Všichni jsme se rozmazlili schopností vyhledávačů „obcházet“ věci, jako jsou pravopisné chyby, pravopisné rozdíly v názvech nebo jakákoli jiná situace, kdy se hledaný výraz může shodovat na stránkách, jejichž autoři mohou preferovat použití jiného pravopisu slova. Přidání takových funkcí do našich vlastních databázových aplikací může podobně obohatit a vylepšit naše aplikace, a přestože nabídky komerčních systémů pro správu relačních databází (RDBMS) poskytují svá vlastní plně vyvinutá přizpůsobená řešení tohoto problému, náklady na licence těchto nástrojů mohou být nižší. oslovit menší vývojáře nebo malé firmy zabývající se vývojem softwaru.
Někdo by mohl namítnout, že by to bylo možné provést pomocí kontroly pravopisu. Kontrola pravopisu je však obvykle k ničemu při hledání správného, ale alternativního pravopisu jména nebo jiného slova. Shoda podle zvuku vyplňuje tuto funkční mezeru. To je téma dnešního programovacího tutoriálu:jak se dotazovat na zvuky pomocí Pythonu pomocí metafonů.
Co je Soundex?
Soundex byl vyvinut na počátku 20. století jako prostředek pro americké sčítání lidu, aby odpovídal jménům podle toho, jak znějí. To bylo poté používáno různými telefonními společnostmi k přiřazování jmen zákazníků. I nadále se používá pro shodu fonetických dat dodnes, přestože je omezena na hláskování a výslovnost americké angličtiny. Omezuje se také na anglická písmena. Většina RDBMS, jako je SQL Server a Oracle, spolu s MySQL a jejími variantami implementuje funkci Soundex a navzdory svým omezením se i nadále používá ke shodě s mnoha neanglickými slovy.
Co je to dvojitý metafon?
Metafon Algoritmus byl vyvinut v roce 1990 a překonává některá omezení Soundexu. V roce 2000 vylepšené pokračování, Double Metaphone , bylo vyvinuto. Double Metaphone vrací primární a sekundární hodnotu, která odpovídá dvěma způsobům, jak může být vyslovováno jediné slovo. Dodnes tento algoritmus zůstává jedním z lepších open-source fonetických algoritmů. Metaphone 3 byl vydán v roce 2009 jako vylepšení Double Metaphone, ale jedná se o komerční produkt.
Bohužel, mnoho prominentních RDBMS zmíněných výše neimplementuje Double Metaphone a většina prominentní skriptovací jazyky neposkytují podporovanou implementaci Double Metaphone. Python však poskytuje modul, který implementuje Double Metaphone.
Příklady uvedené v tomto tutoriálu programování v Pythonu používají MariaDB verze 10.5.12 a Python 3.9.2, obě běží na Kali/Debian Linuxu.
Jak přidat dvojitý metafon do Pythonu
Jako každý modul Pythonu lze k instalaci Double Metaphone použít nástroj pip. Syntaxe závisí na vaší instalaci Pythonu. Typická instalace Double Metaphone vypadá jako následující příklad:
