Stránkování je běžným případem použití v klientských a webových aplikacích kdekoli. Google vám zobrazí 10 výsledků najednou, vaše online banka může zobrazit 20 účtů na stránku a software pro sledování chyb a kontrolu zdroje může na obrazovce zobrazit 50 položek.
Chtěl jsem se podívat na běžný přístup k stránkování na SQL Server 2012 – OFFSET / FETCH (standardní ekvivalent k prioprietární klauzuli LIMIT v MySQL) – a navrhnout variantu, která povede k lineárnějšímu výkonu stránkování v celé sadě, místo aby byla pouze optimální. na začátku. Což je bohužel vše, co bude testovat mnoho obchodů.
Co je stránkování na serveru SQL?
Na základě indexování tabulky, potřebných sloupců a zvolené metody řazení může být stránkování relativně bezbolestné. Pokud hledáte „prvních“ 20 zákazníků a seskupený index toto řazení podporuje (řekněme seskupený index ve sloupci IDENTITY nebo DateCreated), bude dotaz relativně efektivní. Pokud potřebujete podporovat řazení, které vyžaduje indexy bez klastrů, a zejména pokud máte sloupce potřebné pro výstup, které nejsou pokryty indexem (nevadí, pokud neexistuje žádný podpůrný index), mohou být dotazy dražší. A dokonce i stejný dotaz (s jiným parametrem @PageNumber) může být mnohem dražší, protože @PageNumber se zvyšuje – protože k získání tohoto „části“ dat může být zapotřebí více čtení.
Někteří řeknou, že postup ke konci sady je něco, co můžete vyřešit tím, že na problém hodíte více paměti (takže odstraníte jakýkoli fyzický I/O) a/nebo použijete mezipaměť na úrovni aplikace (takže nebudete databáze vůbec). Předpokládejme pro účely tohoto příspěvku, že více paměti není vždy možné, protože ne každý zákazník může přidat RAM na server, který nemá paměťové sloty nebo jej nemá pod kontrolou, nebo jen lusknout prsty a mít připraveny novější, větší servery. jít. Zejména proto, že někteří zákazníci používají Standard Edition, takže jsou omezeni na 64 GB (SQL Server 2012) nebo 128 GB (SQL Server 2014), nebo používají ještě omezenější edice, jako je Express (1 GB) nebo jednu z mnoha cloudových nabídek.
Chtěl jsem se tedy podívat na běžný přístup k stránkování na SQL Server 2012 – OFFSET / FETCH – a navrhnout variantu, která povede k lineárnějšímu výkonu stránkování v celé sadě, místo aby byla optimální pouze na začátku. Což je bohužel vše, co bude testovat mnoho obchodů.
Nastavení / příklad dat stránkování
Půjčím si z jiného příspěvku, Špatné návyky :Zaměření pouze na místo na disku při výběru klíčů, kde jsem naplnil následující tabulku 1 000 000 řádky náhodných (ale ne zcela realistických) zákaznických dat:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Protože jsem věděl, že zde budu testovat I/O a budu testovat z teplé i studené mezipaměti, udělal jsem test alespoň trochu spravedlivější tím, že jsem přestavěl všechny indexy, aby se minimalizovala fragmentace (což by se dělalo méně rušivě, ale pravidelně na většině vytížených systémů, které provádějí jakýkoli typ údržby indexu):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Po opětovném sestavení nyní přichází fragmentace na 0,05 % – 0,17 % pro všechny indexy (úroveň indexu =0), stránky jsou naplněny z více než 99 % a počet řádků / počet stránek pro indexy je následující:
| Index | Počet stránek | Počet řádků |
|---|---|---|
| C_PK_Customers_I (sdružený index) | 19 210 | 1 000 000 |
| C_Email_Customers_I | 7 344 | 1 000 000 |
| C_Active_Customers_I (filtrovaný index) | 13 648 | 815 235 |
| C_Name_Customers_I | 16 824 | 1 000 000 |
Indexy, počty stránek, počty řádků
Toto zjevně není superširoká tabulka a tentokrát jsem z obrázku vynechal kompresi. Možná prozkoumám více konfigurací v budoucím testu.
Jak efektivně stránkovat SQL dotaz
Koncept stránkování – zobrazení uživateli pouze řádků najednou – je snazší si představit, než vysvětlit. Vzpomeňte si na rejstřík fyzické knihy, který může mít více stránek odkazů na body v knize, ale uspořádaných podle abecedy. Pro zjednodušení řekněme, že se na každou stránku rejstříku vejde deset položek. Může to vypadat takto:
Nyní, pokud jsem již přečetl stránky 1 a 2 rejstříku, vím, že abych se dostal na stránku 3, musím přeskočit 2 stránky. Ale protože vím, že na každé stránce je 10 položek, mohu si to představit i jako přeskočení 2 x 10 položek a začít od 21. položky. Nebo, abych to řekl jinak, musím přeskočit prvních (10*(3-1)) položek. Aby to bylo obecnější, mohu říci, že pro začátek na stránce n musím přeskočit prvních (10 * (n-1)) položek. Abych se dostal na první stránku, přeskočím 10*(1-1) položek, abych skončil na položce 1. Abych se dostal na druhou stránku, přeskočím 10*(2-1) položek, abych skončil na položce 11. A tak zapnuto.
