V dokonalém světě by nezáleželo na tom, jakou konkrétní syntaxi T-SQL jsme zvolili k vyjádření dotazu. Jakákoli sémanticky identická konstrukce by vedla k přesně stejnému plánu fyzického provedení s přesně stejnými výkonnostními charakteristikami.
Aby toho dosáhl, musel by optimalizátor dotazů SQL Server znát každou možnou logickou ekvivalenci (za předpokladu, že bychom je někdy mohli znát všechny), a dostat čas a zdroje na prozkoumání všech možností. Vzhledem k obrovskému počtu možných způsobů, jak můžeme vyjádřit stejný požadavek v T-SQL, a obrovskému počtu možných transformací se kombinace rychle stanou neovladatelné pro všechny případy kromě těch úplně nejjednodušších.
„Perfektní svět“ s úplnou syntaxí nezávislostí se nemusí zdát tak dokonalý uživatelům, kteří musí čekat dny, týdny nebo dokonce roky, než se zkompiluje skromně složitý dotaz. Optimalizátor dotazů tedy dělá kompromisy:zkoumá některé běžné ekvivalence a usilovně se snaží vyhnout tomu, aby trávil více času kompilací a optimalizací, než šetří čas provádění. Jeho cíl lze shrnout jako pokus o nalezení rozumného exekučního plánu v rozumném čase při spotřebě rozumných zdrojů.
Jedním z výsledků toho všeho je, že prováděcí plány jsou často citlivé na písemnou formu dotazu. Optimalizátor má určitou logiku pro rychlou transformaci některých široce používaných ekvivalentních konstrukcí do běžné formy, ale tyto schopnosti nejsou ani dobře zdokumentované, ani (v žádném případě) komplexní.
Určitě můžeme maximalizovat své šance na získání dobrého plánu provádění psaním jednodušších dotazů, poskytováním užitečných indexů, udržováním dobrých statistik a omezením se na relační koncepty (např. vyhýbáním se kurzorům, explicitním smyčkám a neinline funkcím), ale to je není úplné řešení. Nelze ani říci, že jedna konstrukce T-SQL bude vždy vytvořit lepší plán provádění než sémanticky identická alternativa.
Moje obvyklá rada je začít s nejjednodušším formulářem relačního dotazu, který vyhovuje vašim potřebám, s použitím jakékoli syntaxe T-SQL, kterou považujete za vhodnější. Pokud dotaz po fyzické optimalizaci (např. indexování) nevyhovuje požadavkům, může stát za to zkusit dotaz vyjádřit trochu jiným způsobem a přitom zachovat původní sémantiku. To je ta záludná část. Kterou část dotazu byste měli zkusit přepsat? Které přepsání byste měli zkusit? Na tyto otázky neexistuje jednoduchá univerzální odpověď. Něco z toho závisí na zkušenostech, i když užitečným vodítkem může být také znalost optimalizace dotazů a vnitřních částí prováděcího modulu.
Příklad
Tento příklad používá tabulku AdventureWorks TransactionHistory. Níže uvedený skript vytvoří kopii tabulky a vytvoří seskupený a neseskupený index. Údaje nebudeme vůbec upravovat; tento krok slouží pouze k tomu, aby bylo indexování jasné (a aby tabulka byla kratší):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Úkolem je vytvořit seznam ID produktů a historie pro šest konkrétních produktů. Jedním ze způsobů, jak vyjádřit dotaz, je:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Tento dotaz vrací 764 řádků pomocí následujícího plánu provádění (zobrazeného v Průzkumníku plánů SentryOne):

Tento jednoduchý dotaz se kvalifikuje pro kompilaci TRIVÁLNÍHO plánu. Plán provádění obsahuje šest samostatných operací hledání indexu v jedné:
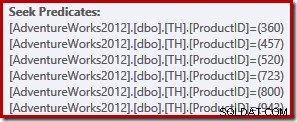
Čtenáři s orlíma očima si jistě všimli, že šest hledání je uvedeno vzestupně pořadí ID produktu, nikoli v (libovolném) pořadí uvedeném v seznamu IN původního dotazu. Pokud dotaz spustíte sami, je docela pravděpodobné, že výsledky budou vráceny ve vzestupném pořadí ID produktu. Dotaz není zaručený vracet výsledky samozřejmě v tomto pořadí, protože jsme nespecifikovali klauzuli ORDER BY nejvyšší úrovně. Můžeme však přidat takovou klauzuli ORDER BY, aniž bychom změnili prováděcí plán vytvořený v tomto případě:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Nebudu opakovat grafiku prováděcího plánu, protože je úplně stejná:dotaz se stále kvalifikuje pro triviální plán, vyhledávací operace jsou přesně stejné a oba plány mají přesně stejné odhadované náklady. Přidání klauzule ORDER BY nás nestálo přesně nic, ale přineslo nám záruku uspořádání sady výsledků.
