Úvod
Nedávno jsme narazili na zajímavý problém s výkonem na jedné z našich databází SQL Server, které zpracovávají transakce vážnou rychlostí. Transakční tabulka použitá k zachycení těchto transakcí se stala horkou tabulkou. V důsledku toho se problém projevil v aplikační vrstvě. Jednalo se o přerušovaný časový limit relace s cílem zaúčtovat transakce.
Stalo se to proto, že relace by se obvykle „držela“ u stolu a způsobila řadu falešných zámků v databázi.
První reakcí typického správce databáze by bylo identifikovat primární blokující relaci a bezpečně ji ukončit. To bylo bezpečné, protože se obvykle jednalo o příkaz SELECT nebo nečinnou relaci.
Byly také další pokusy o vyřešení problému:
- Vyčištění stolu. Očekávalo se, že to zajistí dobrý výkon, i když dotaz musel prohledat celou tabulku.
- Povolení úrovně izolace READ COMMITTED SNAPSHOT pro snížení dopadu blokování relací.
V tomto článku se pokusíme znovu vytvořit zjednodušenou verzi scénáře a použijeme ji k tomu, abychom ukázali, jak jednoduché indexování může řešit podobné situace, když je provedeno správně.
Dvě související tabulky
Podívejte se na výpis 1 a výpis 2. Zobrazují zjednodušené verze tabulek zahrnutých do uvažovaného scénáře.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Výpis 3 ukazuje spouštěč, který vkládá čtyři řádky do TranDetails tabulky pro každý řádek vložený do TranLog tabulka.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Připojit se k dotazu
Typické je najít transakční tabulky podporované velkými tabulkami. Účelem je uchovávat mnohem starší transakce nebo ukládat podrobnosti o záznamech shrnutých v první tabulce. Představte si to jako objednávky a podrobnosti objednávky tabulky, které jsou typické ve vzorových databázích SQL Server. V našem případě zvažujeme TranLog a TranDetails tabulky.
Za normálních okolností transakce naplňují tyto dvě tabulky v průběhu času. Pokud jde o vytváření sestav nebo jednoduché dotazy, dotaz provede spojení těchto dvou tabulek. Toto spojení bude vydělávat na společném sloupci mezi tabulkami.
Nejprve naplníme tabulku pomocí dotazu ve výpisu 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
V našem příkladu je společným sloupcem používaným spojením TranID sloupec:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Můžete se podívat na dva jednoduché ukázkové dotazy, které používají spojení k načtení záznamů z TranLog a TranDetails .
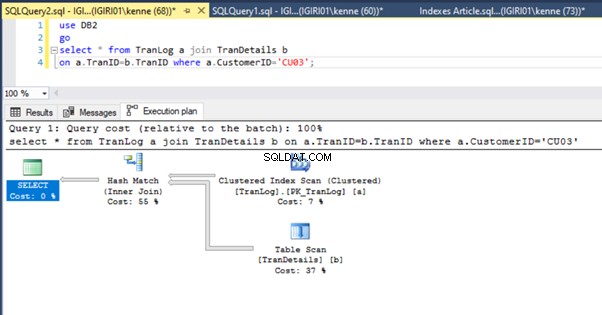
Když spustíme dotazy ve výpisu 5, v obou případech musíme provést úplné prohledání tabulek na obou tabulkách (viz obrázky 1 a 2). Dominantní částí každého dotazu jsou fyzické operace. Oba jsou vnitřní spoje. Výpis 5a však používá Hash Match připojit, zatímco výpis 5b používá vnořenou smyčku připojit. Poznámka:Výpis 5a vrátí 4000 řádků, zatímco Výpis 4b vrátí 4 řádky.
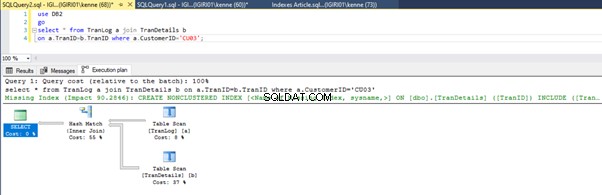
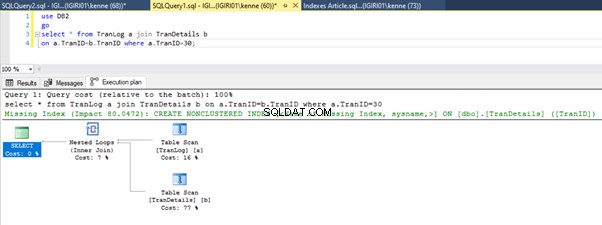
Tři kroky ladění výkonu
První optimalizací, kterou provádíme, je zavedení indexu (přesněji primárního klíče) na TranID sloupec TranLog tabulka:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
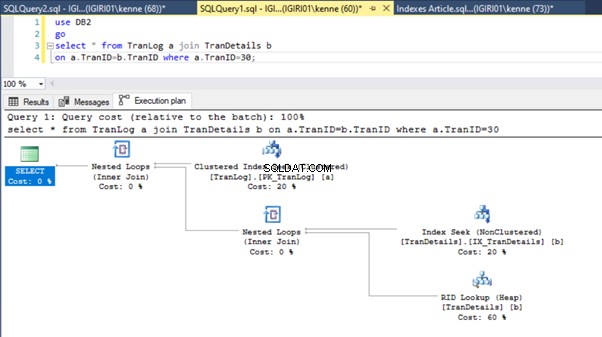
Obrázky 3 a 4 ukazují, že SQL Server využívá tento index v obou dotazech, přičemž provádí skenování ve výpisu 5a a vyhledávání ve výpisu 5b.