# Typical if you have only Python 3 installed $ pip install doublemetaphone # If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install DoubleMetaphone
Upozorňujeme, že použití velkých písmen navíc je záměrné. Následující kód je příkladem použití Double Metaphone v Pythonu:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 1 - Demo script to verify functionality
Výše uvedený skript Pythonu poskytuje následující výstup při spuštění ve vašem integrovaném vývojovém prostředí (IDE) nebo editoru kódu:
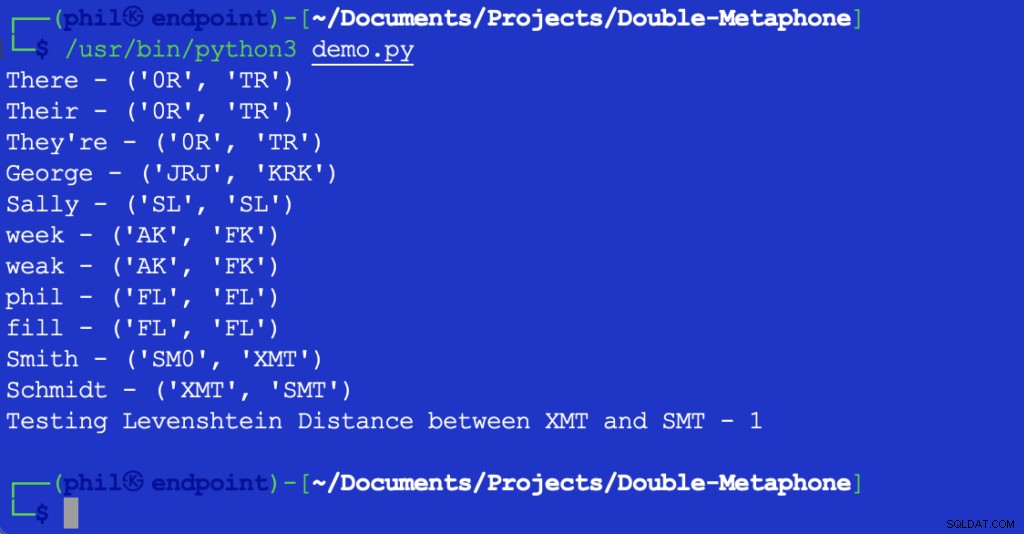
Obrázek 1 – Výstup ukázkového skriptu
Jak je zde vidět, každé slovo má primární i sekundární fonetickou hodnotu. Slova, která se shodují na primárních i sekundárních hodnotách, se nazývají fonetické shody. Slova, která sdílejí alespoň jednu fonetickou hodnotu nebo která sdílejí prvních pár znaků v jakékoli fonetické hodnotě, jsou si foneticky blízká.
Většina zobrazená písmena odpovídají jejich anglické výslovnosti. X může odpovídat KS , SH nebo C . 0 odpovídá té zvuk v nebo tam . Samohlásky se shodují pouze na začátku slova. Kvůli nespočetnému množství rozdílů v regionálních přízvukech není možné říci, že slova mohou být objektivně přesná, i když mají stejné fonetické hodnoty.
Porovnání fonetických hodnot s Pythonem
Existuje mnoho online zdrojů, které mohou popsat úplné fungování algoritmu Double Metaphone; to však není nutné pro jeho použití, protože nás více zajímá porovnávání vypočítané hodnoty, více než nás zajímá výpočet hodnot. Jak bylo uvedeno dříve, pokud je mezi dvěma slovy alespoň jedna společná hodnota, lze říci, že tyto hodnoty jsou fonetické shody a fonetické hodnoty, které jsou podobné jsou foneticky blízko .
Porovnání absolutních hodnot je snadné, ale jak lze určit, že řetězce jsou podobné? I když neexistují žádná technická omezení, která by vám bránila v porovnávání víceslovných řetězců, tato srovnání jsou obvykle nespolehlivá. Držte se porovnávání jednotlivých slov.
Co jsou Levenshteinovy vzdálenosti?
Levenshteinova vzdálenost mezi dvěma řetězci je počet jednotlivých znaků, které je třeba změnit v jednom řetězci, aby odpovídal druhému řetězci. Pár strun, které mají menší Levenshteinovu vzdálenost, jsou si navzájem podobnější než dvojice strun, které mají větší Levenshteinovu vzdálenost. Levenshteinova vzdálenost je podobná Hammingově vzdálenosti , ale druhý jmenovaný je omezen na řetězce stejné délky, protože fonetické hodnoty Double Metaphone se mohou lišit v délce, je smysluplnější je porovnávat pomocí Levenshteinovy vzdálenosti.
Knihovna vzdálenosti Python Levenshtein
Python lze rozšířit tak, aby podporoval výpočty vzdálenosti Levenshtein pomocí modulu Python:
# If your system has Python 2 and Python 3 installed $ /usr/bin/pip3 install python-Levenshtein
Všimněte si, že stejně jako při instalaci DoubleMetaphone výše, syntaxe volání pip se může lišit. Modul python-Levenshtein poskytuje mnohem více funkcí než jen výpočty vzdálenosti Levenshtein.
