Bez ohledu na to, na které straně rovnice jste, někdy je těžké najít kvalifikovaného člověka pro konkrétní práci. V tomto příspěvku se podíváme na datový model, který pomůže náborářům a personálním oddělením zůstat organizovaný během procesu náboru.
Většina z nás byla zapojena do procesu přijímání zaměstnanců – nejčastěji jako uchazeči o zaměstnání. Můžeme se však také ocitnout na straně náboru, například testováním technických znalostí uchazeče. Proces náboru trvá určitou dobu a skupina uchazečů se neustále zmenšuje, jak se blížíme ke konečnému rozhodnutí. Výsledkem by měl být výběr toho nejlepšího člověka pro danou práci.
Nábor je sám o sobě dost komplikovaný, takže budeme diskutovat o poměrně komplexním datovém modelu, který pokryje všechny aspekty procesu. Posaďte se na židli a užijte si dnešní článek!
Jak funguje proces náboru
Většina částí náborového procesu je běžně známá, ale než přejdeme k datovému modelu, probereme si, jak přesně to funguje.
-
Zjištění potřeby
To je absolutní nutnost v procesu náboru; neproběhne žádný proces, pokud si vedení není vědomo nutnosti přijmout nového zaměstnance. Tato potřeba může být důsledkem založení nové společnosti, růstu ve stávající společnosti nebo odchodu stávajícího zaměstnance.
Pokud společnost nemá přesně definované pozice (např. banky), není vždy snadné určit, kdy najmout nového zaměstnance. Mluvit se zaměstnanci a vidět spoustu přesčasů může podnítit nové zaměstnance. Interní nebo externí předpisy mohou také vyžadovat, aby určité pozice byly přiděleny pouze lidem se specifickými dovednostmi a odpovídajícími pracovními zkušenostmi (např. interní revizor).
-
Nastínění pozice a jejích požadovaných dovedností
Abyste si o tomto kroku udělali představu, myslete na opravdu dobře napsaný popis práce. Obsahuje:
- Seznam všech úkolů souvisejících s úlohou
- Minimální vzdělání a kvalifikace s pracovní praxí
- Specifické dovednosti nezbytné pro pracovní funkce
- Další nebo preferované dovednosti
- Shrnutí toho, co zaměstnavatel od uchazeče očekává a co může uchazeč od této práce očekávat
- Rozsah platů a možná i balíček výhod
Tyto informace jsou důležité pro náboráře i uchazeče. Nemá smysl zvát do výběrového řízení deset uchazečů, pokud ani jeden nebude spokojen s finanční nabídkou. A čím podrobnější bude popis práce, tím snazší bude přilákat kvalifikované uchazeče.
-
Definování toho, kdo bude řídit proces a kdy se má každý úkol uskutečnit
Dalším krokem je definovat konkrétní data, kdy se jednotlivé části procesu uskuteční. Společnosti také mohou ke každému kroku přiřadit zaměstnance. Pokud má společnost oddělení lidských zdrojů, bude pravděpodobně řídit každou část náborového procesu, i když ostatní zaměstnanci mohou v případě potřeby přispět svými specifickými znalostmi (např. pokud najímáme IT specialistu, měl by kandidáty posoudit manažer IT oddělení ' technické dovednosti).
Pokud neexistuje HR oddělení, můžeme očekávat, že proces budou mít na starosti řídící pracovníci. V malých a středních společnostech je to nejen potřeba, ale i žádoucí.
-
Zveřejnění úlohy
Nyní jsme připraveni zveřejnit popis práce na našem webu, na nástěnkách nebo agregátorech nebo v novinách. Pracovní nabídka by měla obsahovat odrážky uvedené v kroku 2. To pomůže potenciálním kandidátům rozhodnout se, zda se chtějí o pozici ucházet. Je nezbytné, aby byl popis práce přesný; všichni jsme ztráceli čas pohovory o práci, která neodpovídala jejímu popisu nebo našim očekáváním.
-
Výběr, testování a pohovory s kandidáty
Po skončení období pro podávání žádostí budou uchazeči s nejrelevantnějšími dovednostmi a zkušenostmi pozváni k úvodní fázi hodnocení (obvykle pohovor nebo test). Ostatní uchazeči budou informováni, že nebyli vybráni na dané pracovní místo. Velká společnost by měla k úvodnímu hodnocení pozvat předem definovaný minimální počet kandidátů. To šetří čas žadatelům i firmě.
