obtížné vybrat profily nebo kandidáty do užšího výběru.
seeker_profile tabulka obsahuje další podrobnosti, které nebyly zachyceny během procesu registrace. Obsahuje tato pole:
- id_uživatelského_účtu – Tento sloupec pochází z
user_accounttabulky a funguje jako primární klíč pro tuto tabulku. Zajišťuje, že na jednoho uchazeče o zaměstnání bude existovat maximálně jeden profil. - jméno a last_name – Jak názvy napovídají, tyto sloupce obsahují jméno a příjmení uchazeče o zaměstnání.
- aktuální_plat – Tento atribut obsahuje aktuální plat uchazeče o zaměstnání. Může být zrušena, protože ji lidé možná nebudou chtít zveřejnit.
- je_annually_monthly – To určuje, zda je jejich výše platu za rok nebo za měsíc.
- měna – Toto uloží měnu platu.
education_detail tabulka ukládá historii vzdělání každého uchazeče o zaměstnání, jak ji poskytuje. Má složený primární klíč složený z user_account_id , název_stupně_certifikátu a hlavní sloupců. To zajistí, že uživatelé zadají pouze jeden záznam pro každý titul nebo certifikát. Tabulka obsahuje tyto atributy:
- id_uživatelského_účtu – Tento sloupec pochází z
user_accounttabulky a slouží jako primární klíč pro tuto tabulku. - název_stupně_certifikátu – Toto je typ osvědčení nebo titulu; např. střední škola, vyšší sekundární, absolvent, postgraduální nebo profesní osvědčení.
- hlavní – Tento sloupec obsahuje hlavní studijní obor pro certifikát nebo titul – např. bakalářský titul se zaměřením na informatiku.
- název_univerzity_institutu – Jedná se o institut, školu nebo univerzitu, která udělila titul nebo certifikát.
- počáteční_datum – Tento atribut ukládá datum, kdy byl uživatel přijat do vzdělávacího programu.
- datum_dokončení – Toto je datum udělení titulu nebo certifikátu. Tento atribut má však hodnotu null; lidé možná stále dokončují svůj program, když hledají práci, nebo z programu úplně vypadli.
- procento a cgpa – Tyto sloupce ukládají procento známek nebo CGPA (kumulativní průměr známek), kterých uživatelé dosáhli v jejich studijním nebo certifikačním kurzu.
experience_detail tabulka uchovává záznamy o minulých a současných profesních zkušenostech uživatelů. Obsahuje následující důležité sloupce:
- id_uživatelského_účtu – Tento sloupec pochází z
user_accounttable a je primárním klíčem pro tuto tabulku. - je_současná_job – Toto je sloupec indikátoru, který označuje aktuální úlohu uživatele. Tento sloupec také hraje hlavní roli při odvozování aktuální polohy uživatelů a toho, jak dlouho si aktuální pozici drží.
- počáteční_datum – Toto se uloží, když uživatel zahájí úlohu.
- datum_ukončení – Toto se uloží, když uživatel ukončí úlohu.
- job_title – Obsahuje informace o pracovní roli uživatele.
- název_společnosti – Tento atribut obsahuje relevantní název společnosti spojený s úlohou.
- job_location_city – Toto označuje město, kde se zakázka nacházela.
- job_location_state – Toto označuje stav, kde byla úloha umístěna.
- job_location_country – Označuje zemi, kde byla zakázka umístěna.
- popis – V tomto sloupci jsou uloženy podrobnosti o pracovních rolích a povinnostech, výzvách a úspěších.
Uchazeči o zaměstnání mohou mít více dovedností. Pro uchování záznamů o všech těchto sadách dovedností vytvoříme tabulku seeker_skill_set . Sloupce jsou:
- id_uživatelského_účtu – Tento sloupec pochází z
user_accounttable a je primárním klíčem pro tuto tabulku. - id_souboru dovedností – Toto ID označuje, jakou sadu dovedností uživatel vlastní.
- úroveň_dovednosti – Tento číselný atribut kvantifikuje odbornost uchazečů o zaměstnání v konkrétní dovednosti. Číslo od 1 (začátečník) do 10 (expert) označuje úroveň jejich zkušeností.
Nakonec skill_set tabulka obsahuje popisy všech dovedností uvedených ve výše uvedené tabulce skill_set_id atribut. Obsahuje pouze dva sloupce, název_souboru dovedností a související id .
