Vítejte u třetí – a poslední – části této blogové série, která zkoumá, jak se výkon PostgreSQL v průběhu let vyvíjel. První část se zabývala pracovní zátěží OLTP, reprezentovanou testy pgbench. Druhá část se zabývala analytickými / BI dotazy pomocí podmnožiny tradičního benchmarku TPC-H (v podstatě část testu výkonu).
A tato závěrečná část se zabývá fulltextovým vyhledáváním, tedy schopností indexovat a vyhledávat ve velkém množství textových dat. Stejná infrastruktura (zejména indexy) může být užitečná pro indexování polostrukturovaných dat, jako jsou dokumenty JSONB atd., ale na to se tento benchmark nezaměřuje.
Nejprve se však podívejme na historii fulltextového vyhledávání v PostgreSQL, což se může zdát jako zvláštní funkce, kterou lze přidat do RDBMS, tradičně určeného pro ukládání strukturovaných dat v řádcích a sloupcích.
Historie fulltextového vyhledávání
Když byl Postgres v roce 1996 open-source, neměl nic, co bychom mohli nazvat fulltextovým vyhledáváním. Ale lidé, kteří začali používat Postgres, chtěli provádět inteligentní vyhledávání v textových dokumentech a dotazy LIKE nebyly dost dobré. Chtěli být schopni lemmatizovat výrazy pomocí slovníků, ignorovat zastavovací slova, třídit odpovídající dokumenty podle relevance, používat indexy k provádění těchto dotazů a mnoho dalších věcí. Věci, které nemůžete rozumně dělat s tradičními operátory SQL.
Naštěstí někteří z těch lidí byli také vývojáři, takže na tom začali pracovat – a mohli, díky PostgreSQL, který je dostupný jako open-source po celém světě. V průběhu let bylo mnoho přispěvatelů do fulltextového vyhledávání, ale zpočátku toto úsilí vedli Oleg Bartunov a Teodor Sigaev, jak je znázorněno na následující fotografii. Oba jsou stále hlavními přispěvateli PostgreSQL, pracují na fulltextovém vyhledávání, indexování, podpoře JSON a mnoha dalších funkcích.

Teodor Sigaev a Oleg Bartunov
Zpočátku byla funkčnost vyvinuta jako externí modul „contrib“ (dnes bychom řekli, že jde o rozšíření) nazvaný „tsearch“, vydaný v roce 2002. Později to bylo zastaralé tsearch2, což funkci v mnoha ohledech výrazně zlepšilo a v PostgreSQL 8.3 (vydáno v roce 2008) bylo plně integrováno do jádra PostgreSQL (tj. bez nutnosti instalovat jakékoli rozšíření, ačkoli rozšíření byla stále poskytována pro zpětnou kompatibilitu).
Od té doby došlo k mnoha vylepšením (a práce pokračuje, např. na podpoře datových typů jako JSONB, dotazování pomocí jsonpath atd.). ale tyto pluginy zavedly většinu fulltextových funkcí, které nyní v PostgreSQL máme – slovníky, fulltextové indexování a možnosti dotazování atd.
Srovnávací
Na rozdíl od benchmarků OLTP / TPC-H si nejsem vědom žádného fulltextového benchmarku, který by mohl být považován za „průmyslový standard“ nebo navržený pro více databázových systémů. Většina benchmarků, o kterých vím, je určena k použití s jedinou databází/produktem a je těžké je smysluplně přenést, takže jsem musel zvolit jinou cestu a napsat svůj vlastní fulltextový benchmark.
Před lety jsem napsal archie – pár pythonových skriptů, které umožňují stahování archivů poštovních konferencí PostgreSQL a načítání analyzovaných zpráv do databáze PostgreSQL, kterou lze indexovat a prohledávat. Aktuální snímek všech archivů má ~1M řádků a po načtení do databáze má tabulka asi 9,5 GB (nepočítám indexy).
Pokud jde o dotazy, pravděpodobně bych mohl vygenerovat nějaké náhodné, ale nejsem si jistý, jak realistické by to bylo. Naštěstí jsem před pár lety získal vzorek 33 000 skutečných vyhledávání z webu PostgreSQL (tj. věcí, které lidé skutečně hledali v archivech komunity). Je nepravděpodobné, že bych mohl získat něco realističtějšího/reprezentativnějšího.
Kombinace těchto dvou částí (datová sada + dotazy) vypadá jako pěkný benchmark. Můžeme jednoduše načíst data a spustit vyhledávání s různými typy fulltextových dotazů s různými typy indexů.
Dotazy
Existují různé tvary fulltextových dotazů – dotaz může jednoduše vybrat všechny odpovídající řádky, může seřadit výsledky (seřadit je podle relevance), vrátit jen malý počet nebo nejrelevantnější výsledky atd. Spustil jsem benchmark s různými typů dotazů, ale v tomto příspěvku uvedu výsledky pro dva jednoduché dotazy, které podle mě docela pěkně reprezentují celkové chování.