Malé a střední společnosti se mohou rozhodnout pokračovat v procesu, dokud nenajdou nejvhodnější řešení. V takových případech zůstane lhůta pro podávání žádostí otevřená, dokud nebude nalezen správný kandidát a všechna ostatní data budou stanovena v průběhu.
Proces pohovoru a testování se bude lišit podle velikosti společnosti a organizace. Ve velkých společnostech s HR odděleními bude pravděpodobně existovat soubor testů, které prověří pracovní dovednosti uchazečů. Jiné testy mohou měřit psychologické a osobnostní rysy, aby bylo možné určit shodu mezi uchazečem o zaměstnání, shodu mezi uchazečem a společností nebo dokonce duševní zdraví uchazeče. ☺
Tyto testy budou obvykle rozděleny do několika kroků a každý krok sníží počet žadatelů.
-
Závěrečný rozhovor
Tímto krokem bude pravděpodobně pohovor s několika nejlepšími uchazeči. Je to nejdůležitější krok v procesu, protože uchazeči mohou mluvit sami za sebe, prokázat svou kompetenci a osobnost a rozhodnout, zda pro ně bude společnost a pozice vhodná. Po tomto kroku obdrží nejlepší uchazeč nabídku. Pokud přijmou, nábor na tuto pozici je u konce. Pokud uchazeč nabídku práce odmítne, společnost mu nabídne další volbu.
-
Existují rozdíly v náborovém procesu pro malé, střední a velké podniky? Jak je vyřešíme v našem modelu?
V náborových procesech malých, středních a velkých společností budou určité rozdíly. Proces se navíc bude lišit podle náborových pozic. Představte si, jak odlišné jsou požadované dovednosti a zkušenosti pro správce obsahu, ornitologa a kapitána výletní lodi. Některá zaměstnání budou mít více testů a pohovorů, jiná jich mohou mít jen pár. Nakonec ale vše závisí na získání správných odpovědí a na seřazení uchazečů.
V tomto modelu budu se všemi testy a pohovory zacházet stejně. Uložíme odpovědi každého žadatele, spojíme je s relevantní otázkou a uložíme skóre žadatele pro každý krok procesu.
-
Kdo může tento datový model používat?
Tento model je velmi specifický a měl by být používán pouze pro náborový proces. Ale není to omezeno na HR oddělení; tento model můžete také použít k provozování profesionální náborové služby.
-
Datový model
Datový model se skládá z pěti hlavních tematických oblastí:
JobsApplicants, Recruiters and DocumentsApplicationsTest detailsApplication tests
Každou oblast popíšu samostatně, ve stejném pořadí, v jakém jsou uvedeny.
Část 1:Práce
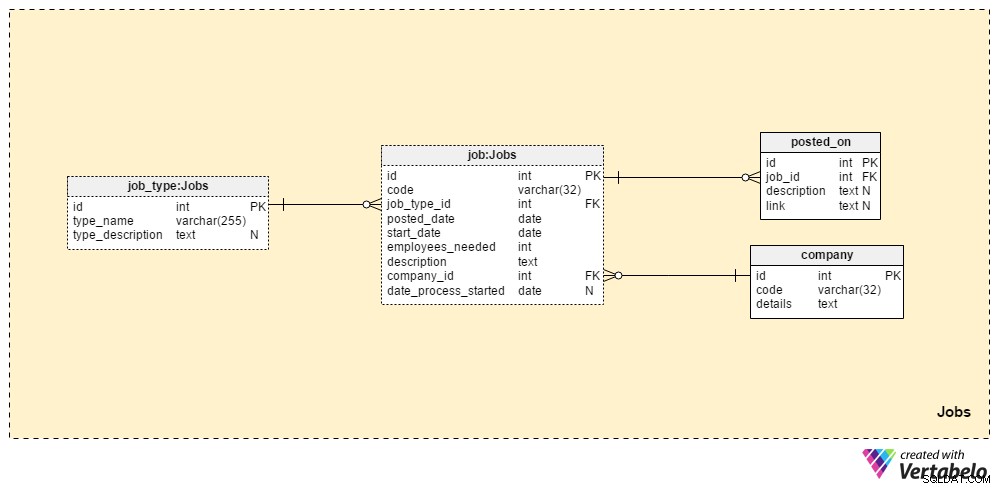
Jobs sekce bude ukládat všechny podrobnosti o všech pozicích, které jsme kdy zveřejnili. Dvě tabulky slovníku, company tabulka a job_type stůl, jsou součástí počátečního nastavení. Zbývající dva stoly, job a posted_on , obsahují „skutečné“ údaje související s pracovními nabídkami.