Nyní máme záruku, že výsledky budou vráceny v pořadí ID produktu, ale náš dotaz v současné době nespecifikuje, jak řádky se stejným ID produktu bude objednáno. Při pohledu na výsledky si můžete všimnout, že řádky pro stejné ID produktu se zdají být seřazeny podle ID transakce, vzestupně.
Bez explicitního ORDER BY je to jen další pozorování (tj. nemůžeme se na toto řazení spolehnout), ale můžeme upravit dotaz, abychom zajistili, že řádky budou seřazeny podle ID transakce v rámci každého ID produktu:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Opět platí, že plán provádění tohoto dotazu je úplně stejný jako předtím; je vytvořen stejný triviální plán se stejnými odhadovanými náklady. Rozdíl je v tom, že výsledky jsou nyní zaručené k objednání nejprve podle ID produktu a poté podle ID transakce.
Někteří lidé by mohli být v pokušení dojít k závěru, že dva předchozí dotazy by také vždy vrátily řádky v tomto pořadí, protože plány provádění jsou stejné. To není bezpečný důsledek, protože ne všechny podrobnosti prováděcího stroje jsou uvedeny v plánech provádění (dokonce i ve formě XML). Bez explicitního pořadí podle klauzule může SQL Server vracet řádky v libovolném pořadí, i když se nám plán zdá stejný (mohl by například provádět vyhledávání v pořadí uvedeném v textu dotazu). Jde o to, že optimalizátor dotazů ví a může vynutit určité chování v rámci enginu, které uživatelé nevidí.
V případě, že vás zajímá, jak může náš nejedinečný neseskupený index na ID produktu vracet řádky v produktu a V pořadí ID transakce, odpovědí je, že neclusterovaný indexový klíč zahrnuje Transaction ID (jedinečný seskupený indexový klíč). Ve skutečnosti, fyzické struktura našeho neshlukovaného indexu je přesně totéž na všech úrovních, jako bychom vytvořili index s následující definicí:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Můžeme dokonce napsat dotaz s explicitním DISTINCT nebo GROUP BY a stále získat přesně stejný plán provádění:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Aby bylo jasno, toto nevyžaduje žádnou změnu původního indexu bez klastrů. Jako poslední příklad si všimněte, že výsledky můžeme požadovat také v sestupném pořadí:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Vlastnosti plánu provádění nyní ukazují, že index je skenován pozpátku:

Kromě toho je plán stejný – byl vytvořen ve fázi triviální optimalizace plánu a má stále stejné odhadované náklady.
Přepsání dotazu
S předchozím dotazem nebo plánem provádění není nic špatného, ale mohli jsme se rozhodnout vyjádřit dotaz jinak:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Je zřejmé, že tento formulář specifikuje přesně stejné výsledky jako původní a nový dotaz skutečně vytváří stejný plán provádění (triviální plán, vícenásobné vyhledávání v jednom, stejné odhadované náklady). Formulář OR možná trochu objasňuje, že výsledkem je kombinace výsledků pro šest jednotlivých ID produktů, což nás může vést k vyzkoušení jiné varianty, která tuto myšlenku ještě více upřesní:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Plán provádění pro dotaz UNION ALL je zcela odlišný:
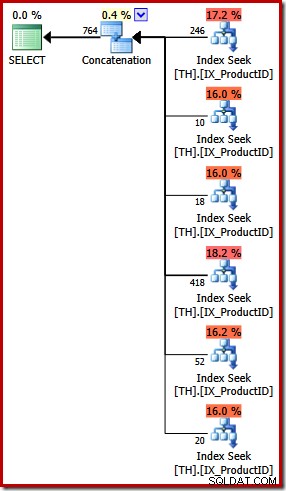
Kromě zjevných vizuálních rozdílů tento plán vyžadoval optimalizaci založenou na nákladech (PLNOU) (nesplňoval podmínky pro triviální plán) a odhadované náklady jsou (relativně řečeno) o dost vyšší, kolem 0,02 jednotek oproti přibližně 0,005 jednotky dříve.
To se vrací k mým úvodním poznámkám:optimalizátor dotazů neví o každé logické ekvivalenci a nemůže vždy rozpoznat alternativní dotazy jako určující stejné výsledky. V této fázi chci říci, že vyjádření tohoto konkrétního dotazu pomocí UNION ALL spíše než IN vedlo k méně optimálnímu prováděcímu plánu.