S těmito informacemi budou uživatelé formulovat stránkovací dotaz, jako je tento, protože klauzule OFFSET / FETCH přidané v SQL Server 2012 byly speciálně navrženy tak, aby přeskočily tolik řádků:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Jak jsem uvedl výše, funguje to dobře, pokud existuje index, který podporuje ORDER BY a který pokrývá všechny sloupce v klauzuli SELECT (a u složitějších dotazů klauzule WHERE a JOIN). Náklady na řazení však mohou být ohromující bez podpůrného indexu, a pokud nejsou pokryty výstupní sloupce, skončíte buď s celou řadou vyhledávání klíčů, nebo v některých scénářích můžete dokonce získat skenování tabulky.
Osvědčené postupy třídění stránkování SQL
Vzhledem k výše uvedené tabulce a indexům jsem chtěl otestovat tyto scénáře, kde chceme zobrazit 100 řádků na stránku a vypsat všechny sloupce v tabulce:
- Výchozí –
ORDER BY CustomerID(shlukovaný index). Toto je nejpohodlnější uspořádání pro lidi z databáze, protože nevyžaduje žádné další třídění a jsou zahrnuta všechna data z této tabulky, která by mohla být potřebná pro zobrazení. Na druhou stranu to nemusí být nejúčinnější index, který lze použít, pokud zobrazujete podmnožinu tabulky. Objednávka také nemusí dávat smysl koncovým uživatelům, zvláště pokud je CustomerID zástupný identifikátor bez vnějšího významu. - Telefonní seznam –
ORDER BY LastName, FirstName(podporující neklastrovaný index). Toto je nejintuitivnější řazení pro uživatele, ale vyžadovalo by to neshlukovaný index pro podporu řazení i pokrytí. Bez podpůrného indexu by musela být naskenována celá tabulka. - Definováno uživatelem –
ORDER BY FirstName DESC, EMail(žádný podpůrný index). To představuje možnost pro uživatele vybrat si libovolné pořadí řazení, které si přeje, což je vzor, před kterým Michael J. Swart varuje v „Návrhové vzory uživatelského rozhraní, které se neškálují.“
Chtěl jsem otestovat tyto metody a porovnat plány a metriky, když se podívám na stránku 1, stránku 500, stránku 5 000 a stránku 9 999 – v rámci scénářů teplé i studené mezipaměti. Vytvořil jsem tyto procedury (liší se pouze klauzulí ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail Ve skutečnosti budete mít pravděpodobně jen jednu proceduru, která buď používá dynamické SQL (jako v mém příkladu „kuchyňského dřezu“) nebo výraz CASE k diktování objednávky.
V obou případech můžete zaznamenat nejlepší výsledky pomocí OPTION (RECOMPILE) v dotazu, abyste se vyhnuli opětovnému použití plánů, které jsou optimální pro jednu možnost řazení, ale ne pro všechny. Vytvořil jsem zde samostatné procedury, abych tyto proměnné odstranil; Pro tyto testy jsem přidal OPTION (RECOMPILE), abych se vyhnul sniffování parametrů a dalším problémům s optimalizací, aniž by bylo nutné opakovaně proplachovat celou mezipaměť plánu.
Alternativní přístup k stránkování serveru SQL pro lepší výkon
Trochu odlišný přístup, který nevidím implementován příliš často, je najít „stránku“, na které se nacházíme, pomocí pouze shlukovacího klíče a poté se k ní připojit:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Je to samozřejmě podrobnější kód, ale doufejme, že je jasné, k čemu lze SQL Server donutit:vyhnout se skenování nebo alespoň odložit vyhledávání, dokud nebude zmenšena mnohem menší sada výsledků. Paul White (@SQL_Kiwi) zkoumal podobný přístup již v roce 2010, předtím, než byl OFFSET/FETCH představen v raných beta verzích SQL Server 2012 (poprvé jsem o tom psal později v tomto roce).
Vzhledem k výše uvedeným scénářům jsem vytvořil tři další procedury, s jediným rozdílem mezi sloupci specifikovanými v klauzuli ORDER BY (nyní potřebujeme dva, jeden pro samotnou stránku a jeden pro uspořádání výsledku):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Poznámka:Toto nemusí fungovat tak dobře, pokud váš primární klíč není klastrovaný – součástí triku, díky kterému to funguje lépe, když lze použít podpůrný index, je to, že klastrovací klíč je již v indexu, takže vyhledávání se často vyhýbá.