- SELECT id, předmět FROM zpráv WHERE body_tsvector @@ $1
- SELECT id, předmět FROM zpráv WHERE body_tsvector @@ $1
ORDER BY ts_rank(body_tsvector, $1) DESC LIMIT 100
První dotaz jednoduše vrátí všechny odpovídající řádky, zatímco druhý vrátí 100 nejrelevantnějších výsledků (toto je něco, co byste pravděpodobně použili pro uživatelská vyhledávání).
Experimentoval jsem s různými jinými typy dotazů, ale všechny se nakonec chovaly podobně jako jeden z těchto dvou typů dotazů.
Indexy
Každá zpráva má dvě hlavní části, ve kterých můžeme vyhledávat – předmět a tělo. Každý z nich má samostatný sloupec tsvector a je indexován samostatně. Předměty zpráv jsou mnohem kratší než těla, takže indexy jsou přirozeně menší.
PostgreSQL má dva typy indexů užitečné pro fulltextové vyhledávání – GIN a GiST. Hlavní rozdíly jsou vysvětleny v dokumentech, ale stručně:
- Indexy GIN jsou pro vyhledávání rychlejší
- Indexy GiST jsou ztrátové, tj. vyžadují opakovanou kontrolu během vyhledávání (a proto jsou pomalejší)
Dříve jsme tvrdili, že aktualizace indexů GiST je levnější (zejména při mnoha souběžných relacích), ale to bylo před časem z dokumentace odstraněno kvůli vylepšením indexovacího kódu.
Tento benchmark netestuje chování s aktualizacemi – jednoduše načte tabulku bez fulltextových indexů, vytvoří je najednou a poté provede 33 000 dotazů na data. To znamená, že nemohu učinit žádná prohlášení o tom, jak tyto typy indexů zpracovávají souběžné aktualizace na základě tohoto benchmarku, ale věřím, že změny dokumentace odrážejí různá nedávná vylepšení GIN.
To by také mělo docela dobře odpovídat případu použití archivu e-mailových konferencí, kde bychom nové e-maily přidávali pouze jednou za čas (málo aktualizací, téměř žádná souběžnost zápisu). Pokud však vaše aplikace provádí mnoho souběžných aktualizací, budete to muset porovnat sami.
Hardware
Provedl jsem benchmark na stejných dvou strojích jako předtím, ale výsledky/závěry jsou téměř totožné, takže uvedu pouze čísla z toho menšího, tj.
- CPU i5-2500K (4 jádra/vlákna)
- 8 GB RAM
- 6 x 100 GB SSD RAID0
- jádro 5.6.15, souborový systém ext4
Již dříve jsem zmínil, že datová sada má při načtení téměř 10 GB, takže je větší než RAM. Ale indexy jsou stále menší než RAM, což je pro benchmark důležité.
Výsledky
Dobře, čas na pár čísel a grafů. Uvedu výsledky jak pro načítání dat, tak pro dotazování, nejprve s GIN a poté s indexy GiST.
GIN / zatížení dat
Myslím, že náklad není nijak zvlášť zajímavý. Za prvé, většina z toho (modrá část) nemá nic společného s fulltextem, protože k tomu dochází před vytvořením dvou indexů. Většinu tohoto času tráví analýzou zpráv, přestavováním e-mailových vláken, udržováním seznamu odpovědí a tak dále. Část tohoto kódu je implementována v PL/pgSQL triggerech, část je implementována mimo databázi. Jedna část potenciálně relevantní pro fulltext je vytváření tsvectorů, ale není možné izolovat čas strávený na tom.
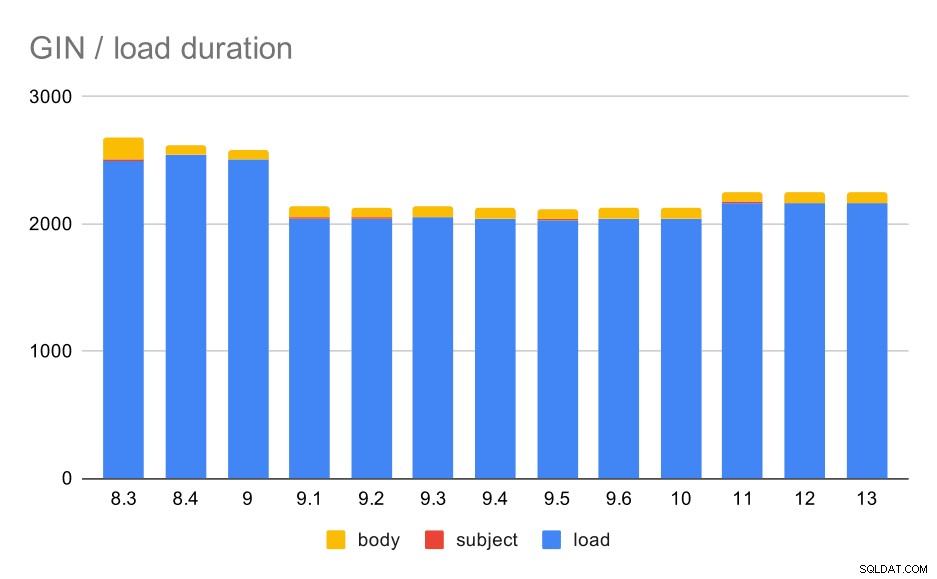
Operace načítání dat s tabulkou a indexy GIN.