Níže uvedený kód ukazuje test pro výpočet Levenshteinovy vzdálenosti v Pythonu:
# demo.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def main(argv):
testwords = ["There", "Their", "They're", "George", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 2 - Demo extended to verify Levenshtein Distance calculation functionality
Spuštění tohoto skriptu poskytne následující výstup:
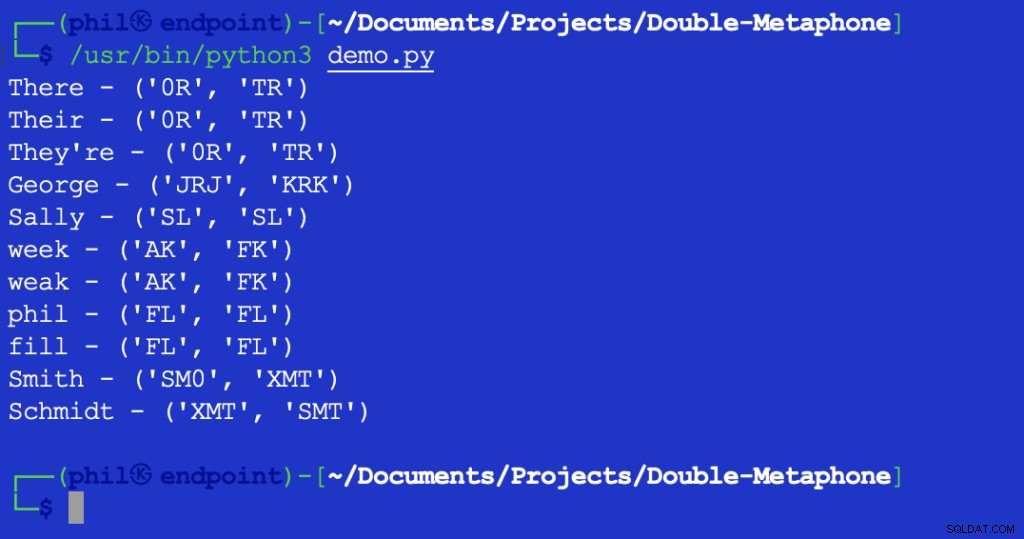
Obrázek 2 – Výstup testu Levenshteinovy vzdálenosti
Vrácená hodnota 1 označuje, že mezi XMT je jeden znak a SMT to je jiné. V tomto případě je to první znak v obou řetězcích.
Porovnání dvojitých metafonů v Pythonu
To, co následuje, není úplným koncem fonetických srovnání. Je to prostě jeden z mnoha způsobů, jak takové srovnání provést. Aby bylo možné efektivně porovnat fonetickou blízkost jakýchkoli dvou daných řetězců, musí být každá fonetická hodnota Double Metaphone jednoho řetězce porovnána s odpovídající fonetickou hodnotou Double Metaphone jiného řetězce. Vzhledem k tomu, že oběma fonetickým hodnotám daného řetězce je dána stejná váha, pak průměr těchto srovnávacích hodnot poskytne přiměřeně dobrou aproximaci fonetické blízkosti:
PN = [ Dist(DM11, DM21,) + Dist(DM12, DM22,) ] / 2.0
Kde:
- DM1(1) :Hodnota prvního dvojitého metafonu řetězce 1,
- DM1(2) :Hodnota druhého dvojitého metafonu řetězce 1
- DM2(1) :Hodnota prvního dvojitého metafonu řetězce 2
- DM2(2) :Hodnota druhého dvojitého metafonu řetězce 2
- PN :Fonetická blízkost, přičemž nižší hodnoty jsou bližší než vyšší hodnoty. Nulová hodnota označuje fonetickou podobnost. Nejvyšší hodnota je počet písmen v nejkratším řetězci.
Tento vzorec se rozpadá v případech jako Schmidt (XMT, SMT) a Smith (SM0, XMT) kde první fonetická hodnota prvního řetězce odpovídá druhé fonetické hodnotě druhého řetězce. V takových situacích oba Schmidt a Smith lze považovat za foneticky podobné kvůli sdílené hodnotě. Kód funkce blízkosti by měl použít výše uvedený vzorec pouze v případě, že jsou všechny čtyři fonetické hodnoty různé. Vzorec má také slabiny při porovnávání řetězců různých délek.
