Ve svém posledním příspěvku jsem ukázal některé účinné přístupy ke skupinovému zřetězení. Tentokrát jsem chtěl mluvit o několika dalších aspektech tohoto problému, které můžeme snadno provést pomocí FOR XML PATH přístup:seřazení seznamu a odstranění duplikátů.
Existuje několik způsobů, jak jsem viděl, že lidé chtějí seřadit seznam oddělený čárkami. Někdy chtějí, aby byla položka v seznamu řazena abecedně; Už jsem to ukázal ve svém předchozím příspěvku. Ale někdy to chtějí seřadit podle nějakého jiného atributu, který ve skutečnosti není uveden ve výstupu; například chci nejprve seřadit seznam podle nejnovější položky. Vezměme si jednoduchý příklad, kde máme tabulku Zaměstnanci a tabulku CoffeeOrders. Pojďme na několik dní vyplnit objednávky jedné osoby:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Pokud použijeme stávající přístup bez zadání ORDER BY , dostaneme libovolné pořadí (v tomto případě je to pravděpodobně tak, že řádky uvidíte v pořadí, v jakém byly vloženy, ale nespoléhejte se na to u větších datových sad, více indexů atd.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Výsledky (nezapomeňte, že můžete získat *odlišné* výsledky, pokud nezadáte ORDER BY ):
Jack | Large double double, Medium double double, Large Vanilla Latte, Medium double double
Pokud chceme seznam seřadit abecedně, je to jednoduché; jen přidáme ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Výsledky:
Jméno | ObjednávkyJack | Large double double, Large Vanilla Latte, Medium double double, Medium double double
Můžeme také seřadit podle sloupce, který se ve výsledkové sadě nevyskytuje; například můžeme objednávat podle poslední objednávky kávy jako první:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Výsledky:
Jméno | ObjednávkyJack | Medium double double, Large Vanilla Latte, Medium double double, Large double double
Další věc, kterou často chceme udělat, je odstranit duplikáty; koneckonců není důvod vidět „Medium double double“ dvakrát. Můžeme to eliminovat pomocí GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Nyní se *stane* seřadit výstup abecedně, ale opět se na to nemůžete spolehnout:
Jméno | ObjednávkyJack | Large double double, Large Vanilla Latte, Medium double double
Pokud chcete zaručit, že objednání tímto způsobem, můžete jednoduše přidat znovu OBJEDNÁVKU:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Výsledky jsou stejné (ale budu se opakovat, v tomto případě je to jen náhoda; pokud chcete toto pořadí, vždy to řekněte):
Jméno | ObjednávkyJack | Large double double, Large Vanilla Latte, Medium double double
Ale co když chceme odstranit duplikáty *a* nejprve seřadit seznam podle poslední objednávky kávy? Vaším prvním sklonem může být ponechat GROUP BY a stačí změnit ORDER BY , takto:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
To nebude fungovat, protože OrderDate není seskupen ani agregován jako součást dotazu:
Sloupec "dbo.CoffeeOrders.OrderDate" je neplatný v klauzuli ORDER BY, protože není obsažen ani v agregační funkci, ani v klauzuli GROUP BY.
Řešením, které nepochybně dělá dotaz trochu ošklivějším, je nejprve seskupit objednávky odděleně a poté vzít pouze řádky s maximálním datem pro danou objednávku kávy na zaměstnance:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Výsledky:
Jméno | ObjednávkyJack | Medium double double, Large Vanilla Latte, Large double double
Tím jsme splnili oba naše cíle:odstranili jsme duplikáty a seřadili jsme seznam podle něčeho, co v seznamu ve skutečnosti není.