job_type slovník obsahuje seznam různých a UNIKÁTNÍCH typů úloh. Můžeme očekávat hodnoty jako “senior database administrator” nebo „IT novinář“ bude uložen v type_name atribut. type_description atribut může uložit podrobnější popis úlohy.
company slovník obsahuje seznam všech společností, se kterými spolupracujeme. Pokud najímáme zaměstnance pouze pro naši společnost, bude tento slovník obsahovat pouze název naší společnosti. Pokud jsme personální agentura, uchová jména každé společnosti, která nás najala.
Seznam všech pracovních pozic, které jsme kdy zveřejnili, je uložen v tabulce „job“. Atributy v této tabulce jsou:
code– Naše interní UNIQUE ID používané k označení úlohy.job_type_id– Odkazuje na související typ úlohy.posted_date– Datum, kdy byla tato pracovní pozice zveřejněna.start_date– Očekávané datum zahájení (první pracovní den) pro danou úlohu.employees_needed– Počet zaměstnanců, které chceme přijmout během tohoto náborového procesu. Většinou to bude mít hodnotu „1“, ale v některých případech – např. při zakládání nové společnosti nebo zakládání nového oddělení – můžeme očekávat větší hodnoty.description– Podrobný popis této pozice. Toto je místo, kde uvedeme všechny požadované, preferované a požadované pracovní dovednosti.company_id– Odkazuje na ID společnosti, která nás najala. Pokud jsme personální agentura, bude to odkazovat na obchodní název uložený vecompanystůl. Jinak to bude ID naší vlastní společnosti.date_process_started– Datum zahájení náborového procesu. Pokud potřebujeme definovat budoucí kroky a akce týkající se této úlohy, může to být NULL.
Poslední tabulkou v této oblasti je posted_on stůl. Pro každý job_id , uložíme link na pracovní místo a související description . Tato data bychom mohli použít k tomu, abychom zjistili, kde uchazeči nacházejí naše pracovní pozice.
Část 2:Žadatelé, náboráři a dokumenty
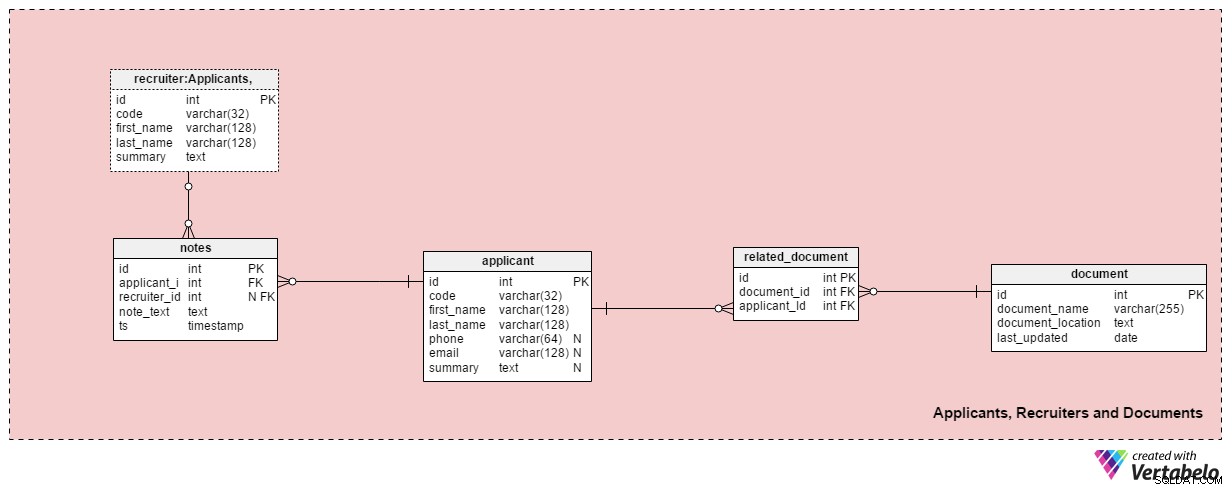
Tato předmětová oblast obsahuje všechny tabulky potřebné k uložení informací o náborářích, uchazečích a jejich souvisejících dokumentech.
