V dnešní době jsou databáze pokrývající více cloudů poměrně běžné. Slibují vysokou dostupnost a možnost snadné implementace postupů obnovy po havárii. Jsou také metodou, jak se vyhnout uzamčení dodavatele:pokud své databázové prostředí navrhnete tak, aby mohlo fungovat mezi více poskytovateli cloudu, s největší pravděpodobností nejste vázáni na funkce a implementace specifické pro jednoho konkrétního poskytovatele. To vám usnadní přidání dalšího poskytovatele infrastruktury do vašeho prostředí, ať už jde o další cloud nebo místní nastavení. Tato flexibilita je velmi důležitá vzhledem k tomu, že mezi poskytovateli cloudu existuje nelítostná konkurence a migrace od jednoho k druhému by mohla být docela proveditelná, pokud by byla podpořena snížením nákladů.
Rozložení vaší infrastruktury přes více datových center (od stejného poskytovatele nebo ne, na tom opravdu nezáleží) přináší vážné problémy, které je třeba vyřešit. Jak lze navrhnout celou infrastrukturu tak, aby data byla v bezpečí? Jak se vypořádat s výzvami, kterým musíte čelit při práci v multi-cloudovém prostředí? V tomto blogu se podíváme na jeden, ale pravděpodobně ten nejzávažnější – potenciál rozděleného mozku. Co to znamená? Pojďme se trochu ponořit do toho, co je rozdělený mozek.
Co je to „Split-Brain“?
Split-brain je stav, kdy prostředí, které se skládá z více uzlů, trpí rozdělením sítě a bylo rozděleno na více segmentů, které spolu nejsou v kontaktu. Nejjednodušší případ bude vypadat takto:
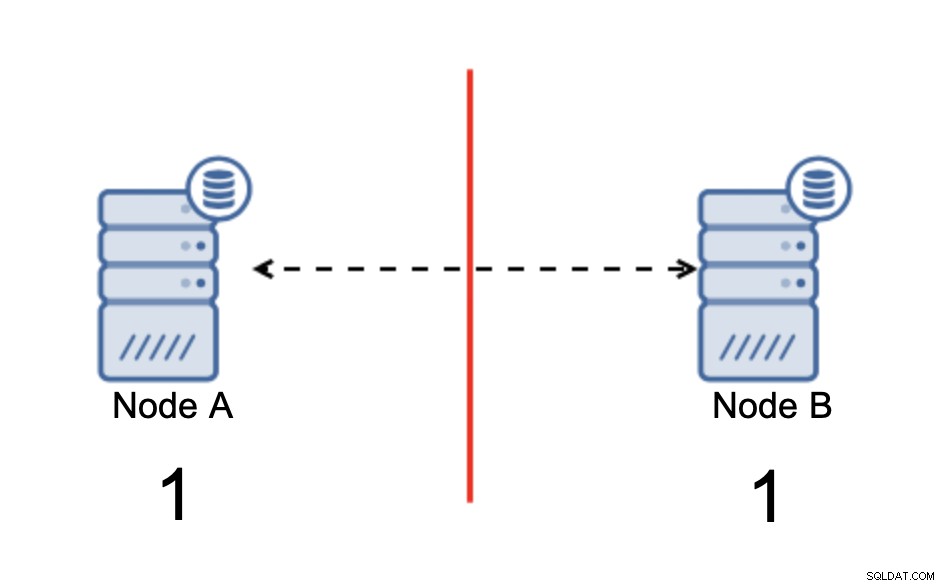
Máme dva uzly, A a B, propojené přes síť pomocí bi -směrová asynchronní replikace. Poté je síťové připojení mezi těmito uzly přerušeno. V důsledku toho se oba uzly nemohou vzájemně propojit a jakékoli změny provedené v uzlu A nelze přenést do uzlu B a naopak. Oba uzly, A i B, jsou aktivní a přijímají spojení, jen si nemohou vyměňovat data. To může vést k vážným problémům, protože aplikace může provádět změny na obou uzlech s očekáváním, že uvidí úplný stav databáze, zatímco ve skutečnosti pracuje pouze s částečně známým stavem dat. V důsledku toho může aplikace provádět nesprávné akce, uživateli mohou být prezentovány nesprávné výsledky a tak dále. Myslíme si, že je jasné, že split-brain je potenciálně velmi nebezpečný stav a jednou z priorit by bylo se s tím do určité míry vypořádat. Co se s tím dá dělat?
Jak se vyhnout rozdělení mozku
Zkrátka záleží. Hlavním problémem, který je třeba řešit, je skutečnost, že uzly jsou v provozu, ale nemají mezi sebou konektivitu, a proto nevědí o stavu druhého uzlu. Asynchronní replikace MySQL obecně nemá žádný mechanismus, který by interně vyřešil problém rozděleného mozku. Můžete se pokusit implementovat některá řešení, která vám pomohou vyhnout se rozdělení mozku, ale mají určitá omezení nebo problém stále plně nevyřeší.