Všimněte si, že neexistuje žádný jedinečně účinný způsob, jak porovnávat struny různých délek, i když výpočet Levenshteinovy vzdálenosti mezi dvěma strunami zohledňuje rozdíly v délce strun. Možným řešením by bylo porovnat oba řetězce až do délky kratšího z těchto dvou řetězců.
Níže je uveden příklad fragmentu kódu, který implementuje výše uvedený kód, spolu s několika testovacími ukázkami:
# demo2.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testwords = ["Philippe", "Phillip", "Sallie", "Sally", "week", "weak", "phil", "fill", "Smith", "Schmidt", "Harold", "Herald"]
for testword in testwords:
print (testword + " - ", end="")
print (doublemetaphone(testword))
print ("Testing Levenshtein Distance between XMT and SMT - " + str(distance('XMT', 'SMT')))
print ("Distance between AK and AK - " + str(distance('AK', 'AK')) + "]")
print ("Comparing week and weak - [" + str(Nearness("week", "weak")) + "]")
print ("Comparing Harold and Herald - [" + str(Nearness("Harold", "Herald")) + "]")
print ("Comparing Smith and Schmidt - [" + str(Nearness("Smith", "Schmidt")) + "]")
print ("Comparing Philippe and Phillip - [" + str(Nearness("Philippe", "Phillip")) + "]")
print ("Comparing Phil and Phillip - [" + str(Nearness("Phil", "Phillip")) + "]")
print ("Comparing Robert and Joseph - [" + str(Nearness("Robert", "Joseph")) + "]")
print ("Comparing Samuel and Elizabeth - [" + str(Nearness("Samuel", "Elizabeth")) + "]")
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 3 - Implementation of the Nearness Algorithm Above
Ukázkový kód Pythonu poskytuje následující výstup:
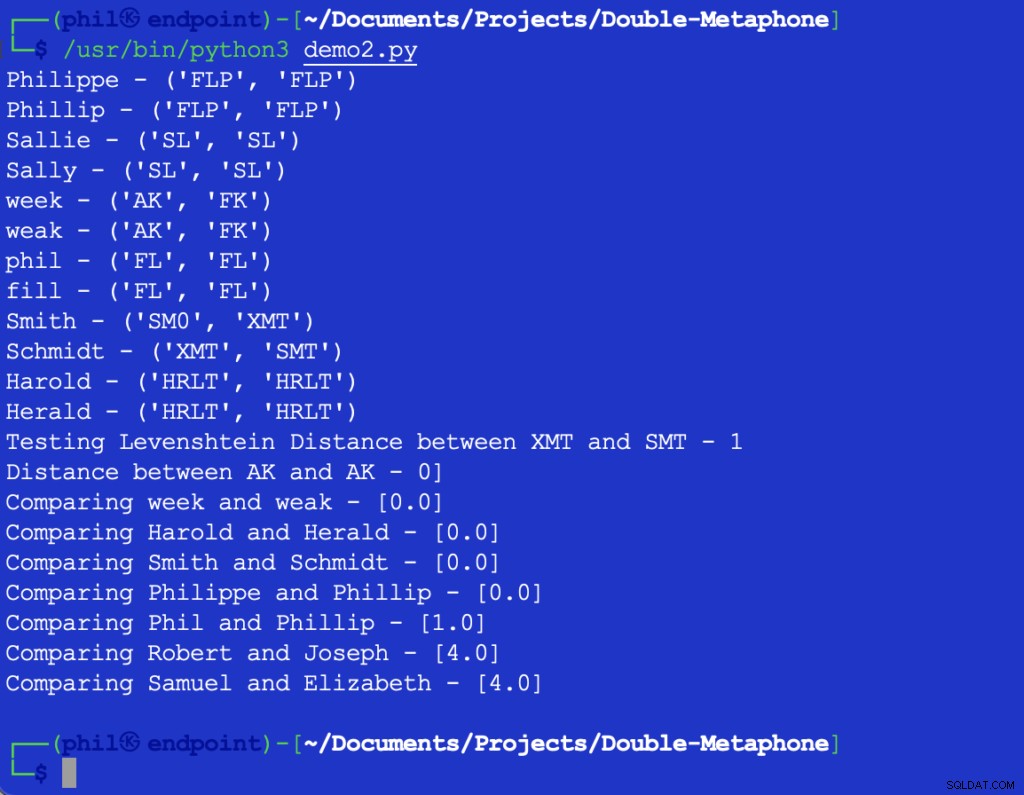
Obrázek 3 – Výstup algoritmu Nearness
Vzorová sada potvrzuje obecný trend, že čím větší jsou rozdíly ve slovech, tím vyšší je výstup blízkosti funkce.
