Moodle, open source Learning Management System, se v loňském roce stal stále populárnějším, protože si pandemie vynutila tvrdá uzamčení a většina vzdělávacích aktivit se přesunula ze škol, vysokých škol a univerzit na online platformy. Díky tomu byl na IT týmy vyvíjen tlak, aby zajistily, že tyto online platformy budou schopny pojmout mnohem vyšší zatížení, než jaké byly zvyklé. Byly vzneseny otázky – jak lze platformu Moodle škálovat, aby zvládla zvýšenou zátěž? Na jednu stranu není škálování samotné aplikace těžký úkol, ale databáze na druhou stranu je jiné zvíře. Databáze, stejně jako všechny stavové služby, je notoricky obtížné škálovat. V tomto příspěvku na blogu bychom rádi probrali některé problémy, kterým budete čelit při škálování databáze Moodle.
Škálování databáze Moodle – výzva
Hlavním zdrojem problémů je dědictví – Moodle, stejně jako mnoho databází, pochází z jedné databáze a jako takový přichází s určitými očekáváními, která s takovým prostředím souvisí. Typické je, že můžete provádět jednu transakci za druhou a druhá transakce vždy uvidí výsledek té první. To nemusí nutně platit ve většině prostředí distribuovaných databází. Asynchronní replikace nedává žádné sliby. Jakákoli transakce se může v procesu ztratit. Stačí, aby se master zhroutil, než se data transakce přenesou na podřízené jednotky. Semisynchronní replikace přináší příslib bezpečnosti dat, ale neslibuje nic jiného. Slave mohou