applicant tabulka uvádí všechny žadatele, se kterými jsme kdy byli v kontaktu. Každý žadatel je v našem systému JEDNOZNAČNĚ definován pomocí „kódu“. Kromě toho uložíme jméno a příjmení každého žadatele, phone číslo, email adresy a jejich summary . Tento stůl lze upravit pro konkrétní potřeby, např. přidání dalších telefonních čísel, e-mailů nebo fyzických adres.
Žadatelům poskytneme dostupné dokumenty. Seznam všech dostupných dokumentů (životopis nebo životopis, tituly nebo diplomy, přepisy, certifikace atd.) je uložen v document stůl. U každého dokumentu uložíme jeho název v systému, jeho umístění a čas poslední aktualizace.
Žadatelům přiřadíme dokumenty pomocí related_document stůl. Obsahuje pouze dva cizí klíče, které tvoří document_id – applicant_id UNIKÁTNÍ pár.
recruiter tabulka uvádí zaměstnance, kteří mohou být zařazeni do žádosti o zaměstnání nebo kteří zadávají poznámky týkající se uchazeče. Každý recruiter je JEDINEČNĚ definován svým code . Uložíme pouze základní údaje, jako je first_name , last_name a summary náborového pracovníka .
Poslední tabulkou v této oblasti jsou notes stůl. Zde uložíme všechny poznámky týkající se žadatele. Mohli bychom ukládat poznámky jako „Žadatel zmeškal schůzku“ nebo „Uchazeč si vedl skvěle na prvním pohovoru“ . U každé poznámky uložíme ID náborového pracovníka, který tuto poznámku napsal, ID souvisejícího žadatele, note_text a časové razítko, kdy byla poznámka vytvořena.
Část 3:Podrobnosti testu
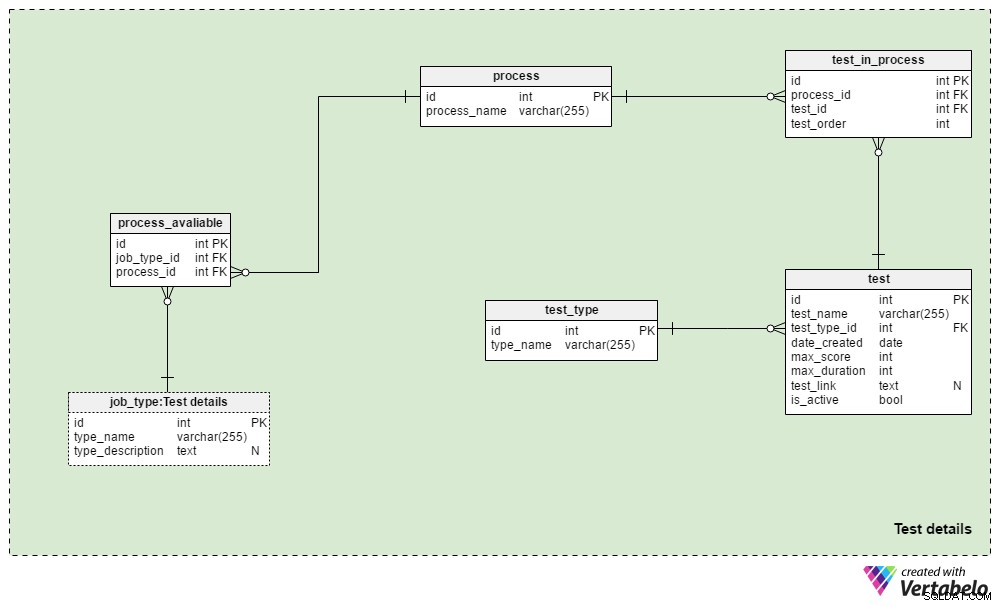
Test details předmětová oblast obsahuje tabulky používané k definování náborových procesů a testů používaných během těchto procesů. Obecně vždy použijeme stejný proces výběru pro stejný typ zakázky:změny se provádějí pouze tehdy, když to vyžadují obchodní okolnosti. Pro každý typ úlohy bychom mohli použít několik různých procesů a téměř jistě použijeme stejný proces pro různé typy úloh.
process table je jednoduchý slovník obsahující pouze UNIKÁTNÍ process_name atribut. Uvádí všechny náborové procesy, které jsme kdy použili a aktuálně používáme.