Integrace databáze v Pythonu
Výše uvedený kód porušuje funkční mezeru mezi daným RDBMS a implementací Double Metaphone. Navíc implementací Nearness funkce v Pythonu, je snadné ji nahradit, pokud by byl preferován jiný porovnávací algoritmus.
Zvažte následující tabulku MySQL/MariaDB:
create table demo_names (record_id int not null auto_increment, lastname varchar(100) not null default '', firstname varchar(100) not null default '', primary key(record_id)); Listing 4 - MySQL/MariaDB CREATE TABLE statement
Ve většině databázově řízených aplikací middleware sestavuje příkazy SQL pro správu dat, včetně jejich vkládání. Následující kód vloží do této tabulky některé ukázkové názvy, ale v praxi by totéž mohl dělat jakýkoli kód z webové nebo desktopové aplikace, která shromažďuje taková data.
# demo3.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
testNames = ["Smith, Jane", "Williams, Tim", "Adams, Richard", "Franks, Gertrude", "Smythe, Kim", "Daniels, Imogen", "Nguyen, Nancy",
"Lopez, Regina", "Garcia, Roger", "Diaz, Catalina"]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
for name in testNames:
nameParts = name.split(',')
# Normally one should do bounds checking here.
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
sql = "insert into demo_names (lastname, firstname) values(%s, %s)"
values = (lastname, firstname)
insertCursor = mydb.cursor()
insertCursor.execute (sql, values)
mydb.commit()
mydb.close()
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Inserting sample data into a database.
Spuštěním tohoto kódu se nic nevytiskne, ale naplní se testovací tabulka v databázi pro další použití. Dotazování na tabulku přímo v klientovi MySQL může ověřit, že výše uvedený kód fungoval:
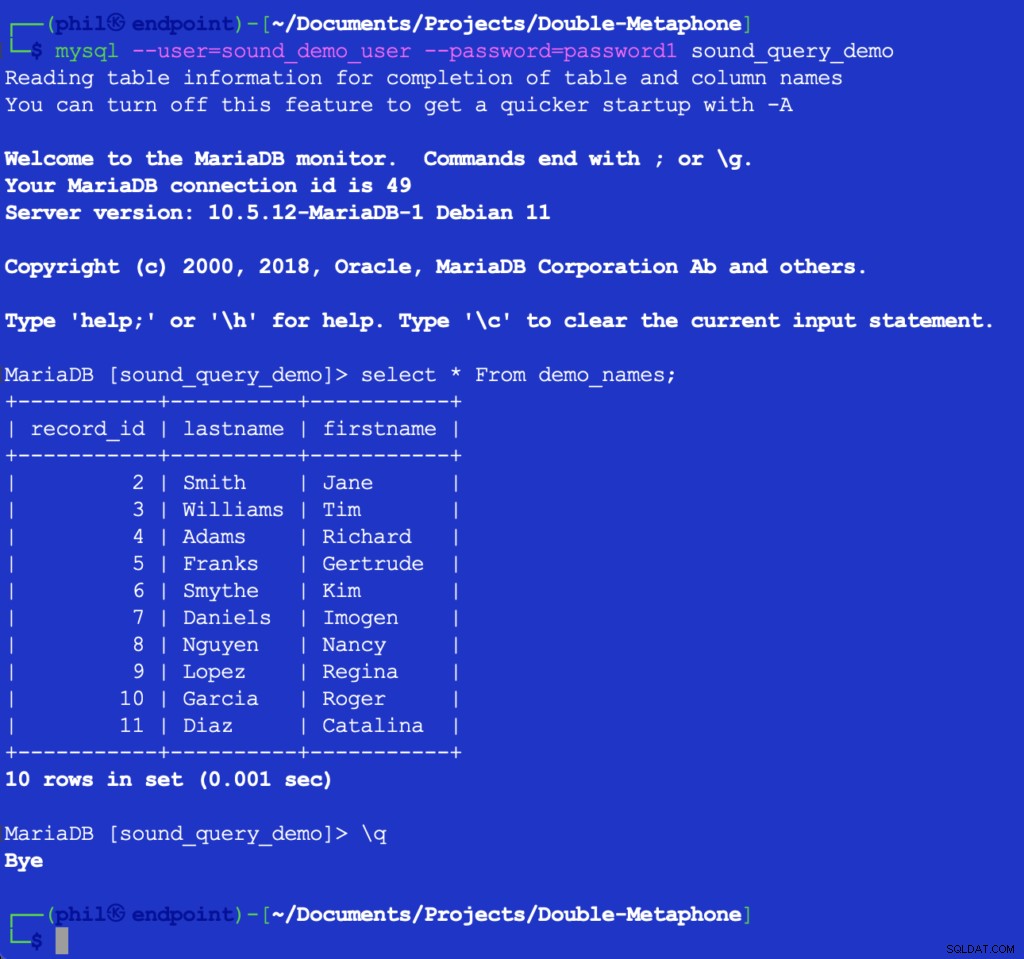
Obrázek 4 – Vložená data tabulky
Níže uvedený kód vloží některá srovnávací data do výše uvedené tabulky a provede s nimi srovnání blízkosti:
# demo4.py
import sys
# pip install doublemetaphone
# /usr/bin/pip3 install DoubleMetaphone
from doublemetaphone import doublemetaphone
#/usr/bin/pip3 install python-Levenshtein
from Levenshtein import _levenshtein
from Levenshtein._levenshtein import *
# /usr/bin/pip3 install mysql.connector
import mysql.connector
def Nearness(string1, string2):
dm1 = doublemetaphone(string1)
dm2 = doublemetaphone(string2)
nearness = 0.0
if dm1[0] == dm2[0] or dm1[1] == dm2[1] or dm1[0] == dm2[1] or dm1[1] == dm2[0]:
nearness = 0.0
else:
distance1 = distance(dm1[0], dm2[0])
distance2 = distance(dm1[1], dm2[1])
nearness = (distance1 + distance2) / 2.0
return nearness
def main(argv):
comparisonNames = ["Smith, John", "Willard, Tim", "Adamo, Franklin" ]
mydb = mysql.connector.connect(
host="localhost",
user="sound_demo_user",
password="password1",
database="sound_query_demo")
sql = "select lastname, firstname from demo_names order by lastname, firstname"
cursor1 = mydb.cursor()
cursor1.execute (sql)
results1 = cursor1.fetchall()
cursor1.close()
mydb.close()
for comparisonName in comparisonNames:
nameParts = comparisonName.split(",")
firstname = nameParts[1].strip()
lastname = nameParts[0].strip()
print ("Comparison for " + firstname + " " + lastname + ":")
for result in results1:
firstnameNearness = Nearness (firstname, result[1])
lastnameNearness = Nearness (lastname, result[0])
print ("\t[" + firstname + "] vs [" + result[1] + "] - " + str(firstnameNearness)
+ ", [" + lastname + "] vs [" + result[0] + "] - " + str(lastnameNearness))
return 0
