Zatímco Jeff Atwood a Joe Celko si zřejmě myslí, že náklady na GUID nejsou žádný velký problém (viz Jeffův příspěvek na blogu „Primární klíče:ID versus GUID“ a toto vlákno diskusní skupiny nazvané „Identita vs. Uniqueidentifier“), další odborníci – konkrétněji odborníci na indexy a architekturu zaměřující se na prostor SQL Server – mají tendenci nesouhlasit. Například Kimberly Tripp ve svém příspěvku „Místo na disku je levný – O TOM NENÍ!“, kde vysvětluje, že dopad není jen na místo na disku a fragmentaci, ale co je důležitější, na velikost indexu a paměť. stopa.
To, co říká Kimberly, je opravdu pravda – neustále se setkávám s odůvodněním „místo na disku je levné“ pro GUID (příklad z minulého týdne). Existují další odůvodnění pro GUID, včetně potřeby generovat jedinečné identifikátory mimo databázi (a někdy před skutečným vytvořením řádku) a potřeba jedinečných identifikátorů napříč samostatnými distribuovanými systémy (a tam, kde rozsahy identit nejsou praktické). Ale opravdu chci vyvrátit mýtus, že GUID nestojí tolik, protože stojí, a musíte tyto náklady zvážit při svém rozhodování.
Vydal jsem se na tuto misi otestovat výkon různých velikostí klíčů za předpokladu stejných dat ve stejném počtu řádků, se stejnými indexy a zhruba stejnou zátěží (přehrát *přesně* stejnou zátěž může být docela náročné). Nejen, že jsem chtěl změřit základní věci, jako je velikost indexu a fragmentace indexu, ale také účinky, které mají, jako například:
- vliv na využití fondu vyrovnávacích pamětí
- četnost „špatných“ rozdělení stránek
- celkový dopad na realistickou dobu trvání pracovní zátěže
- vliv na průměrnou dobu běhu jednotlivých dotazů
- vliv na dobu běhu následujících spouštěčů
- vliv na používání databáze tempdb
K prozkoumání těchto dat použiji různé techniky, včetně Extended Events, výchozího trasování, DMV souvisejících s tempdb a SQL Sentry Performance Advisor.
Nastavení
Nejprve jsem vytvořil milion zákazníků, které jsem vložil do počáteční tabulky pomocí některých vestavěných metadat SQL Server; to by zajistilo, že „náhodní“ zákazníci by se v každém testu skládali ze stejných přirozených dat.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMÁRNÍ KLÍČ CLUSTERED, Jméno NVARCHAR(64), Příjmení NVARCHAR(64), E-mail NVARCHAR(320) NENÍ NULL UNIKÁTNÍ, Aktivní BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, Jméno, Příjmení, E-mail, [Aktivní])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) OD ( VYBERTE fn, ln, em, a, r =ŘÁDEK_ČÍSLO() PŘES (ODDĚLENÍ PODLE EM ORDER BY em) OD ( VYBERTE VRCHNÍ (2000000) fn =LEFT(jméno, 64), ln =LEFT(jméno, 64), em =LEFT(jméno, LEN(jméno)%5+1) + '.' + VLEVO(c. jméno, LEN(jméno)%5+2) + '@' + RIGHT(jméno, LEN(jméno+jméno)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO SELECT TOP (10) * FROM dbo.CustomerSeeds ORDER BY rn;GO
Váš počet najetých kilometrů se může lišit, ale v mém systému tato populace trvala 86 sekund. Deset reprezentativních řádků (pro zvětšení klikněte):
 Vzoroví zákazníci
Vzoroví zákazníci
Dále jsem potřeboval tabulky pro umístění počátečních dat pro každý případ použití s několika dalšími indexy pro simulaci nějaké reality a přišel jsem s krátkými příponami, které později usnadní všechny druhy diagnostiky:
| datový typ | výchozí | komprese | přípona případu použití |
|---|---|---|---|
| INT | IDENTITA | žádné | Já |
| INT | IDENTITA | stránka + řádek | Ic |
| VELKÝ | IDENTITA | žádné | B |
| VELKÝ | IDENTITA | stránka + řádek | Bc |
| UNIQUEIDENTIFIER | NEWID() | žádné | G |
| UNIQUEIDENTIFIER | NEWID() | stránka + řádek | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | žádné | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | stránka + řádek | Sc |
Tabulka 1:Případy použití, datové typy a přípony
Všech osm tabulek, všechny převzaté ze stejné šablony (jen bych změnil komentáře, aby odpovídaly případu použití, a nahradil bych $use_case$ s příslušnou příponou z výše uvedené tabulky):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NENÍ NULL VÝCHOZÍ NEWID(), --CustomerID UNIQUEIDENTIFIER NENÍ NULL VÝCHOZÍ NEWSEQUENTIALID(), Jméno NVARCHAR(64) NENÍ NULL, Příjmení NVARCHAR(64) NENÍ NULL, E-mail 320 NVARCHAR(NO) Aktivní BIT NOT NULL DEFAULT 1, vytvořeno DATETIME NOT NULL DEFAULT SYSDATETIME(), aktualizováno DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMÁRNÍ KLÍČ (ID zákazníka)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE_použití_INDEXU_CREATE$mail ONdCust_omers_ Customers_$use_case$(EMAIL) --WITH (DATA_COMPRESSION =PAGE);GCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(Jméno, Příjmení, E-mail) WHERE Active =1 --WITH (DATA_COMPRESSION); INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(Příjmení, Jméno) INCLUDE (E-mail) --WITH (DATA_COMPRESSION =PAGE);PŘEJÍTJakmile byly tabulky vytvořeny, pokračoval jsem v naplňování tabulek a měření mnoha metrik, o kterých jsem se zmiňoval výše. Mezi každým testem jsem restartoval službu SQL Server, abych se ujistil, že všechny začínají ze stejné základní linie, že DMV budou resetovány atd.