Testování řazení klíčů shlukování
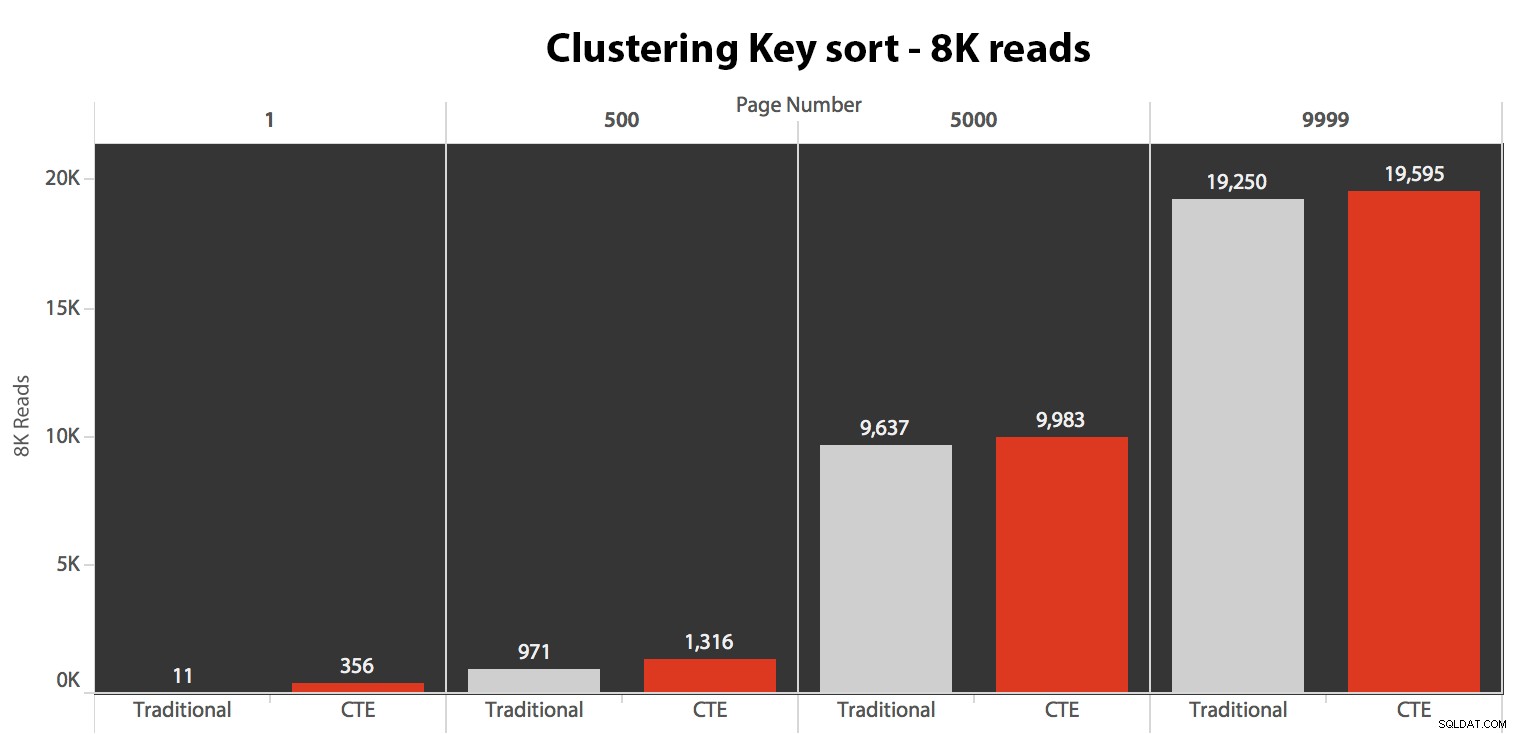
Nejprve jsem testoval případ, kdy jsem neočekával velký rozptyl mezi oběma metodami – řazení podle shlukovacího klíče. Spustil jsem tyto příkazy v dávce v SQL Sentry Plan Explorer a pozoroval jsem trvání, čtení a grafické plány, přičemž jsem se ujistil, že každý dotaz začínal z úplně studené mezipaměti:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
Výsledky zde nebyly ohromující. Více než 5 spuštění je zde zobrazen průměrný počet přečtení, který ukazuje zanedbatelné rozdíly mezi dvěma dotazy, napříč všemi čísly stránek, při řazení podle shlukovacího klíče:
Plán pro výchozí metodu (jak je zobrazen v Průzkumníku plánu) byl ve všech případech následující:
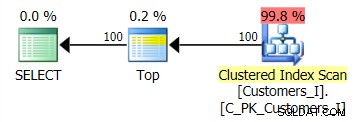
Zatímco plán metody založené na CTE vypadal takto:
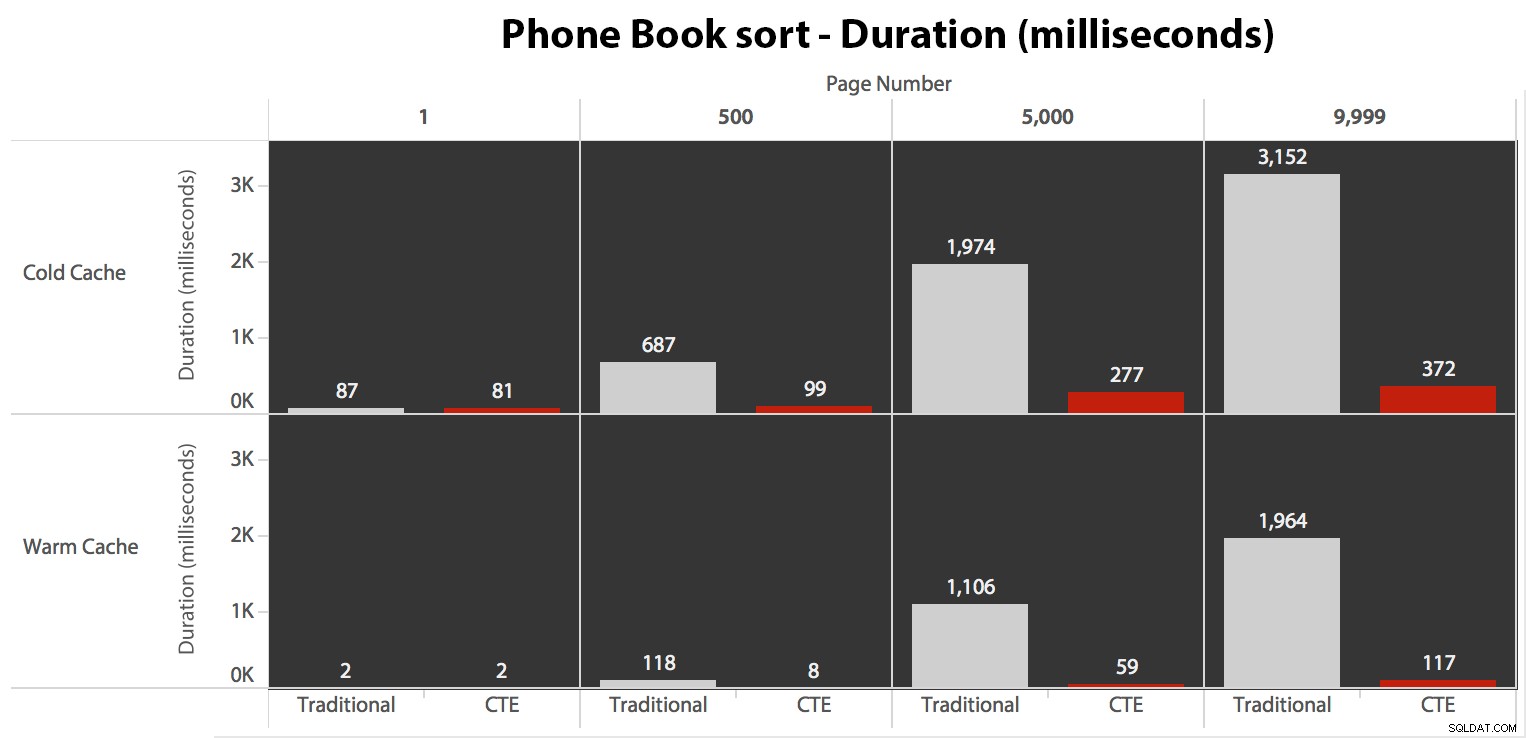