Následující tabulka ukazuje zdrojová data pro tento graf – hodnoty jsou trvání v sekundách. LOAD zahrnuje analýzu archivů mbox (ze skriptu Python), vkládání do tabulky a různé další úkoly (přestavba e-mailových vláken atd.). SUBJECT/BODY INDEX odkazuje na vytvoření fulltextového GIN indexu ve sloupcích předmět/tělo po načtení dat.
| NAČÍST | SUBJECT INDEX | BODY INDEX | |
| 8,3 | 2501 | 8 | 173 |
| 8.4 | 2540 | 4 | 78 |
| 9.0 | 2502 | 4 | 75 |
| 9.1 | 2046 | 4 | 84 |
| 9.2 | 2045 | 3 | 85 |
| 9.3 | 2049 | 4 | 85 |
| 9.4 | 2043 | 4 | 85 |
| 9.5 | 2034 | 4 | 82 |
| 9.6 | 2039 | 4 | 81 |
| 10 | 2037 | 4 | 82 |
| 11 | 2169 | 4 | 82 |
| 12 | 2164 | 4 | 79 |
| 13 | 2164 | 4 | 81 |
Je zřejmé, že výkon je poměrně stabilní – mezi 9,0 a 9,1 došlo k poměrně výraznému zlepšení (zhruba 20 %). Nejsem si zcela jistý, která změna by mohla být zodpovědná za toto vylepšení – nic v poznámkách k vydání 9.1 se nezdá být jasně relevantní. Ve verzi 8.4 je také jasné zlepšení v budování indexů GIN, což zkracuje čas přibližně na polovinu. Což je samozřejmě hezké. Je zajímavé, že ani pro toto nevidím žádnou zjevně související položku poznámek k vydání.
Ale co velikosti indexů GIN? Existuje mnohem větší variabilita, přinejmenším do 9.4, kdy velikost indexů klesne z ~1 GB na pouhých 670 MB (zhruba 30 %).
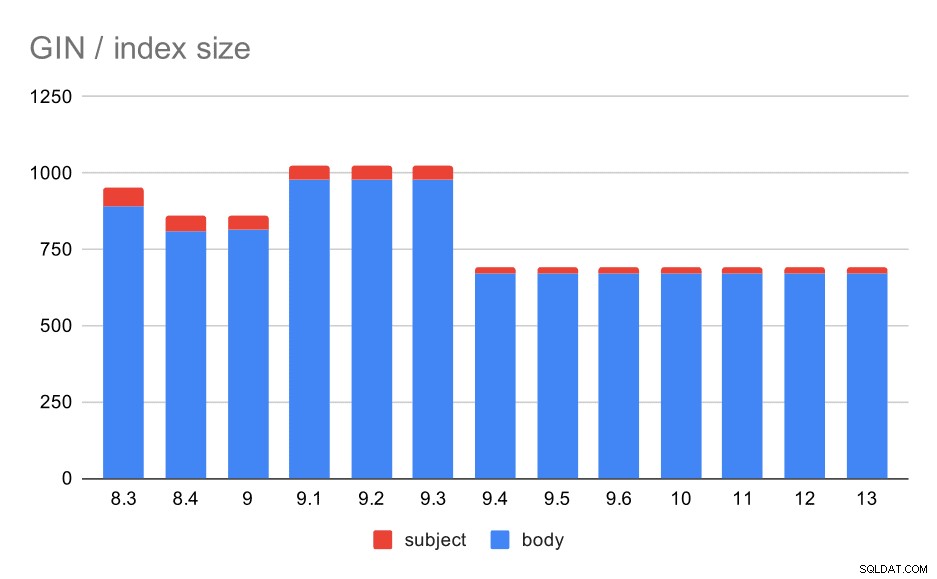
Velikost indexů GIN u předmětu/těla zprávy. Hodnoty jsou megabajty.
