Když uživatelé požadují data ze systému, obvykle je chtějí vidět v určitém pořadí… i když vracejí tisíce řádků. Jak mnoho správců databází a vývojářů ví, ORDER BY může způsobit zmatek do plánu dotazů, protože vyžaduje třídění dat. To může někdy vyžadovat operátor SORT jako součást provádění dotazu, což může být nákladná operace, zejména pokud jsou odhady vypnuté a rozlije se na disk. V ideálním světě jsou data již tříděna díky indexu (indexy a řazení se velmi doplňují). Často mluvíme o vytvoření krycího indexu pro uspokojení dotazu – aby se optimalizátor nemusel vracet k základní tabulce nebo klastrovanému indexu, aby získal další sloupce. A možná jste slyšeli lidi říkat, že na pořadí sloupců v indexu záleží. Přemýšleli jste někdy o tom, jak to ovlivňuje vaše operace SORT?
Zkoumání ORDER BY a Sorts
Začneme s novou kopií databáze AdventureWorks2014 na instanci SQL Server 2014 (verze 12.0.2000). Pokud spustíme jednoduchý dotaz SELECT proti Sales.SalesOrderHeader bez ORDER BY, uvidíme prostý starý Clustered Index Scan (pomocí SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Dotaz bez ORDER BY, skenování seskupeného indexu
Dotaz bez ORDER BY, skenování seskupeného indexu
Nyní přidejte ORDER BY, abyste viděli, jak se plán změní:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
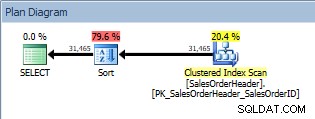 Dotaz pomocí příkazu ORDER BY, skenování seskupeného indexu a řazení
Dotaz pomocí příkazu ORDER BY, skenování seskupeného indexu a řazení
Kromě Clustered Index Scan nyní optimalizátor zavádí řazení, jehož odhadované náklady jsou výrazně vyšší než náklady na skenování. Nyní jsou odhadované náklady pouze odhadované a zde nemůžeme s naprostou jistotou říci, že řazení zabralo 79,6 % nákladů na dotaz. Abychom skutečně pochopili, jak drahé je řazení, museli bychom se také podívat na STATISTIKY IO, což je za dnešním cílem.
Pokud by se jednalo o dotaz, který byl ve vašem prostředí prováděn často, pravděpodobně byste zvážili přidání indexu na jeho podporu. V tomto případě neexistuje žádná klauzule WHERE, pouze načítáme čtyři sloupce a řadíme je podle jednoho z nich. Logický první pokus o index by byl:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Po přidání indexu, který má všechny požadované sloupce, spustíme náš dotaz znovu, a pamatujme, že index provedl práci, aby seřadil data. Nyní vidíme Index Scan proti našemu novému indexu bez klastrů:
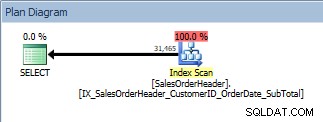 Dotaz pomocí příkazu ORDER BY, nový, neseskupený index je naskenován
Dotaz pomocí příkazu ORDER BY, nový, neseskupený index je naskenován
To je dobrá zpráva. Co se ale stane, když někdo tento dotaz pozmění – buď proto, že uživatelé mohou určit, podle kterých sloupců chtějí seřadit, nebo proto, že vývojář požadoval změnu? Uživatelé mohou například chtít vidět CustomerID a SalesOrderID v sestupném pořadí:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
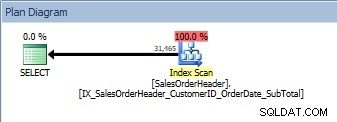 Dotaz se dvěma sloupci v ORDER BY, je naskenován nový, neseskupený index
