V této době tvrdé konkurence nejsou pracovní portály jen platformou pro publikování a hledání práce. Využívají pokročilé služby a funkce, aby udrželi zájem svých zákazníků. Pojďme se ponořit do některých pokročilých funkcí a vytvořit datový model, který je zvládne.
Základní funkce potřebné pro web pracovního portálu jsem vysvětlil v předchozím článku. Model je zobrazen níže. Tento model budeme považovat za základ, který změníme, aby vyhovoval novým požadavkům. Nejprve se podívejme, jaké by tyto požadavky (nebo vylepšení) měly být.
Co přidáváme do datového modelu online pracovního portálu?
Krátce, do našeho dřívějšího datového modelu přidáme čtyři vylepšení:
- Osobní panel pro uchazeče o zaměstnání. To sleduje všechny jejich žádosti o zaměstnání a poskytuje aktualizace v reálném čase o jakýchkoli změnách stavu (tj. žádost se změní z přijaté na zkontrolovanou).
- Hlavní panel profilu. Zde jsou uvedeny podrobnosti o tom, kdo navštěvuje profil uchazeče o zaměstnání a kolikrát byl jeho životopis stažen za poslední den, týden nebo měsíc.
- Správa placených služeb. Pracovní portály často nabízejí služby, jako je příprava odborných životopisů, správa sociálních profilů, kariérní poradenství atd. Naše nové funkce budou schopny podporovat placené nabídky.
- Správa formulářů před aplikací. Když uchazeči podávají žádost o zaměstnání, mohou být požádáni o vyplnění krátkého dotazníku týkajícího se pracovní doby, místa a prověrek. Vytvoříme způsoby, jak tento formulář přizpůsobit personalisté a systém zachytí otázky a odpovědi.
Vylepšení č. 1:Osobní ovládací panel
Otázky k zodpovězení: Jaký je aktuální stav podané žádosti? Je to užší výběr na pohovor? Bylo to vůbec zhlédnuto?
Můžeme sledovat žádosti o zaměstnání zadáním job_application_status_id ve sloupci job_post_activity stůl. Tento sloupec obsahuje aktuální stav žádosti o zaměstnání. Musíme vytvořit další tabulku, job_application_status , k udržení všech možných stavů aplikace. Některé stavy mohou být ‚odesláno‘, ‚probíhá kontrola‘, ‚archivováno‘, ‚odmítnuto‘, ‚zařazeno do užšího výběru k pohovoru‘, ‚v procesu náboru‘ a tak dále.
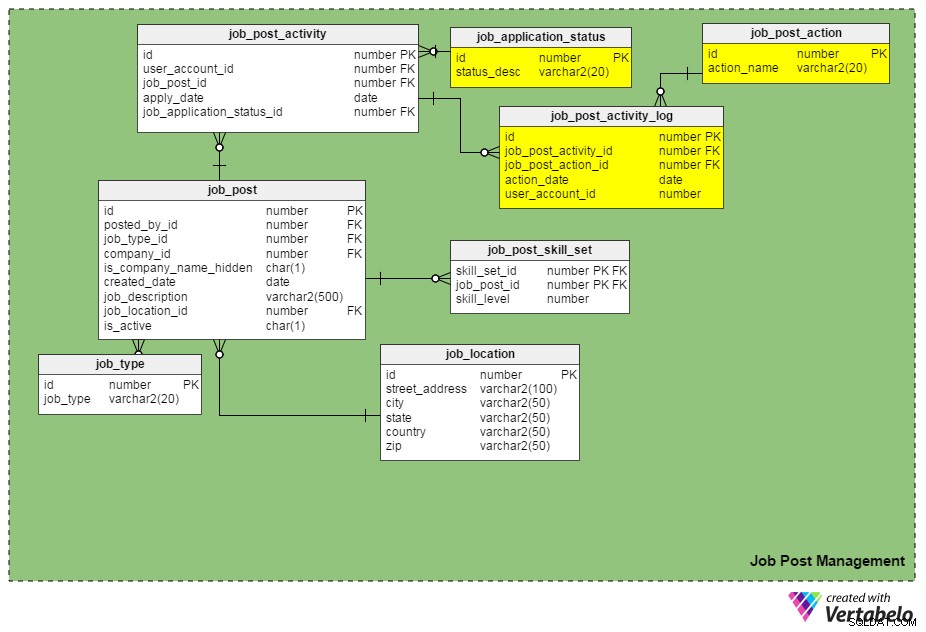
Další nová tabulka, job_post_activity_log , ukládá informace o všech akcích provedených na žádostech o zaměstnání, kdo akci provedl a kdy byla provedena. Tato tabulka obsahuje následující sloupce:
id– Primární klíč tabulky.job_post_activity_id– ID aplikace, na které se akce provádí.job_post_action_id– ID provedené akce. Toto je cizí klíč, který odkazuje najob_post_actionstůl. Mezi typy akcí, které zde můžeme ukládat, patří „odesláno“, „zobrazeno“, „pohovor“, „proveden písemný test“, „zpracovává se nabídka“, „nabídka odeslána“, „nabídka přijata“ atd.action_date– Datum, kdy byla provedena akce.user_account_id– ID osoby, která provedla akci.