Následující tabulka ukazuje velikosti indexů GIN v těle zprávy a předmětu. Hodnoty jsou v megabajtech.
| BODY | PŘEDMĚT | |
| 8.3 | 890 | 62 |
| 8.4 | 811 | 47 |
| 9.0 | 813 | 47 |
| 9.1 | 977 | 47 |
| 9.2 | 978 | 47 |
| 9.3 | 977 | 47 |
| 9.4 | 671 | 20 |
| 9.5 | 671 | 20 |
| 9.6 | 671 | 20 |
| 10 | 672 | 20 |
| 11 | 672 | 20 |
| 12 | 672 | 20 |
| 13 | 672 | 20 |
V tomto případě si myslím, že můžeme bezpečně předpokládat, že toto zrychlení souvisí s touto položkou v poznámkách k vydání 9.4:
- Snížit velikost indexu GIN (Alexander Korotkov, Heikki Linnakangas)
Variabilita velikosti mezi 8.3 a 9.1 se zdá být způsobena změnami v lemmatizaci (jak se slova převádějí do „základního“ tvaru). Kromě rozdílů ve velikosti vracejí dotazy v těchto verzích například mírně odlišné počty výsledků.
GIN / dotazy
Nyní hlavní část tohoto benchmarku – výkon dotazů. Všechna zde uvedená čísla platí pro jednoho klienta – škálovatelnost klienta jsme již probrali v části týkající se výkonu OLTP, zjištění platí i pro tyto dotazy. (Navíc tento konkrétní stroj má pouze 4 jádra, takže bychom se stejně daleko, pokud jde o testování škálovatelnosti, nedostali.)
SELECT id, předmět FROM zpráv WHERE tsvector @@ $1
Nejprve dotaz vyhledá všechny odpovídající dokumenty. Pro vyhledávání ve sloupci „předmět“ můžeme udělat asi 800 dotazů za sekundu (a ve skutečnosti to v 9.1 trochu klesne), ale v 9.4 to najednou vystřelí až 3000 dotazů za sekundu. Pro sloupec „tělo“ je to v podstatě stejný příběh – zpočátku 160 dotazů, pokles na ~90 dotazů v 9.1 a poté zvýšení na 300 v 9.4.
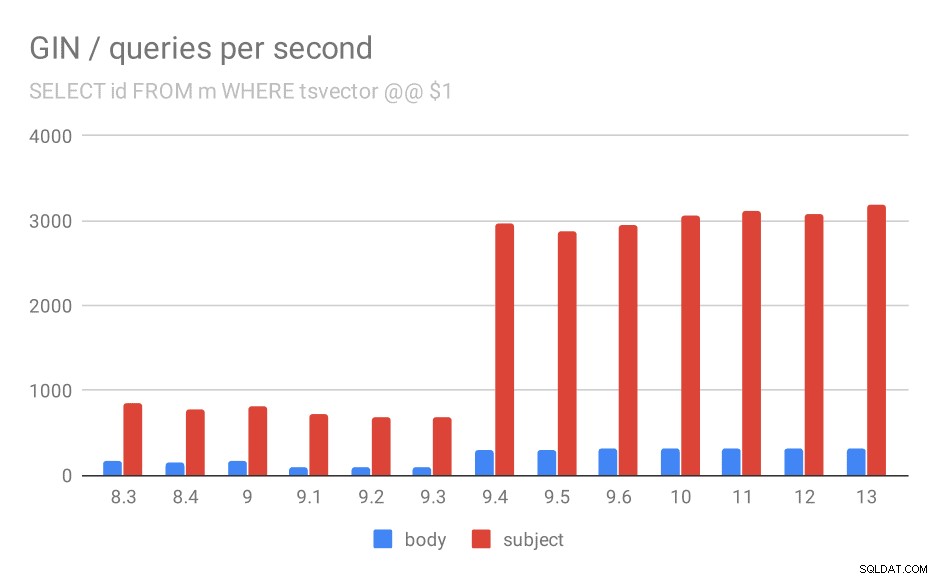
Počet dotazů za sekundu pro první dotaz (načtení všech odpovídajících řádků).
A znovu, zdrojová data – čísla jsou propustnost (počet dotazů za sekundu).
| BODY | PŘEDMĚT | |
| 8.3 | 168 | 848 |
| 8.4 | 155 | 774 |
| 9.0 | 160 | 816 |
| 9.1 | 93 | 712 |
| 9.2 | 93 | 675 |
| 9.3 | 95 | 692 |
| 9.4 | 303 | 2966 |
| 9.5 | 303 | 2871 |
| 9.6 | 310 | 2942 |
| 10 | 311 | 3066 |
| 11 | 317 | 3121 |
| 12 | 312 | 3085 |
| 13 | 320 | 3192 |
Myslím, že můžeme bezpečně předpokládat, že vylepšení v 9.4 souvisí s touto položkou v poznámkách k vydání:
- Zvýšení rychlosti víceklíčového vyhledávání GIN (Alexander Korotkov, Heikki Linnakangas)
Takže další vylepšení 9.4 v GIN od stejných dvou vývojářů – Alexander a Heikki jasně udělali hodně dobré práce na indexech GIN ve verzi 9.4 😉
SELECT id, předmět FROM zpráv WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
U dotazu, který řadí výsledky podle relevance pomocí ts_rank a LIMIT, je celkové chování téměř přesně stejné, myslím, že není třeba podrobně popisovat graf.