Dotaz se dvěma sloupci v ORDER BY, je naskenován nový, neseskupený index
Máme stejný plán; nebyl přidán žádný operátor řazení. Pokud se podíváme na index pomocí sp_helpindex Kimberly Tripp (některé sloupce se sbalily, aby se ušetřilo místo), uvidíme, proč se plán nezměnil:
 Výstup sp_helpindex
Výstup sp_helpindex
Klíčový sloupec pro index je CustomerID, ale protože SalesOrderID je klíčový sloupec pro seskupený index, je také součástí klíče indexu, takže data jsou řazena podle CustomerID a poté SalesOrderID. Dotaz požadoval data seřazená podle těchto dvou sloupců v sestupném pořadí. Index byl vytvořen s oběma sloupci vzestupně, ale protože se jedná o dvojitě propojený seznam, lze index číst zpětně. Můžete to vidět v podokně Vlastnosti v Management Studio pro operátor skenování neklastrovaného indexu:
 Podokno vlastností skenování neshlukovaného indexu, které ukazuje, že to bylo obráceně
Podokno vlastností skenování neshlukovaného indexu, které ukazuje, že to bylo obráceně
Skvělé, s tímto dotazem nejsou žádné problémy...ale co tento:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
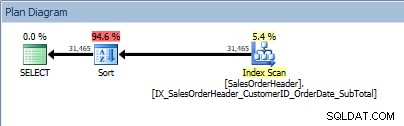 Dotaz se dvěma sloupci v ORDER BY a je přidáno řazení
Dotaz se dvěma sloupci v ORDER BY a je přidáno řazení
Znovu se objeví náš operátor SORT, protože data pocházející z indexu nejsou řazena v požadovaném pořadí. Stejné chování uvidíme, pokud třídíme podle jednoho ze zahrnutých sloupců:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
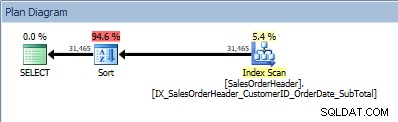 Dotaz se dvěma sloupci v ORDER BY a přidáním řazení
Dotaz se dvěma sloupci v ORDER BY a přidáním řazení
Co se stane, když (konečně) přidáme predikát a mírně změníme naše ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
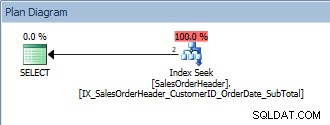 Dotaz s jedním predikátem a ORDER BY
Dotaz s jedním predikátem a ORDER BY
Tento dotaz je v pořádku, protože SalesOrderID je opět součástí indexového klíče. Pro toto jedno CustomerID jsou data již objednána podle SalesOrderID. Co když se dotazujeme na rozsah CustomerID seřazených podle SalesOrderID?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];;
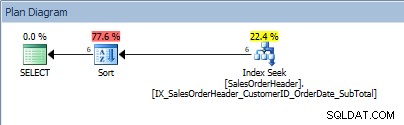 Dotaz s rozsahem hodnot v predikátu a ORDER BY
Dotaz s rozsahem hodnot v predikátu a ORDER BY
Krysy, náš SORT je zpět. Skutečnost, že data jsou uspořádána podle CustomerID, pomáhá pouze při hledání indexu k nalezení tohoto rozsahu hodnot; pro ORDER BY SalesOrderID musí optimalizátor vložit řazení, aby vložil data do požadovaného pořadí.
V tuto chvíli se možná divíte, proč jsem fixovaný na operátor Sort, který se objevuje v plánech dotazů. Je to proto, že je to drahé. Může to být drahé z hlediska zdrojů (paměť, IO) a/nebo doby trvání.
Trvání dotazu může být ovlivněno řazením, protože se jedná o operaci stop-and-go. Před další operací v plánu musí být setříděna celá sada dat. Pokud je třeba objednat pouze několik řádků dat, není to tak velký problém. Jestli jsou to tisíce nebo miliony řádků? Nyní čekáme.