stále zaostávat a i když jsou data uložena na trvalém úložišti jako přenosový protokol a nakonec budou aplikována na datovou sadu, stále to neznamená, že již byla použita. Můžete se dotazovat na své podřízené a nevidíte data, která jste právě zapsali do masteru.
Dokonce ani clustery, jako je Galera ve výchozím nastavení nepřicházejí se skutečně synchronní replikací – mezera je výrazně snížena ve srovnání s replikačními systémy, ale stále existuje a okamžitý SELECT provedený po předchozím zápisu nemusí vidět data, která jste právě uložili do databáze, protože váš SELECT byl směrován do jiného uzlu Galera než váš předchozí zápis.
Existuje několik řešení, která můžete použít ke škálování databáze Moodle MySQL. Pro začátek, pokud používáte nastavení replikace, můžete použít funkci „bezpečné čtení“ z Moodle. Popsali jsme to v jednom z našich předchozích blogů. To povede k situaci, kdy Moodle rozhodne, které zápisy budou distribuovány mezi podřízené jednotky a které zasáhnou master.
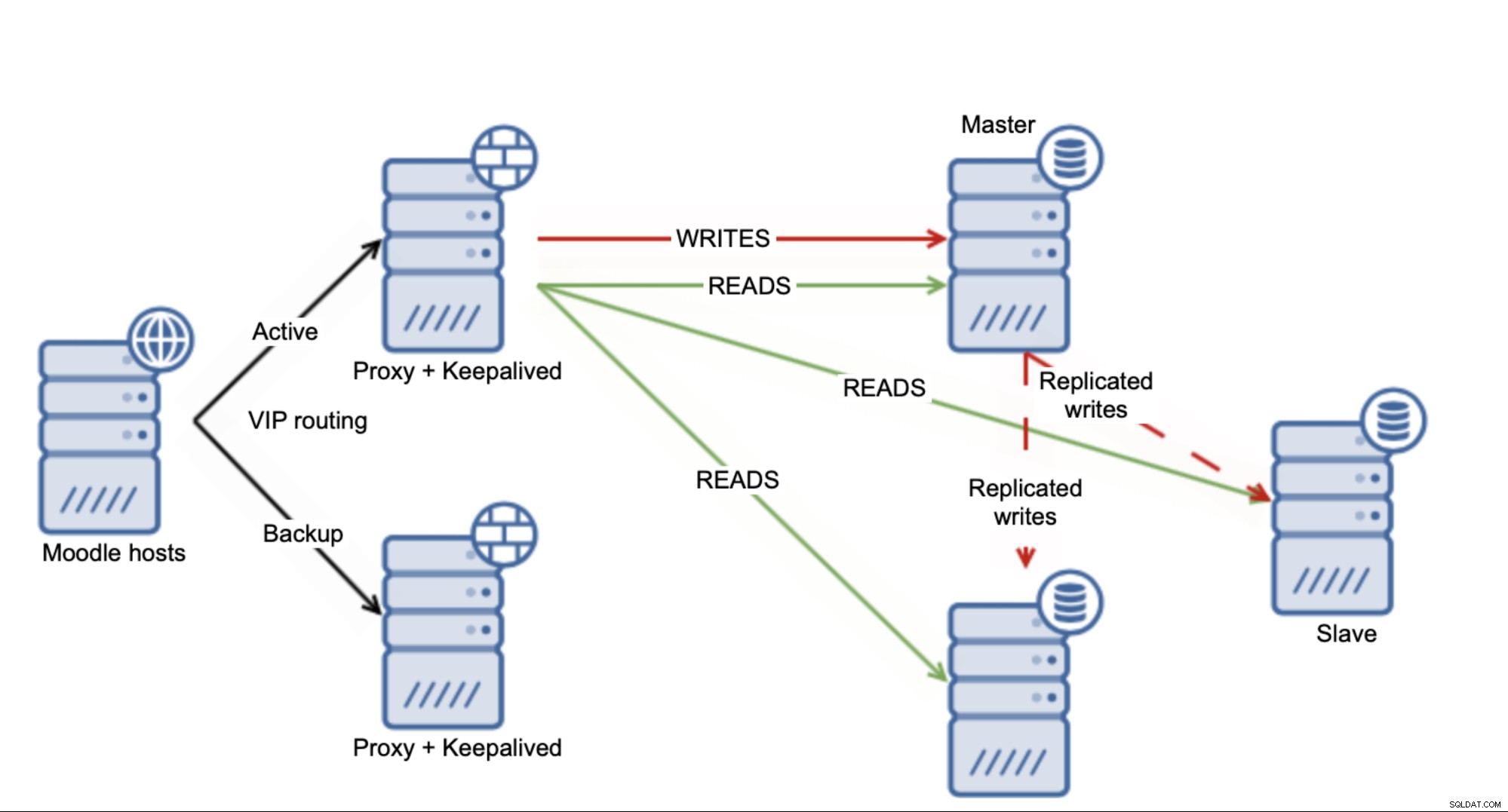
Na jednu stranu je to dobré – můžete bezpečně používat několik připojených otroků na master, což vám umožní alespoň do určité míry vyložit master. Na druhou stranu to má k ideálu daleko, protože jde jen o podmnožinu SELECTů, které budete moci posílat otrokům. Vše samozřejmě závisí na přesném případu, ale můžete očekávat, že hlavní bude i nadále překážkou ohledně zatížení.
