Pokračuji v sérii článků o základech EXPLAIN v PostgreSQL, což je krátká recenze Understanding EXPLAIN od Guillaume Lelarge.
Abyste problému lépe porozuměli, vřele doporučuji prostudovat si původní „Understanding EXPLAIN“ od Guillaume Lelarge a přečtěte si můj první a druhý článek.
OBJEDNAT PODLE
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Nejprve provedete sekvenční skenování (Seq Scan) tabulky foo a poté provedete třídění (Sort). Znak -> příkazu EXPLAIN označuje hierarchii kroků (uzel). Čím dříve je krok proveden, tím větší odsazení má.
Klíč řazení je podmínkou řazení.
Způsob řazení:externí sloučení Disk Při třídění se použije dočasný soubor na disku o kapacitě 4592 kB.
Zaškrtněte u možnosti VYROVNÁVACÍ PAMĚTI:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
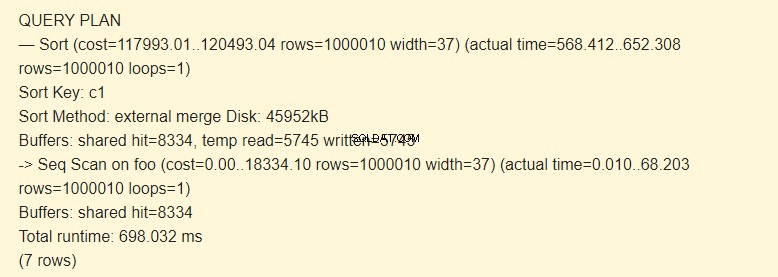
temp read=5745 write=5745 line skutečně znamená, že 45960Kb (5745 bloků po 8Kb každý) bylo uloženo a přečteno v dočasném souboru. Operace s 8334 bloky byly provedeny v mezipaměti.
Operace se souborovým systémem jsou pomalejší než operace v RAM.
Zkusme zvýšit kapacitu paměti work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Způsob řazení:quicksort Paměť:102702 kB – celé řazení bylo provedeno v RAM.
Index je následující:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Zůstal nám pouze Index Scan, který výrazně ovlivnil rychlost dotazu.
LIMIT
Odstraňte dříve vytvořený index:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Podle očekávání jsou použity Seq Scan a Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan čte řádky tabulky a porovnává je (Filtr) s podmínkou. Jakmile bude 10 záznamů splňovat podmínku, skenování se ukončí. V našem případě, abychom získali 10 výsledkových řádků, museli jsme číst pouze 3063 záznamů, nikoli celou tabulku. 3053 řádků z tohoto čísla bylo odmítnuto (řádky odstraněny filtrem).
Totéž se děje s indexovým skenováním.
PŘIPOJIT SE
Vytvořte novou tabulku a vygenerujte pro ni statistiky:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Dotaz na dvě tabulky je následující:
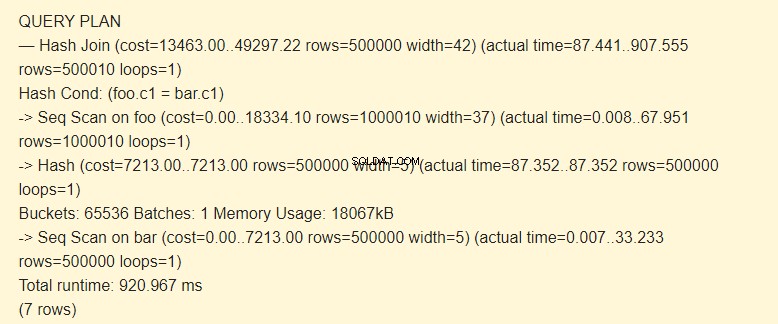
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Nejprve sekvenční skenování (Seq Scan) přečte tabulku sloupců. Pro každý řádek se vypočítá hash (Hash).
Poté prohledá tabulku foo a pro každý řádek se vypočítá hash, který se porovná (Hash Join) s hashem tabulky sloupců pomocí podmínky Hash Cond. Pokud se shodují, vypíše se výsledný řetězec.
18067 kB paměti se používá k ukládání hashů pro lištu.
Přidejte index:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Hash se již nepoužívá. Sloučení spojení a skenování indexů na indexech obou tabulek výrazně zvyšují výkon.
LEVÉ PŘIPOJENÍ:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
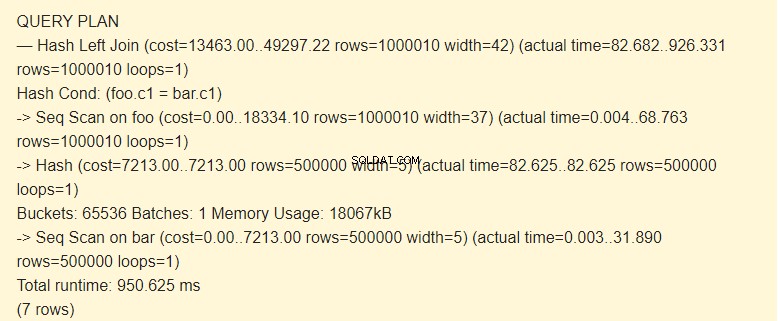
Seq Scan?
Podívejme se, jaký výsledek budeme mít, pokud deaktivujeme Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Podle plánovače je použití indexů nákladnější než použití hashů. To je možné s dostatečně velkým množstvím alokované paměti. Pamatujete si, že jsme zvýšili work_mem?
Pokud však nemáte dostatek paměti, plánovač se bude chovat jinak:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Pokud zakážeme Index Scan, jaký výsledek EXPLAIN zobrazí?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
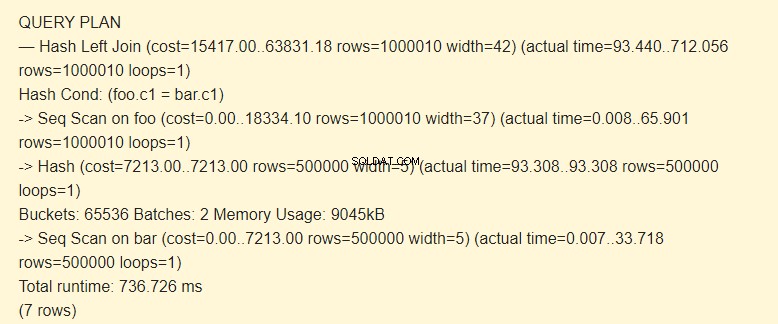
Dávky:2 má zvýšené náklady. Celý hash se nevešel do paměti; museli jsme to rozdělit do dvou balíčků po 9045 kB.
Děkuji, že čtete mé články! Doufám, že byly užitečné. Pokud máte nějaké připomínky nebo zpětnou vazbu, neváhejte mi dát vědět.