Když se odvážíme od asynchronní replikace, věci vypadají jinak. MySQL Group Replication a MySQL Galera Cluster jsou technologie, které těží z povědomí o sestaveném clusteru. Obě tato řešení udržují komunikaci mezi uzly a zajišťují, že cluster je informován o stavu uzlů. Implementují mechanismus kvora, který řídí, zda mohou být klastry provozuschopné nebo ne.
Proberme tato dvě řešení (asynchronní replikace a clustery založené na kvorech) podrobněji.
Clusterování založené na kvoru
Nebudeme diskutovat o rozdílech v implementaci mezi MySQL Galera Cluster a MySQL Group Replication, zaměříme se na základní myšlenku přístupu založeného na kvoru a na to, jak je navržen pro řešení problému split-brain ve vašem clusteru.
Sečteno a podtrženo:cluster, aby fungoval, vyžaduje, aby byla k dispozici většina jeho uzlů. S tímto požadavkem si můžeme být jisti, že menšina nemůže nikdy skutečně ovlivnit zbytek shluku, protože menšina by neměla být schopna provádět žádné akce. To také znamená, že aby bylo možné zvládnout selhání jednoho uzlu, měl by mít cluster alespoň tři uzly. Pokud máte pouze dva uzly:
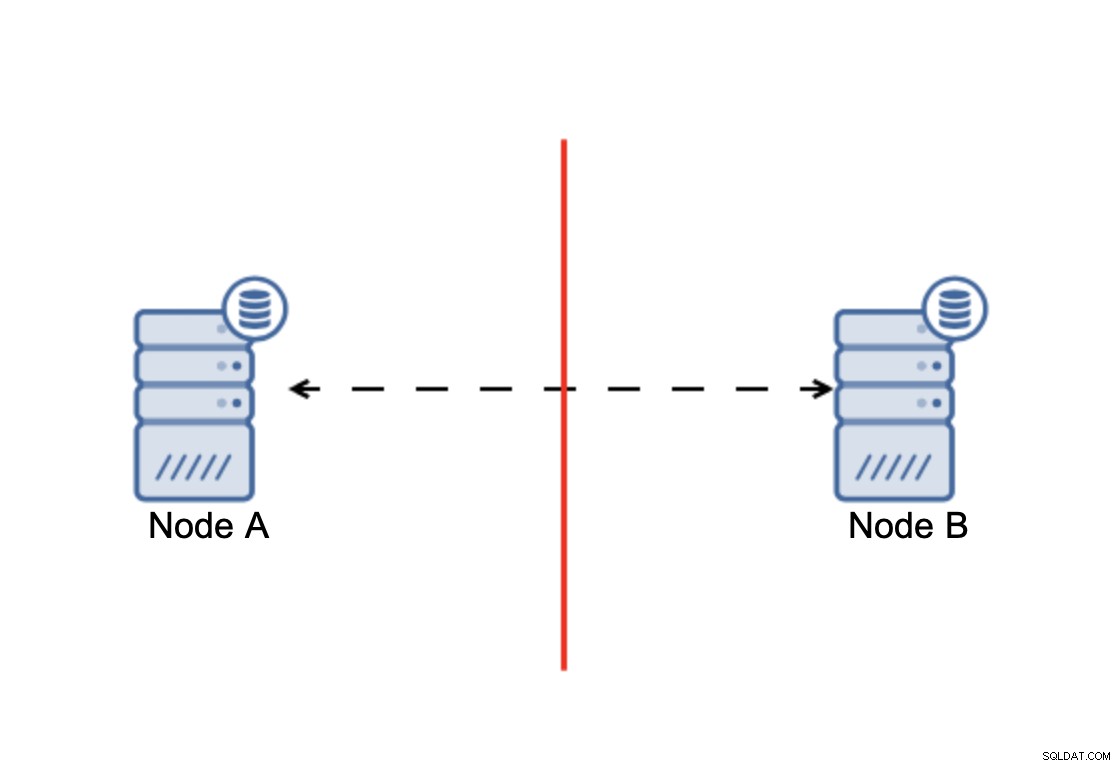
Když dojde k rozdělení sítě, skončíte se dvěma částmi shluk, z nichž každý se skládá z přesně 50 % z celkového počtu uzlů ve shluku. Žádná z těchto částí nemá většinu. Pokud však máte tři uzly, věci jsou jiné:
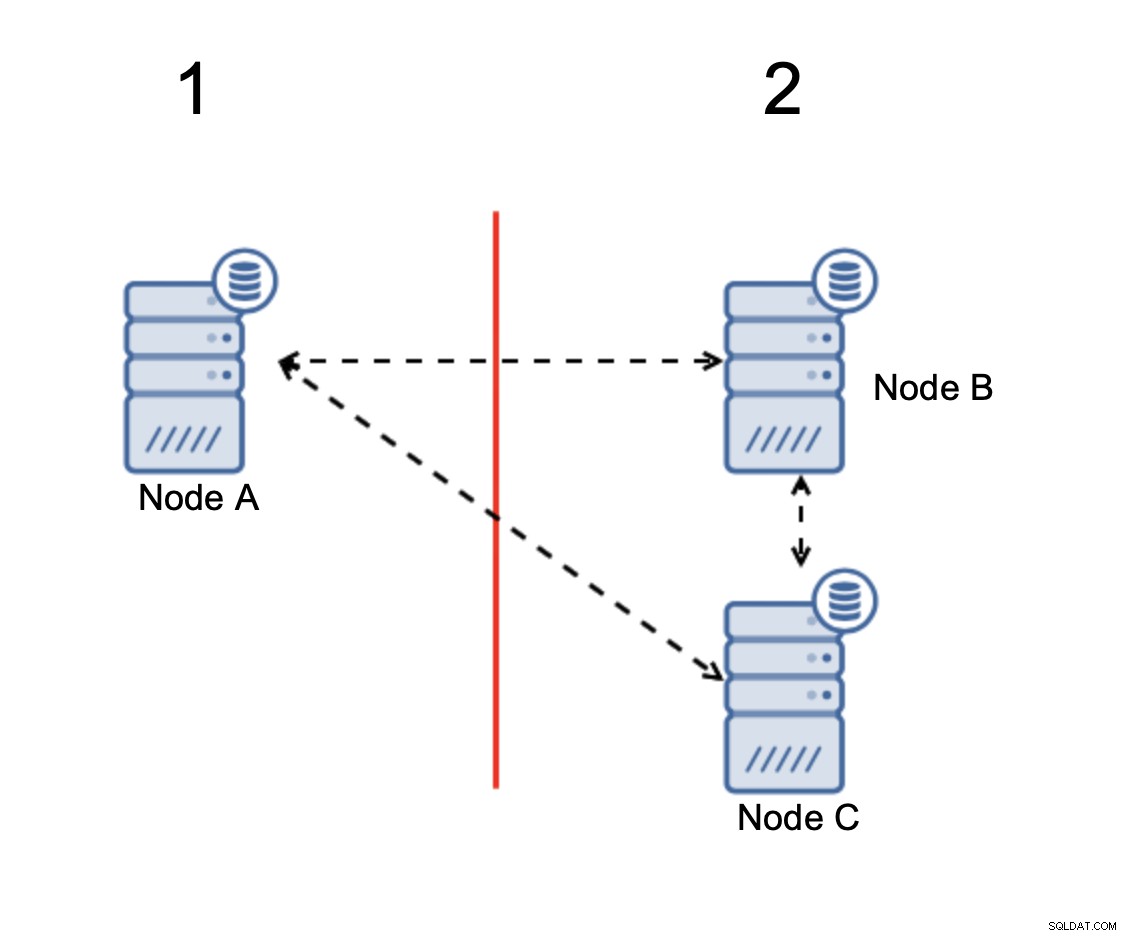
Uzly B a C mají většinu:tato část se skládá ze dvou uzlů mimo ze tří, takže může pokračovat v provozu. Na druhou stranu uzel A představuje pouze 33 % uzlů ve shluku, takže nemá většinu a přestane zvládat provoz, aby se vyhnul rozdělenému mozku.
S takovou implementací je velmi nepravděpodobné, že by došlo k rozdělení mozku (muselo by být zavedeno prostřednictvím některých podivných a neočekávaných stavů sítě, podmínek závodu nebo zjevně chyb v kódu shlukování. I když to není nemožné setkat se za takových podmínek je použití jednoho z řešení, které je založeno na kvoru, nejlepší možností, jak se vyhnout rozdělení mozku, které v tuto chvíli existuje.
Asynchronní replikace
Asynchronní replikace sice není ideální volbou, pokud jde o řešení split-brain, ale stále je životaschopnou možností. Před implementací multicloudové databáze s asynchronní replikací byste měli zvážit několik věcí.
Za prvé, převzetí služeb při selhání. Asynchronní replikace přichází s jedním zapisovačem – zapisovatelný by měl být pouze master a ostatní uzly by měly obsluhovat provoz pouze pro čtení. Výzvou je, jak se vypořádat s hlavním selháním?
