Minulý pátek jsem uspořádal webový seminář o Plan Explorer 3.0, nových funkcích a o tom, proč jsme se rozhodli odstranit edici PRO a rozdat všechny funkce zdarma . Pokud jste to nestihli, můžete se na webinář podívat zde:
- Webový seminář Plan Explorer 3.0
Bylo předloženo mnoho skvělých otázek a pokusím se je zde zodpovědět. V různých bodech prezentace jsme také položili několik vlastních otázek a uživatelé se jich zeptali na podrobnosti, takže začnu otázkami průzkumu. Měli jsme maximum 502 účastníků a v níže uvedených grafech uvedu, kolik lidí odpovědělo na jednotlivé otázky. Vzhledem k tomu, že první otázka byla položena před technickým zahájením webináře, odpovědělo na ni menší množství lidí.
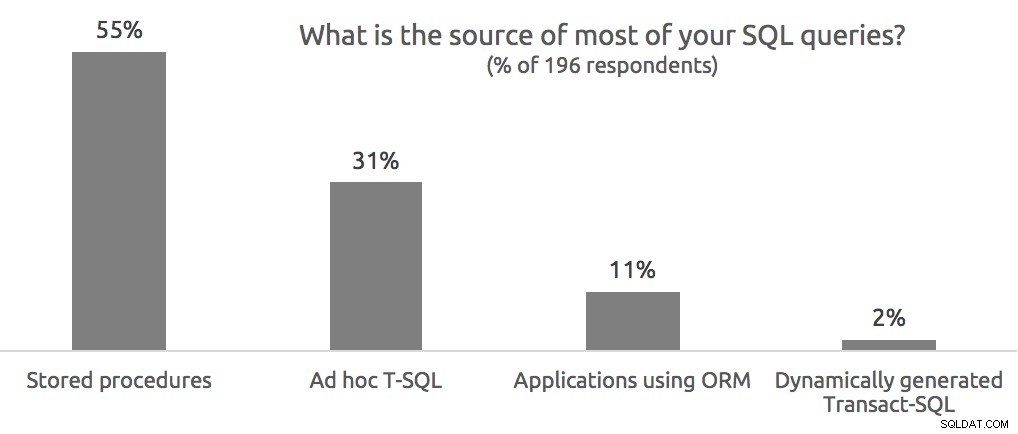
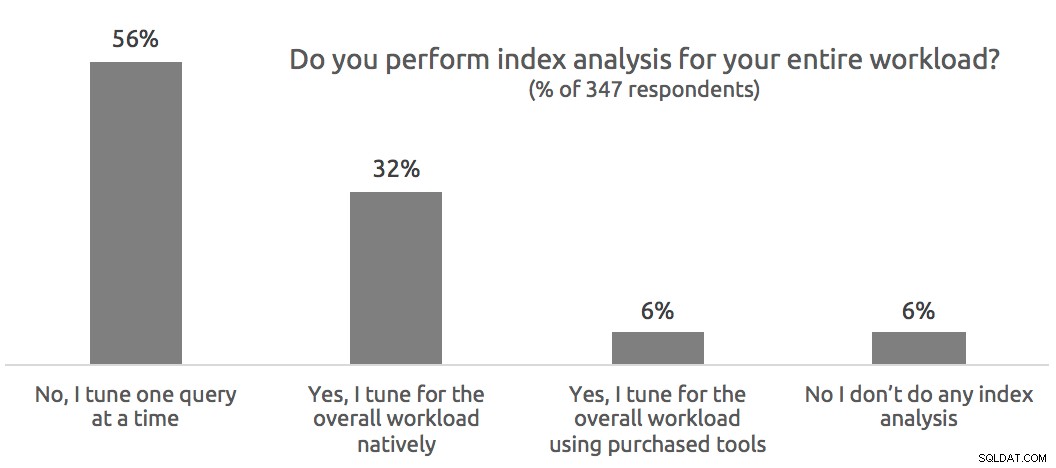
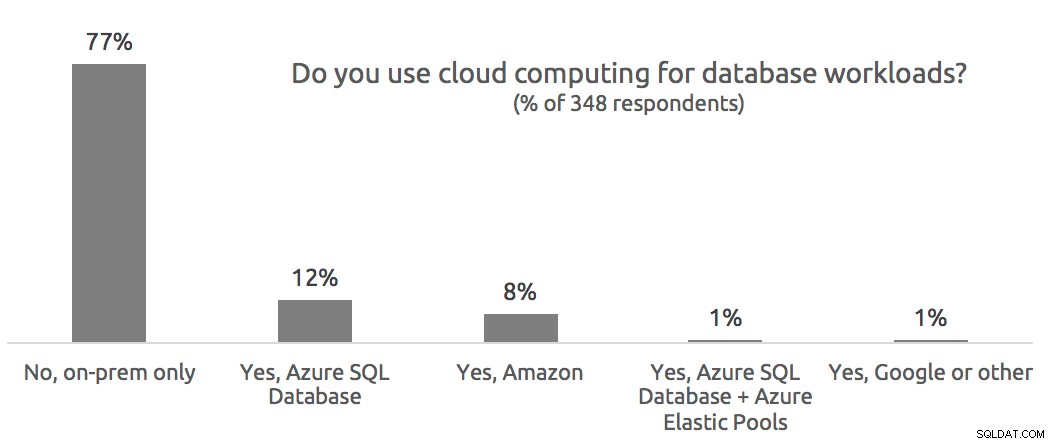
Dotazy publika
Otázka:Jsou k dispozici ukázky kódu?
