Jedním z nejoblíbenějších způsobů dosažení vysoké dostupnosti pro MySQL je replikace. Replikace existuje již mnoho let a se zavedením GTID se stala mnohem stabilnější. Ale i přes tato vylepšení se může proces replikace z různých důvodů přerušit – například když master a slave nejsou synchronizované, protože zápisy byly odesílány přímo do slave. Jak řešíte problémy s replikací a jak je řešíte?
V tomto příspěvku na blogu probereme některé běžné problémy s replikací a jak je vyřešit pomocí ClusterControl. Začněme tím prvním.
Replikace se zastavila s nějakou chybou
Většina MySQL DBA obvykle zaznamená tento druh problému alespoň jednou za svou kariéru. Z různých důvodů se slave může poškodit nebo se může zastavit synchronizace s masterem. Když k tomu dojde, první věcí, kterou musíte udělat pro zahájení odstraňování problémů, je zkontrolovat zprávy v protokolu chyb. Ve většině případů je chybová zpráva snadno dohledatelná v protokolu chyb nebo spuštěním dotazu SHOW SLAVE STATUS.
Podívejme se na následující příklad z SHOW STATUS SLAVE:
********** 0. row **********
Slave_IO_State:
Master_Host: 10.2.9.71
Master_User: cmon_replication
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000111
Read_Master_Log_Pos: 255477362
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: binlog.000111
Slave_IO_Running: No
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 255477362
Relay_Log_Space: 256
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master:
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 1236
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1000
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 1000-1000-2268440
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: optimistic
SQL_Delay: 0
SQL_Remaining_Delay:
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Slave_DDL_Groups: 0
Slave_Non_Transactional_Groups: 0