Nyní, zatímco I/O byl stejný bez ohledu na ukládání do mezipaměti (jen mnohem více čtení napřed ve scénáři studené mezipaměti), změřil jsem dobu trvání s chladnou mezipamětí a také s teplou mezipamětí (kde jsem okomentoval příkazy DROPCLEANBUFFERS a před měřením provedli dotazy několikrát). Tyto doby trvání vypadaly takto:
I když můžete vidět vzor, který ukazuje, jak se trvání zvyšuje s rostoucím číslem stránky, mějte na paměti měřítko:pro dosažení řádků 999 801 -> 999 900 mluvíme o půl sekundě v nejhorším případě a 118 milisekundách v nejlepším případě. Vyhrává přístup CTE, ale ne o tolik.
Testování řazení v telefonním seznamu
Dále jsem testoval druhý případ, kdy bylo řazení podporováno nepokrývajícím indexem na Příjmení, Jméno. Výše uvedený dotaz právě změnil všechny výskyty Test_1 na Test_2 . Zde byly čtení pomocí studené mezipaměti:
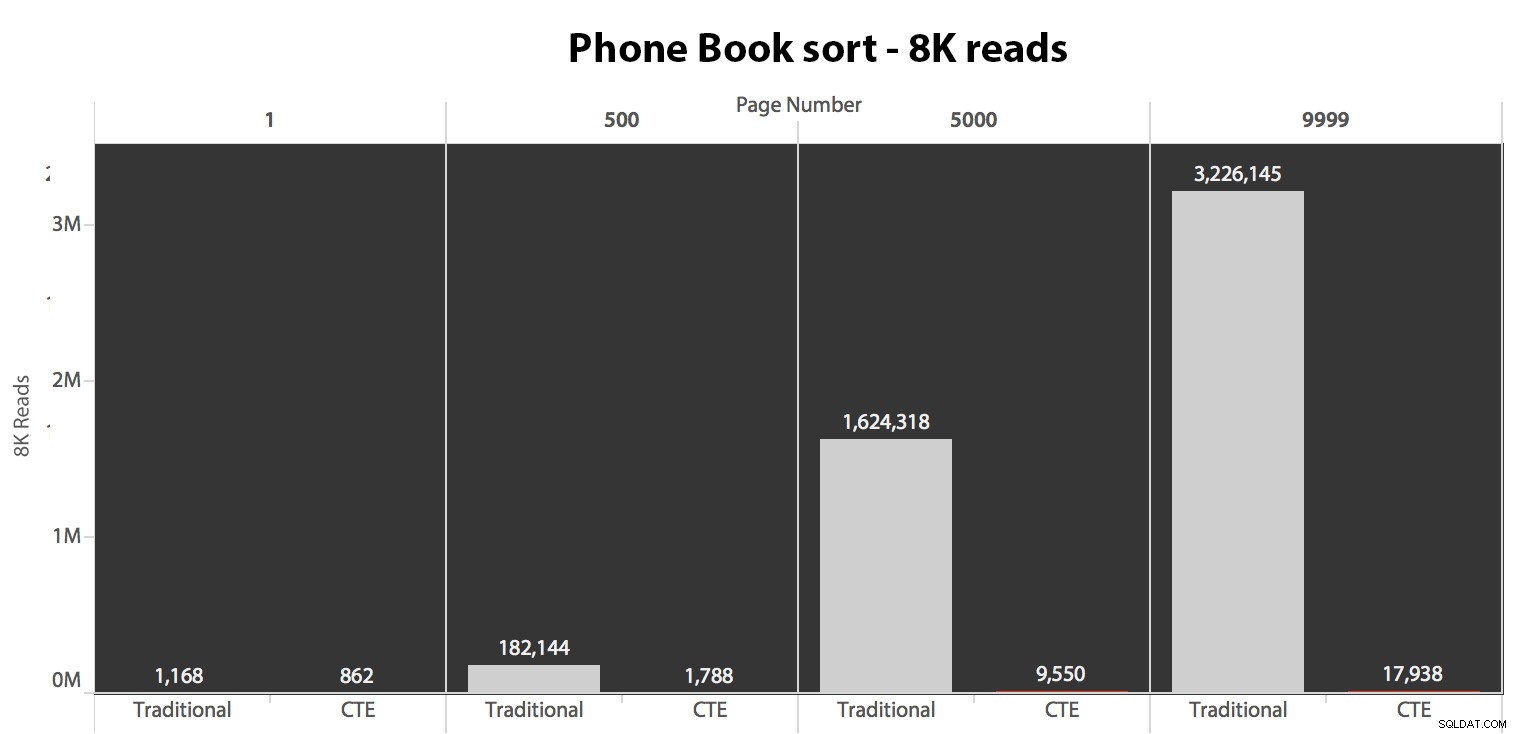
(Odečty pod teplou mezipamětí probíhaly podle stejného vzoru – skutečná čísla se mírně lišila, ale ne natolik, aby opravňovala samostatný graf.)