Nesporné přílohy
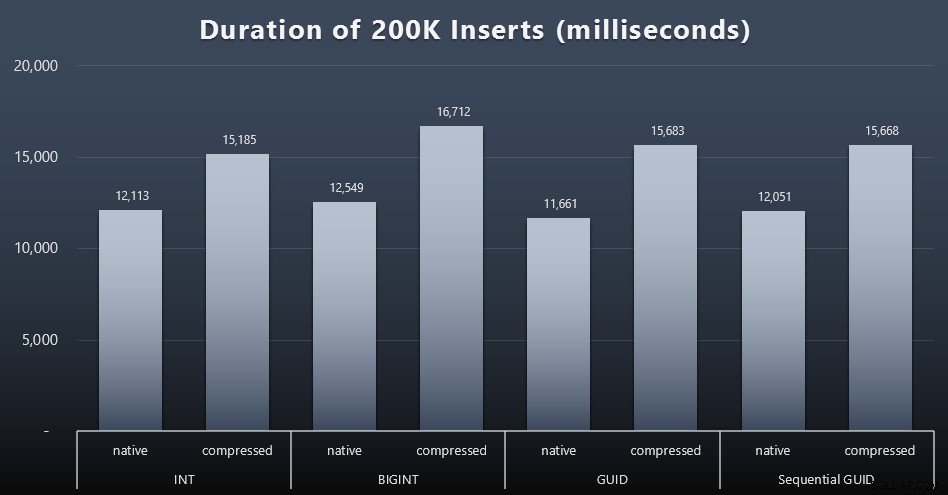
Mým konečným cílem bylo naplnit tabulku 1 000 000 řádky, ale nejprve jsem chtěl vidět dopad datového typu a komprese na nezpracované vložky bez sporů. Vygeneroval jsem následující dotaz – který by naplnil tabulku prvními 200 000 kontakty, 2 000 řádky najednou – a spustil ho proti každé tabulce:
DECLARE @i INT =1;WHILE @i <=100ZAČÁTEK INSERT dbo.Customers_$use_case$(Jméno, Příjmení, E-mail, Aktivní) VYBERTE Křestní jméno, Příjmení, E-mail, Aktivní OD dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) ŘÁDKY NAČÍST POUZE 2000 ŘÁDKŮ; SET @i +=1;ENDVýsledky (kliknutím zvětšíte):
Každý případ trval asi 12 sekund (bez komprese) a 16 sekund (s kompresí), bez jasného vítěze v žádném režimu úložiště. Vliv komprese (hlavně na režii CPU) je docela konzistentní, ale protože běží na rychlém SSD, vliv různých typů dat na I/O je zanedbatelný. Ve skutečnosti se zdálo, že komprese proti BIGINT má největší dopad (a to dává smysl, protože každá jednotlivá hodnota menší než 2 miliardy by byla komprimována).
Větší sporná pracovní zátěž
Dále jsem chtěl vidět, jak smíšené pracovní zatížení bude soutěžit o zdroje a obecně fungovat proti každému datovému typu. Tak jsem vytvořil tyto procedury (nahrazující
$use_case$a$data_type$přiměřeně pro každý test):-- náhodné jednotlivé aktualizace dat ve více než jednom indexu CREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; AKTUALIZACE dbo.Customers_$use_case$ SET Příjmení =COALESCE(STUFF(Příjmení, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- čte ("stránkování") - podporuje více sorts-- použijte dynamické SQL ke sledování statistik dotazů samostatněCREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT ID zákazníka, Jméno, Příjmení, E-mail, Aktivní, Vytvořeno, Aktualizováno OD dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) ŘÁDKY NAČÍST DALŠÍ @ps POUZE ŘÁDKY;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOPoté jsem vytvořil zakázky, které by tyto procedury opakovaly, s mírným zpožděním, a také – současně – dokončily naplnění zbývajících 800 000 kontaktů. Tento skript vytvoří všech 32 úloh a také vytiskne výstup, který lze později použít k asynchronnímu volání všech úloh pro konkrétní test:
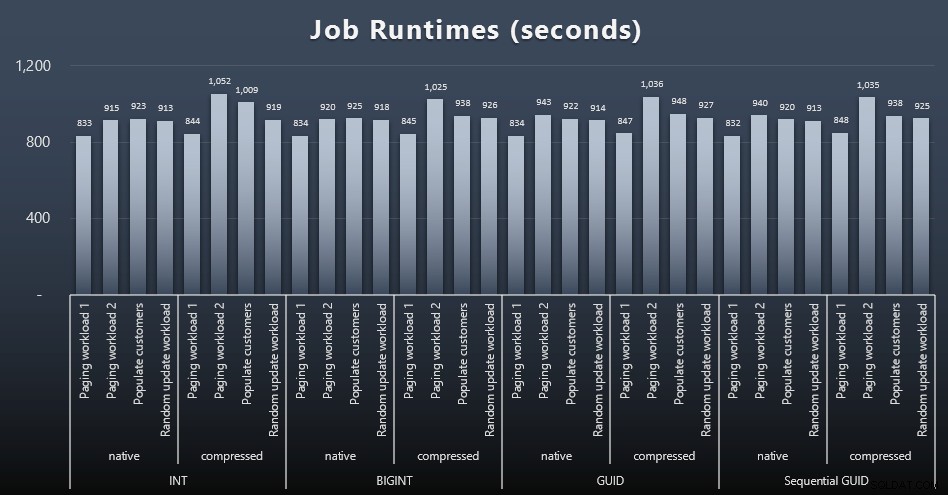
USE msdb;GO DECLARE @typ TABLE(případ_použití VARCHAR(2), datový_typ SYSNAME);INSERT @typ(případ_použití, typ_dat) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(jméno SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(název, cmd) VALUES( N'Náhodná aktualizace pracovní zátěž', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 ZAČÁTEK VYBRAT NAHORU (1) @CustomerID =CustomerID OD dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; '0ČEKEJTE' 0 ZPOŽDĚNÍ:0 :01''; SET @i +=1; END'),( N'Populate customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 ZAČNĚTE INSERT dbo.Customers_$use_case$ (Jméno, Příjmení, E-mail, Aktivní) VYBERTE JMÉNO, Příjmení, E-mail, Aktivní Z dbo.CustomerSeeds JAKO c OBJEDNAT PODLE RN OFFSET 2000 * (@i-1) ŘÁDKY NAČÍTÁNÍ DALŠÍCH 2000 ŘÁDKŮ POUZE; ČEKEJTE NA ZPOŽDĚNÍ ':'00:00 01''; SET @i +=1; END'),( N'Paging zátěž 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- řazení podle SET ID zákazníka @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'),( N'Paging zátěž 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- řazení podle Příjmení, Jméno SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Příjmení, Jméno'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL FAST_FORWARD FORSELECT name =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) OD @typ AS t CROSS JOIN @jobs AS j; OTEVŘENO c; NAČÍST c DO @n, @c; WHILE @@FETCH_STATUS <> -1BEGIN IF EXISTS (VYBERTE 1 Z msdb.dbo.sysjobs WHERE name =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; NAČÍST c DO @n, @c;KONECMěření načasování úloh v každém případě bylo triviální – mohl jsem zkontrolovat data zahájení a ukončení v
msdb.dbo.sysjobhistorynebo je vytáhněte z SQL Sentry Event Manager. Zde jsou výsledky (kliknutím zvětšíte):
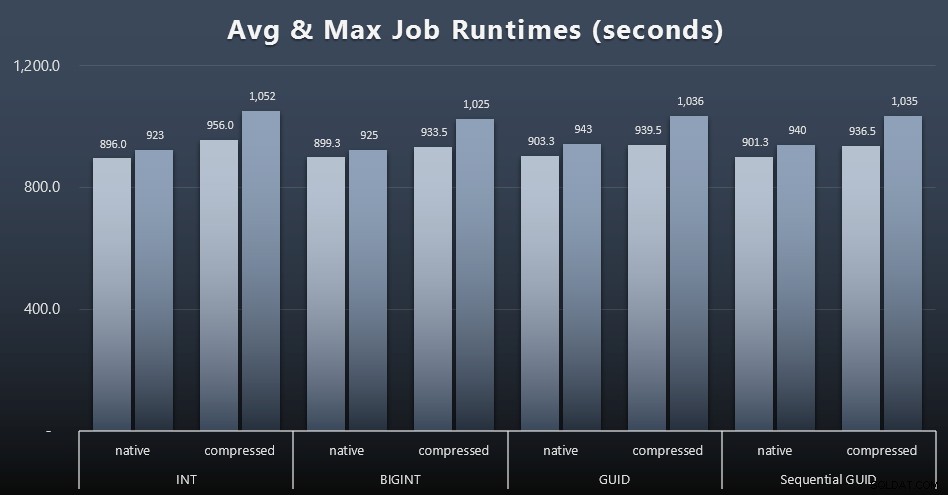
A pokud byste chtěli mít o něco méně na strávení, podívejte se na průměrnou a maximální dobu běhu všech čtyř úloh (kliknutím zvětšíte):
Ale ani v tomto druhém grafu není ve skutečnosti dostatek rozptylu na to, aby byl přesvědčivý argument pro nebo proti kterémukoli z přístupů.
Doby běhu dotazu
Převzal jsem některé metriky z
sys.dm_exec_query_statsasys.dm_exec_trigger_statszjistit, jak dlouho v průměru jednotlivé dotazy trvaly.