Kromě celkové doby trvání dotazu musíme myslet také na využití zdrojů. Vezměme 31 465 řádků, se kterými jsme pracovali, a vložíme je do proměnné tabulky, poté spusťte tento počáteční dotaz s ORDER BY na CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
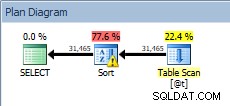 Dotaz na proměnnou tabulky s řazením
Dotaz na proměnnou tabulky s řazením
Náš SORT je zpět a tentokrát má varování (všimněte si žlutého trojúhelníku s vykřičníkem). Varování nejsou dobrá. Pokud se podíváme na vlastnosti řazení, můžeme vidět varování:"Operátor použil tempdb k úniku dat během provádění s úrovní úniku 1":
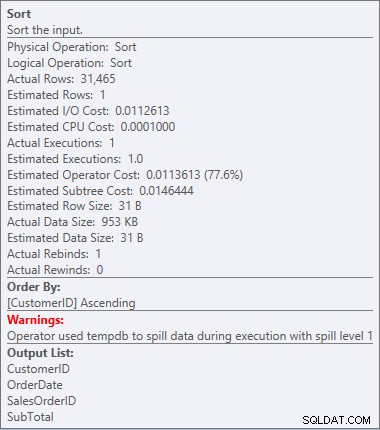 Upozornění na řazení
Upozornění na řazení
Tohle není něco, co bych chtěl vidět v plánu. Optimalizátor odhadl, kolik místa by potřeboval v paměti k třídění dat, a tuto paměť si vyžádal. Ale když ve skutečnosti měl všechna data a šel je třídit, engine si uvědomil, že není dostatek paměti (optimalizátor požadoval příliš málo!), takže operace Sort se rozlila. V některých případech se to může přenést na disk, což znamená, že čtení a zápisy jsou pomalé. Nejen, že čekáme jen na to, abychom si dali data do pořádku, je to ještě pomalejší, protože to všechno nestihneme v paměti. Proč optimalizátor nepožádal o dostatek paměti? Měl špatný odhad ohledně dat, která potřebovala seřadit:
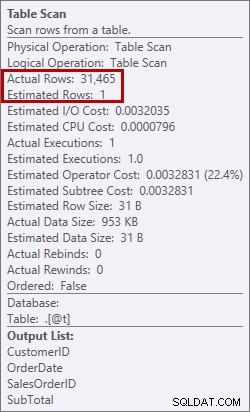 Odhad 1 řádku versus skutečných 31 465 řádků
Odhad 1 řádku versus skutečných 31 465 řádků
V tomto případě jsem si vynutil špatný odhad použitím proměnné tabulky. Existují známé problémy s odhady statistik a proměnnými tabulek (Aaron Bertrand má skvělý příspěvek o možnostech, jak se to pokusit vyřešit), a zde se optimalizátor domníval, že ze skenování tabulky se vrátí pouze 1 řádek, nikoli 31 465.
Možnosti
Co tedy můžete jako DBA nebo vývojář udělat, abyste se vyhnuli SORT ve svých plánech dotazů? Rychlá odpověď zní:"Neobjednávejte si svá data." Ale to není vždy reálné. V některých případech můžete toto třídění přesunout na klienta nebo na aplikační vrstvu – ale uživatelé musí stále čekat na seřazení dat v tam vrstva. V situacích, kdy nemůžete změnit, jak aplikace funguje, můžete začít tím, že se podíváte na své indexy.
Pokud podporujete aplikaci, která uživatelům umožňuje spouštět ad-hoc dotazy nebo změnit pořadí řazení, aby viděli data seřazená tak, jak chtějí... budete to mít nejtěžší (ale není to ztracený případ, takže ještě nepřestávej číst!). Nemůžete indexovat pro každou možnost. Je to neefektivní a více problémů vytvoříte, než vyřešíte. Nejlepším řešením je promluvit si s uživateli (já vím, někdy je děsivé opustit svůj kout lesa, ale zkuste to). U dotazů, které uživatelé zadávají nejčastěji, zjistěte, jak obvykle chtějí data zobrazit. Ano, můžete to získat také z mezipaměti plánů – můžete načítat dotazy a plány, dokud vás nenapadne, abyste viděli, co dělají. Rychlejší je ale mluvit s uživateli. Další výhodou je, že můžete vysvětlit, proč se ptáte a proč není nápad „řadit podle všech sloupců, protože mohu“ tak dobrý. Vědět je polovina úspěchu. Pokud můžete strávit nějaký čas vzděláváním svých zkušených uživatelů a uživatelů, kteří školí nové lidi, možná budete schopni udělat něco dobrého.
Pokud podporujete aplikaci s omezenými možnostmi ORDER BY, můžete provést skutečnou analýzu. Zkontrolujte, jaké varianty ORDER BY existují, určete, které kombinace se spouštějí nejčastěji, a indexujte, aby tyto dotazy podporovaly. Pravděpodobně nezasáhnete každého, ale přesto můžete zapůsobit. Můžete to udělat ještě o krok dále tím, že si promluvíte se svými vývojáři a poučíte je o problému a o tom, jak jej řešit.
A konečně, když se díváte na plány dotazů s operacemi SORT, nezaměřujte se pouze na odstranění řazení. Podívejte se kde řazení se vyskytuje v plánu. Pokud se to stane nalevo od plánu a je to obvykle několik řádků, mohou existovat další oblasti s větším faktorem zlepšení, na které je třeba se zaměřit. Třídění nalevo je vzor, na který jsme se dnes zaměřili, ale ne vždy dochází k řazení kvůli ORDER BY. Pokud zcela vpravo na plánu vidíte řazení a touto částí plánu se pohybuje mnoho řádků, víte, že jste našli dobré místo, kde začít ladit.