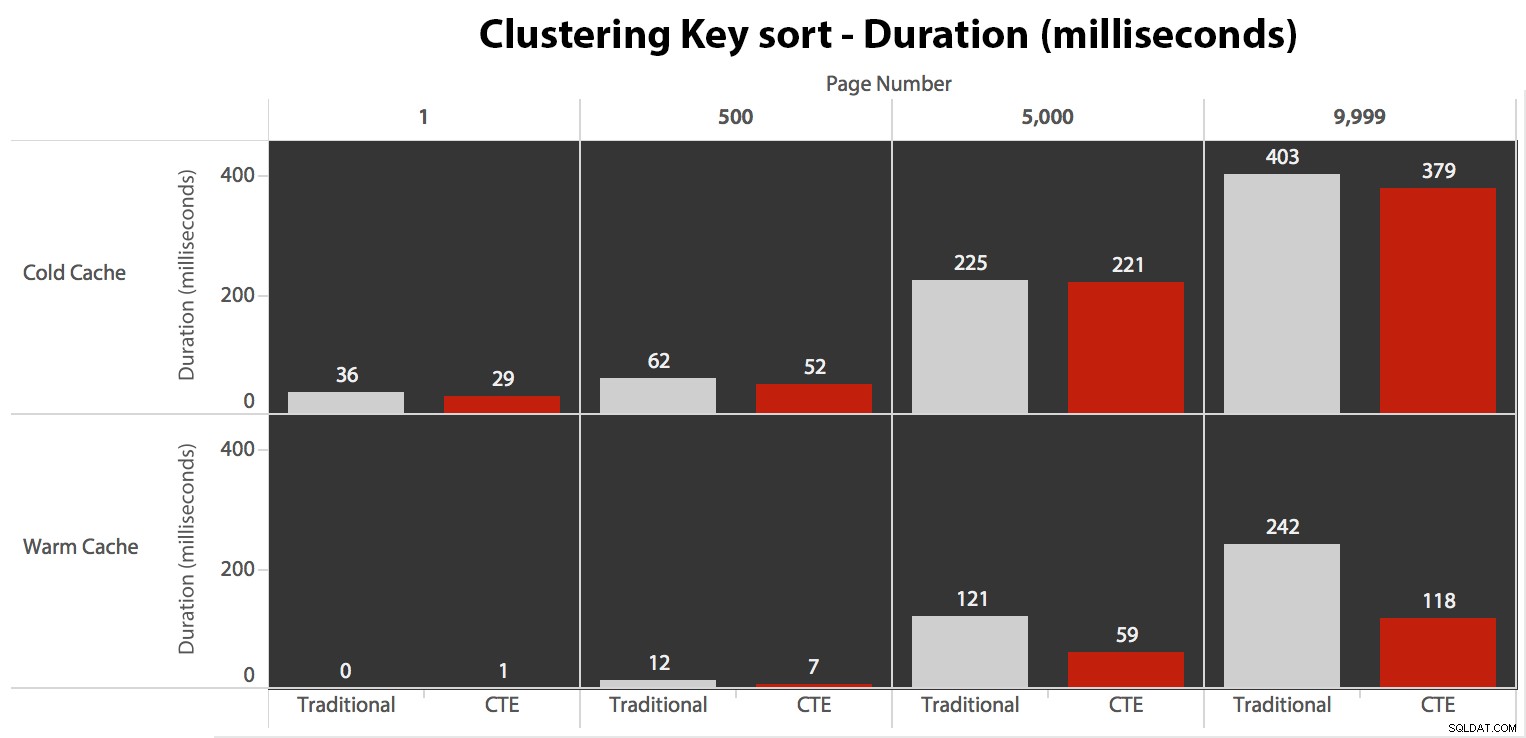
Když k řazení nepoužíváme seskupený index, je jasné, že I/O náklady spojené s tradiční metodou OFFSET/FETCH jsou mnohem horší, než když nejprve identifikujeme klíče v CTE a vytáhneme zbytek sloupců. pouze pro tuto podmnožinu.