Alternativním přístupem by mohlo být použití Galera Cluster a rozložení zátěže rovnoměrně mezi všechny uzly.
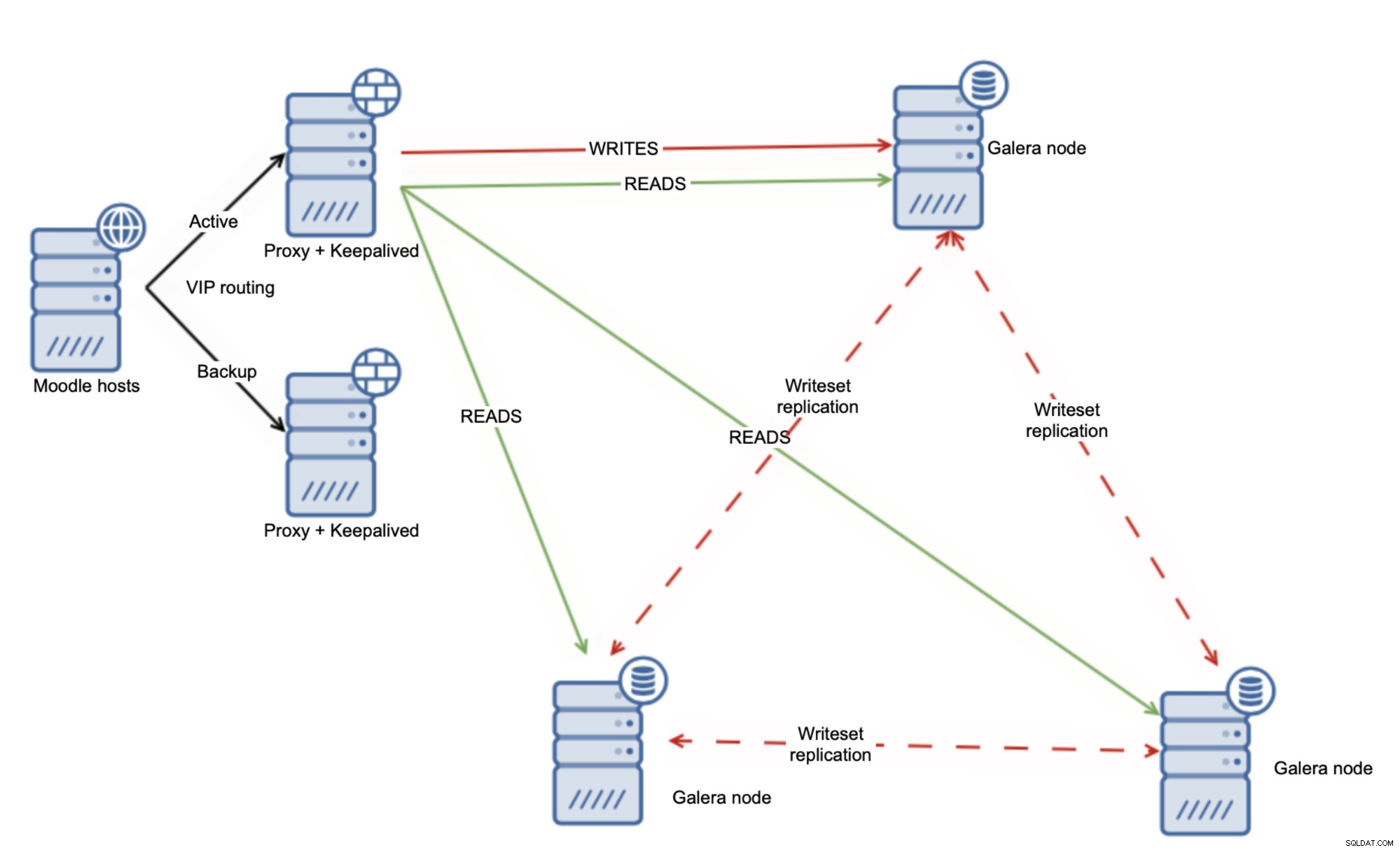
To samo o sobě nestačí ke zpracování veškerého přečteného -write problémy, ale naštěstí můžete použít proměnnou wsrep-sync-wait, kterou lze použít k zajištění toho, že kontroly kauzality jsou na místě a klastr se chová jako skutečný synchronní klastr. Použití tohoto nastavení vám umožní bezpečně číst ze všech vašich uzlů Galera.
Vynucování kontrol kauzality samozřejmě ovlivní výkon Galery, ale stále to dává smysl, protože můžete těžit ze čtení z více uzlů Galery současně. Od tohoto bodu je škálování čtení s Galera Clusterem docela snadné – stačí přidat více uzlů Galera do clusteru. Load Balancer by měl být překonfigurován tak, aby je sbíral a používal jako další cíl pro čtení, což vám umožní škálovat až na 10+ čtecích uzlů.
Musíte mít na paměti, že přidání dalších uzlů, replikace nebo Galera, na tom vlastně nezáleží, přidává operacím v clusteru určitou složitost. Musíte zajistit, že jsou vaše uzly správně monitorovány, že zálohy fungují, replikace probíhá správně a že samotný cluster je ve správném stavu. V replikačních prostředích musí být převzetí služeb při selhání řešeno tak či onak a pro Galera i replikaci možná budete chtít znovu sestavit uzly v klastru, pokud zjistíte jakýkoli druh nekonzistence dat v klastru. Naštěstí vám ClusterControl může výrazně pomoci zvládnout tyto výzvy.