Populace
Prvních 200 000 zákazníků bylo načteno poměrně rychle – pod 20 sekund – díky žádné konkurenční zátěži. Jakmile však čtyři úlohy běžely současně, došlo k významnému dopadu na trvání zápisu kvůli souběžnosti. Zbývajících 800 000 řádků vyžadovalo v průměru minimálně o řád více času na dokončení. Zde jsou výsledky zprůměrování každých 2 000 zákaznických příloh (kliknutím zvětšíte):
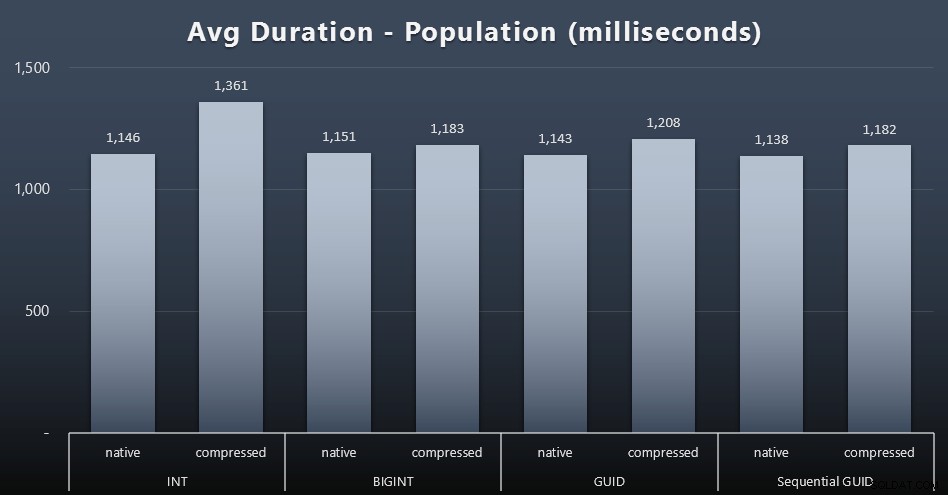
Vidíme zde, že komprese INT byla jedinou skutečnou odlehlostí – mám na to nějaké teorie, ale zatím nic nezvratného.
Úlohy stránkování
Zdá se, že průměrné doby běhu stránkovacích dotazů byly také významně ovlivněny souběžností ve srovnání s mými testovacími běhy v izolaci. Zde jsou výsledky (kliknutím zvětšíte):
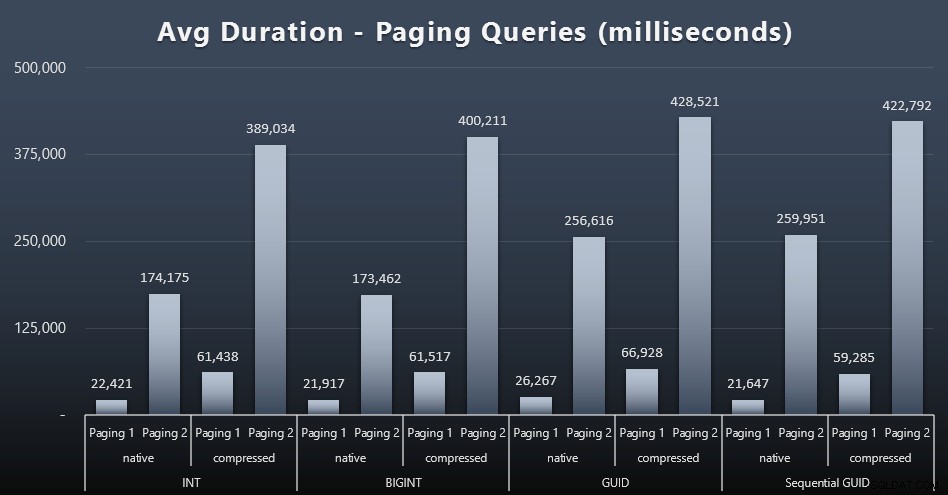
(Paging 1 =objednávka podle CustomerID, Paging 2 =objednávka podle LastName, FirstName.)
Vidíme, že jak pro Stránkování 1 (uspořádání podle CustomerID), tak pro Stránkování 2 (seřazení podle jmen), existuje významný dopad na dobu běhu kvůli kompresi (až ~700 %). Oba GUID se zdají být nejpomalejšími koňmi v tomto dostihu, přičemž NEWID() si vede nejhůře.
Aktualizovat úlohy
Aktualizace singletonu byly poměrně rychlé i při velké souběhu, ale stále existovaly některé znatelné rozdíly kvůli kompresi a dokonce některé překvapivé rozdíly mezi typy dat (kliknutím zvětšíte):
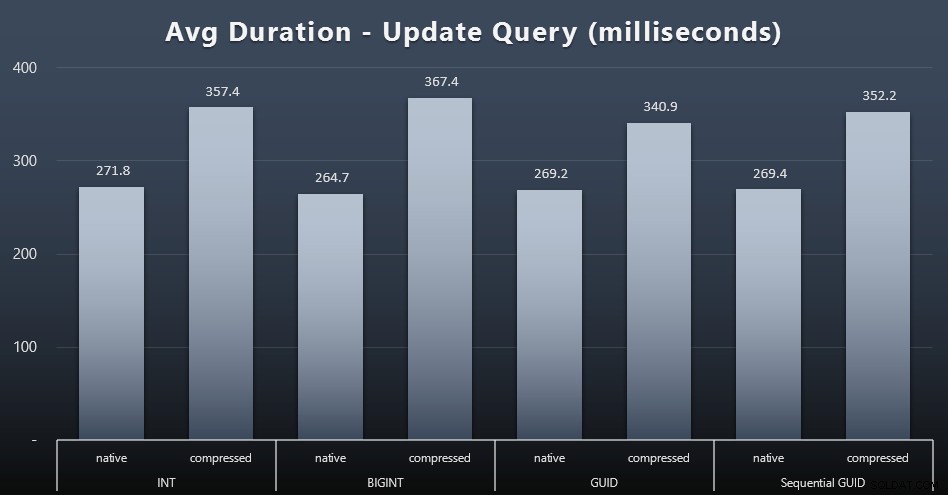
Nejpozoruhodnější je, že aktualizace řádků obsahujících hodnoty GUID byly ve skutečnosti rychlejší než aktualizace obsahující INT/BIGINT, když se používala komprese. S nativním úložištěm byly rozdíly méně pozoruhodné (ale INT tam bylo stále propadák).