Je „job_post_action“ shodný s „job_application_status“? Jak se liší?
Na první pohled vypadají stejně, ale ve skutečnosti jsou odlišné. Existují pádné důvody, proč potřebujeme dvě podobná pole:
- S kandidátem vede pohovor dvě nebo více osob samostatně. V tomto případě zůstává stav žádosti o zaměstnání stejný (tj. „probíhá náborový proces“), dokud nebudou dokončena všechna kola pohovoru. Záznamy pro každého jednotlivého tazatele jsou však vloženy do
job_post_activity_logstůl a mají akci ‚vyzpovídat‘. - Aplikaci může zobrazit více než jeden náborář ve stejné společnosti. Použitím těchto dvou atributů neztratíte informace o žadateli.
- Podání nabídky vybranému kandidátovi podléhá vícenásobnému schválení (tj. schválení od finančního týmu, schválení od manažera náborového oddělení atd.). V tomto případě zůstává stav žádosti o zaměstnání „nabídka ve fázi kontroly“, ale databáze může zaznamenat, která schválení prošla a která ne, pomocí
job_post_activity_logstůl.
Vylepšení č. 2:Panel profilu
Otázky k zodpovězení: Kdo v poslední době našel můj profil? Kolikrát to bylo zobrazeno náboráři za poslední měsíc, týden nebo den? Podívali se náboráři z top společností na můj profil?
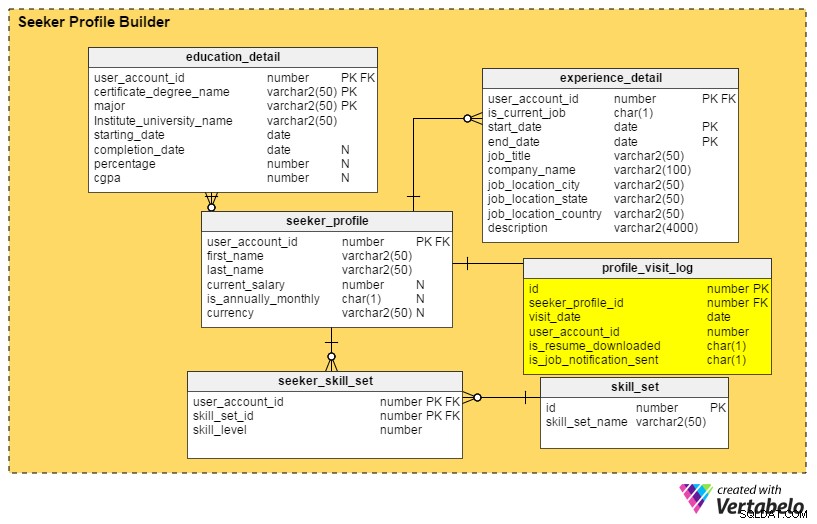
Odpovědi na všechny tyto otázky jsou v profile_visit_log stůl. Tato tabulka zachycuje všechna data o návštěvách profilu, včetně toho, kdo navštívil profil, kdy byl zobrazen atd. Sloupce v této tabulce jsou:
id– Primární klíč tabulky.seeker_profile_id– Který profil byl navštíven.visit_date– Kdy byl profil otevřen.user_account_id– Kdo viděl profil.is_resume_downloaded– Sloupec vlajky, který označuje, zda byl související životopis stažen během návštěvy. Tento sloupec nám pomůže odvodit, kolikrát si náboráři stáhli životopis.is_job_notification_sent– Další sloupec s příznakem, tento uvádí, zda bylo vlastníkovi profilu zasláno oznámení o úkolu.