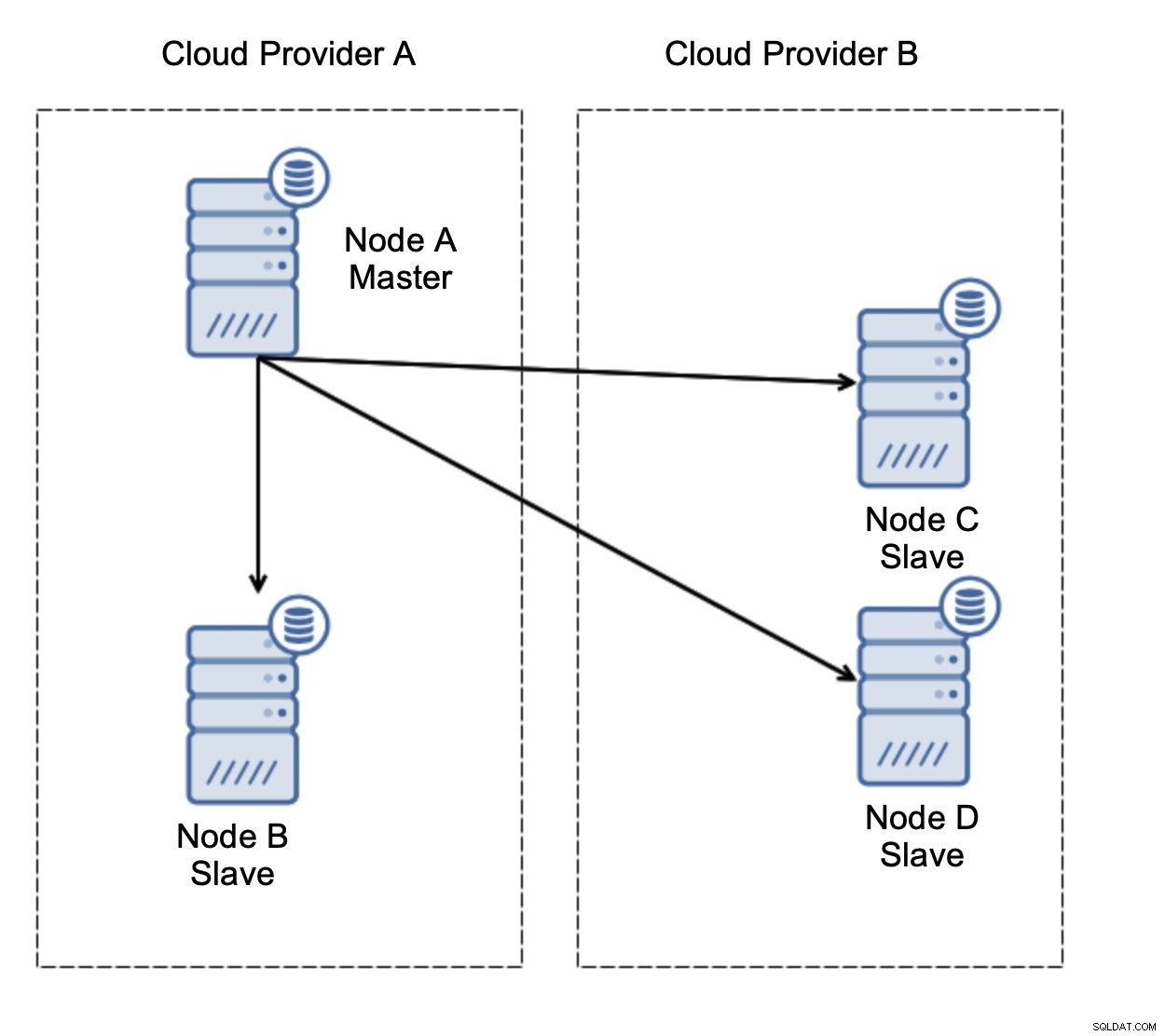
Uvažujme nastavení jako na obrázku výše. Máme dva cloudové poskytovatele, v každém dva uzly. Poskytovatel A hostí také master. Co by se mělo stát, když mistr selže? Jeden z otroků by měl být povýšen, aby bylo zajištěno, že databáze bude i nadále funkční. V ideálním případě by se mělo jednat o automatizovaný proces, který zkrátí dobu potřebnou k uvedení databáze do provozního stavu. Co by se však stalo, kdyby došlo k rozdělení sítě? Jak se očekává, že ověříme stav clusteru?