Jak ClusterControl pomáhá spravovat klastr databáze Moodle MySQL
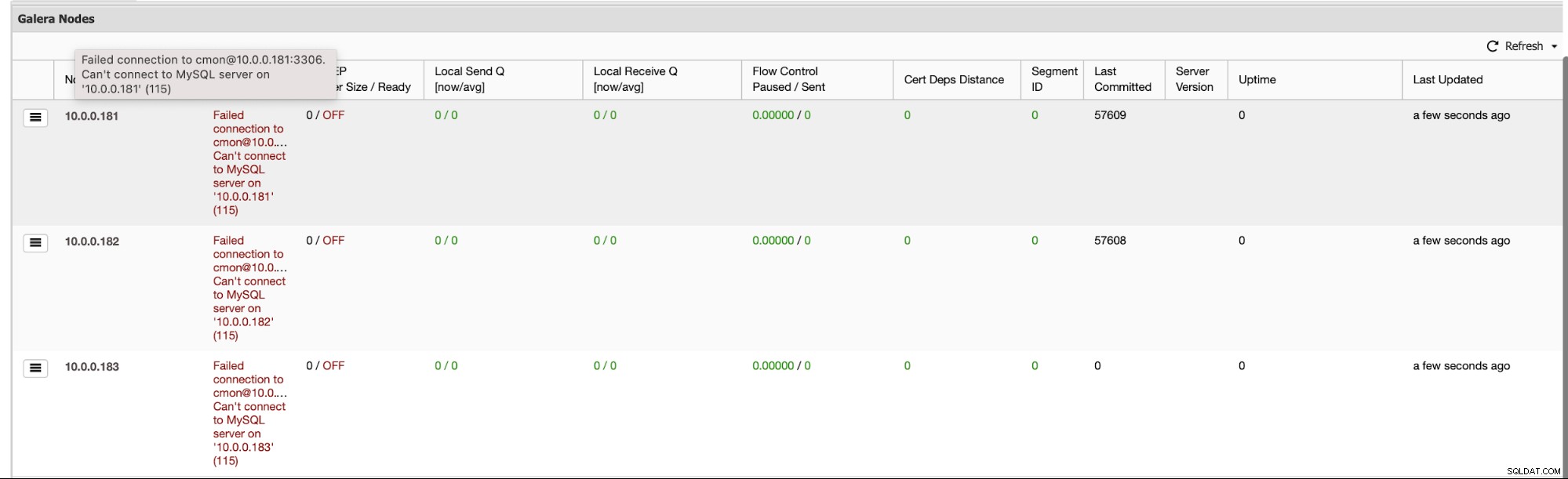
Za prvé, pokud se celý cluster zhroutí, ClusterControl provede automatické obnovení clusteru – dokud budou dostupné všechny uzly, zahájí ClusterControl proces obnovy clusteru:

Po chvíli by měl být celý cluster opět online.
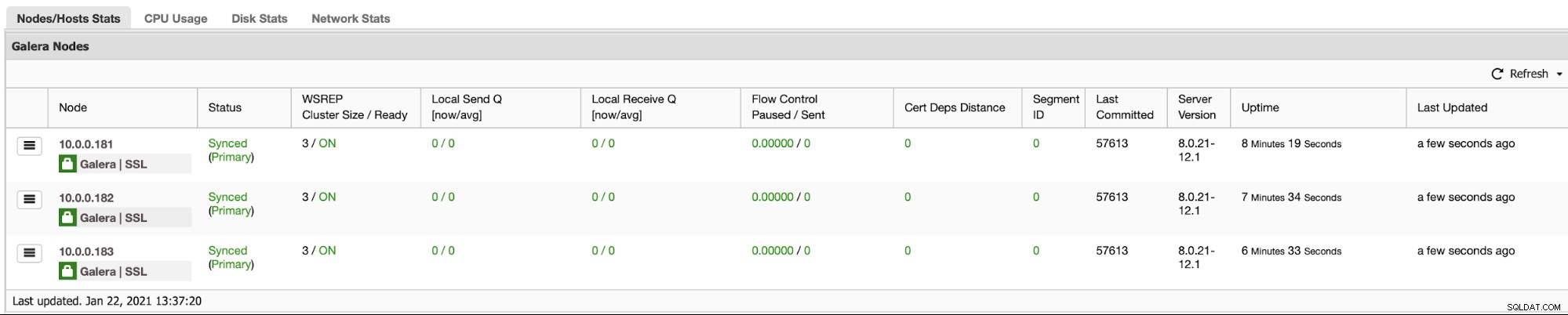
ClusterControl přichází se sadou možností správy:
Cluster můžete škálovat přidáním uzlů nebo replikačních podřízených jednotek. Můžete dokonce vytvořit celý podřízený cluster, který se bude replikovat mimo hlavní cluster.
Je možné snadno nastavit plán zálohování, který bude spuštěn ClusterControl. Můžete dokonce nastavit automatické ověřování záloh.
