Všechny moderní databázové systémy podporují modul Query Optimizer, který automaticky identifikuje nejúčinnější strategii pro provádění SQL dotazů. Efektivní strategie se nazývá „plán“ a měří se z hlediska nákladů, které jsou přímo úměrné „době provedení dotazu/odpovědi“. Plán je reprezentován ve formě stromového výstupu z Query Optimizer. Uzly stromu plánu lze rozdělit převážně do následujících 3 kategorií:
- Skenovat uzly :Jak bylo vysvětleno v mém předchozím blogu „Přehled různých metod skenování v PostgreSQL“, označuje způsob, jakým je třeba načíst data základní tabulky.
- Připojit se k uzlům :Jak bylo vysvětleno v mém předchozím blogu „Přehled metod JOIN v PostgreSQL“, uvádí, jak je třeba spojit dvě tabulky, aby se získal výsledek dvou tabulek.
- Uzly materializace :Nazývané také jako pomocné uzly. Předchozí dva druhy uzlů souvisely s tím, jak načíst data ze základní tabulky a jak spojit data získaná ze dvou tabulek. Uzly v této kategorii jsou aplikovány na data získaná za účelem další analýzy nebo přípravy zprávy atd. Třídění dat, agregace dat atd.
Zvažte jednoduchý příklad dotazu, například...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Předpokládejme, že byl vygenerován plán odpovídající níže uvedenému dotazu:
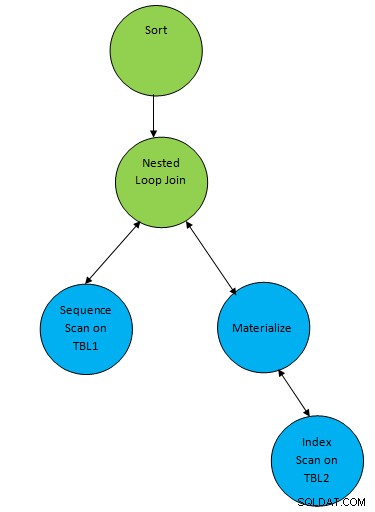
Takže zde je nad výsledek přidán jeden pomocný uzel „Sort“ spojení pro seřazení dat v požadovaném pořadí.
Některé z pomocných uzlů generovaných optimalizátorem dotazů PostgreSQL jsou následující:
- Seřadit
- Souhrnný
- Seskupit podle agregace
- Limit
- Unikátní
- LockRows
- SetOp
Pojďme pochopit každý z těchto uzlů.
Řadit
Jak název napovídá, tento uzel je přidán jako součást stromu plánu, kdykoli je potřeba seřadit data. Seřazená data mohou být vyžadována explicitně nebo implicitně, jako níže uvedené dva případy:
Uživatelský scénář vyžaduje tříděná data jako výstup. V tomto případě může být uzel Sort nad načítáním celých dat včetně veškerého dalšího zpracování.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Poznámka: I když uživatel požadoval konečný výstup v seřazeném pořadí, uzel Sort nemusí být přidán do konečného plánu, pokud je v odpovídající tabulce a sloupci řazení index. V tomto případě může zvolit indexové skenování, které bude mít za následek implicitně seřazené pořadí dat. Vytvořme například index ve výše uvedeném příkladu a uvidíme výsledek:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Jak bylo vysvětleno v mém předchozím blogu Přehled metod JOIN v PostgreSQL, Merge Join vyžaduje, aby byla data obou tabulek před spojením setříděna. Může se tedy stát, že Merge Join je levnější než jakákoli jiná metoda spojení, a to i s dodatečnými náklady na třídění. Takže v tomto případě bude uzel Sort přidán mezi metodu spojení a skenování tabulky, takže setříděné záznamy mohou být předány metodě spojení.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Souhrnný
Agregační uzel se přidá jako součást stromu plánu, pokud existuje agregační funkce použitá k výpočtu jednotlivých výsledků z více vstupních řádků. Některé z použitých agregačních funkcí jsou COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) a MIN (MINIMUM).
Agregovaný uzel může být součástí skenování základních vztahů nebo (a) spojení vztahů. Příklad:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Tyto druhy uzlů jsou rozšířením uzlu „Agregovat“. Pokud se agregační funkce používají ke kombinaci více vstupních řádků podle jejich skupiny, pak se tyto druhy uzlů přidají do stromu plánu. Pokud tedy dotaz používá nějakou agregační funkci a spolu s tím je v dotazu klauzule GROUP BY, bude do stromu plánu přidán uzel HashAggregate nebo GroupAggregate.
Protože PostgreSQL používá Cost Based Optimizer ke generování optimálního stromu plánu, je téměř nemožné odhadnout, který z těchto uzlů bude použit. Ale pojďme pochopit, kdy a jak se používá.