A: Ano, tři soubory relací, které jsem použil pro své ukázky, jsou k dispozici zde:
- Ukázky webinářů Plan Explorer 3.0
Můžete je otevřít v nejnovějším sestavení Plan Exploreru, ale pokud chcete některý z dotazů spustit znovu lokálně, budete potřebovat AdventureWorks2014 (se zvětšujícím skriptem od Jonathana Kehayiase) a/nebo novou vzorovou databázi Wide World Importers.
O:Takže vše, co je dnes zobrazeno, je v novém, jednotném a bezplatném Průzkumníku plánů? Pokud ano, jaký je nový model příjmů vaší společnosti?A: Vždy mě překvapí, když narazím na lidi, kteří si myslí, že vše, co nabízíme, je Průzkumník plánů (vidím je osobně a také u Gregova příspěvku na blogu bylo několik podobných komentářů). Náš skutečný chleba s máslem je v naší monitorovací platformě a doufáme, že vaše pozitivní zkušenosti s Plan Explorer vás přivedou k vyzkoušení našich dalších řešení.
Otázka:Stále používáme SQL Server 2008. Má používání PE oproti SSMS výhody?A: Ano, i když přijdete o některé funkce (jako je Live Query Profile), v porovnání s SSMS máte k dispozici mnohem více informací a my se snažíme, aby konkrétní problémy byly mnohem lépe zjistitelné.
Otázka:Bude Live Query Profile fungovat pro SQL Server 2014?A: Ano, pokud je použita aktualizace Service Pack 1, protože funkce závisí na DMV, který byl přidán do SQL Server 2014 SP1.
Otázka:Jaká jsou omezení s ohledem na SQL Server 2012? Mohu tento nástroj vůbec použít?A: Absolutně. Omezení, které jsem uvedl během webináře o SQL Server 2012 a nižších, je, že nejsou schopny zachytit data profilu Live Query.
O:Jsou data shromažďována pouze pro SQL Server 2014 a vyšší? Co když je nainstalován SQL Server 2014, ale kompatibilita je nastavena na rok 2012?A: Ano, Live Query Profile (a grafy prostředků) funguje v SQL Server 2014 (alespoň s SP1), SQL Server 2016 a Azure SQL Database. Není ovlivněn úrovní kompatibility.
Otázka:Která verze SQL Serveru je potřeba k získání informací o statistikách čekání zpět?
A: Shromažďování statistik čekání se opírá o relaci Extended Events, takže musíte používat SQL Server 2008 nebo vyšší a spouštět v kontextu uživatele nebo přihlášení s dostatečnými oprávněními k vytvoření a zrušení relace Extended Events (CONTROL SERVER v SQL Server 2008 a 2008 R2 a ALTER ANY EVENT SESSION v SQL Server 2012 a vyšší).
A: Na tyto dvě otázky bylo mnoho variací a podle toho, jak to vypadalo, lidé si během webináře aktivně hráli s novou verzí a neviděli data analýzy indexu ani data profilu živého dotazu. Pokud máte existující plán zachycený z SSMS nebo dřívější verze Průzkumníka plánů, nebudou zde žádné informace k zobrazení.