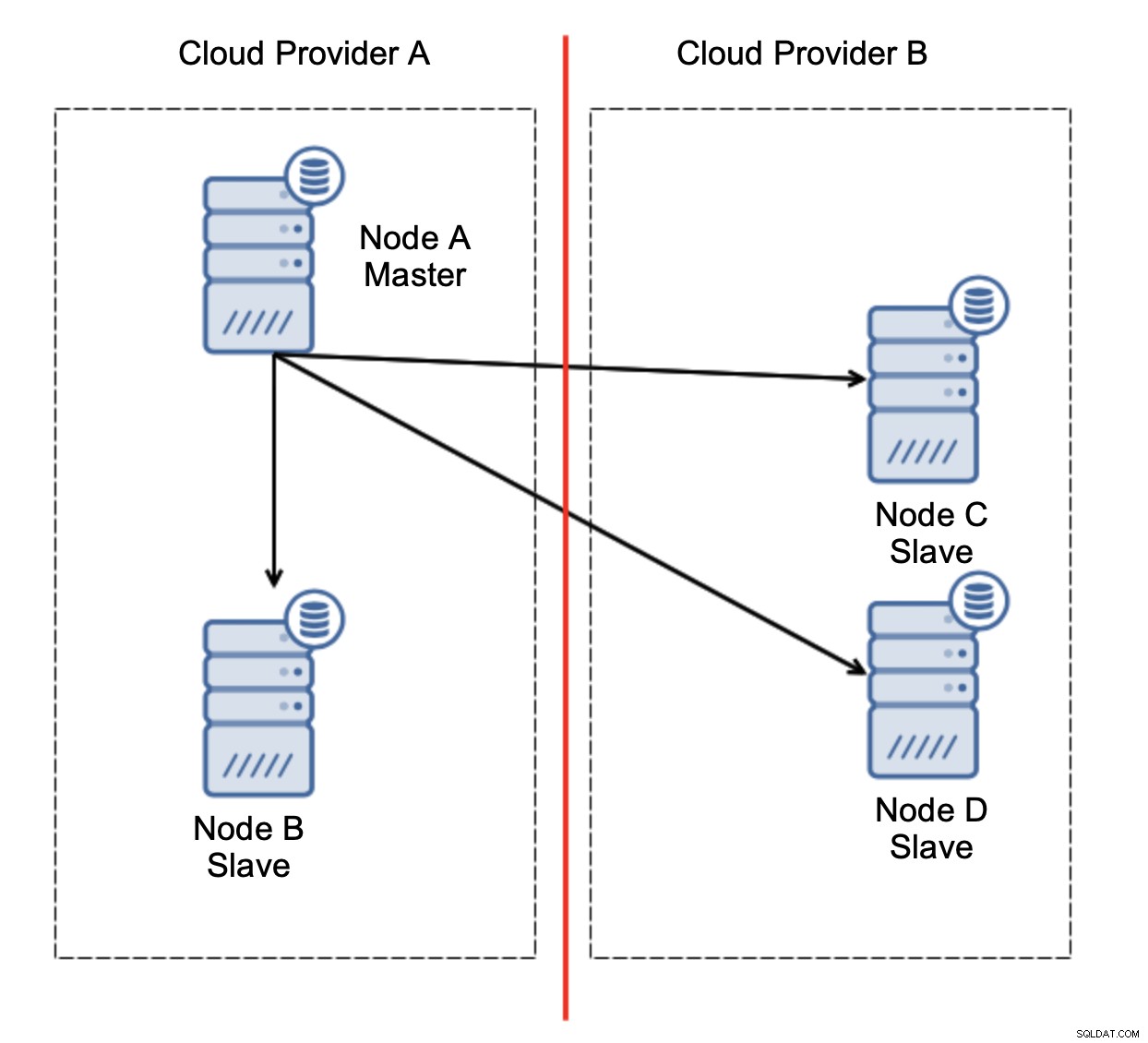
Tady je výzva. Mezi dvěma poskytovateli cloudu dochází ke ztrátě síťového připojení. Z hlediska uzlů C a D jsou uzel B i hlavní uzel A offline. Měl by být uzel C nebo D povýšen na master? Ale starý master je stále aktivní - nespadl, jen není dostupný přes síť. Pokud bychom propagovali jeden z uzlů umístěných u poskytovatele B, skončili bychom se dvěma zapisovatelnými mastery, dvěma datovými sadami a rozděleným mozkem:
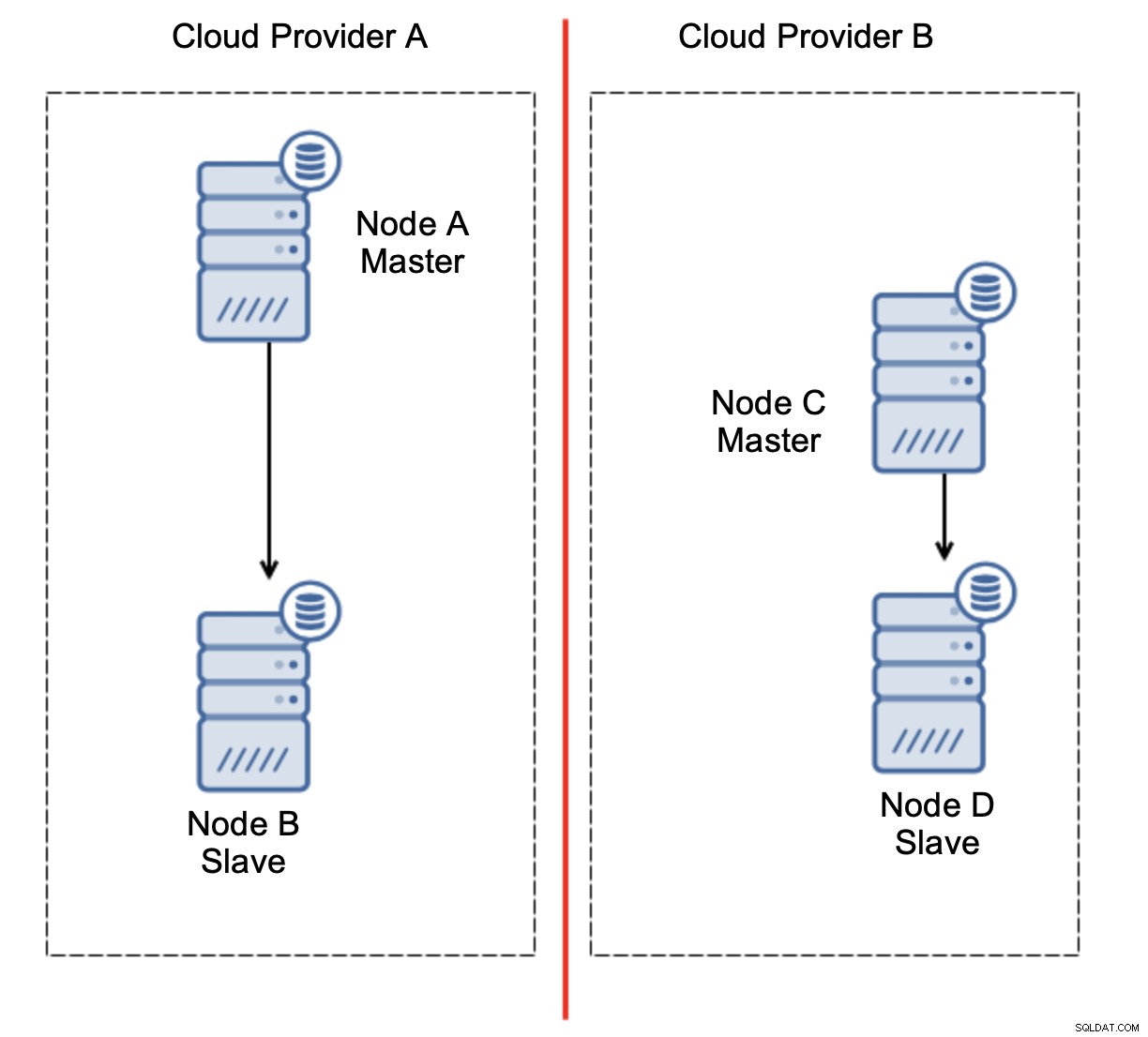
Tohle rozhodně není něco, co bychom chtěli. Zde je několik možností. Za prvé, můžeme definovat pravidla pro převzetí služeb při selhání tak, že k převzetí služeb při selhání může dojít pouze v jednom ze segmentů sítě, kde je umístěn hlavní server. V našem případě by to znamenalo, že pouze uzel B by mohl být automaticky povýšen na master. Tímto způsobem můžeme zajistit, že k automatickému převzetí služeb při selhání dojde, pokud je uzel A mimo provoz, ale nebude provedena žádná akce, pokud dojde k rozdělení sítě. Některé z nástrojů, které vám mohou pomoci zvládnout automatizovaná převzetí služeb při selhání (jako je ClusterControl), podporují bílé a černé listiny a umožňují uživatelům definovat, které uzly lze považovat za kandidáty na převzetí služeb při selhání a které by nikdy neměly být použity jako hlavní.
Další možností by bylo implementovat nějaké řešení „vědomí o topologii“. Mohli byste se například pokusit zkontrolovat hlavní stav pomocí externích služeb, jako jsou nástroje pro vyrovnávání zatížení.