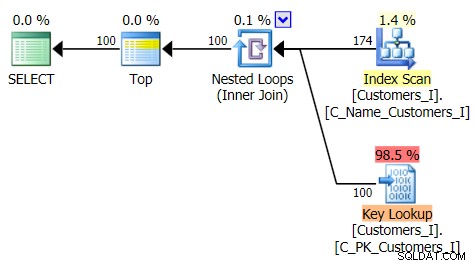
Zde je plán pro tradiční přístup k dotazu:
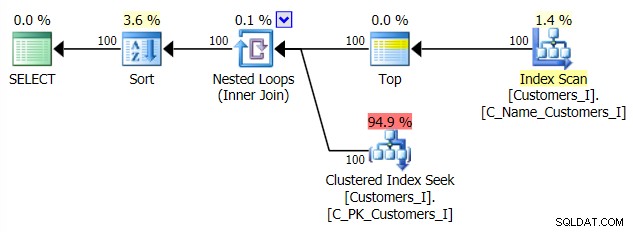
A plán mého alternativního přístupu CTE:
Nakonec doby trvání:
Tradiční přístup ukazuje velmi zřejmý vzestup trvání, když pochodujete ke konci stránkování. Přístup CTE také ukazuje nelineární vzor, ale je mnohem méně výrazný a poskytuje lepší načasování při každém čísle stránky. Vidíme 117 milisekund pro předposlední stránku, oproti tradičnímu přístupu za téměř dvě sekundy.
Testování uživatelem definovaného řazení
Nakonec jsem změnil dotaz tak, aby používal Test_3 uložené procedury, testování případu, kdy bylo řazení definováno uživatelem a nemělo podpůrný index. I/O byly konzistentní v každé sadě testů; ten graf je tak nezajímavý, jen na něj odkazuji. Zkrátka:ve všech testech bylo něco málo přes 19 000 přečtení. Důvodem je, že každá jednotlivá varianta musela provést úplné skenování kvůli chybějícímu indexu pro podporu řazení. Zde je plán pro tradiční přístup:
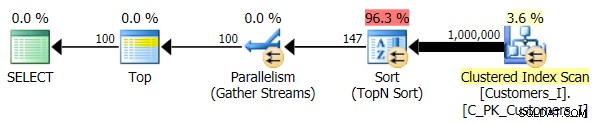
A zatímco plán pro verzi dotazu CTE vypadá znepokojivě složitější…
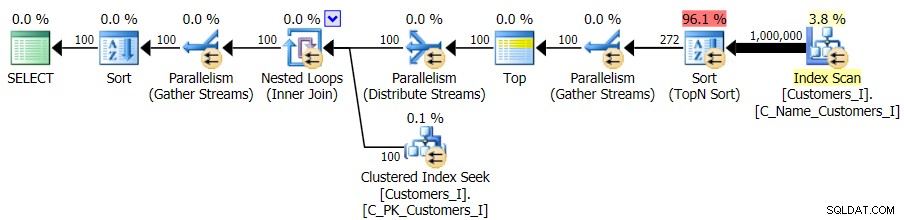
…vede to ke kratšímu trvání ve všech případech kromě jednoho. Zde jsou doby trvání:
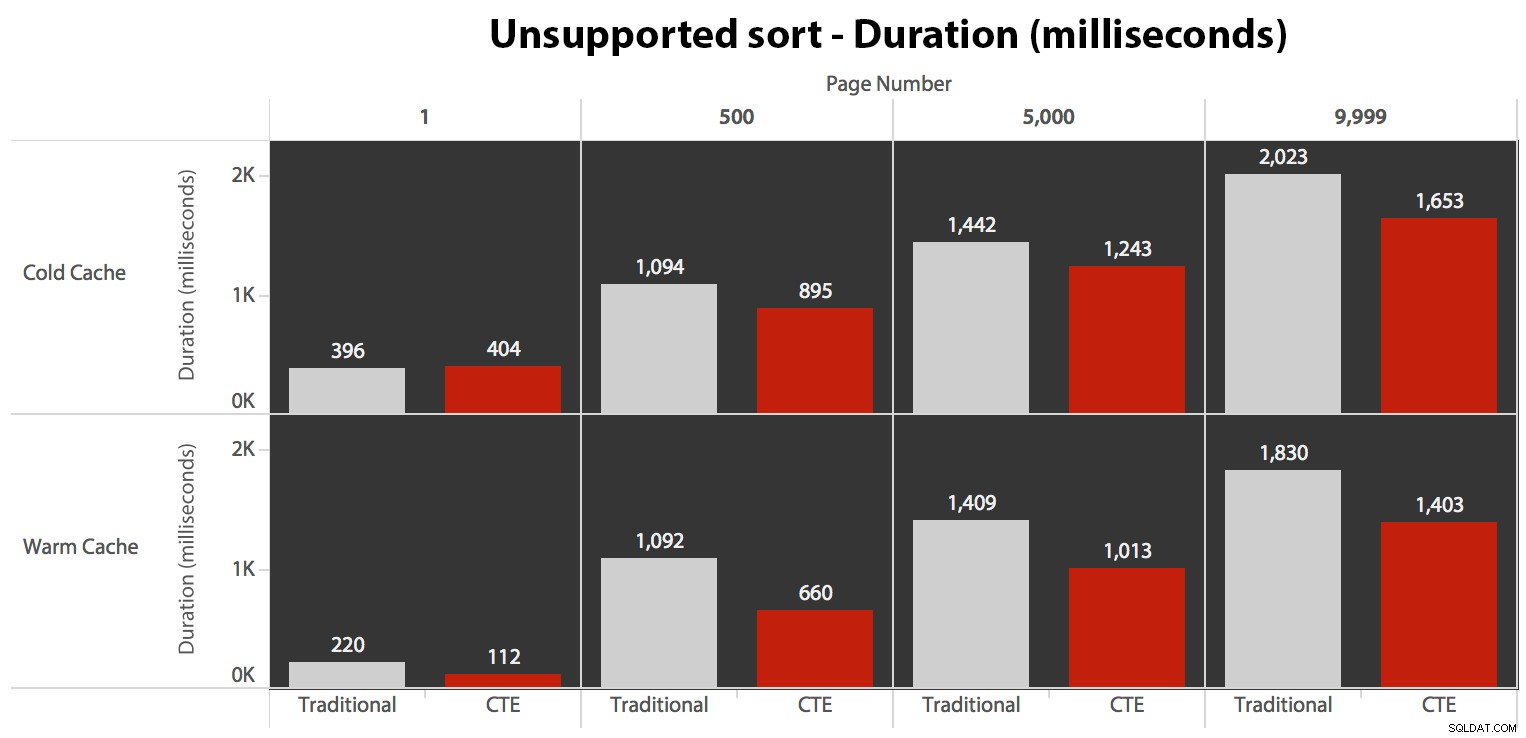
Můžete vidět, že zde nemůžeme dosáhnout lineárního výkonu pomocí žádné z metod, ale CTE je s velkým náskokem navrch (od 16 % do 65 % lepší) v každém jednotlivém případě kromě dotazu studené mezipaměti proti prvnímu stránku (kde prohrála o neuvěřitelných 8 milisekund). Zajímavé také je, že tradiční metodě příliš nepomáhá teplá cache v „uprostřed“ (stránky 500 a 5000); teprve ke konci sady stojí za zmínku jakákoli účinnost.