Aby bylo možné shromáždit Analýzu indexu data, musíte vygenerovat odhadovaný nebo skutečný plán z Průzkumníka plánu. Chcete-li zobrazit mřížku sloupců a indexů, musíte vybrat Vybraná operace:v rozevíracím seznamu v horní části karty Analýza indexu.
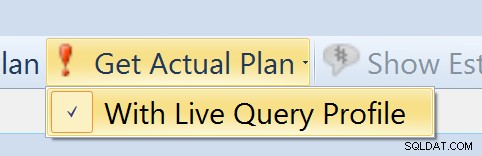
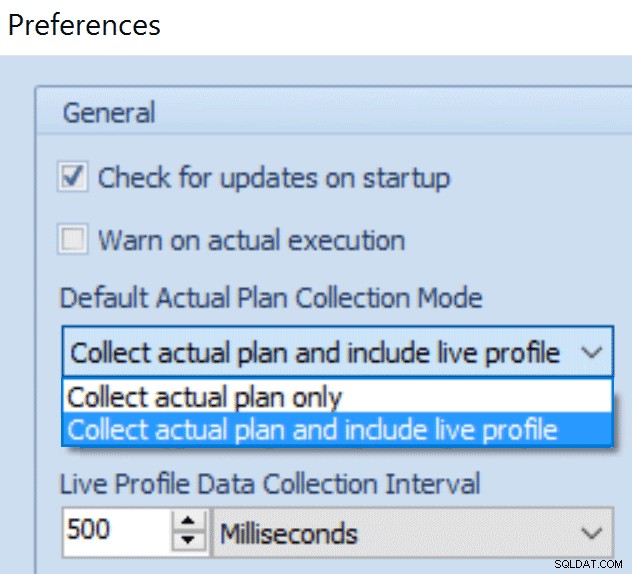
Za účelem shromažďování živého profilu dotazu data, musíte vygenerovat skutečný plán z Průzkumníka plánu a běžet proti verzi 2014 SP1 nebo lepší. Musíte se také ujistit, že jste vybrali možnost „S profilem živého dotazu“ (viz obrázek vpravo), a počkat na dokončení dotazu, než se grafy vykreslí. V budoucí verzi se grafy budou vykreslovat v reálném čase, ale v této verzi to děláme až po shromáždění všech dat.
Otázka:Funguje profil Live Query Profile proti klonovaným databázím v SQL Server 2014 SP2?A: Ano, bude to fungovat, ale neposkytne to mnoho informací, protože klonovaná databáze je prázdná – v plánu uvidíte správné odhady, ale skutečné hodnoty budou všechny 0, takže metriky za běhu nebudou představovat žádné realistické nebo smysluplná úzká hrdla. Pokud nevyplňujete klon alternativními daty, jak propaguje Erin Stellato v dřívějším příspěvku. Také si uvědomte, že pokud chcete, aby plány dotazů odrážely skutečné velikosti produkčních dat, měli byste se ujistit, že všechny formy automatických statistik jsou vypnuté, jinak budou aktualizovány při spouštění dotazů a poté budou všechny odhady 0.
Otázka:Funguje nová verze Plan Exploreru s SQL Server 2016?A: Ano. Podporujeme všechny nové operátory plánu SQL Server 2016 a další změny plánu show (viz můj příspěvek „Podpora průzkumníka plánů pro SQL Server 2016“) a doplněk funguje také s nejnovější verzí SSMS (viz můj příspěvek, "Oznamujeme podporu doplňku Plan Explorer pro SSMS 2016").
