Obecně řečeno, nejlepší druh řazení je ten, kterému se úplně vyhýbáme. Pečlivým indexováním a někdy i kreativním psaním dotazů můžeme často odstranit potřebu operátoru řazení z plánů provádění. Tam, kde jsou data, která mají být tříděna, velká, může vyhnutí se tomuto druhu třídění vést k velmi významným zlepšením výkonu.
Druhý nejlepší druh řazení je ten, kterému se nemůžeme vyhnout, ale který si vyhrazuje přiměřené množství paměti a celou nebo většinu z ní využívá k něčemu, co stojí za to. Být užitečný může mít mnoho podob. Někdy se řazení může více než vyplatit tím, že umožní pozdější operaci, která na setříděném vstupu funguje mnohem efektivněji. Jindy je řazení prostě nezbytné a my ho musíme udělat co nejúčinnější.
Pak přicházejí druhy, kterým se obvykle chceme vyhnout:ty, které si rezervují mnohem více paměti, než potřebují, a ty, které si rezervují příliš málo. Poslední případ je ten, na který se většina lidí zaměřuje. S nedostatkem paměti vyhrazené (nebo dostupné) pro dokončení požadované operace řazení v paměti operátor Sort, až na několik výjimek, vysype datové řádky do tempdb . Ve skutečnosti to téměř vždy znamená zapisovat třídicí stránky do fyzického úložiště (a později je samozřejmě znovu číst).
V moderních verzích SQL Server má rozlité řazení za následek výstražnou ikonu v plánech po spuštění, která může obsahovat podrobnosti o tom, kolik dat bylo rozlito, kolik vláken bylo zapojeno a úroveň rozlití.
Pozadí:Úrovně rozlití
Zvažte úkol seřadit 4000 MB dat, když máme k dispozici pouze 500 MB paměti. Je zřejmé, že nemůžeme seřadit celou sadu v paměti najednou, ale můžeme úlohu rozdělit:
Nejprve načteme 500 MB dat, roztřídíme je v paměti a výsledek zapíšeme na disk. Toto provedení celkem 8krát spotřebuje celých 4000 MB vstupu, což má za následek 8 sad setříděných dat o velikosti 500 MB. Druhým krokem je provedení 8cestného sloučení setříděných datových sad. Všimněte si, že sloučení je vyžadováno, nikoli jednoduché zřetězení sad, protože je zaručeno, že data budou tříděna podle potřeby pouze v rámci konkrétní 500 MB sady v mezistupni.
V zásadě bychom mohli číst a slučovat jeden řádek najednou z každého z osmi běhů řazení, ale to by nebylo příliš efektivní. Místo toho čteme první část každého řazení zpět do paměti, řekněme 60 MB. To spotřebuje 8 x 60 MB =480 MB z 500 MB, které máme k dispozici. Poté můžeme na chvíli efektivně provést 8cestné sloučení v paměti a uložit do vyrovnávací paměti konečný seřazený výstup s 20 MB paměti, která je stále k dispozici. Když se každý z vyrovnávací paměti běhu řazení vyprázdní, načteme do paměti novou sekci tohoto běhu řazení. Jakmile jsou všechny série řazení spotřebovány, je řazení dokončeno.
Můžeme zahrnout některé další podrobnosti a optimalizace, ale to je základní náčrt úniku úrovně 1, známého také jako jednoprůchodový únik. K vytvoření konečného setříděného výstupu je vyžadován jeden další průchod daty.
Nyní by n-way sloučení teoreticky mohlo pojmout jakousi libovolnou velikost, v libovolném množství paměti, jednoduše zvýšením počtu mezilehlých místně tříděných sad. Problém je v tom, že jak se 'n' zvyšuje, nakonec čteme a zapisujeme menší kusy dat. Například třídění 400 GB dat v 500 MB paměti by znamenalo něco jako 800směrné sloučení, kdy by v jednu chvíli bylo z každé mezitříděné sady v paměti pouze asi 0,6 MB (800 x 0,6 MB =480 MB, ponechává určitý prostor pro výstupní vyrovnávací paměť).