Propojíme procesy s různými typy úloh. Tyto vztahy uložíme do process_available stůl. Jeho jedinými atributy jsou UNIKÁTNÍ pár job_type_id – process_id . Pokud je pro určitý typ práce k dispozici více procesů, náborář si může vybrat jeden.
test_in_process Tabulka se používá k definování pořadí testů během tohoto procesu. Atributy v této tabulce jsou:
process_idatest_id– Odkazuje na související proces a test.test_order– Pořadové číslo tohoto testu nebo kroku v procesu. Společně sprocess_id, tvoří UNIKÁTNÍ klíč tabulky. Během procesu můžeme mít vždy pouze jeden krok.
test tabulka uvádí všechny aktuálně a dříve používané testy v náborovém procesu. Za testy budeme také považovat hodnocení životopisů a pohovory. Přestože nepotřebují definovat otázky a odpovědi, jsou součástí hodnocení. Pro každý test uložíme:
test_name– UNIKÁTNÍ označení pro každý test.test_type_id– Odkazuje natest_typeslovník.date_created– Datum, kdy jsme vytvořili tento test v našem systému.max_score– Maximální skóre dosažitelné pro tento test. Tato hodnota je součtem všech správných odpovědí v tomto testu nebo nejvyšší známky, kterou mohou náboráři udělit životopisu nebo pohovoru.max_duration– Jak dlouho (v minutách) má žadatel na vyplnění testu.test_link– Obsahuje odkaz na umístění testu. Tato hodnota může být NULL, pokud v procesu nepoužijeme test.is_active– Označuje, zda aktuálně používáme tento test.
test_type slovník. Obsahuje všechny UNIKÁTNÍ názvy testů podle formátu, např. „Kontrola životopisu“ , „online test dovedností“ , "papírový test dovedností" a „rozhovor“ .
Tento model nezahrnuje strukturu potřebnou k ukládání testovacích otázek a odpovědí. Spíše ukládá odkaz na místa, která tyto informace obsahují. Stejný design bude použit v Applications předmětová oblast.
Část 4:Aplikace
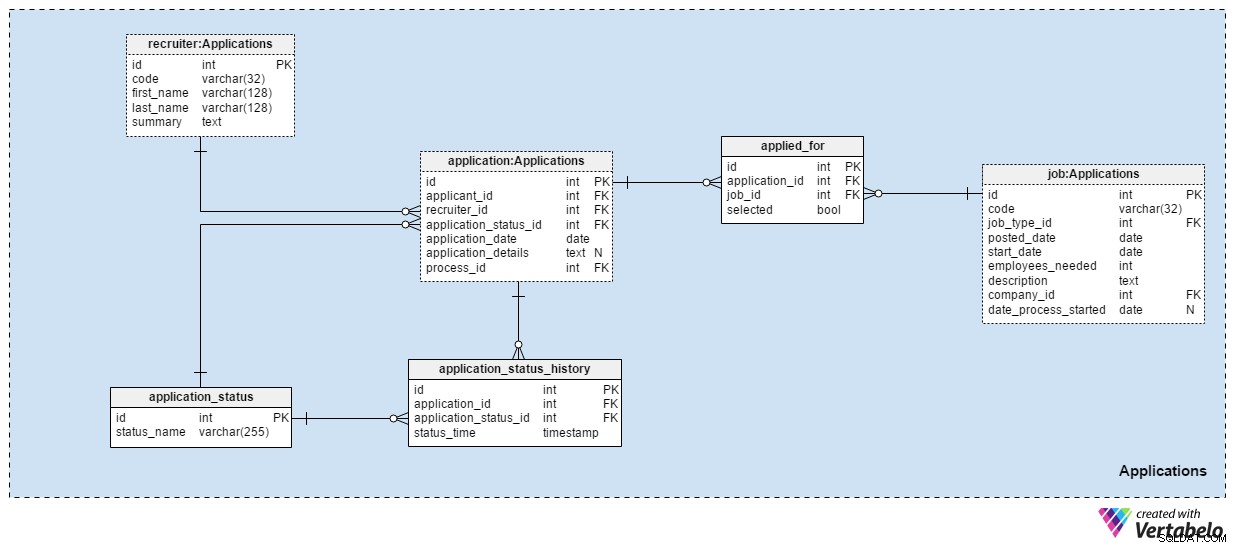
Applications předmětová oblast je pravděpodobně nejdůležitější v tomto datovém modelu. Všechny ostatní dosud uvedené tematické oblasti popisovaly aplikace. Tento ukládá skutečné věci.