Otázka:Takže i skutečný plán provádění v SSMS je označen jako odhadovaný náklady?A: Ano to je správně. Když zachytíte data profilu Live Query Profile, můžeme změnit procenta nákladů pro všechny operátory, protože víme se značným stupněm přesnosti, kolik skutečné práce každá operace vykonala (dotaz však musí běžet déle, než je prahová hodnota). To může být zvláště užitečné, pokud řešíte problém se vstupem a výstupem, protože se zdá, že odhady nikdy nezohledňují úzká místa vstupu/výstupu. Následující grafika prochází původními odhady (vždy vám můžeme ukázat, co by vám řekl SSMS), skutečnými hodnotami po přeúčtování a skutečnými hodnotami po přeúčtování a změnou nákladů na „podle I/O“ a šířky čar na "podle velikosti dat":
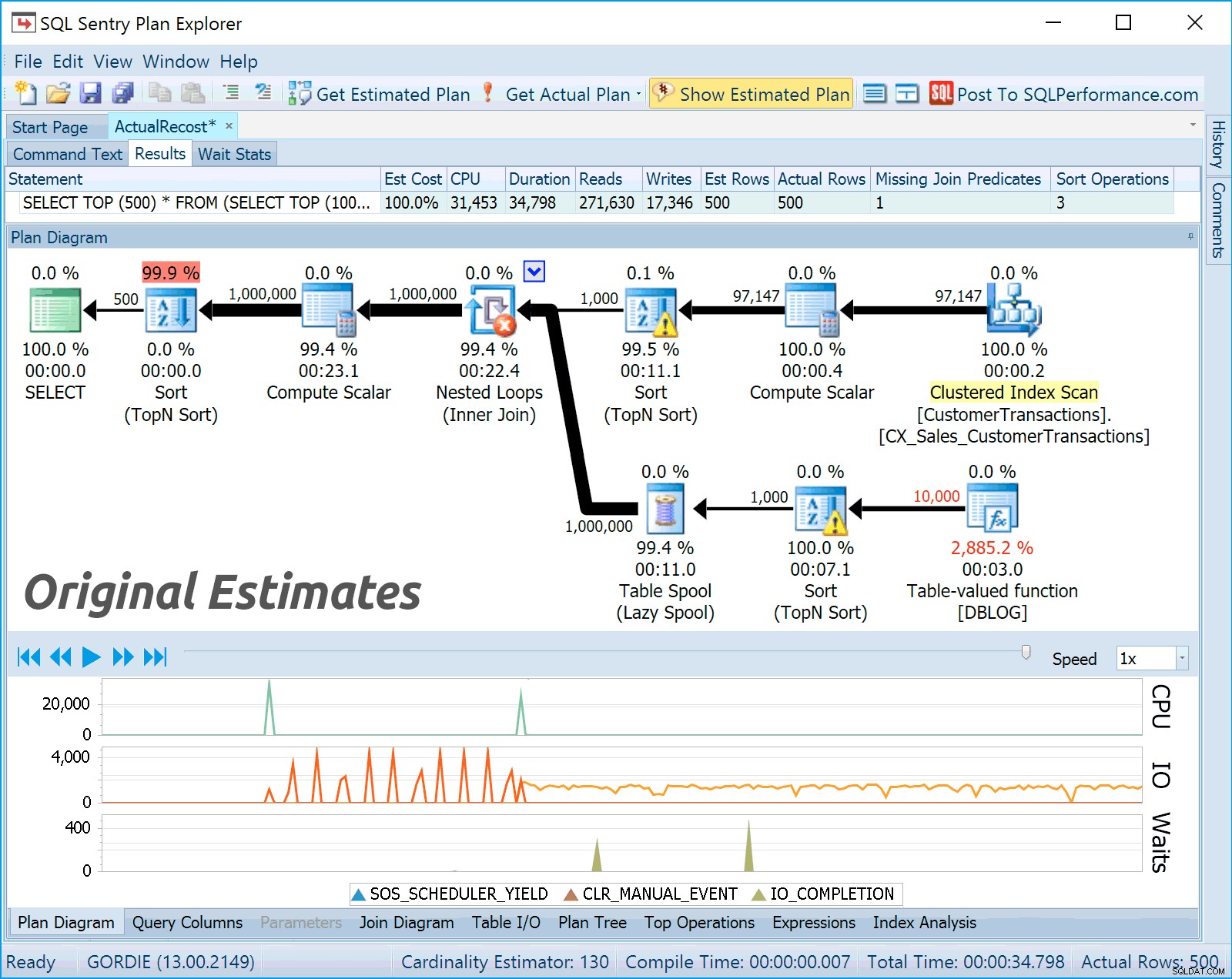
A: Této otázce jsem se věnoval ve webináři, ale aby bylo jasno, myslím si, že vývoj dotazu má dva kroky:(1) zajištění správných výsledků a (2) optimalizace výkonu. Jsem pevně přesvědčen, že v současné době byste měli používat SSMS pro (1) a Plan Explorer pro (2). Dlouho jsem propagoval, že jakmile si lidé budou jisti, že mají správné výsledky, měli by ladit generováním skutečných prováděcí plány z Průzkumníka plánů, protože pro vás shromažďujeme mnohem více informací o běhu. Tyto informace o běhu jsou zvláště užitečné, pokud sdílíte své plány na našem webu otázek a odpovědí, protože díky nim jsou všechny metriky a potenciální úzká místa mnohem zjevnější.