K vyřešení tohoto problému lze použít více průchodů sloučení. Obecnou myšlenkou je postupně slučovat malé kousky do větších, dokud nebudeme schopni efektivně produkovat finální tříděný výstupní proud. V příkladu to může znamenat sloučení 40 z 800 sad seřazených při prvním průchodu najednou, což povede ke 20 větším blokům, které lze poté znovu sloučit a vytvořit výstup. S celkem dvěma extra průchody přes data by to byl únik úrovně 2 a tak dále. Naštěstí lineární nárůst úrovně úniku umožňuje exponenciální nárůst velikosti třídění, takže úrovně hlubokého třídění jsou zřídka nutné.
Úroveň 15 000
V tuto chvíli byste se možná divili, jaká kombinace malého přidělení paměti a enormní velikosti dat by mohla vést k přelití na úroveň 15 000. Snažíte se roztřídit celý internet do 1 MB paměti? Možná, ale je to příliš těžké na demo. Abych byl upřímný, nemám ponětí, zda je taková skutečně vysoká úroveň úniku v SQL Server vůbec možná. Cílem zde (podvod, jistě) je přimět SQL Server k hlášení únik úrovně 15 000.
Klíčovou složkou je rozdělení. Od SQL Server 2012 nám bylo povoleno (pohodlné) maximálně 15 000 oddílů na objekt (podpora 15 000 oddílů je k dispozici také u 2008 SP2 a 2008 R2 SP1, ale musíte to povolit ručně pro každou databázi a být si vědomi všech upozornění).
První věc, kterou budeme potřebovat, je funkce oddílu s 15 000 prvky a související schéma oddílů. Abychom se vyhnuli skutečně enormnímu inline bloku kódu, používá následující skript ke generování požadovaných příkazů dynamické SQL:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Skript lze snadno upravit na nižší číslo v případě, že se vaše nastavení potýká s 15 000 oddíly (zejména z hlediska paměti, jak brzy uvidíme). Dalšími kroky jsou vytvoření normální (nerozdělené) tabulky haldy s jedním sloupcem s celým číslem a poté do ní naplnění celými čísly od 1 do 15 000 včetně:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; To by mělo být dokončeno za 100 ms nebo tak. Pokud máte k dispozici číselnou tabulku, můžete ji místo toho použít pro lepší zážitek ze sady. Způsob naplnění základní tabulky není důležitý. Abychom získali našich 15 000 úrovní, vše, co nyní musíme udělat, je vytvořit rozdělený seskupený index na stole:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Doba provedení velmi závisí na používaném úložném systému. Na mém notebooku, který používám docela typický spotřebitelský SSD z doby před několika lety, to trvá asi 20 sekund, což je docela významné, vezmeme-li v úvahu, že se zabýváme celkem pouze 15 000 řádky. Na virtuálním počítači Azure s poměrně nízkou specifikací a docela strašným I/O výkonem trval stejný test 20 minut.
Analýza
Plán provádění pro sestavení indexu je:
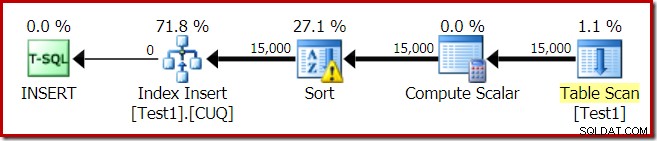
Skenování tabulky přečte 15 000 řádků z naší tabulky haldy. Compute Scalar vypočítá číslo cílového indexového oddílu pro každý řádek pomocí interní funkce RangePartitionNew() . Třídění je nejzajímavější částí plánu, takže se na něj podíváme podrobněji.
