V mém předchozím článku jsme začali popisovat základy příkazu EXPLAIN a analyzovali, co se děje v PostgreSQL při provádění dotazu.
Budu pokračovat v psaní o základech EXPLAIN v PostgreSQL. Tato informace je krátká recenze Understanding EXPLAIN od Guillaume Lelarge. Vřele doporučuji přečíst si originál, protože některé informace chybí.
Mezipaměť
Co se stane na fyzické úrovni při provádění našeho dotazu? pojďme na to přijít. Nasadil jsem svůj server na Ubuntu 13.10 a používal diskové mezipaměti na úrovni OS.
Zastavím PostgreSQL, potvrdím změny v systému souborů, vymažem mezipaměť a spustím PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Po vymazání mezipaměti spusťte dotaz s možností BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Čteme tabulku po blocích. Mezipaměť je prázdná. Museli jsme zpřístupnit 8334 bloků, abychom mohli přečíst celou tabulku z disku.
Buffery:sdílené čtení je počet bloků, které PostgreSQL čte z disku.
Spusťte předchozí dotaz
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Vyrovnávací paměti:sdílený přístup je počet bloků načtených z mezipaměti PostgreSQL.
S každým dotazem PostgreSQL bere více a více dat z mezipaměti, čímž zaplňuje vlastní mezipaměť.
Operace čtení z mezipaměti jsou rychlejší než operace čtení disku. Tento trend můžete vidět sledováním celkové hodnoty za běhu.
Velikost mezipaměti je definována konstantou shared_buffers v souboru postgresql.conf.
KDE
Přidejte podmínku do dotazu
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Na stole nejsou žádné indexy. Při provádění dotazu je každý záznam tabulky prohledán sekvenčně (Seq Scan) a porovnán s podmínkou c1> 500. Pokud je podmínka splněna, záznam se přidá k výsledku. V opačném případě se zahodí. Filtr indikuje toto chování, stejně jako zvýšení hodnoty nákladů.
Odhadovaný počet řádků se sníží.
Původní článek vysvětluje, proč náklady nabývají této hodnoty a jak se počítá odhadovaný počet řádků.
Je čas vytvořit indexy.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Odhadovaný počet řádků se změnil. A co index?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Filtrováno je pouze 510 řádků s více než 1 milionem. PostgreSQL musel číst více než 99,9 % tabulky.
Vynutíme použití indexu vypnutím Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

V Index Scan a Index Cond se místo filtru používá index foo_c1_idx.
Při výběru celé tabulky použití indexu zvýší náklady a čas na provedení dotazu.
Povolit Seq Scan:
SET enable_seqscan TO on;
Upravte dotaz:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
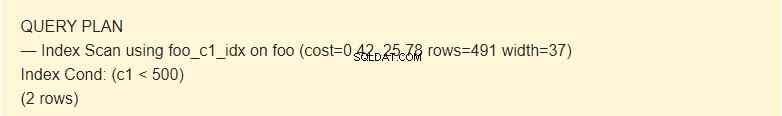
Zde plánovač používá index.
Nyní zkomplikujme hodnotu přidáním textového pole.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Jak můžete vidět, index foo_c1_idx se používá pro c1 <500. Chcete-li provést c2 ~~ ‘abcd%’::text, použijte filtr.
Je třeba poznamenat, že ve výstupu výsledků je použit formát POSIX operátoru LIKE. Pokud je v podmínce pouze textové pole:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Je použito Seq Scan.
Sestavte index podle c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Index není použit, protože moje databáze pro testovací pole používá kódování UTF-8.
Při sestavování indexu je nutné zadat třídu operátoru text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Skvělý! Povedlo se!
Bitmap Index Scan používá index foo_c2_idx1 k určení záznamů, které potřebujeme. Poté PostgreSQL přejde do tabulky (Bitmap Heap Scan), aby se ujistil, že tyto záznamy skutečně existují. Toto chování odkazuje na verzování PostgreSQL.
Pokud vyberete místo celého řádku pouze pole, na kterém je index postaven:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Index Only Scan bude proveden rychleji než Index Scan, protože není nutné číst řádek tabulky:width=4.
Závěr
- Seq Scan přečte celou tabulku
- Index Scan používá index pro příkazy WHERE a čte tabulku při výběru řádků.
- Bitmap Index Scan používá Index Scan a ovládání výběru pomocí tabulky. Efektivní pro velký počet řádků.
- Prohledávání pouze indexu je nejrychlejší blok, který čte pouze index.
Další čtení:
Optimalizace dotazů v PostgreSQL. Základy VYSVĚTLENÍ – Část 3