Vylepšení č. 3:Správa placených služeb
Otázka k zodpovězení: Jak mohou online portály využívat další placené služby?
Kromě platformy pro zveřejňování a vyhledávání pracovních míst poskytuje mnoho online portálů další služby, jako je vytváření odborných životopisů, kariérní poradenství atd. Nabízejí také produkty, které pomáhají uchazečům o zaměstnání najít vysněnou práci ve městě snů. Například jeden z předních pracovních míst nabízí produkt, díky kterému bude váš profil na vrcholu seznamu náborářů, takže můžete získat více nabídek na pohovor. Většina těchto produktů nebo služeb je k dispozici na základě předplatného. Když si uživatel zakoupí službu nebo produkt, zaplatí za určité časové období (tj. měsíc, tři měsíce, jeden rok) za používání tohoto produktu nebo služby.
Když jsem se díval na tyto pracovní portály, všiml jsem si, že téměř žádné produkty nebo služby nejsou nabízeny samostatně. Z velké části je více produktů a služeb spojeno do jednoho balíčku a tento balíček je nabízen buď uchazečům o zaměstnání, nebo náborářům.
S přihlédnutím ke všem těmto bodům jsem přišel s následujícím datovým modelem pro začlenění placených služeb a produktů do naší stávající online pracovní stránky:
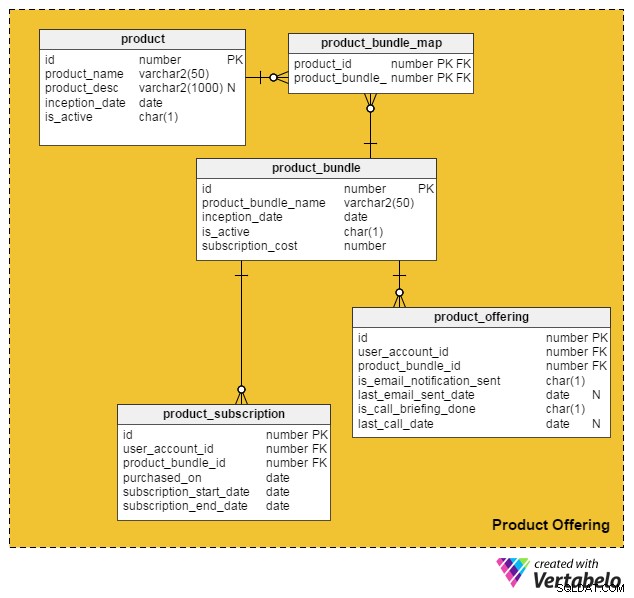
product tabulka obsahuje podrobnosti o jednotlivých produktech. (Produkty i služby budeme označovat jako „produkty“). Sloupce v této tabulce jsou:
id– Primární klíč této tabulky, který dává jedinečné ID každému produktu nabízenému na našem portálu.product_name– Obsahuje název produktu.product_desc– Ukládá stručný popis produktu.inception_date– Datum, kdy byl produkt představen.is_active– Zda je produkt aktivní či nikoli.
Vzhledem k tomu, že produkty a služby lze spojit do jednoho balíčku a nabídnout je zákazníkům, vytvořil jsem product_bundle tabulky pro ukládání záznamů o všech takových svazcích. Atributy jsou:
id– Primární klíč tabulky, který poskytuje jedinečné ID pro každý balíček produktů.product_bundle_name– Ukládá název balíčku.inception_date– Datum, kdy byl balíček představen.is_active– Označuje, zda je svazek aktivní či nikoli.subscription_cost– Uloží cenu požadovanou za balíček.
Lze zákazníkům nabídnout jeden produkt?
Ano. V tomto datovém modelu může být jeden produkt jeho vlastním „balíčkem“. Následující tabulky popisují tuto a některé další důležité funkce.
product_bundle_map tabulka ukládá seznam všech produktů, které jsou součástí balíčku. Jeho atributy jsou samozřejmé.