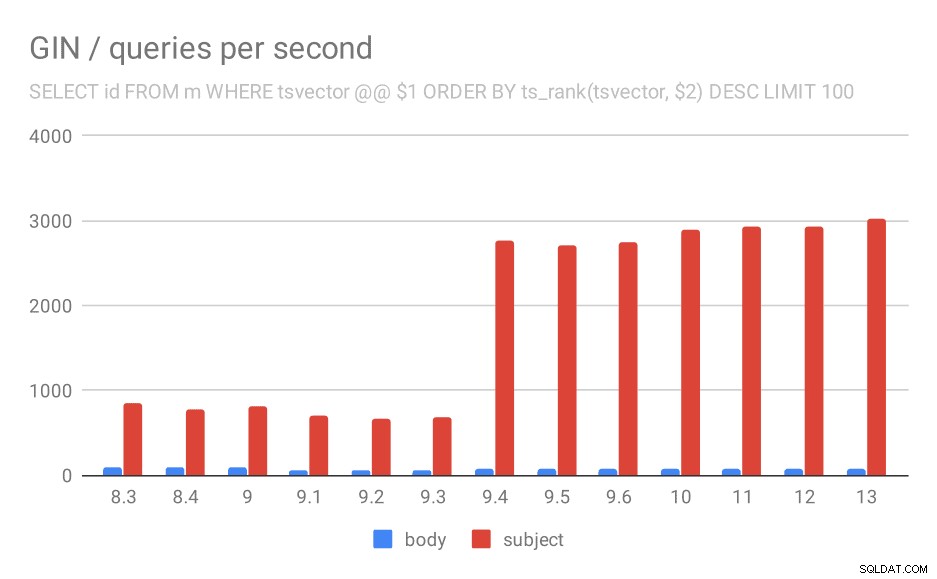
Počet dotazů za sekundu pro druhý dotaz (načítání nejrelevantnějších řádků).
| BODY | PŘEDMĚT | |
| 8.3 | 94 | 840 |
| 8.4 | 98 | 775 |
| 9.0 | 102 | 818 |
| 9.1 | 51 | 704 |
| 9.2 | 51 | 666 |
| 9.3 | 51 | 678 |
| 9.4 | 80 | 2766 |
| 9.5 | 81 | 2704 |
| 9.6 | 78 | 2750 |
| 10 | 78 | 2886 |
| 11 | 79 | 2938 |
| 12 | 78 | 2924 |
| 13 | 77 | 3028 |
Je tu však jedna otázka – proč výkon klesl mezi 9,0 a 9,1? Zdá se, že došlo k poměrně výraznému poklesu propustnosti – asi o 50 % pro vyhledávání v těle a o 20 % pro vyhledávání v předmětech zpráv. Nemám jasné vysvětlení, co se stalo, ale mám dva postřehy…
Za prvé se změnila velikost indexu – když se podíváte na první graf „GIN / velikost indexu“ a tabulku, uvidíte, že index v tělech zpráv vzrostl z 813 MB na přibližně 977 MB. To je významný nárůst a mohlo by to vysvětlit určité zpomalení. Problém je však v tom, že index předmětů vůbec nerostl, ale dotazy se také zpomalily.
Za druhé se můžeme podívat na to, kolik výsledků vrátily dotazy. Indexovaná datová sada je naprosto stejná, takže se zdá rozumné očekávat stejný počet výsledků ve všech verzích PostgreSQL, že? No, v praxi to vypadá takto:
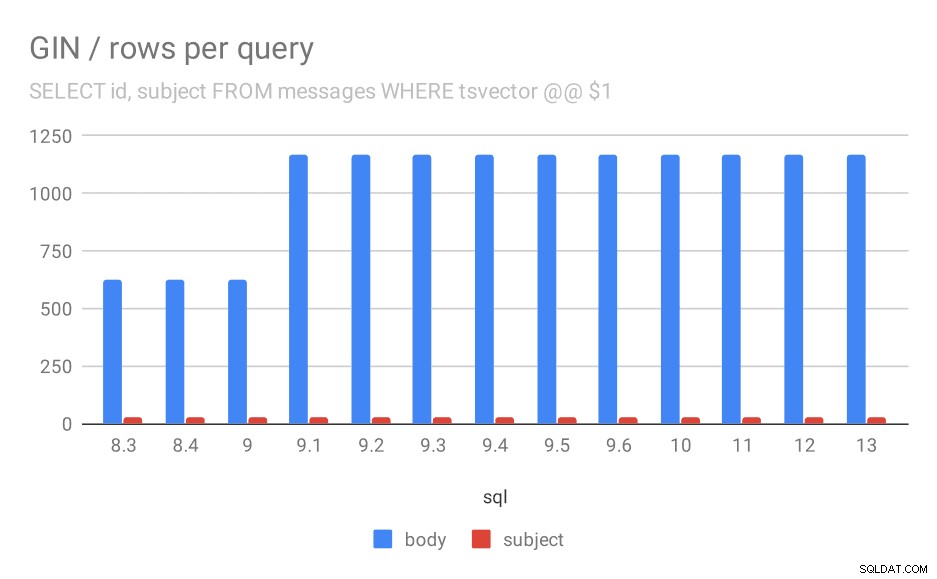
Průměrný počet řádků vrácených pro dotaz.