Statistika spouštění
Zde jsou průměrné a maximální doby běhu jednoduchého spouštění v každém případě (kliknutím zvětšíte):
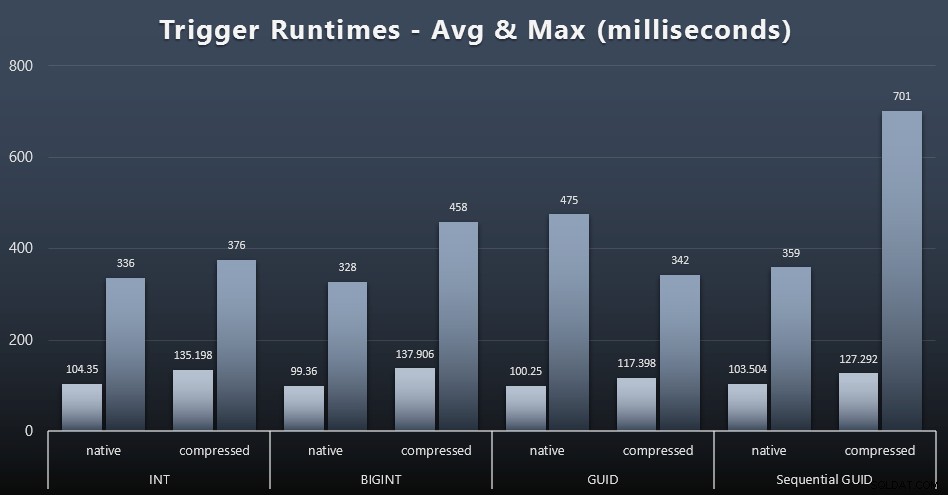
Zdá se, že komprese zde má mnohem větší dopad než výběr datového typu (ačkoli by to bylo pravděpodobně výraznější, kdyby některá z mých úloh aktualizace aktualizovala mnoho řádků namísto toho, aby se skládala pouze z vyhledávání jednoho řádku). Maximum pro sekvenční GUID je zjevně nějaká odlehlá hodnota, kterou jsem nezkoumal (můžete říct, že je nevýznamné na základě průměru, který je stále v souladu).
Na co tyto dotazy čekaly?
Po každém pracovním zatížení jsem se také podíval na nejvyšší čekání v systému, zahodil jsem zjevná čekání na frontu/časovač (jak popsal Paul Randal) a irelevantní aktivitu monitorovacího softwaru (jako TRACEWRITE ). Zde jsou 3 nejlepší čekání v každém případě (kliknutím zvětšíte):
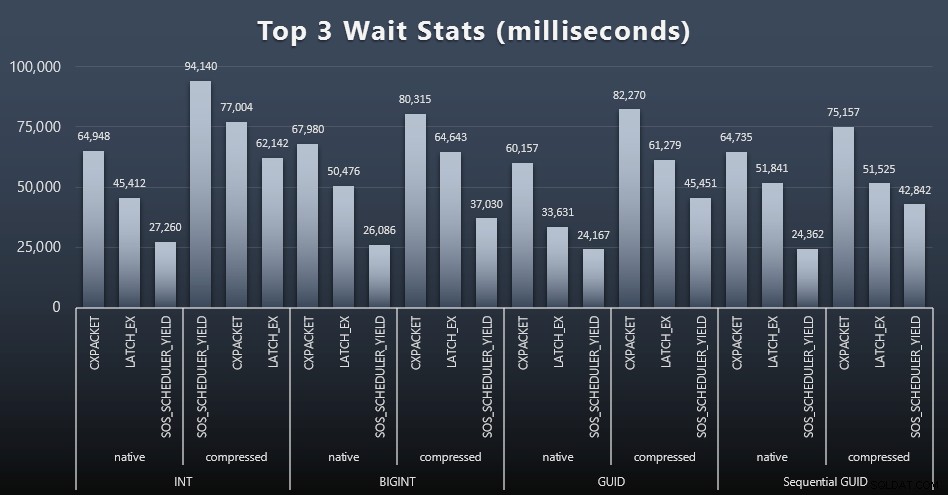
Ve většině případů se čekalo CXPACKET, pak LATCH_EX, pak SOS_SCHEDULER_YIELD. V případě použití zahrnujícím celá čísla a kompresi však převzal SOS_SCHEDULER_YIELD, což pro mě znamená určitou neefektivitu v algoritmu pro kompresi celých čísel (což může být zcela nesouvisející s algoritmem používaným ke stlačování BIGINTů do INT). Dále jsem to nezkoumal ani jsem nenašel důvod pro sledování čekání na jednotlivý dotaz.