Vyšší hlasitost
Po individuálním otestování několika provedení a stanovení průměrů jsem si řekl, že by také mělo smysl otestovat vysoký objem transakcí, které by trochu simulovaly reálný provoz na vytíženém systému. Vytvořil jsem tedy úlohu se 6 kroky, jeden pro každou kombinaci metody dotazu (tradiční stránkování vs. CTE) a typu řazení (klastrovací klíč, telefonní seznam a nepodporované), se 100krokovou sekvencí zásahu do čtyř výše uvedených čísel stránek. , 10krát každé a 60 dalších náhodně vybraných čísel stránek (ale stejná pro každý krok). Zde je návod, jak jsem vygeneroval skript pro vytvoření úlohy:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Zde je výsledný seznam kroků úlohy a jedna z vlastností kroku:
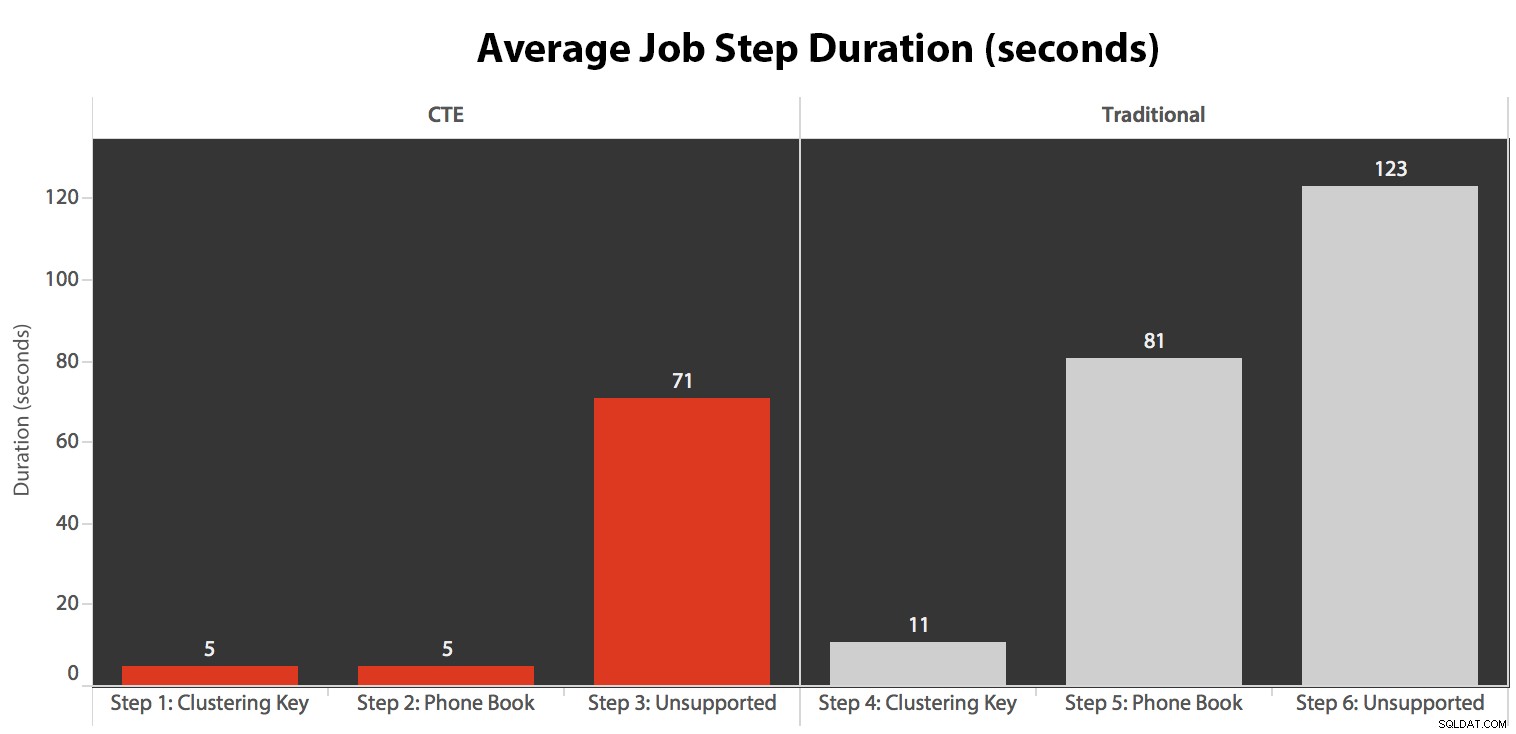
Spustil jsem úlohu pětkrát, pak jsem zkontroloval historii úlohy a zde byly průměrné doby běhu každého kroku:
Také jsem koreloval jedno z poprav v kalendáři SQL Sentry Event Manager…
…s řídicím panelem SQL Sentry a ručně označeny zhruba tam, kde probíhal každý ze šesti kroků. Zde je graf využití procesoru ze strany řídicího panelu systému Windows:
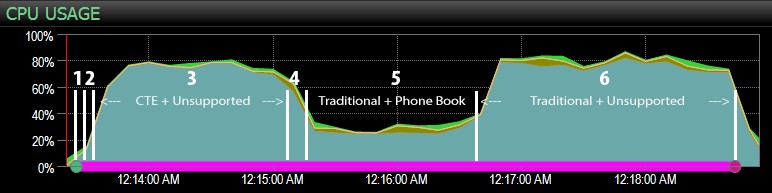
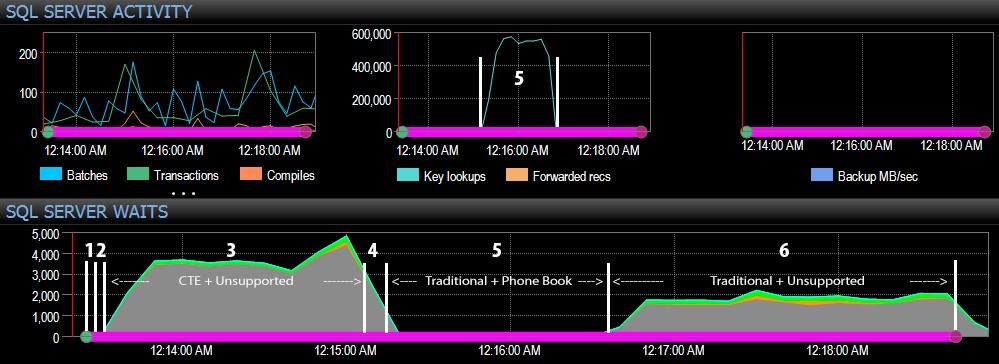
A ze strany řídicího panelu SQL Server byly zajímavé metriky v grafech Key Lookups and Waits:
Nejzajímavější postřehy pouze z čistě vizuální perspektivy:
- CPU je během kroku 3 (CTE + žádný podpůrný index) a kroku 6 (tradiční + žádný podpůrný index) poměrně horký, přibližně 80 %;
- Čekání na CXPACKET je relativně vysoké během kroku 3 a v menší míře během kroku 6;
- můžete vidět obrovský skok v klíčových vyhledáváních, na téměř 600 000, v rozmezí asi jedné minuty (což odpovídá kroku 5 – tradičnímu přístupu s indexem ve stylu telefonního seznamu).