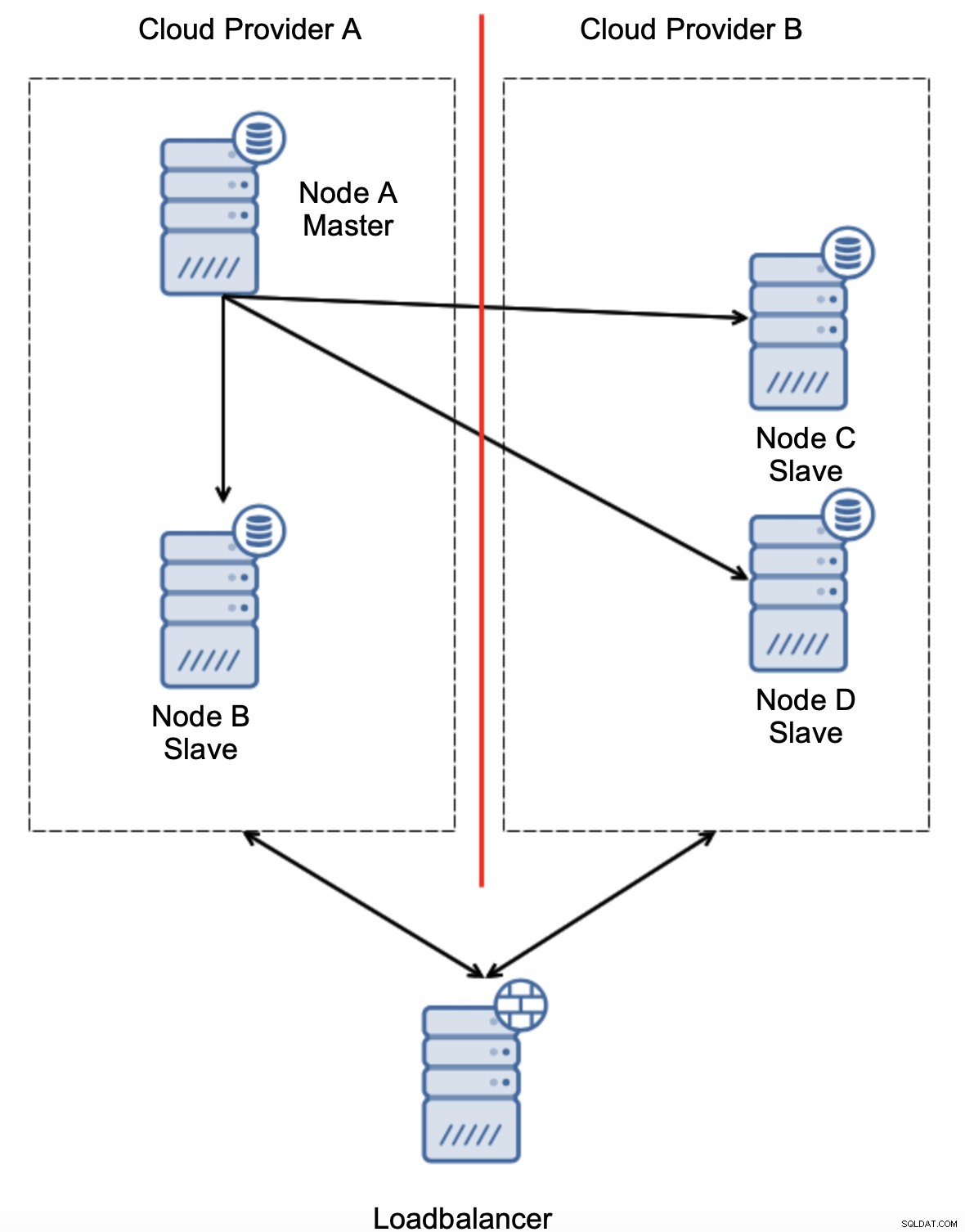
Pokud by automatizace převzetí služeb při selhání mohla zkontrolovat stav topologie, jak jej vidí load balancer, může se stát, že load balancer, umístěný na třetím místě, může skutečně dosáhnout do obou datových center a dát jasně najevo, že uzly u cloudového poskytovatele A nejsou mimo provoz, jen je nelze dosáhnout od cloudového poskytovatele B. v ClusterControl je implementována další vrstva kontrol.
Nakonec, ať už použijete jakýkoli nástroj k implementaci automatického převzetí služeb při selhání, může být také navržen tak, aby podporoval kvorum. Pak se třemi uzly na třech místech můžete snadno určit, která část infrastruktury by měla být udržována při životě a která ne.