Další tabulka product_subscription , přichází do hry, když si zákazníci předplatí balíčky produktů. Zaznamenává podrobnosti o tom, kteří zákazníci se přihlásili ke kterým balíčkům. Sloupce v této tabulce jsou:
id– Primární klíč tabulky.user_account_id– Uživatel, který balíček zakoupil.product_bundle_id– Balíček produktů zakoupený uživatelem.purchased_on– Datum nákupu.subscription_start_date– Datum zahájení předplatného. Upozorňujeme, že datum nákupu produktu a datum zahájení předplatného se mohou lišit. Proto pro ně máme dva různé sloupce.subscription_end_date– Kdy předplatné skončí.
Konečná tabulka, product_offering , slouží především k marketingu. Pracovní portály obvykle analyzují nedávné aktivity uživatelů (jak uchazečů o zaměstnání, tak náborářů) a poté se rozhodnou, které produkty budou pro které uživatele přínosné. Pomocí e-mailů nebo telefonátů pak zákazníky kontaktují s vybranými nabídkami. Sloupce pro tuto tabulku jsou:
id– Primární klíč tabulky.user_account_id– Uživatel, na kterého pracovní portál cílí.product_bundle_id– Balíček produktů, který marketingoví pracovníci portálu přiřadili uživateli.is_email_notification_sent– Zda byl odeslán e-mail týkající se nabídky produktu.last_email_sent_date– Když uživatel naposledy obdržel produktový e-mail od marketingového týmu. Je běžné, že marketéři posílají uživateli více upozornění a další upozornění posílají pravidelně. V tomto sloupci je uloženo datum, kdy bylo odesláno poslední upozornění.is_call_briefing_done– Zda zákazník obdržel telefonický hovor s informací o produktu.last_call_date– Datum posledního telefonního hovoru. Zákazníkům může být uskutečněno více hovorů (následných hovorů).
Vylepšení č. 4:Správa formulářů před aplikací
Otázka k zodpovězení: Jak může náborář získat přizpůsobený formulář souhlasu vyplněný všemi potenciálními uchazeči o zaměstnání?
Mnohokrát, uchazeči o zaměstnání, aby odpověděli na konkrétní otázky, když se ucházeli o místo. To běžně zahrnuje věci, jako je souhlas s prověřením kriminální minulosti. Existují však různé další typy souhlasů, které mohou být potřeba. Například práce v marketingu může vyžadovat hodně cestování; práce v rámci outsourcingu podnikových procesů (BPO) mohou vyžadovat, aby zaměstnanci pracovali na hřbitovní (tj. pozdní noční) směny. Ty jsou uvedeny ve formulářích předběžné přihlášky.
Vždy je nejlepší získat souhlas při podání žádosti o zaměstnání. Tímto způsobem se uchazeči, kteří nejsou ochotni splnit tyto požadavky, nebudou o práci ucházet.
Než přejdu k datovému modelu, dovolte mi nejprve zdůraznit některá základní fakta o formulářích souhlasu:
- Příspěvek s nabídkou práce může mít více než jeden formulář souhlasu.
- Každý formulář souhlasu má různé otázky spojené s různými sekcemi.
- Otázku lze nastavit jako povinnou nebo volitelnou v závislosti na tom, jak je otázka ve formuláři označena. Otázka může být v jednom formuláři volitelná a v jiném povinná.
- Na každou otázku lze odpovědět buď (1) ano, (2) ne nebo (3) neaplikovatelné.
- Všechny odpovědi budou zaznamenány.