Slave_Transactional_Groups: 0Zřetelně vidíme, že chyba souvisí s chybou Got fatal error 1236 from master při čtení dat z binárního protokolu:'Nelze najít stav GTID požadovaný slave v žádných souborech binlog. Stav slave je pravděpodobně příliš starý a požadované soubory binlogu byly vyčištěny.'. Stručně řečeno, chyba nám v podstatě říká, že existuje nekonzistence v datech a požadované binární soubory protokolu již byly smazány.
Toto je jeden dobrý příklad, kdy proces replikace přestane fungovat. Kromě SHOW SLAVE STATUS můžete také sledovat stav na kartě „Přehled“ clusteru v ClusterControl. Jak to tedy opravit pomocí ClusterControl? Máte dvě možnosti, jak to zkusit:
-
Můžete zkusit znovu spustit slave z „Akce uzlu“
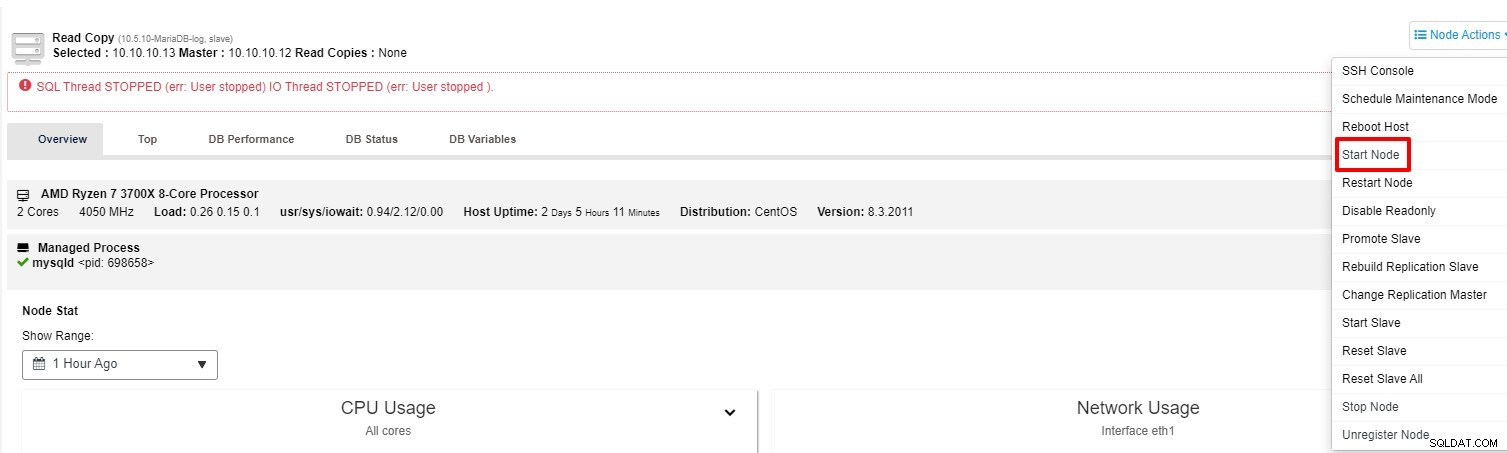
-
Pokud slave stále nefunguje, můžete spustit úlohu „Rebuild Replication Slave“ z „Akce uzlu“
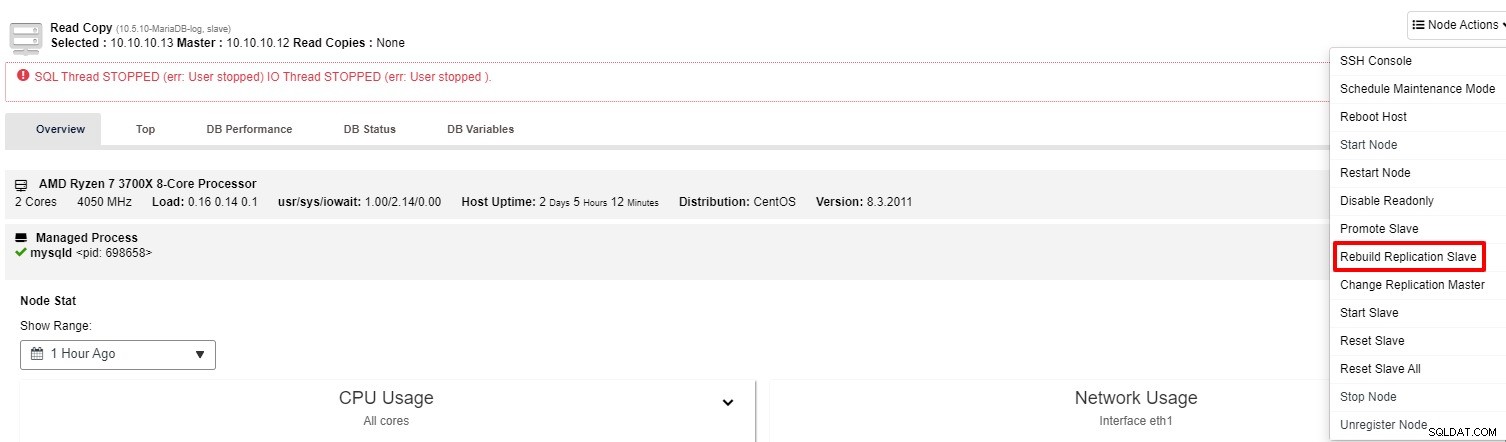
Většinou problém vyřeší druhá možnost. ClusterControl vytvoří zálohu hlavního zařízení a obnoví data obnovením rozbitého slave zařízení. Jakmile jsou data obnovena, je slave připojen k masteru, aby mohl dohnat.
Existuje také několik ručních způsobů, jak znovu sestavit slave, jak je uvedeno níže. Další podrobnosti můžete získat také na tomto odkazu:
-
Použití Mysqldump k opětovnému sestavení nekonzistentního MySQL Slave
-
Použití Mydumper k přestavbě nekonzistentního MySQL Slave
-
Použití snímku k opětovnému sestavení nekonzistentního MySQL Slave
-
Použití Xtrabackup nebo Mariabackup k přestavění nekonzistentního MySQL Slave
Povýšit otroka, aby se stal mistrem
Postupem času je třeba OS nebo databázi opravit nebo upgradovat, aby byla zachována stabilita a bezpečnost. Jedním z osvědčených postupů, jak minimalizovat prostoje, zejména u velkého upgradu, je povýšení jednoho z slave na master poté, co byl upgrade úspěšně proveden na tomto konkrétním uzlu.