Každá přihláška, kterou jsme kdy obdrželi, je zaznamenána v application stůl. U každé žádosti uložíme související ID žadatele, ID náborového pracovníka a odkaz na aktuální stav dané žádosti. Tento stav aktualizujeme současně s novým záznamem v application_status_history stůl. application_date atribut se používá k uložení příslušného data, zatímco všechny další podrobnosti jsou uloženy v textovém formátu. process_id atribut ukládá odkaz na proces vybraný pro danou aplikaci.
Stav aplikací se časem změní. Seznam všech stavů aplikací je uložen v application_status slovník. Jediný atribut je status_name a může obsahovat pouze UNIKÁTNÍ hodnoty. Očekávané hodnoty zahrnují:"použito" , "Životopis zkontrolován" , "vybráno pro test" , "zamítnuto po kontrole životopisu" , "prošel testem" , "pozván na pohovor" a "ukončeno žadatelem" .
Všechny stavy aplikací uložíme do application_status_history stůl. Tato tabulka obsahuje odkazy na application tabulka a application_status slovník. Uložíme také přesný status_time kdy byl aplikaci přidělen tento stav. application_id – status_time pár tvoří UNIKÁTNÍ klíč této tabulky.
Ve většině případů se uchazeč bude ucházet pouze o jednu pozici s jednou žádostí. Je možné, že se uchazeč bude ucházet o více pozic a my pro něj během výběrového řízení vybereme nejvhodnější roli. V applied_for tabulky, uložíme UNIKÁTNÍ pár application_id – job_id . Zaznamenáme také, zda byl selected žadatel související s touto aplikací pro tu pozici. Můžeme očekávat, že všechny selected hodnoty budou nastaveny na „False“ na začátku výběrového procesu a že aktualizujeme pouze jednu pro každou pracovní pozici na „True“ .
Část 5:Testy aplikací
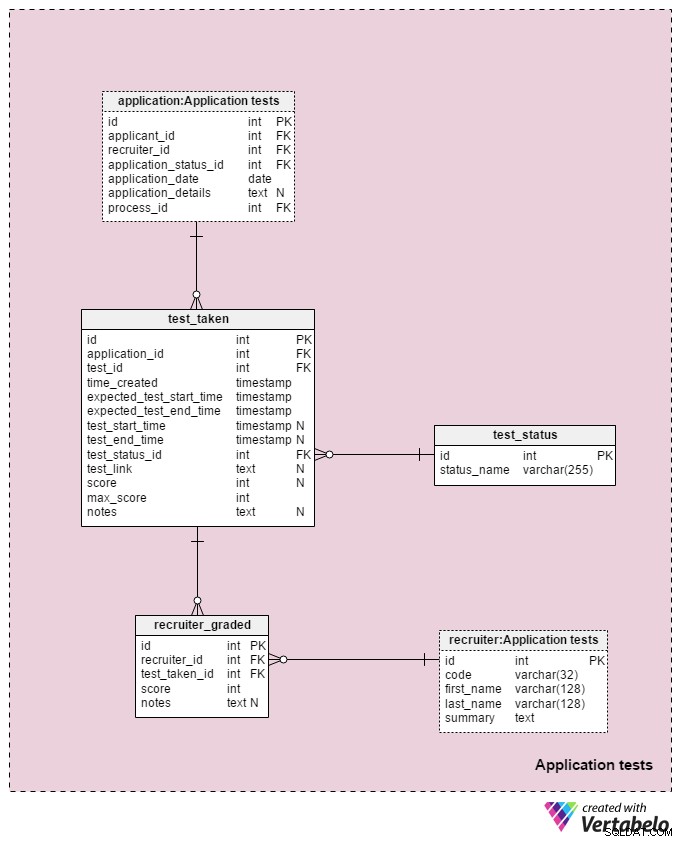
Poslední předmětová oblast v našem modelu bude použita k uložení výsledků každého testu provedeného během výběrového procesu. Dvě tabulky použité v této oblasti jsou kopiemi z jiných oblastí:application a recruiter . Jsou zde použity pro zjednodušení modelu.