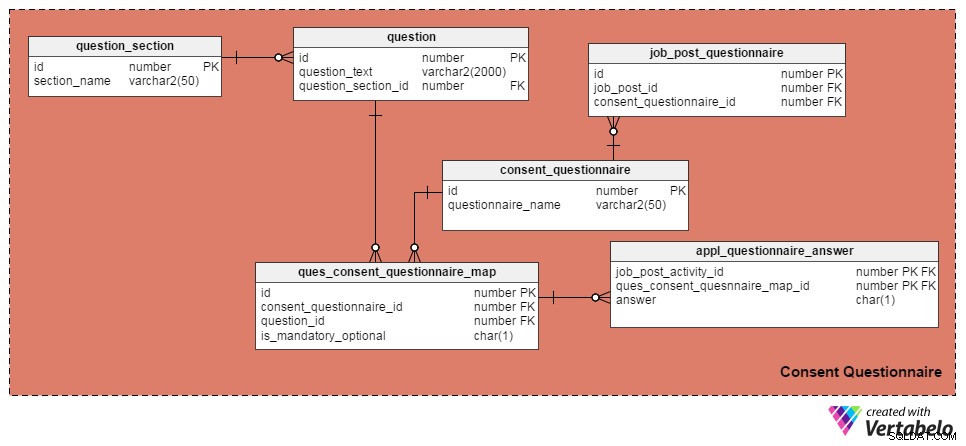
Ke správě otázek a formulářů souhlasu jsem použil následující čtyři tabulky. První, question tabulka, obsahuje seznam otázek. Má tyto atributy:
id– Primární klíč tabulky, který každé otázce přiděluje jedinečné ID.question_text– Ukládá aktuální text otázky.question_section_id– Sekce, kde se zobrazuje otázka. (Např. „Pracoval jsi ve vývoji softwaru alespoň pět let?“ se zobrazí v části „Pracovní zkušenosti“.) Toto je sloupec cizího klíče, na který odkazujequestion_sectionstůl.
Sekce question_section tabulka ukládá informace o sekci. Je to způsob, jak seskupit otázky týkající se stejného tématu. Kromě id atribut, který je primárním klíčem tabulky, jediným atributem je section_name , což je samovysvětlující.
consent_questionnaire tabulka obsahuje názvy formulářů souhlasu. Jeho dva atributy jsou také samozřejmé.
ques_consent_questionnaire_map tabulka je jádrem této oblasti. Všechny ostatní tabulky v této tematické oblasti s ní přímo či nepřímo souvisí. Jeho účelem je vést seznam otázek označených ve formulářích souhlasu. Sloupce v této tabulce jsou:
id– Primární klíč této tabulky.consent_questionnaire_id– Identifikační číslo formuláře souhlasu.question_id– Identifikační číslo otázky.is_mandatory_optional– Označuje, zda je otázka pro daný formulář souhlasu povinná nebo volitelná. Otázka může být součástí více formulářů souhlasu, ale v některých může být povinná a v jiných volitelná. To je jediný důvod, proč tento sloupec ponechat zde, místo aby byl uveden vquestionstůl.
V následujících několika tabulkách probereme formuláře souhlasu se značkami pro jednotlivé pracovní pozice a zaznamenáme odpovědi kandidátů. Začněme job_post_questionnaire tabulka, která ukládá informace o tom, jaké formuláře souhlasu jsou součástí pracovní nabídky. Může existovat jeden nebo více formulářů souhlasu označených pracovní pozicí. Sloupce v této tabulce jsou:
id– Primární klíč tabulky.job_post_id– Označuje, kterým pracovním místem je formulář souhlasu označen.consent_questionnaire_id– Formulář souhlasu označený k pracovnímu příspěvku.
Dále appl_questionnaire_answer tabulka zaznamenává jednotlivé odpovědi na každou otázku formuláře souhlasu, jak je vyplnili žadatelé. Sloupce v této tabulce jsou:
job_post_activity_id– Sloupec cizího klíče odkazovaný zjob_post_activitystůl. Ukládá informace o kandidátovi, který na otázku odpověděl.quest_consent_quesnnaire_map_id– Další sloupec cizího klíče odkazovaný zquest_consent_questionnaire_mapstůl. Ukládá, která otázka z kterého formuláře souhlasu je zodpovězena.answer– Skutečná odpověď uchazeče o zaměstnání. Ponechal jsem to jako sloupec CHAR(1), protože na všechny otázky v našem modelu lze odpovědět jako „Ano“ (odpověď =„Y“), „Ne“ (odpověď =„N“) nebo „Nelze použít“ (odpověď ='X').
Nový a vylepšený datový model online pracovního portálu
Dokončený datový model si můžete prohlédnout níže.
Co byste přidali?
Napadají vás nějaké další funkce, které byste přidali na náš online pracovní portál? Podělte se o své názory v sekci komentářů.