Výkon
Možná se divíte, jak špatně si tyto metody vedou proti robustnějšímu souboru dat. Naplním naši tabulku 100 000 řádky, podívám se, jak si vedou bez jakýchkoli dalších indexů, a pak znovu spustím stejné dotazy s trochou ladění indexu, abychom podpořili naše dotazy. Nejprve tedy získání 100 000 řádků rozložených mezi 1 000 zaměstnanců:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Nyní spusťte každý z našich dotazů dvakrát a na druhý pokus se podívejme, jaké je načasování (zde uděláme skok důvěry a předpokládejme, že – v ideálním světě – budeme pracovat s primovanou mezipamětí ). Spustil jsem je v SQL Sentry Plan Explorer, protože je to nejjednodušší způsob, který znám, a porovnat spoustu jednotlivých dotazů:
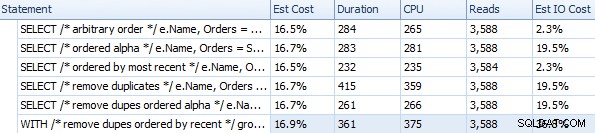 Délka a další metriky doby běhu pro různé přístupy FOR XML PATH
Délka a další metriky doby běhu pro různé přístupy FOR XML PATH
Tyto časování (trvání je v milisekundách) opravdu nejsou IMHO vůbec tak špatné, když se zamyslíte nad tím, co se tu vlastně dělá. Nejsložitější plán, alespoň vizuálně, se zdál být ten, kde jsme odstranili duplikáty a seřadili je podle poslední objednávky:
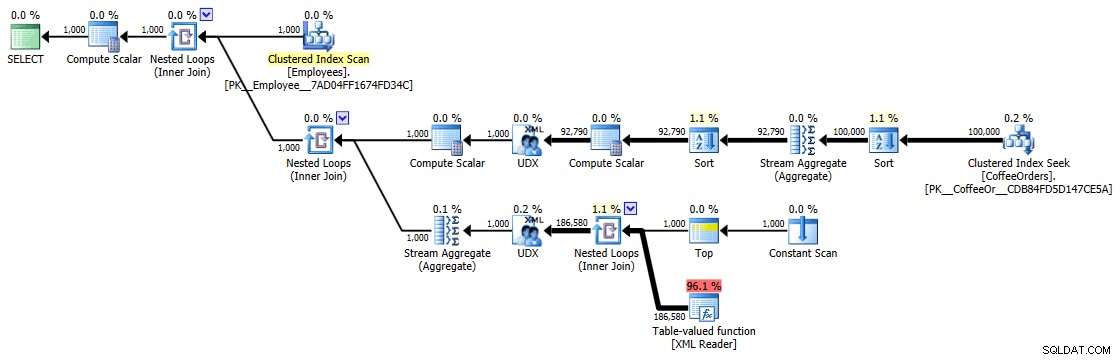 Plán provádění pro seskupený a seřazený dotaz
Plán provádění pro seskupený a seřazený dotaz
Ale i ten nejdražší operátor zde – funkce s hodnotou tabulky XML – se zdá být celý CPU (i když přiznám, že si nejsem jistý, kolik skutečné práce je odhaleno v detailech plánu dotazů):
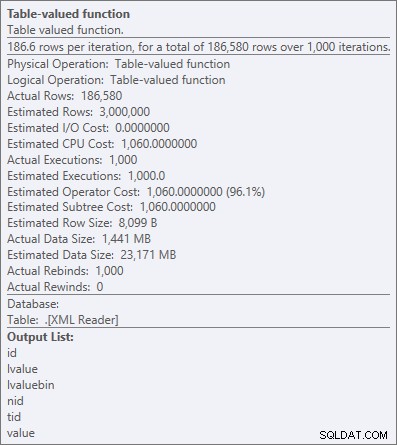 Vlastnosti operátora pro funkci s hodnotou tabulky XML
Vlastnosti operátora pro funkci s hodnotou tabulky XML
"Všechny CPU" je obvykle v pořádku, protože většina systémů je vázána I/O a/nebo pamětí, nikoli CPU. Jak říkám docela často, ve většině systémů vyměním část své kapacity CPU za paměť nebo disk kterýkoli den v týdnu (jeden z důvodů, proč se mi líbí OPTION (RECOMPILE) jako řešení všudypřítomných problémů s čicháním parametrů).
To znamená, že vám důrazně doporučuji otestovat tyto přístupy proti podobným výsledkům, které můžete získat z přístupu GROUP_CONCAT CLR na CodePlex, stejně jako provádění agregace a třídění na úrovni prezentace (zejména pokud uchováváte normalizovaná data v nějakém vrstvě mezipaměti).