if __name__ == "__main__":
main(sys.argv[1:])
Listing 5 - Nearness Comparison Demo
Spuštěním tohoto kódu získáme výstup níže:
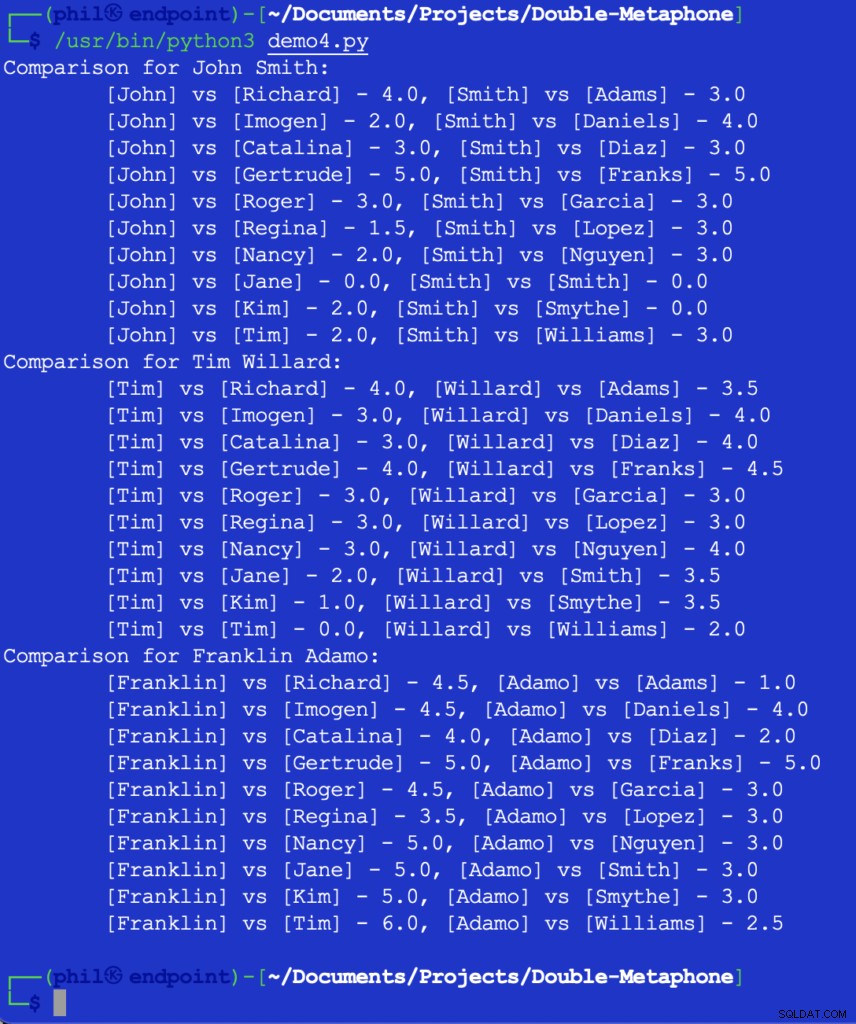
Obrázek 5 – Výsledky srovnání blízkosti
V tomto okamžiku by bylo na vývojáři, aby rozhodl, jaká by byla prahová hodnota pro to, co představuje užitečné srovnání. Některá z výše uvedených čísel se mohou zdát neočekávaná nebo překvapivá, ale jedním z možných dodatků ke kódu může být IF příkaz k odfiltrování jakékoli srovnávací hodnoty, která je větší než 2 .
Možná stojí za zmínku, že samotné fonetické hodnoty nejsou v databázi uloženy. Je to proto, že jsou počítány jako součást kódu Pythonu a není skutečná potřeba je nikam ukládat, protože jsou při ukončení programu zahozeny, nicméně vývojář může najít hodnotu v jejich uložení do databáze a následné implementaci porovnání. funkce v rámci databáze uložená procedura. Jednou z hlavních nevýhod tohoto je však ztráta přenositelnosti kódu.
Závěrečné úvahy o dotazování na data pomocí zvuku pomocí Pythonu
Zdá se, že porovnávání dat podle zvuku nepřinese „lásku“ nebo pozornost, jakou může získat porovnávání dat analýzou obrazu, ale pokud se aplikace musí vypořádat s více podobně znějícími variantami slov ve více jazycích, může to být velmi užitečné. nářadí. Jednou z užitečných vlastností tohoto typu analýzy je, že vývojář nemusí být lingvistický nebo fonetický odborník, aby mohl tyto nástroje používat. Vývojář má také velkou flexibilitu při definování toho, jak lze taková data porovnávat; srovnání lze upravit podle potřeb aplikace nebo obchodní logiky.
Doufejme, že tento obor získá více pozornosti ve výzkumné sféře a do budoucna budou existovat schopnější a robustnější analytické nástroje.