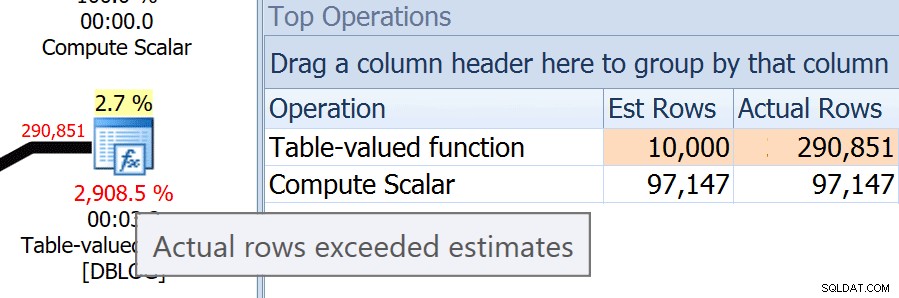
O:Jaká jsou procenta pod operátorem... například 2 885 % pod funkcí?A: Toto procento není cenou, ale spíše procentem řádků, které byly skutečně zpracovány v porovnání s odhadem. V tomto případě SQL Server odhadoval, že funkce vrátí 10 000 řádků, ale za běhu se vrátila téměř 300 000! Pokud umístíte kurzor pouze na toto % číslo, můžete vidět bublinovou nápovědu a rozdíly v odhadu počtu řádků můžete vidět v nápovědě pro operátora nebo v jiných mřížkách, jako jsou Top operace (funkce nyní vrací jiný počet řádků, než tomu bylo během ukázky):
A: Ano, všechny naše panely jsou nastavitelné; mnohé mají připínáček, který přepíná mezi statickým a automatickým skrytím, většinu panelů lze přetahovat (stejně jako ve Visual Studiu, SSMS atd.) a zejména panel přehrávání má nahoře uprostřed malou šipku, která vám umožňuje pro rychlé zobrazení/skrytí:
A: Nejsem si jistý, zda správně interpretuji otázku, ale všechny naše panely jsou kontextově citlivé a prohlášení pro aktuálně zkoumaný plán je zobrazeno jak v mřížce příkazů, tak na panelu Textová data:
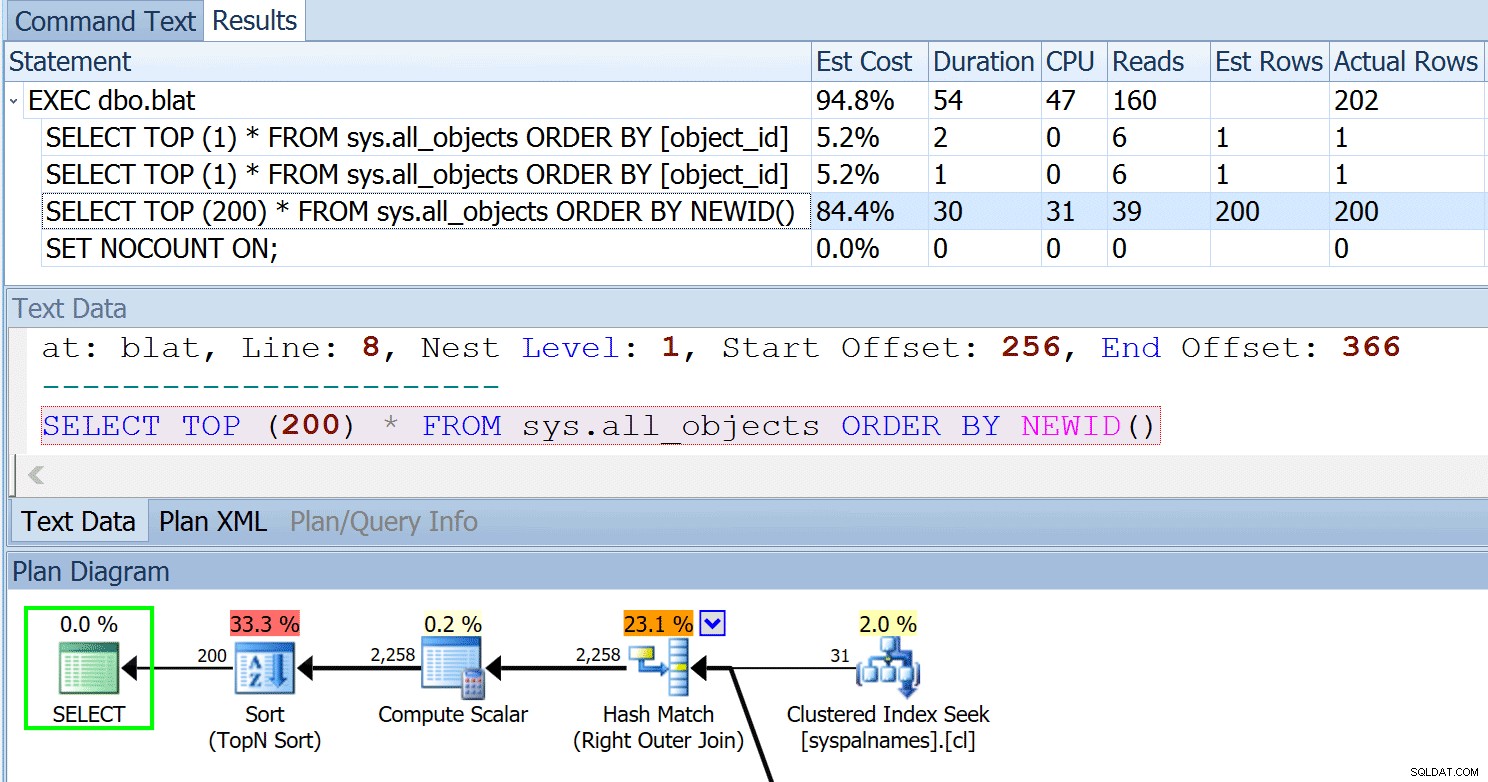
Pokud text příkazu není kvůli délce zcela viditelný, můžete vždy klepnout pravým tlačítkem na buňku a zvolit Kopírovat příkaz do příkazového textu Kopírovat a poté přepnout na tuto kartu. Nebo, pokud nechcete přepsat aktuální obsah záložky Text příkazu, zvolte Kopírovat> Buňka a vložte do nové relace, SSMS nebo jiného editoru.