Všechny podrobnosti související s každým testem jsou uloženy v test_taken stůl. Tato tabulka také obsahuje všechny další kroky v procesu, které lze ohodnotit, jako je kontrola životopisu. Atributy v této tabulce jsou:
application_id– Odkazuje naapplicationstůl. To souvisí s testem s žadatelem, který test absolvoval.test_id– Odkazuje natestkatalog. Můžeme také odkazovat natest_in_processtabulka zde, která by nám poskytla více informací o provedeném testu. Rozhodl jsem se ne, protože tato struktura nám poskytuje větší flexibilitu. (Např. pokud chceme žadatelům umožnit, aby test absolvovali dvakrát nebo mimo obvyklé časy).time_created– Skutečný čas, kdy jsme tento test vložili do našeho systému.expected_test_start_timeaexpected_test_end_time– Čas začátku a konce, jak bylo projednáno s žadatelem. Tyto hodnoty bychom mohli změnit v případě, že žadatel nebo náborář potřebuje test odložit.test_start_timeatest_end_time– Skutečné časy začátku a konce testu. Tyto budou obsahovat hodnoty NULL při vytvoření testu; hodnoty budou aktualizovány, když žadatel zahájí a ukončí tento test.test_status_id– Odkazuje natest_statusslovník.test_link– Odkazy na test s odpověďmi žadatele. Bude aktualizován, když žadatel odešle test.score– Skóre žadatele v tomto testu. To je stanoveno buď ručně náborovým pracovníkem (např. pro kontrolu životopisu), nebo automaticky (součet všech skóre testovaných položek). Může také obsahovat hodnotu NULL pro testy, které nejsou hodnoceny nebo hodnoceny na nějaké předem definované stupnici. Navíc test, který je naplánován, ale ještě není dokončen, může mít hodnotu NULL.max_score– Maximální dosažitelné skóre testu. Toto je stejné jako hodnota uložená vtest.”max_scoreatribut. Tuto hodnotu chci zachovat, protože náborář by mohl test během jeho zadávání upravit, a tak změnit maximální skóre, kterého by bylo možné dosáhnout.notes– Jakékoli další poznámky nebo poznámky zadané náborovými pracovníky ohledně tohoto konkrétního testu.
Kombinace test_id – application_id – expected_test_start_time atributy tvoří UNIKÁTNÍ klíč této tabulky. Před přidáním nové testovací relace bychom přesto měli zkontrolovat, zda se u souvisejícího žadatele a všech souvisejících náborových pracovníků nepřekrývají intervaly testování.
test_status slovník obsahuje seznam všech UNIKÁTNÍCH status_name které lze přiřadit k testu. Některé očekávané hodnoty zahrnují:"nezahájeno" , "probíhá" , "úspěšně dokončeno" , "dokončeno neúspěšně" , "odloženo" , "zrušeno" a "žadatel zrušen" .
Poslední tabulkou v našem modelu je recruiter_graded tabulka, která ukládá všechny známky, které náboráři dali při hodnocení každého testu. Proto budeme ukládat odkazy na recruiter a test_taken tabulky. Uložíme také score dosažené stejně jako všechny notes . Tyto informace jsou velmi důležité, zvláště když testy hodnotíme ručně (tj. pro hodnocení životopisů a pohovory).
Dnes jsme diskutovali o datovém modelu, který může pokrýt téměř jakoukoli situaci v procesu výběru a náboru – včetně neobvyklých výjimek.
Většina z nás má s tímto tématem nějaké zkušenosti. Podělte se prosím o své zkušenosti, když jste byli v roli náborového pracovníka nebo na druhé straně stolu. Pokrývá tento model situace, kterým jste čelili? Pokud ne, jaké změny byste navrhli?