| BODY | PŘEDMĚT | |
| 8.3 | 624 | 26 |
| 8.4 | 624 | 26 |
| 9.0 | 622 | 26 |
| 9.1 | 1165 | 26 |
| 9.2 | 1165 | 26 |
| 9.3 | 1165 | 26 |
| 9.4 | 1165 | 26 |
| 9.5 | 1165 | 26 |
| 9.6 | 1165 | 26 |
| 10 | 1165 | 26 |
| 11 | 1165 | 26 |
| 12 | 1165 | 26 |
| 13 | 1165 | 26 |
Je zřejmé, že v 9.1 se průměrný počet výsledků vyhledávání v tělech zpráv náhle zdvojnásobí, což je téměř dokonale úměrné zpomalení. Počet výsledků vyhledávání předmětů však zůstává stejný. Nemám pro to příliš dobré vysvětlení, kromě toho, že se indexování změnilo způsobem, který umožňuje shodu více zpráv, ale je o něco pomalejší. Pokud máte lepší vysvětlení, rád bych je slyšel!
GiST / zatížení dat
Nyní další typ fulltextových indexů – GiST. Tyto indexy jsou ztrátové, to znamená, že vyžadují překontrolování výsledků pomocí hodnot z tabulky. Můžeme tedy očekávat nižší propustnost ve srovnání s indexy GIN, ale jinak je rozumné očekávat zhruba stejný vzorec.
Časy načítání skutečně téměř dokonale odpovídají GIN – časy vytvoření indexu jsou různé, ale celkový vzorec je stejný. Zrychlení v 9.1, malé zpomalení v 11.
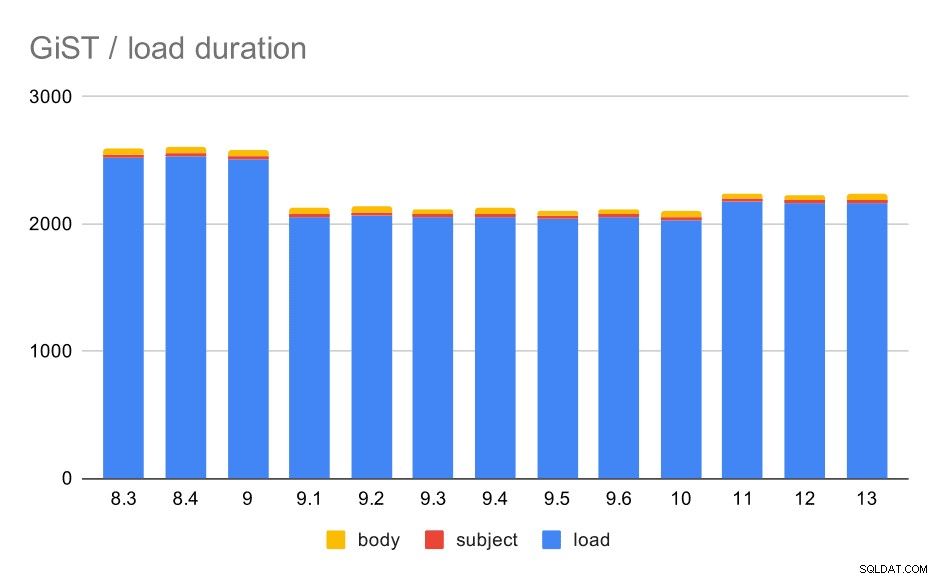
Operace načítání dat s tabulkou a indexy GiST.
| NAČÍST | PŘEDMĚT | BODY | |
| 8.3 | 2522 | 23 | 47 |
| 8.4 | 2527 | 23 | 49 |
| 9.0 | 2511 | 23 | 45 |
| 9.1 | 2054 | 22 | 46 |
| 9.2 | 2067 | 22 | 47 |
| 9.3 | 2049 | 23 | 46 |
| 9.4 | 2055 | 23 | 47 |
| 9.5 | 2038 | 22 | 45 |
| 9.6 | 2052 | 22 | 44 |
| 10 | 2029 | 22 | 49 |
| 11 | 2174 | 22 | 46 |
| 12 | 2162 | 22 | 46 |
| 13 | 2170 | 22 | 44 |
Velikost indexu však zůstala téměř konstantní – nebyla zde žádná vylepšení GiST podobná GIN v 9.4, což snížilo velikost o ~30%. Ve verzi 9.1 došlo k nárůstu, což je další známka toho, že se fulltextové indexování v této verzi změnilo, aby indexovalo více slov.