3. Zveřejňování a vyhledávání pracovních míst
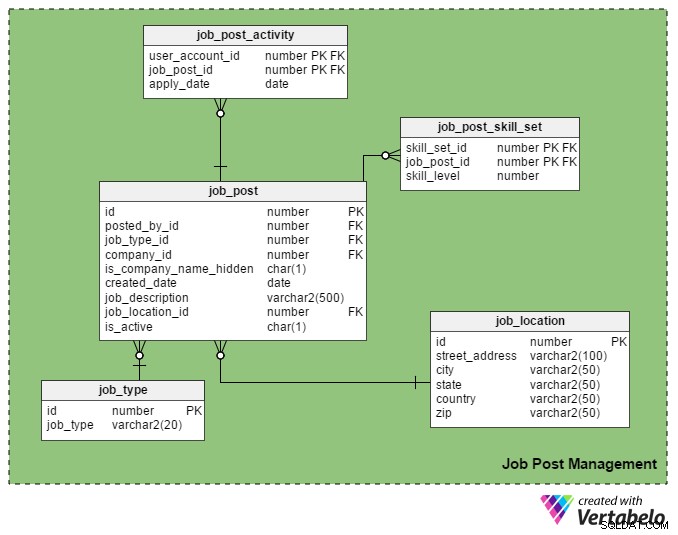
Toto je hlavní USP (Unique Selling Point) pracovního portálu. Pouze registrovaní náboráři mohou zveřejňovat nabídku práce na portálu a mohou se na ně hlásit pouze registrovaní uchazeči o zaměstnání.
job_post tabulka je hlavní tabulka v této oblasti. Jak asi tušíte, obsahuje podrobnosti o pracovních nabídkách. Všechny ostatní tabulky v této sekci jsou vytvořeny kolem něj a jsou s ním propojeny.
- id – Toto je primární klíč této tabulky. Každé pracovní pozici je přiděleno jedinečné číslo a na toto číslo se odkazuje v dalších tabulkách.
- posted_by_id – Tento sloupec obsahuje id_uživatele_registru náborového pracovníka, který úlohu zveřejnil.
- job_type_id – Tento sloupec označuje, zda je trvání úlohy trvalé nebo dočasné (smlouva).
- id_společnosti – Tento sloupec ukládá ID společnosti související s pracovní pozicí. Je to odkaz na
companystůl. - is_company_name_hidden – Toto je sloupec vlajky, který ukazuje, zda se má uchazečům o zaměstnání zobrazovat název společnosti. Náboráři mohou u svých příspěvků raději nezobrazovat názvy společností. Místo toho používají výrazy jako „Global Automobile Company“, „California-Based IT Company“ a tak dále.
- datum_vytvoření – Zde se uloží datum, kdy byla úloha zveřejněna.
- job_description – Obsahuje stručný popis úlohy.
- job_location_id – Toto odkazuje na atribut v
job_locationtabulka, ve které je uloženo skutečné místo zakázky:ulice, město, stát, země a PSČ. - je_aktivní – To znamená, že úloha je stále otevřená. Náboráři mohou své příspěvky označit jako neaktivní, jakmile jsou pozice obsazeny.
job_post_skill_set tabulka ukládá podrobnosti o sadách dovedností požadovaných pro práci. Struktura tabulky je totožná s seeker_skill_set stůl.
A poslední tabulka v této sekci, job_post_activity tabulka obsahuje podrobnosti o tom, kteří uchazeči o zaměstnání se ucházejí o zaměstnání a kdy.
Co byste přidali do tohoto datového modelu online pracovního portálu?
Dnešní online pracovní portály poskytují více než jen platformu pro zveřejňování a ucházení se o zaměstnání. Často zahrnují další profesionální služby jako:
- Osobní řídicí panel pro sledování žádostí o zaměstnání
- Aktualizace aplikací v reálném čase
- Nástroje pro tvorbu životopisů ve videu
- Služby sepisování odborných životopisů
- Tvůrci profilů na LinkedIn nebo jiných sociálních sítích
- Přehledy mezd napříč pracovními rolemi, společnostmi, odvětvími nebo zeměpisnými polohami
Pokud bychom chtěli tyto funkce zabudovat do našeho systému, jaké další změny bychom museli provést? Napadá vás nějaká další nutnost na pracovním portálu?
Sdělte nám prosím své názory v sekci komentářů.