HashAggregate
HashAggregate funguje tak, že vytváří hashovací tabulku dat, aby je seskupil. HashAggregate tedy může být použit agregací na úrovni skupiny, pokud se agregace odehrává na netříděné sadě dat.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Data schématu tabulky demo1 jsou zde jako v příkladu uvedeném v předchozí části. Vzhledem k tomu, že existuje pouze 1000 řádků k seskupení, je zdroj potřebný k vytvoření hashovací tabulky nižší než náklady na řazení. Plánovač dotazů se rozhodne zvolit HashAggregate.
GroupAggregate
GroupAggregate pracuje na seřazených datech, takže nevyžaduje žádnou další datovou strukturu. GroupAggregate může být použit agregací na úrovni skupiny, pokud je agregace na seřazené datové sadě. Aby bylo možné seskupovat setříděná data, může buď explicitně třídit (přidáním uzlu Sort), nebo může pracovat s daty načtenými podle indexu, v takovém případě jsou setříděna implicitně.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Data schématu tabulky demo2 jsou zde jako v příkladu uvedeném v předchozí části. Vzhledem k tomu, že zde existuje 100 000 řádků k seskupení, zdroj potřebný k vytvoření hashovací tabulky může být nákladnější než náklady na řazení. Plánovač dotazů se tedy rozhodne zvolit GroupAggregate. Zde si všimněte, že záznamy vybrané z tabulky „demo2“ jsou explicitně seřazeny a pro které je ve stromu plánu přidán uzel.
Viz další příklad níže, kde jsou již data načítána setříděná kvůli skenování indexu:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Viz níže jeden další příklad, který i když má Index Scan, přesto potřebuje explicitně seřadit jako sloupec, ve kterém index a sloupec seskupení nejsou stejné. Stále je tedy potřeba třídit podle sloupce seskupení.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Poznámka: GroupAggregate/HashAggregate lze použít pro mnoho dalších nepřímých dotazů, i když agregace se skupinou v dotazu není. Záleží na tom, jak plánovač interpretuje dotaz. Např. Řekněme, že potřebujeme získat odlišnou hodnotu z tabulky, pak ji lze vidět jako skupinu podle odpovídajícího sloupce a poté vzít jednu hodnotu z každé skupiny.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Takže zde se HashAggregate používá, i když zde není žádná agregace a skupina.
Limit
Limit uzly se přidají do stromu plánu, pokud je v dotazu SELECT použita klauzule „limit/offset“. Tato klauzule se používá k omezení počtu řádků a volitelně poskytuje offset pro zahájení čtení dat. Příklad níže:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Unikátní
Tento uzel se vybere, aby získal odlišnou hodnotu ze základního výsledku. Všimněte si, že v závislosti na dotazu, selektivitě a dalších informacích o zdrojích lze odlišnou hodnotu získat pomocí HashAggregate/GroupAggregate také bez použití Unique node. Příklad:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL poskytuje funkci uzamčení všech vybraných řádků. Řádky lze vybrat v režimu „Shared“ nebo „Exclusive“ v závislosti na klauzuli „FOR SHARE“ a „FOR UPDATE“. Při provádění této operace se do stromu plánu přidá nový uzel „LockRows“.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL poskytuje funkce pro spojení výsledků dvou nebo více dotazů. Takže když se vybere typ uzlu Join pro spojení dvou tabulek, vybere se podobný typ uzlu SetOp, který spojí výsledky dvou nebo více dotazů. Vezměme si například tabulku se zaměstnanci s jejich ID, jménem, věkem a jejich platem, jak je uvedeno níže:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Nyní sežeňme zaměstnance ve věku nad 25 let:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Nyní získáme zaměstnance s platem vyšším než 95 milionů:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Nyní, abychom získali zaměstnance ve věku nad 25 let a platu nad 95 milionů, můžeme napsat níže protínající dotaz:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Takže zde je přidán nový typ uzlu HashSetOp pro vyhodnocení průniku těchto dvou jednotlivých dotazů.
Všimněte si, že jsou zde přidány další dva druhy nových uzlů:
Připojit
Tento uzel se přidá za účelem sloučení více sad výsledků do jedné.
Skenování poddotazů
Tento uzel se přidá, aby vyhodnotil jakýkoli dílčí dotaz. Ve výše uvedeném plánu je poddotaz přidán k vyhodnocení jedné další konstantní hodnoty sloupce, která označuje, která vstupní sada přispěla ke konkrétnímu řádku.
HashedSetop pracuje s použitím hash podkladového výsledku, ale je možné vygenerovat operaci SetOp založenou na třídění pomocí optimalizátoru dotazů. Uzel Settop založený na řazení je označen jako „Setop“.
Poznámka:Je možné dosáhnout stejného výsledku jako ve výše uvedeném výsledku jediným dotazem, ale zde je to ukázáno pomocí intersect jen pro snadnou ukázku.
Závěr
Všechny uzly PostgreSQL jsou užitečné a jsou vybírány na základě povahy dotazu, dat atd. Mnoho klauzulí je mapováno jedna ku jedné s uzly. U některých klauzulí existuje několik možností pro uzly, o kterých se rozhoduje na základě kalkulací nákladů na data.