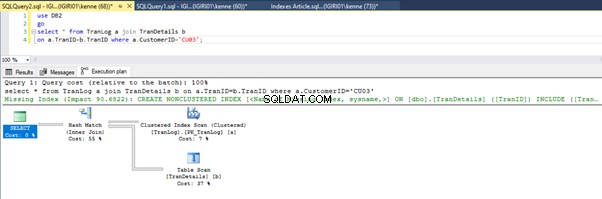
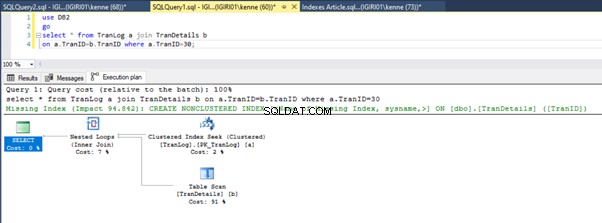
Ve výpisu 5b máme hledání indexu. Stává se to kvůli sloupci zahrnutému v predikátu klauzule WHERE – TranID. Je to sloupec, na který jsme použili index.
Dále představíme cizí klíč na TranID sloupec TranDetails tabulka (Výpis 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
To se na prováděcím plánu příliš nemění. Situace je prakticky stejná, jak je znázorněno dříve na obrázcích 3 a 4.
Poté zavedeme index do sloupce cizího klíče:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Tato akce dramaticky změní plán provádění výpisu 5b (viz obrázek 6). Vidíme, že se více index snaží stát. Všimněte si také vyhledávání RID na obrázku 6.
K vyhledávání RID na haldách obvykle dochází při absenci primárního klíče. Halda je tabulka bez primárního klíče.
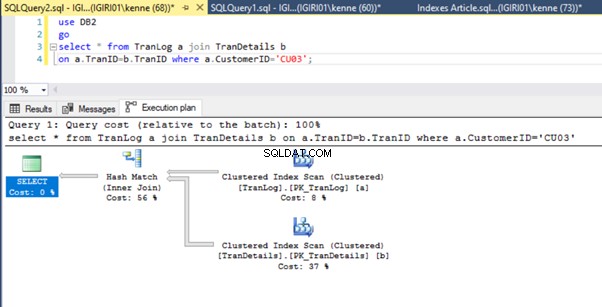
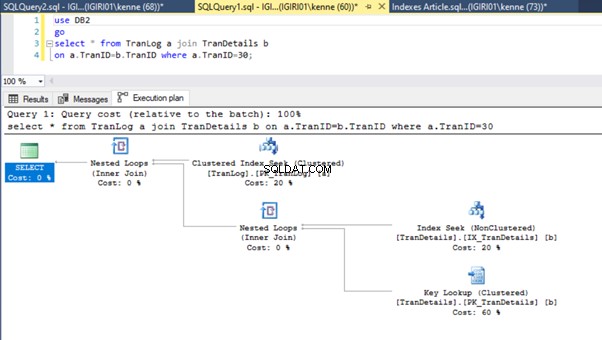
Nakonec přidáme primární klíč do TranDetails stůl. Tím se zbavíte prohledávání tabulky a vyhledávání haldy RID ve výpisech 5a a 5b (viz obrázky 7 a 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Závěr
Zlepšení výkonu zavedené indexy je dobře známé i začínajícím DBA. Chceme však upozornit, že je třeba se podrobně podívat na to, jak dotazy využívají indexy.
Dále je myšlenkou vytvořit řešení v konkrétním případě, kdy máme spojovací dotazy mezi Protokolem transakcí tabulky a Podrobnosti transakce tabulky.
Obecně má smysl vynutit vztah mezi takovými tabulkami pomocí klíče a zavést indexy do sloupců primárního a cizího klíče.
Při vývoji aplikací, které používají takový návrh, by vývojáři měli mít na paměti požadované indexy a vztahy ve fázi návrhu. Moderní nástroje pro specialisty na SQL Server tyto požadavky mnohem snáze splňují. Své dotazy můžete profilovat pomocí specializovaného nástroje Query Profiler. Je součástí profesionálního řešení s mnoha funkcemi dbForge Studio pro SQL Server vyvinutého společností Devart, aby usnadnilo život DBA.