Nejprve upozornění na řazení, jak je zobrazeno v Průzkumníkovi plánu:

Podobné varování z SSMS (převzato z jiného běhu skriptu):
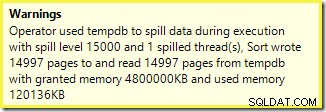
První věc, kterou je třeba poznamenat, je zpráva o úrovni 15 000 třídění, jak bylo slíbeno. Není to úplně přesné, ale detaily jsou docela zajímavé. Řazení v tomto plánu má Partition ID vlastnost, která se běžně nevyskytuje:
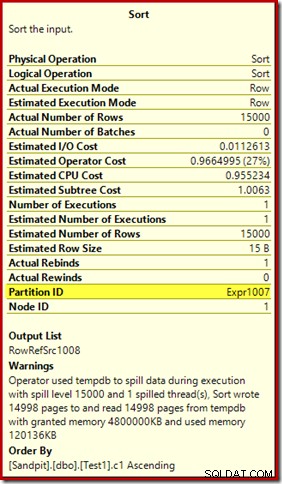
Tato vlastnost je nastavena stejně jako definice interní rozdělovací funkce v Compute Scalar.
Toto je nezarovnané sestavení indexu , protože zdroj a cíl mají různá uspořádání rozdělení. V tomto případě tento rozdíl vzniká, protože zdrojová tabulka haldy není rozdělena, ale cílový index ano. V důsledku toho je za běhu vytvořeno 15 000 samostatných řazení:jeden na neprázdný cílový oddíl. Každé z těchto řazení se rozlije na úroveň 1 a SQL Server sečte všechny tyto úniky, aby výsledná úroveň seřazení byla 15 000.
15 000 samostatných druhů vysvětluje velkou paměť. Každá instance řazení má minimální velikost 40 stránek, což je 40 x 8 kB =320 kB. 15 000 řazení proto vyžaduje minimálně 15 000 x 320 KB =4 800 000 KB paměti. To je jen necelých 4,6 GB RAM vyhrazené výhradně pro dotaz, který třídí 15 000 řádků obsahujících jeden celočíselný sloupec. A každý druh se vysype na disk, přestože obdrží pouze jeden řádek! Pokud by se pro sestavení indexu použil paralelismus, přidělení paměti by mohlo být dále navýšeno o počet vláken. Všimněte si také, že jeden řádek je zapsán na stránce, což vysvětluje počet stránek zapsaných a přečtených z databáze tempdb. Zdá se, že došlo ke sporu, což znamená, že hlášený počet stránek je často o několik méně než 15 000.
Tento příklad samozřejmě odráží okrajový případ, ale stále je těžké pochopit, proč každé řazení vysype svůj jeden řádek namísto řazení v paměti, kterou dostal. Možná je to z nějakého důvodu záměrné, nebo je to prostě chyba. Ať je to jakkoli, stále je docela zábavné vidět, jak několik stovek KB dat trvá tak dlouho s přidělením 4,6 GB paměti a 15 000 úrovněmi. Pokud se s tím možná nesetkáte v produkčním prostředí. Každopádně je třeba si toho být vědom.
Zavádějící zpráva o úniku 15 000 úrovní se do značné míry týká omezení reprezentace ve výstupu plánu show. Základní problém je něco, co vzniká na mnoha místech, kde dochází k opakovaným akcím, například na vnitřní straně spojování vnořených smyček. Určitě by bylo užitečné mít v těchto případech možnost vidět přesnější členění namísto celkového součtu. Postupem času se tato oblast trochu zlepšila, takže nyní máme pro některé operace více informací o plánu na vlákno nebo oddíl. Stále je však před námi dlouhá cesta.
Stále je méně než užitečné, že 15 000 samostatných úniků úrovně 1 je zde hlášeno jako jeden únik 15 000 úrovně.
Testovací varianty
Tento článek je spíše o zdůraznění omezení informací o plánu a potenciálu špatného výkonu při použití extrémního počtu oddílů, než o zefektivnění konkrétní ukázkové operace, ale je zde několik zajímavých variant, na které se chci také podívat. .