Otázka:Jak mohu zastavit „Získat skutečný plán“, pokud jsem omylem zahájil 1-hodinový dotaz?A: Pokud je aktuálně spuštěn dotaz, na stavovém řádku vlevo dole je tlačítko Zastavit:
A: Rozhodně máme v plánu v budoucnu učinit skriptování indexu robustnějším, včetně možností jako DROP_EXISTING a ONLINE.
Otázka:Souvisí to se SentryOne?A: Všechny funkce v Průzkumníku plánu jsou k dispozici také v klientovi SentryOne. Pokud máte klienta, technicky nemusíte instalovat Plan Explorer, kromě toho, že aktualizace jsou dodávány podle jiného plánu, takže v mnoha případech může mít smysl mít nainstalované oba.
Mějte na paměti, že plány, které pro vás shromažďujeme během monitorovacích aktivit, jsou odhadované plány kvůli vysokým nákladům na shromažďování skutečných plánů pro všechny dotazy běžící na serveru. To znamená, že pokud v klientovi přejdete na shromážděný plán, nebude mít další informace, jako je analýza indexu a data profilu živého dotazu. Dotaz můžete kdykoli znovu spustit interaktivně, abyste získali další data za běhu.
Otázka:Jaká je režie výkonu těchto nových funkcí?A: Většina informací, které shromažďujeme, není o nic dražší, než kdybyste spustili stejné dotazy a shromáždili stejná data runtime z Management Studio (např. se zapnutým SHOWPLAN, STATISTICS TIME a STATISTICS IO). Mnohé z toho je však kompenzováno naším výchozím chováním při zahazování výsledků, takže server nezatěžujeme snahou přenášet výsledky do naší aplikace.