To je dále podpořeno průměrným počtem výsledků, kdy GiST je přesně stejný jako u GIN (s nárůstem 9.1).
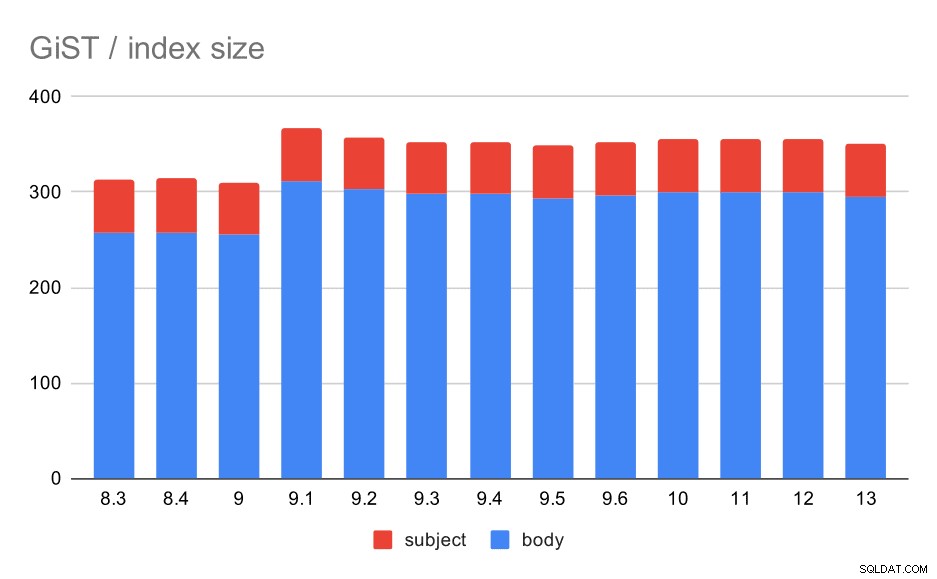
Velikost indexů GiST v předmětu/tělu zprávy. Hodnoty jsou megabajty.
| BODY | PŘEDMĚT | |
| 8.3 | 257 | 56 |
| 8.4 | 258 | 56 |
| 9.0 | 255 | 55 |
| 9.1 | 312 | 55 |
| 9.2 | 303 | 55 |
| 9.3 | 298 | 55 |
| 9.4 | 298 | 55 |
| 9.5 | 294 | 55 |
| 9.6 | 297 | 55 |
| 10 | 300 | 55 |
| 11 | 300 | 55 |
| 12 | 300 | 55 |
| 13 | 295 | 55 |
GiST / queries
Unfortunately, for the queries the results are nowhere as good as for GIN, where the throughput more than tripled in 9.4. With GiST indexes, we actually observe continuous degradation over the time.
SELECT id, subject FROM messages WHERE tsvector @@ $1
Even if we ignore versions before 9.1 (due to the indexes being smaller and returning fewer results faster), the throughput drops from ~270 to ~200 queries per second, with the main drop between 9.2 and 9.3.