Online, řazení v tempdb
Provádění stejné operace vytvoření rozděleného indexu s ONLINE = ON, SORT_IN_TEMPDB = ON netrpí stejně obrovským přidělením paměti a přeléváním:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Všimněte si, že pomocí ONLINE sama o sobě nestačí. Ve skutečnosti to vede ke stejnému plánu jako předtím se všemi stejnými problémy, plus další režii pro online vytváření každého indexového oddílu. Pro mě to má za následek dobu provedení hodně přes minutu. Bůh ví, jak dlouho by to trvalo na instanci Azure s nízkou specifikací a děsivým I/O výkonem.
Každopádně plán provádění s ONLINE = ON, SORT_IN_TEMPDB = ON je:

Třídění se provádí před výpočtem cílového čísla oddílu. Nemá vlastnost ID oddílu, takže je to jen normální řazení. Celá operace běží asi deset sekund (ještě je potřeba vytvořit spoustu oddílů). Rezervuje méně než 3 MB paměti a využívá maximálně 816 KB. Docela lepší než 4,6 GB a 15 000 úniků.
Nejprve index, potom data
Podobné výsledky lze získat zápisem dat nejprve do tabulky haldy:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Dále vytvořte prázdnou rozdělenou klastrovanou tabulku a vložte data z haldy:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; To trvá asi deset sekund, s přidělením 2 MB paměti a bez přelévání:
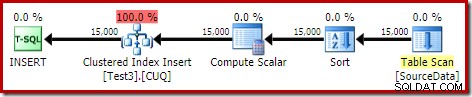
Řazení by se samozřejmě dalo také úplně vyhnout indexováním (nerozdělené) zdrojové tabulky a vložením dat v pořadí podle indexu (nejlepší řazení není žádné řazení, pamatujte).
Rozdělená halda, poté data a poté index
Pro tuto poslední variantu nejprve vytvoříme rozdělenou haldu a načteme 15 000 testovacích řádků:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Ten skript běží sekundu nebo dvě, což je docela dobré. Posledním krokem je vytvoření rozděleného seskupeného indexu:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
To je naprostá katastrofa, jak z hlediska výkonu, tak z hlediska informací o plánu show. Samotná operace běží necelou minutu s následujícím plánem provádění:

Toto je plán vložek se společným umístěním. Konstantní skenování obsahuje řádek pro každé ID oddílu. Vnitřní strana smyčky hledá aktuální rozdělení haldy (ano, hledání na haldě). Řazení má vlastnost ID oddílu (přestože je konstantní pro každou iteraci smyčky), takže existuje řazení na oddíl a nežádoucí chování při přelévání. Varování statistik v tabulce haldy je falešné.
Kořen plánu vkládání uvádí, že bylo vyhrazeno přidělení paměti 1 MB, přičemž bylo použito maximálně 144 kB:
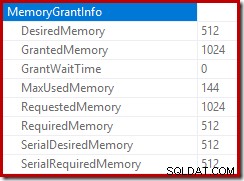
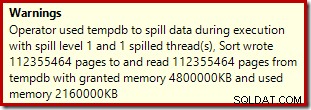
Operátor řazení nehlásí únik úrovně 15 000, ale jinak dělá úplný nepořádek s iterační matematikou po smyčkách:

Sledování přidělení paměti DMV během provádění ukazuje, že tento dotaz ve skutečnosti rezervuje pouze 1 MB, přičemž na každou iteraci smyčky je použito maximálně 144 kB. (Naopak rezervace 4,6 GB paměti v prvním testu je naprosto pravá.) To je samozřejmě matoucí.
Problém (jak bylo zmíněno dříve) je v tom, že SQL Server je zmatený ohledně toho, jak nejlépe hlásit, co se stalo během mnoha iterací. Pravděpodobně není praktické zahrnout informace o výkonu plánu na oddíl a iteraci, ale nelze uniknout skutečnosti, že současné uspořádání občas vytváří matoucí výsledky. Můžeme jen doufat, že jednoho dne bude možné najít lepší způsob, jak hlásit tento typ informací, v konzistentnějším formátu.