Tímto způsobem můžete svou aplikaci nasměrovat na nový hlavní server a replikace master-slave bude nadále fungovat. Mezitím můžete také s klidem v duši pokračovat v upgradu starého mistra. S ClusterControl to lze provést několika kliknutími pouze za předpokladu, že replikace je nakonfigurována jako Global Transaction ID-based nebo GTID-based zkráceně. Abyste předešli ztrátě dat, vyplatí se zastavit veškeré dotazy aplikace v případě, že starý master funguje správně. Toto není jediná situace, kdy byste mohli otroka povýšit. V případě, že je hlavní uzel mimo provoz, můžete také provést tuto akci.
Bez ClusterControl existuje několik kroků k propagaci otroka. Každý z kroků vyžaduje ke spuštění také několik dotazů:
-
Ručně sundat předlohu
-
Vyberte nejpokročilejšího otroka, který se stane pánem, a připravte ho
-
Znovu připojte ostatní otroky k novému masteru
-
Změna starého pána na otroka
Nicméně kroky k podpoře Slave pomocí ClusterControl jsou jen několik kliknutí:Cluster> Nodes> zvolte slave uzel> Promote Slave podle obrázku níže:
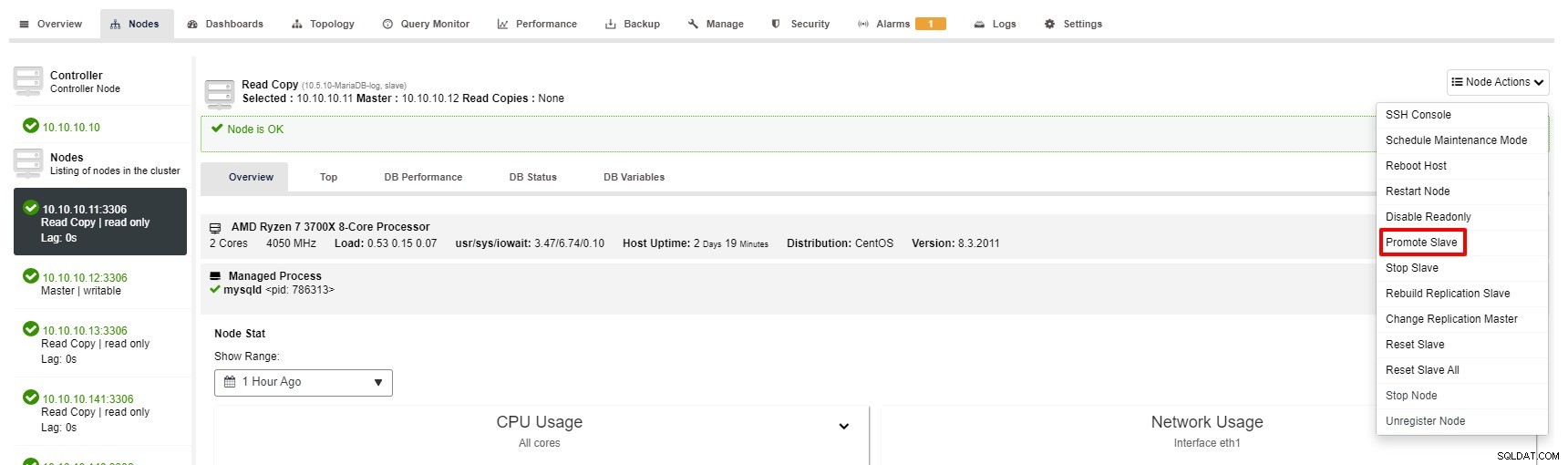
Hlavní se stává nedostupným
Představte si, že musíte spustit velké transakce, ale databáze je mimo provoz. Nezáleží na tom, jak jste opatrní, toto je pravděpodobně nejzávažnější nebo nejkritičtější situace pro nastavení replikace. Když k tomu dojde, vaše databáze není schopna přijmout jediný zápis, což je špatné. Kromě toho vaše aplikace samozřejmě nebudou fungovat správně.