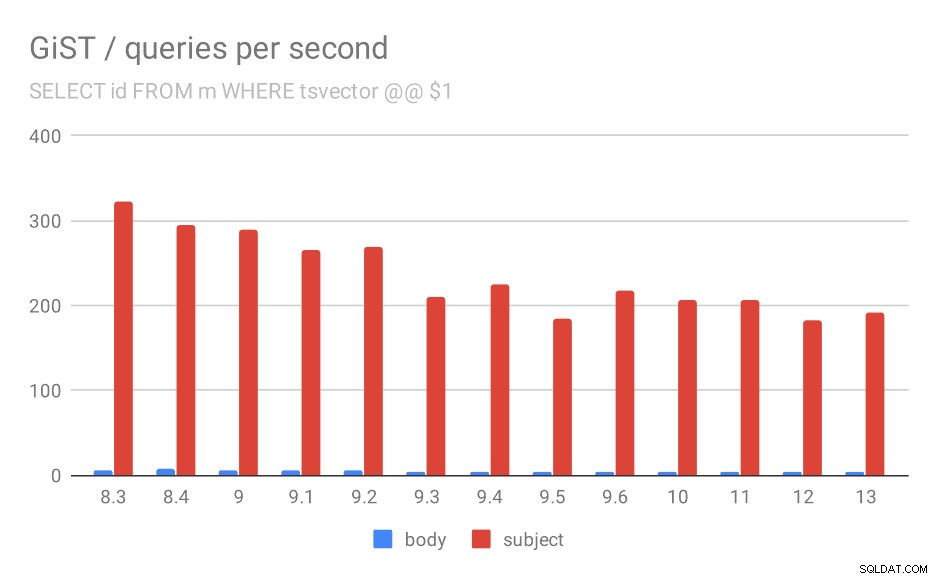
Number of queries per second for the first query (fetching all matching rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 322 |
| 8.4 | 7 | 295 |
| 9.0 | 6 | 290 |
| 9.1 | 5 | 265 |
| 9.2 | 5 | 269 |
| 9.3 | 4 | 211 |
| 9.4 | 4 | 225 |
| 9.5 | 4 | 185 |
| 9.6 | 4 | 217 |
| 10 | 4 | 206 |
| 11 | 4 | 206 |
| 12 | 4 | 183 |
| 13 | 4 | 191 |
SELECT id, subject FROM messages WHERE tsvector @@ $1
ORDER BY ts_rank(tsvector, $2) DESC LIMIT 100
And for queries with ts_rank the behavior is almost exactly the same.
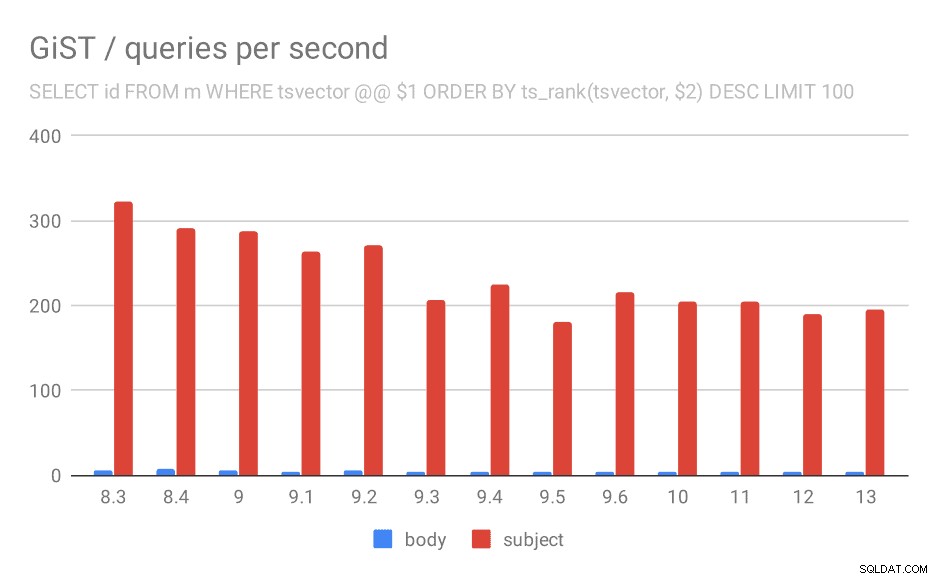
Number of queries per second for the second query (fetching the most relevant rows).
| BODY | SUBJECT | |
| 8.3 | 5 | 323 |
| 8.4 | 7 | 291 |
| 9.0 | 6 | 288 |
| 9.1 | 4 | 264 |
| 9.2 | 5 | 270 |
| 9.3 | 4 | 207 |
| 9.4 | 4 | 224 |
| 9.5 | 4 | 181 |
| 9.6 | 4 | 216 |
| 10 | 4 | 205 |
| 11 | 4 | 205 |
| 12 | 4 | 189 |
| 13 | 4 | 195 |
I’m not entirely sure what’s causing this, but it seems like a potentially serious regression sometime in the past, and it might be interesting to know what exactly changed.
It’s true no one complained about this until now – possibly thanks to upgrading to a faster hardware which masked the impact, or maybe because if you really care about speed of the searches you will prefer GIN indexes anyway.
But we can also see this as an optimization opportunity – if we identify what caused the regression and we manage to undo that, it might mean ~30% speedup for GiST indexes.
Summary and future
By now I’ve (hopefully) convinced you there were many significant improvements since PostgreSQL 8.3 (and in 9.4 in particular). I don’t know how much faster can this be made, but I hope we’ll investigate at least some of the regressions in GiST (even if performance-sensitive systems are likely using GIN). Oleg and Teodor and their colleagues were working on more powerful variants of the GIN indexing, named VODKA and RUM (I kinda see a naming pattern here!), and this will probably help at least some query types.
I do however expect to see features buil extending the existing full-text capabilities – either to better support new query types (e.g. the new index types are designed to speed up phrase search), data types and things introduced by recent revisions of the SQL standard (like jsonpath).