U extrémně složitých plánů běžících proti databázím s velmi složitými schématy a SPOUSTOU indexů může být shromažďování indexů a statistik méně efektivní, ale je extrémně nepravděpodobné, že by to mělo nějaký znatelný dopad na stávající zátěž. Toto nebude ovlivněno počtem řádků v tabulce, která byla zmíněna v jedné variantě této otázky.
U skutečně dlouhotrvajících dotazů nebo dotazů náročných na zdroje by mě nejvíce zajímala naše sbírka Live Query Profile. Máme dvě předvolby, které s tím mohou pomoci:zda zahrnout Live Query Profile se všemi skutečnými generováním plánu ve výchozím nastavení a v jakém intervalu shromažďovat data z DMV. I když se stále domnívám, že režie této kolekce by se nikdy neměla blížit režii samotného dotazu, můžete tato nastavení upravit, aby byla kolekce méně agresivní.
To vše, s prohlášením, že vše by se mělo dělat s mírou, jsem nezaznamenal žádné problémy související s režií shromažďování dat a neváhal bych použít plnou funkčnost proti produkční instanci.
Otázka:Je tam něco, co by pomohlo vytvořit filtrované indexy?A: V současné době nemáme žádnou funkci, která by doporučovala filtrované indexy, ale rozhodně je na nás.
O:Máte v plánu přidat funkci porovnání plánu dotazů do Průzkumníka plánů?A: Ano, toto je určitě na našem plánu již dlouho předtím, než byla tato funkce zavedena v SSMS. :-) Uděláme si čas a vytvoříme sadu funkcí, kterou od nás snad očekáváte.
Otázka:Mohli byste použít s balíčky SSIS ke zjištění výkonu balíčku?A: Předpokládám, že byste mohli, pokud vyvoláte balíček nebo úlohu prostřednictvím T-SQL proti serveru (Plan Explorer nemá schopnost spouštět věci jako balíčky SSIS přímo). Aplikace však zobrazí pouze aspekty výkonu, které jsou viditelné prostřednictvím serveru SQL Server – pokud se v balíčku SSIS vyskytnou neefektivnosti, které nesouvisejí s prováděním na serveru SQL Server (řekněme nekonečná smyčka v úloze skriptu), nebudeme je moci vyzvednout, protože nemáme žádnou viditelnost a neprovádíme žádnou analýzu kódu.
O:Můžete rychle ukázat, jak používat funkci analýzy uváznutí?A: Tato otázka mi během webináře unikla, ale mluvím o této funkci ve své Demo Kit, Jonathan Kehayias o ní napsal blog zde, Steve Wright o ní má video na YouTube a oficiální dokumentaci si můžete prohlédnout v uživatelské příručce PE.
O:Lze to použít jako Profiler? Mohu analyzovat celou pracovní zátěž?A: Plán Explorer je navržen tak, aby pomohl analyzovat jednotlivé dotazy a jejich plány provádění. Máme plně funkční monitorovací platformu pro větší rozsah úsilí a existuje také několik nástrojů pro analýzu pracovního zatížení od třetích stran.
O:V ladění dotazů jsem úplně nový – můžete mi navrhnout nástroje a články pro hlubší pochopení?A: Existuje mnoho zdrojů, jak se zlepšit v ladění dotazů:
- Jakákoli kniha T-SQL od Itzika Ben-Gana, Granta Fritcheyho nebo Benjamina Nevareze;
- Jakýkoli blogový příspěvek od Paula Whitea nebo Roba Farleyho;
- Otázky a odpovědi zde na answer.sqlperformance.com nebo na dba.stackexchange.com;
- videa ladění dotazů na YouTube;
- Demonstrační sada (s novou verzí již brzy!); a,
- Procvičujte . Vážně. Můžete si přečíst všechny knihy a články, které chcete, ale bez praktického, praktického řešení problémů a zlepšování problematických dotazů se skutečnými problémy s výkonem bude těžké stát se odborníkem. IMHO.
Shrnutí
Děkujeme za účast na webináři a moc děkujeme za všechny skvělé otázky. Je mi líto, že jsem je nemohl všechny oslovit, ale doufám, že vám to přesto pomohlo. Pokud máte otázku, kterou jsem výše nezodpověděl, neváhejte se mě zeptat přímo na abertrand@sentryone.com.