Existuje několik důvodů nebo příčin, které vedou k tomuto problému. Některé z příkladů jsou selhání hardwaru, poškození operačního systému, poškození databáze a tak dále. Jako správce databáze musíte rychle jednat, abyste obnovili hlavní databázi.
Díky clusterové funkci „Auto Recovery“, která je k dispozici v ClusterControl, lze proces převzetí služeb při selhání automatizovat. Lze jej povolit nebo zakázat jediným kliknutím. Jak název napovídá, v případě potřeby vyvolá celou topologii clusteru. Například replikace master-slave musí mít v daný okamžik alespoň jednoho naživu, bez ohledu na počet dostupných slave. Když master není dostupný, automaticky povýší jednoho z podřízených.
Podívejme se na níže uvedený snímek obrazovky:
Na výše uvedeném snímku obrazovky vidíme, že „Automatické obnovení“ je povoleno pro klastr i uzel. V topologii si všimněte, že aktuální hlavní IP adresa je 10.10.10.11. Co se stane, když zničíme hlavní uzel pro účely testování?
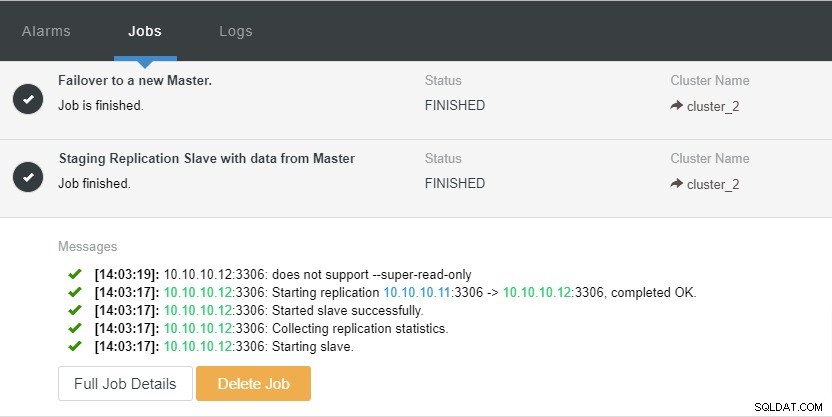
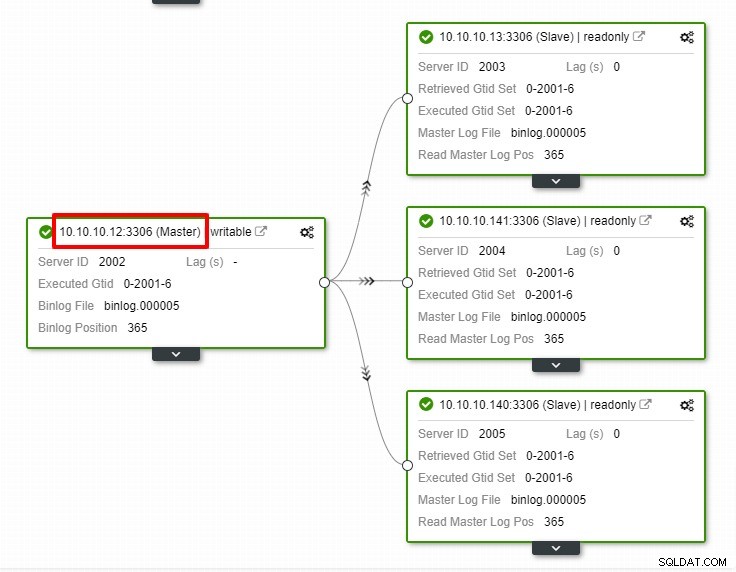
Jak vidíte, podřízený uzel s IP 10.10.10.12 je automaticky povýšen na hlavní, takže topologie replikace je překonfigurována. Namísto ručního provádění, které samozřejmě bude zahrnovat mnoho kroků, vám ClusterControl pomůže udržovat vaše nastavení replikace tím, že vám odpadne potíže.
Závěr
V jakékoli nešťastné události s vaší replikací je oprava s ClusterControl velmi jednoduchá a méně obtížná. ClusterControl vám pomůže rychle obnovit vaše problémy s replikací, což prodlouží dobu provozu vašich databází.