Druhý příklad
Tento příklad vybere jinou sadu šesti ID produktů a požaduje výsledky v pořadí ID transakce:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Náš neshlukovaný index nemůže poskytovat řádky v požadovaném pořadí, takže optimalizátor dotazů má na výběr mezi hledáním na neshlukovaném indexu a řazením, nebo skenováním seskupeného indexu (který je klíčován pouze na ID transakce) a použitím predikátů ID produktu jako zbytek. Uvedená ID produktů mají náhodou nižší selektivitu než předchozí sada, takže optimalizátor v tomto případě zvolí skenování klastrovaného indexu:
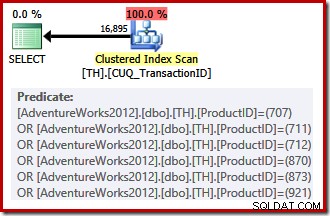
Vzhledem k tomu, že je třeba učinit volbu založenou na nákladech, tento prováděcí plán se nekvalifikoval pro triviální plán. Odhadované náklady na konečný plán jsou asi 0,714 Jednotky. Skenování seskupeného indexu vyžaduje 797 logické čtení v době provádění.
Možná nás překvapí, že dotaz nepoužil index produktu, a mohli bychom zkusit vynutit hledání neshlukovaného indexu pomocí nápovědy indexu nebo zadáním FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
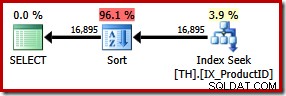
Výsledkem je explicitní řazení podle ID transakce. Odhaduje se, že nové řazení tvoří 96 % nového plánu 1.15 jednotková cena. Tato vyšší odhadovaná cena vysvětluje, proč optimalizátor zvolil zjevně levnější skenování clusterovaných indexů, když je nechal na svých vlastních zařízeních. I/O náklady na nový dotaz jsou však nižší:při spuštění spotřebuje hledání indexu pouze 49 logická čtení (pokles ze 797).
Mohli jsme se také rozhodnout vyjádřit tento dotaz pomocí (dříve neúspěšného) nápadu UNION ALL:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Vytvoří následující plán provádění (kliknutím na obrázek jej zvětšíte v novém okně):

Tento plán se může zdát složitější, ale jeho odhadované náklady jsou pouze 0,099 jednotek, což je mnohem nižší hodnota než při skenování sdruženého indexu (0,714 jednotek) nebo hledat plus řazení (1,15 Jednotky). Navíc nový tarif spotřebuje pouze 49 logická čtení v době provádění – stejná jako u plánu hledání + řazení a mnohem nižší než 797 potřebných pro skenování seskupeného indexu.
Vyjádření dotazu pomocí UNION ALL tentokrát přineslo mnohem lepší plán, a to jak z hlediska odhadovaných nákladů, tak z hlediska logického čtení. Zdrojová datová sada je příliš malá na to, aby bylo možné skutečně smysluplně porovnat dobu trvání dotazů nebo využití procesoru, ale skenování clusterového indexu trvá dvakrát déle (26 ms) než ostatní dva v mém systému.
Další řazení v naznačeném plánu je v tomto jednoduchém příkladu pravděpodobně neškodné, protože je nepravděpodobné, že by se rozlilo na disk, ale mnoho lidí bude stejně preferovat plán UNION ALL, protože je neblokující, vyhýbá se přidělení paměti a nevyžaduje nápověda k dotazu.
Závěr
Viděli jsme, že syntaxe dotazu může ovlivnit plán provádění zvolený optimalizátorem, i když dotazy logicky určují přesně stejnou sadu výsledků. Stejné přepsání (např. UNION ALL) někdy povede ke zlepšení a někdy způsobí výběr horšího plánu.
Přepisování dotazů a zkoušení alternativní syntaxe je platná technika ladění, ale je zapotřebí určité opatrnosti. Jedním z rizik je, že budoucí změny produktu mohou způsobit, že jiný formulář dotazu náhle přestane vytvářet lepší plán, ale dalo by se namítnout, že je to vždy riziko a je zmírněno testováním před upgradem nebo použitím průvodců plánem.
Existuje také riziko, že se touto technikou necháte unést: použití „divných“ nebo „neobvyklých“ konstrukcí dotazů k získání lepšího plánu je často známkou toho, že byla překročena hranice. Kde přesně leží rozdíl mezi platnou alternativní syntaxí a 'neobvyklým/podivným', je pravděpodobně dost subjektivní; mým osobním průvodcem je pracovat s ekvivalentními formuláři relačních dotazů a udržovat věci co nejjednodušší.