V budoucím testu – stejně jako u mého předchozího příspěvku o GUID – bych to chtěl otestovat na systému, kde se data nevejdou do paměti (snadno simulovatelné) a kde jsou disky pomalé (simulovat tak není snadné) , protože některé z těchto výsledků pravděpodobně těží z věcí, které nemá každý produkční systém – rychlých disků a dostatečné paměti RAM. Také bych měl testy rozšířit tak, aby zahrnovaly více variant (používání úzkých a širokých sloupců, úzkých a širokých indexů, indexu telefonního seznamu, který ve skutečnosti pokrývá všechny výstupní sloupce, a řazení v obou směrech). Scope creep rozhodně omezil rozsah mého testování pro tuto první sadu testů.
Jak zlepšit stránkování serveru SQL Server
Stránkování nemusí být vždy bolestivé; SQL Server 2012 jistě usnadňuje syntaxi, ale pokud pouze zapojíte nativní syntaxi, nemusíte vždy vidět velkou výhodu. Zde jsem ukázal, že trochu podrobnější syntaxe pomocí CTE může v nejlepším případě vést k mnohem lepšímu výkonu a v nejhorším případě pravděpodobně k zanedbatelným rozdílům ve výkonu. Oddělením umístění dat od získávání dat do dvou různých kroků můžeme v některých scénářích vidět ohromnou výhodu, kromě vyšších čekání CXPACKET v jednom případě (a dokonce i tehdy byly paralelní dotazy dokončeny rychleji než ostatní dotazy s malým nebo žádným čekáním, takže je nepravděpodobné, že by to byli „špatní“ CXPACKET, před kterými vás každý varuje).
Přesto i rychlejší metoda je pomalá, když neexistuje žádný podpůrný index. I když můžete být v pokušení implementovat index pro každý možný třídicí algoritmus, který si uživatel může vybrat, možná budete chtít zvážit poskytnutí méně možností (protože všichni víme, že indexy nejsou zdarma). Potřebuje vaše aplikace například nezbytně podporovat řazení podle příjmení vzestupně *a* příjmení sestupně? Pokud chtějí přejít přímo k zákazníkům, jejichž příjmení začíná na Z, nemohou přejít na *poslední* stránku a pracovat pozpátku? To je rozhodnutí o podnikání a použitelnosti více než technické, prostě si to ponechte jako možnost, než přiřadíte indexy na každý sloupec řazení, v obou směrech, abyste dosáhli nejlepšího výkonu i pro ty nejobskurnější možnosti řazení.