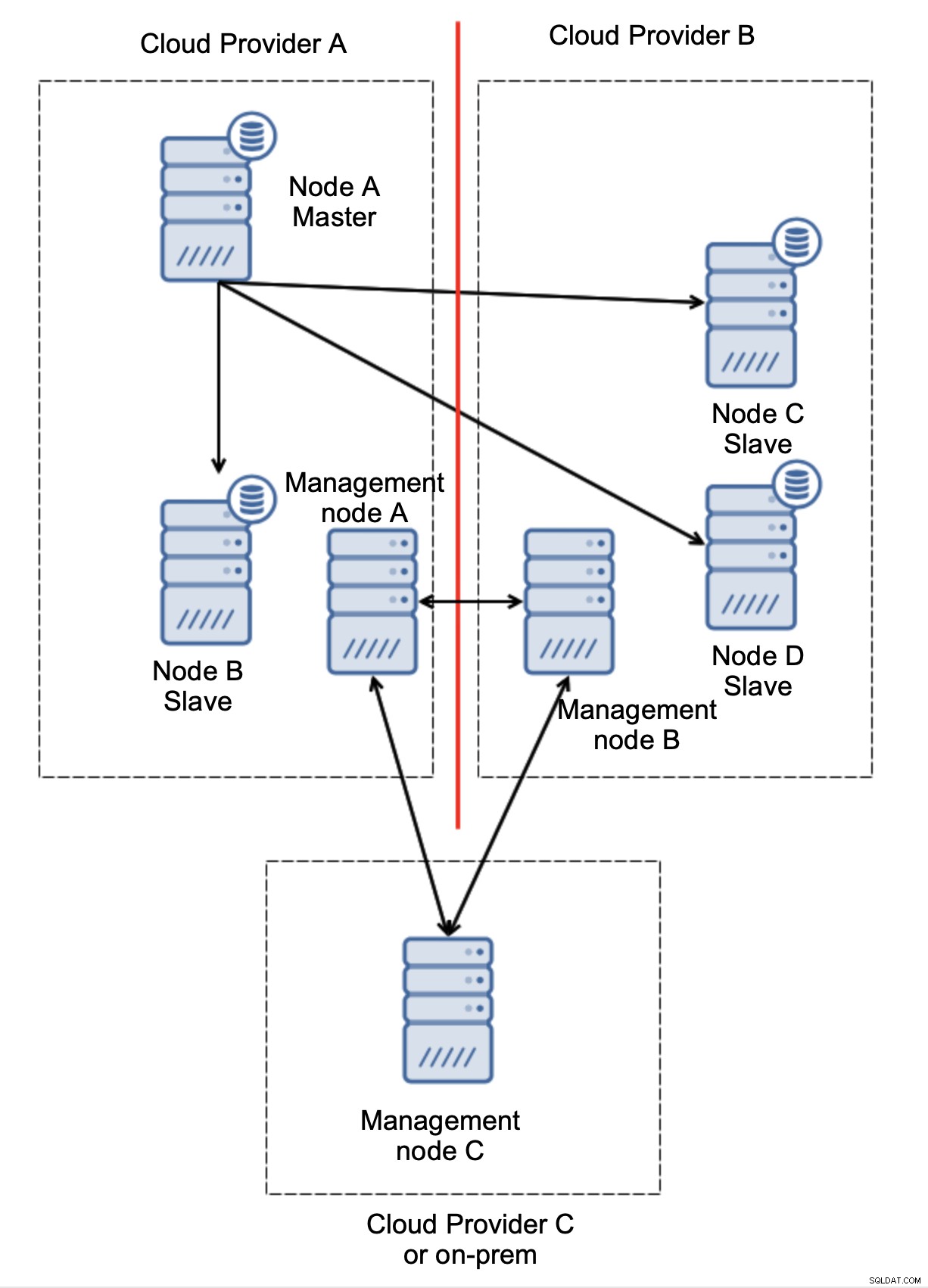
Zde jasně vidíme, že problém souvisí pouze s konektivitou mezi poskytovateli A a B. Řídící uzel C bude fungovat jako relé a v důsledku toho by nemělo být spuštěno žádné převzetí služeb při selhání. Na druhou stranu, pokud je jedno datové centrum zcela odříznuto:

Je také docela jasné, co se stalo. Řídicí uzel A bude hlásit, že nemůže oslovit většinu klastru, zatímco řídicí uzly B a C budou tvořit většinu. Na tom je možné stavět a například psát skripty, které budou spravovat topologii podle stavu řídícího uzlu. To by mohlo znamenat, že skripty spouštěné v cloudovém poskytovateli A zjistí, že uzel správy A netvoří většinu, a zastaví všechny databázové uzly, aby se zajistilo, že v děleném cloudovém poskytovateli nedojde k žádným zápisům.
ClusterControl lze při nasazení v režimu vysoké dostupnosti považovat za řídicí uzly, které jsme použili v našich příkladech. Tři uzly ClusterControl nad protokolem RAFT vám mohou pomoci určit, zda je daný segment sítě rozdělen nebo ne.
Závěr
Doufáme, že vám tento příspěvek na blogu poskytne určitou představu o scénářích rozděleného mozku, ke kterým může dojít při nasazení MySQL na více cloudových platformách.