Místo na disku / Fragmentace
I když mám tendenci souhlasit s tím, že nejde o místo na disku, stále je to metrika, kterou stojí za to prezentovat. I v tomto velmi zjednodušeném případě, kdy existuje pouze jedna tabulka a klíč není přítomen ve všech ostatních souvisejících tabulkách (které by v reálné aplikaci jistě existovaly), je rozdíl významný. Nejprve se podívejme na reserved sloupec z sp_spaceused (kliknutím zvětšíte):
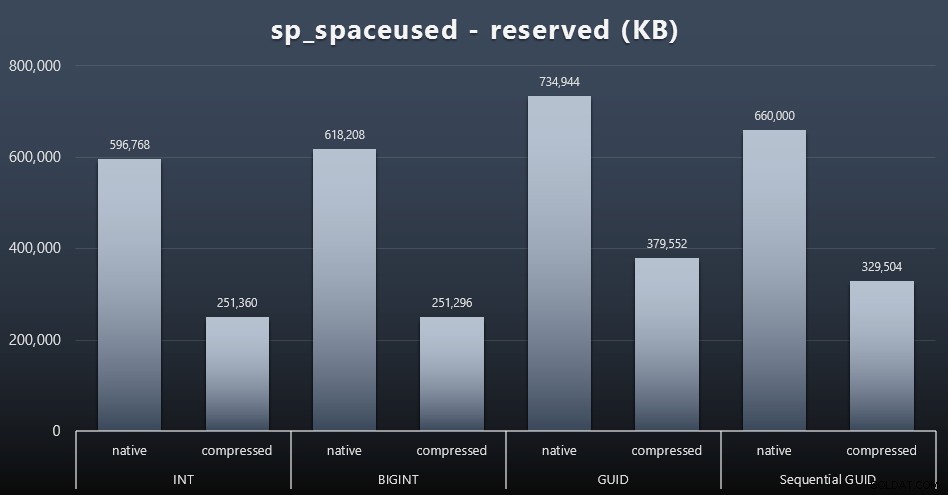
Zde BIGINT zabral jen o něco více místa než INT a GUID (podle očekávání) měl větší skok. Sekvenční GUID mělo méně významné zvýšení využitého prostoru a bylo také mnohem lépe komprimováno než tradiční GUID. Opět zde žádné překvapení – GUID je větší než číslo, tečka. Nyní by zastánci GUID mohli namítnout, že cena, kterou zaplatíte za místo na disku, není tak vysoká (18 % oproti BIGINT bez komprese, kolem 50 % s kompresí). Pamatujte však, že se jedná o jedinou tabulku s 1 milionem řádků. Představte si, jak to bude extrapolovat, když máte 10 milionů zákazníků a mnozí z nich mají 10, 30 nebo 500 objednávek – tyto klíče by se mohly opakovat v tuctu dalších tabulek a v každém řádku by zabíraly stejné místo navíc.
Když jsem se podíval na fragmentaci po každém pracovním zatížení (nezapomeňte, že se neprovádí žádná údržba indexu) pomocí tohoto dotazu:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Výsledky přinesly mnohem méně zajímavé vizuály; vše neshlukované indexy byly fragmentovány přes 99 %. Seskupené indexy však byly buď velmi silně fragmentované, nebo nebyly fragmentovány vůbec (kliknutím zvětšíte):
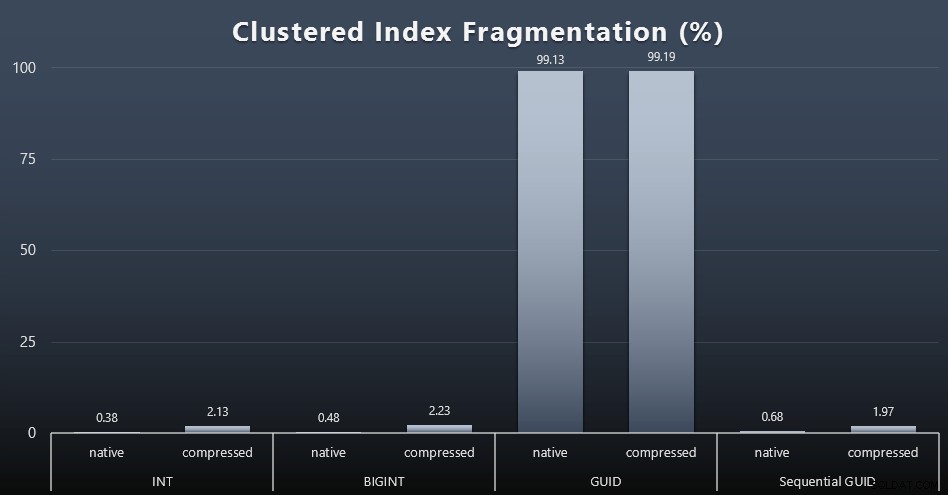
Fragmentace je další metrika, která často znamená mnohem méně, když mluvíme o SSD, ale je důležité si uvědomit totéž, protože ne všechny systémy si mohou dovolit být blaženě nevědomé toho, jaký dopad může mít fragmentace na I/O vzory. Domnívám se, že při použití nesekvenčních GUID v systému s větším množstvím I/O by byl dopad samotné fragmentace drasticky zesílen na většinu ostatních metrik v tomto testu.
Využití fondu vyrovnávacích pamětí
Zde se uvážlivost ohledně množství místa na disku používaného vašimi tabulkami opravdu vyplatí – čím větší jsou vaše tabulky, tím více místa zabírají ve fondu vyrovnávacích pamětí. Přesouvání dat do a z vyrovnávací paměti je drahé a opět se jedná o velmi zjednodušený případ, kdy testy probíhaly izolovaně a na instanci nebyly jiné aplikace a databáze, které by soutěžily o drahocennou paměť.