Pravděpodobně budete chtít monitorovat svůj databázový cluster. ClusterControl vám to umožňuje:
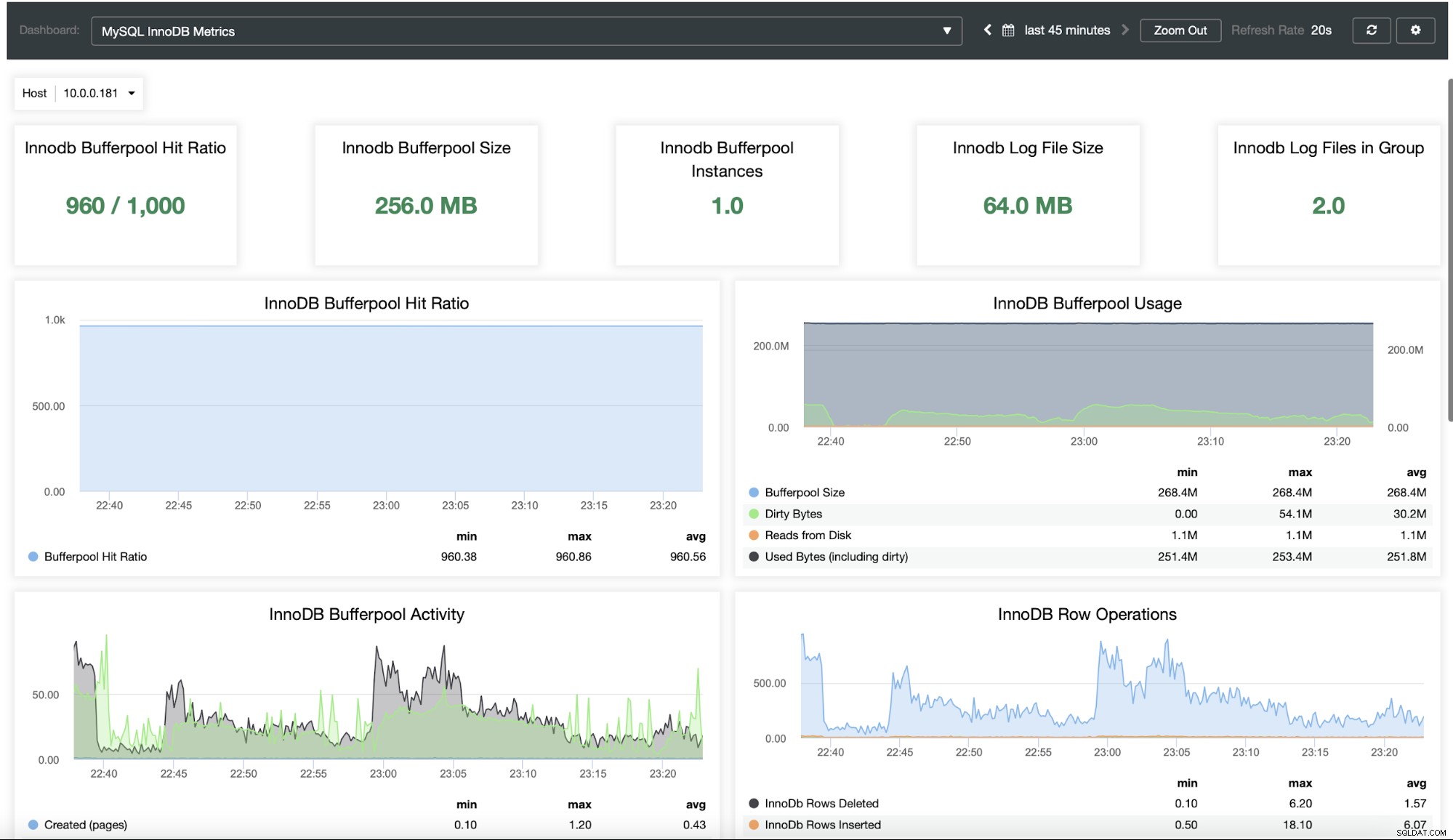
Jak můžete vidět, ClusterControl je skvělá platforma, kterou lze použít ke snížení složitosti škálování a správy databáze Moodle MySQL. Rádi bychom slyšeli o vašich zkušenostech s rozšiřováním Moodlu a zejména jeho databáze.