Proč provedení dotazu trvá tak dlouho? Proč tam nejsou žádné indexy? Je pravděpodobné, že jste slyšeli o EXPLAIN v PostgreSQL. Stále však existuje mnoho lidí, kteří netuší, jak jej používat. Doufám, že tento článek pomůže uživatelům zvládnout tento skvělý nástroj.
Tento článek je autorskou revizí Understanding EXPLAIN od Guillaume Lelarge. Vzhledem k tomu, že jsem o některé informace přišel, vřele doporučuji seznámit se s originálem.
Ďábel není tak černý, jak je malován
Pro optimalizaci dotazů je důležité porozumět logice jádra PostgreSQL. pokusím se vysvětlit. Opravdu to není tak složité.
EXPLAIN zobrazí potřebné informace, které vysvětlují, co jádro dělá pro každý konkrétní dotaz.
Podívejme se, co příkaz EXPLAIN zobrazuje, a pochopíme, co se přesně děje uvnitř PostgreSQL. Tyto informace můžete použít na PostgreSQL 9.2 a vyšší verze.
Naše úkoly:
- Naučte se číst a porozumět výstupu příkazu EXPLAIN
- Pochopte, co se děje v PostgreSQL, když je spuštěn dotaz
První kroky
Budeme cvičit na testovacím stole s milionem řádků.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Zkuste si přečíst data
EXPLAIN SELECT * FROM foo;
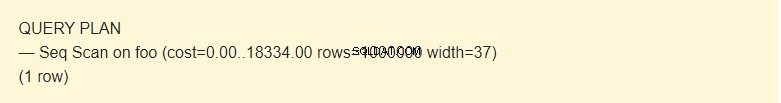
Data z tabulky je možné číst několika způsoby. V našem případě EXPLAIN upozorní, že se používá Seq Scan – sekvenční čtení dat Foo tabulky blok po bloku.
Co jsou náklady ?
Není to čas, ale koncept určený k odhadu nákladů na operaci. První hodnota 0,00 jsou náklady na získání prvního řádku. Druhá hodnota 18334,00 jsou náklady na získání všech řádků.
Řádky jsou přibližný počet řádků vrácených při provádění operace Seq Scan. Plánovač vrátí tuto hodnotu. V mém případě odpovídá skutečnému počtu řádků v tabulce.
Šířka je průměrná velikost jednoho řádku v bajtech.
Zkusme přidat 10 řádků.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Hodnota řádků se nezměnila. Statistika tabulky je stará. Chcete-li aktualizovat statistiku, zavolejte příkaz ANALYZE.
Nyní řádky zobrazí správný počet řádků.
Co se stane při spuštění ANALYZE?
- Náhodně se vybere a přečte z tabulky několik řádků.
- Shromažďují se statistiky hodnot podle každého sloupce.
Počet řádků, které ANALYZE přečte, závisí na parametru default_statistics_target.
Skutečné údaje
Vše, co jsme viděli výše ve výstupu příkazu EXPLAIN, plánovač očekává, že dostane. Zkusme je porovnat s výsledky na skutečných datech. K tomu použijte EXPLAIN (ANALYZE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Takový dotaz bude skutečně proveden. Pokud tedy provedete příkaz EXPLAIN (ANALYZE) pro příkazy INSERT, DELETE nebo UPDATE, vaše data se změní. Buď opatrný! V těchto případech použijte příkaz ROLLBACK.
Příkaz zobrazí následující dodatečné parametry:
- skutečný čas je skutečný čas v milisekundách strávený získáním prvního řádku a všech řádků.
- řádky je skutečný počet řádků přijatých pomocí Seq Scan.
- loops je počet, kolikrát bylo nutné provést operaci Seq Scan.
- Celková doba běhu je celková doba provádění dotazu.
Další čtení:
Optimalizace dotazů v PostgreSQL. Základy VYSVĚTLENÍ – Část 2
Optimalizace dotazů v PostgreSQL. Základy VYSVĚTLENÍ – Část 3