Jedná se o jednoduché měření následujícího dotazu na konci každé úlohy:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Výsledky (kliknutím zvětšíte):
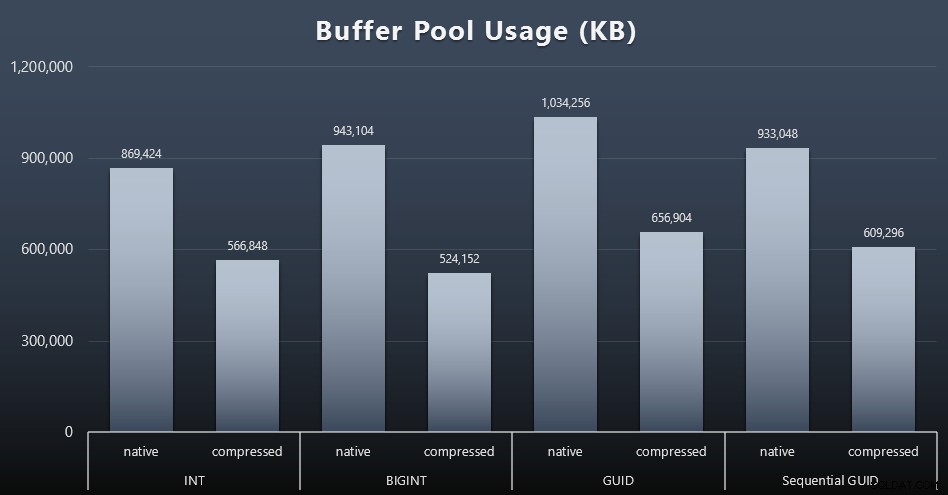
Zatímco většina tohoto grafu není vůbec překvapivá – GUID zabírá více místa než BIGINT, BIGINT více než INT – přišlo mi zajímavé, že sekvenční GUID zabírá méně místa než BIGINT, a to i bez komprese. Udělal jsem si poznámku, abych provedl nějakou forenzní analýzu na úrovni stránky, abych určil, jaký druh efektivity se odehrává zde pod krytem.
Využití tempdb
Nejsem si jistý, co jsem zde očekával, ale po každém pracovním zatížení jsem shromáždil obsah tří DMV o využití prostoru souvisejících s tempdb, sys.dm_db_file|session|task_space_usage . Jediný, který na základě datového typu vykazoval nějakou volatilitu, byl sys.dm_db_file_space_usage extent_allocation_page_count . To ukazuje, že – alespoň v mé konfiguraci a této specifické zátěži – GUID provedou tempdb trochu důkladnějším tréninkem (kliknutím zvětšíte):
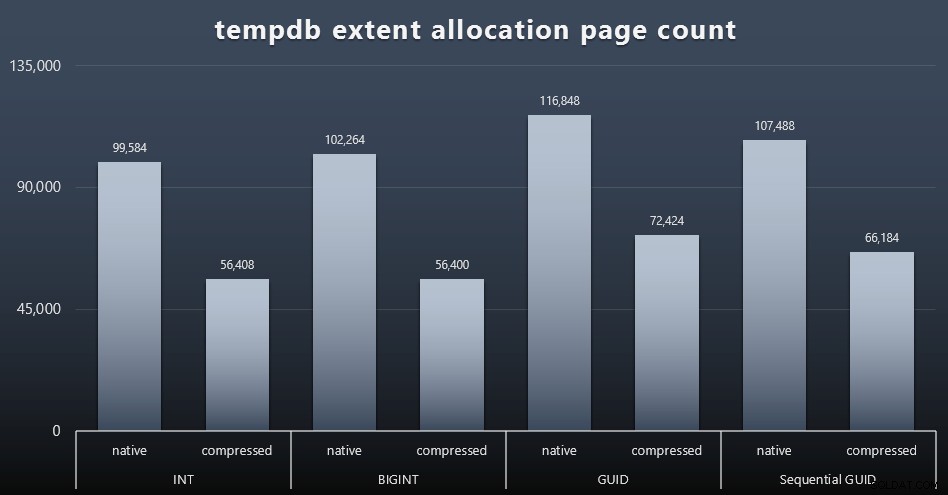
Špatné rozdělení stránky
Jedna z věcí, kterou jsem chtěl změřit, byl dopad na rozdělení stránek – ne normální rozdělení stránek (když přidáte novou stránku), ale když ve skutečnosti musíte přesouvat data mezi stránkami, abyste vytvořili místo pro více řádků. Jonathan Kehayias o tom mluví podrobněji ve svém příspěvku na blogu „Sledování problémových rozštěpení stránek v SQL Server 2012 Extended Events – tentokrát opravdu ne!“, který také poskytuje základ pro relaci Extended Events, kterou jsem použil k zachycení dat:
VYTVOŘIT RELACI UDÁLOSTI [BadPageSplits] NA SERVER PŘIDAT UDÁLOST sqlserver.transaction_log (WHERE operation =11 AND database_id =10) PŘIDAT CÍL package0.histogram ( SET filtering_event_name ='sqlserver.loc_type nit_log =', source_type nit_log =', source_type nit_log', source_typenit_log );REZACE UDÁLOSTI BRANKÁŘE [BadPageSplits] VE STAVU SERVERU =START;PŘEJÍT
A dotaz, který jsem použil k vykreslení:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name_session ='Btar ='histogram' ) JAKO x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) JAKO tabINNER PŘIPOJIT sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER PŘIPOJIT SE k sys.partitions AS p ON container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; A zde jsou výsledky (kliknutím zvětšíte):
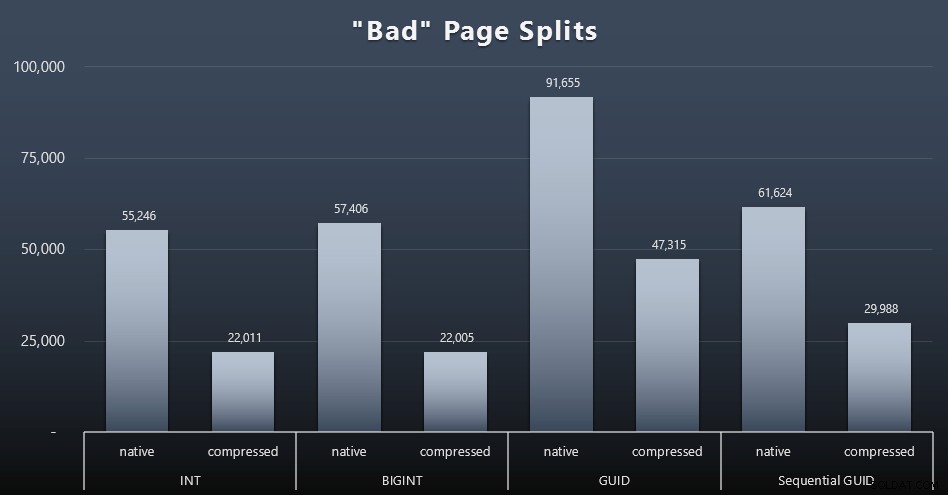
Ačkoli jsem již poznamenal, že v mém scénáři (kde běžím na rychlých SSD) nesporný rozdíl v I/O aktivitě přímo neovlivňuje celkovou dobu běhu, je to stále metrika, kterou budete chtít zvážit – zvláště pokud nemáte SSD nebo pokud je vaše pracovní zátěž již I/O vázána.
Závěr
I když mi tyto testy trochu otevřely oči ohledně toho, jak dlouhotrvající vjemy, které jsem měl, byly změněny modernějším hardwarem, jsem stále docela pevně proti plýtvání místem na disku nebo v paměti. Zatímco jsem se snažil demonstrovat určitou rovnováhu a nechat GUID zazářit, z hlediska výkonu je zde velmi málo na podporu přepínání z INT/BIGINT na kteroukoli formu UNIQUEIDENTIFIER – pokud to nepotřebujete z jiných méně hmatatelných důvodů (jako je vytvoření klíče v aplikace nebo udržování jedinečných klíčových hodnot v různých systémech). Stručné shrnutí, které ukazuje, že NEWID() je nejhorší volbou v mnoha metrikách, kde byl podstatný rozdíl (a ve většině těchto případů byl NEWSEQUENTIALID() těsně druhý)):
| Metrika | Vymazat poražené? |
|---|---|
| Nesporné přílohy | – kreslit – |
| Souběžná pracovní zátěž | – kreslit – |
| Jednotlivé dotazy – populace | INT (komprimovaný) |
| Jednotlivé dotazy – stránkování | NEWID() / NEWSEQUENTIALID() |
| Jednotlivé dotazy – aktualizace | INT (nativní) / BIGINT (komprimovaný) |
| Jednotlivé dotazy – PO spuštění | – kreslit – |
| Místo na disku | NEWID() |
| Fragmentace seskupených indexů | NEWID() |
| Využití fondu vyrovnávacích pamětí | NEWID() |
| Použití tempdb | NEWID() |
| "Špatné" rozdělení stránky | NEWID() |
Tabulka 2:Největší poražení
Neváhejte a otestujte si tyto věci sami; Mohu sestavit celou svou sadu skriptů, pokud je chcete spouštět ve svém vlastním prostředí. Krátký účel celého tohoto příspěvku je docela jednoduchý:kromě předvídatelného dopadu na místo na disku je třeba vzít v úvahu mnoho důležitých metrik, takže by neměly být použity samostatně jako argument v žádném směru.
Nechci, aby se tento způsob myšlení omezoval na klíče jako takové. Opravdu by se na to mělo myslet, kdykoli se provádí výběr datového typu. Vidím datetime volí se často, například když je pouze date nebo smalldatetime je potřeba. Na transakčních tabulkách to také může vést k velkému plýtvání místem na disku, a to se dostane i na některé z těchto dalších zdrojů.
V budoucím testu bych chtěl porovnat výsledky pro mnohem větší tabulku (> 2 miliardy řádků). Mohu to simulovat pomocí INT nastavením počáteční hodnoty identity na -2 miliardy, což umožňuje ~4 miliardy řádků. A rád bych, aby srovnání zátěže a místa na disku/paměti zahrnovalo více než jednu tabulku, protože jednou z výhod hubeného klíče je, když je tento klíč zastoupen v desítkách souvisejících tabulek. Sledoval jsem události autogrow, ale žádné nebyly, protože databáze byla dostatečně velká, aby se přizpůsobila růstu, a nenapadlo mě měřit skutečné využití protokolu uvnitř existujícího souboru protokolu, takže bych chtěl otestovat opět s výchozími hodnotami pro velikost protokolu a automatický růst a tentokrát měření DBCC SQLPERF(LOGSPACE); . Bylo by také zajímavé načasovat přestavby a měřit využití protokolu v důsledku těchto operací. Nakonec bych rád učinil I/O relevantnějším faktorem tím, že najdu server s mechanickými pevnými disky – vím, že je jich tam spousta, ale v některých obchodech jsou dost vzácné.