Význam převzetí služeb při selhání
Failover je jedním z nejdůležitějších postupů pro správu databází. Je to užitečné nejen při správě velkých databází v produkci, ale také v případě, že chcete mít jistotu, že váš systém bude vždy dostupný, kdykoli k němu přistoupíte – zejména na úrovni aplikace.
Než může dojít k převzetí služeb při selhání, musí instance vaší databáze splňovat určité požadavky. Tyto požadavky jsou ve skutečnosti velmi důležité pro vysokou dostupnost. Jedním z požadavků, které musí instance vaší databáze splňovat, je redundance. Redundance umožňuje pokračovat v převzetí služeb při selhání, ve kterém je redundance nastavena tak, aby měl kandidáta na převzetí služeb při selhání, kterým může být replika (sekundární) uzel nebo z fondu replik fungujících jako pohotovostní nebo horké pohotovostní uzly. Kandidát je vybírán buď ručně, nebo automaticky na základě nejpokročilejšího nebo nejaktuálnějšího uzlu. Obvykle byste chtěli repliku v pohotovostním režimu, protože může zachránit vaši databázi před stahováním indexů z disku, protože pohotovostní režim často zaplňuje indexy do fondu vyrovnávací paměti databáze.
Failover je termín používaný k popisu, že došlo k procesu obnovy. Před procesem obnovy k tomu dochází, když primární (nebo hlavní) databázový uzel selže po havárii, po přírodních katastrofách, po selhání hardwaru nebo může utrpět rozdělení sítě; toto jsou nejčastější případy, kdy může dojít k převzetí služeb při selhání. Proces obnovy obvykle pokračuje automaticky a poté hledá nejžádanější a nejaktuálnější sekundární (repliku), jak bylo uvedeno výše.
Pokročilé převzetí služeb při selhání
I když je proces obnovy během převzetí služeb při selhání automatický, existují určité případy, kdy není nutné proces automatizovat a řízení musí převzít ruční proces. Složitost je často hlavním hlediskem spojeným s technologiemi zahrnujícími celý zásobník vaší databáze – automatické převzetí služeb při selhání lze také kombinovat s manuálním převzetím služeb při selhání.
Ve většině každodenních úvah o správě databází není většina obav souvisejících s automatickým převzetím služeb při selhání skutečně triviální. Často přijde vhod implementovat a nastavit automatické převzetí služeb při selhání v případě problémů. Ačkoli to zní slibně, protože to pokrývá složitosti, přichází pokročilé mechanismy převzetí služeb při selhání, které zahrnují události „před“ a „po“ události, které jsou v softwaru nebo technologii pro přepnutí při selhání spojeny jako háčky.
Tyto před a po události přicházejí buď s kontrolami, nebo s určitými akcemi, které je třeba provést, než bude moci definitivně pokračovat s převzetím služeb při selhání, a poté, co je provedeno převzetí služeb při selhání, s některými vyčištěními, aby bylo zajištěno, že převzetí služeb při selhání je konečně úspěšné jeden. Naštěstí jsou k dispozici nástroje, které umožňují nejen automatické převzetí služeb při selhání, ale mají i schopnost aplikovat háčky před a po skriptu.
V tomto blogu použijeme automatické převzetí služeb při selhání ClusterControl (CC) a vysvětlíme, jak používat háky před a po skriptu a na který cluster se vztahují.
ClusterControl Replication Failover
Mechanismus převzetí služeb při selhání ClusterControl je efektivně použitelný přes asynchronní replikaci, která je použitelná pro varianty MySQL (MySQL/Percona Server/MariaDB). Je použitelný i pro clustery PostgreSQL/TimescaleDB – ClusterControl podporuje streamingovou replikaci. Klastry MongoDB a Galera mají svůj vlastní mechanismus pro automatické převzetí služeb při selhání zabudovaný do vlastní databázové technologie. Přečtěte si více o tom, jak ClusterControl provádí automatickou obnovu databáze a převzetí služeb při selhání.
Převzetí selhání ClusterControl nefunguje, pokud není povoleno obnovení uzlu a clusteru (automatické obnovení). To znamená, že tato tlačítka by měla být zelená.

V dokumentaci je uvedeno, že tyto možnosti konfigurace lze také použít k povolení / zakázat následující:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
Pro tento blog se zaměřujeme hlavně na to, jak používat háky před/po skriptu, což je v podstatě velká výhoda pro pokročilé převzetí služeb při selhání replikace.
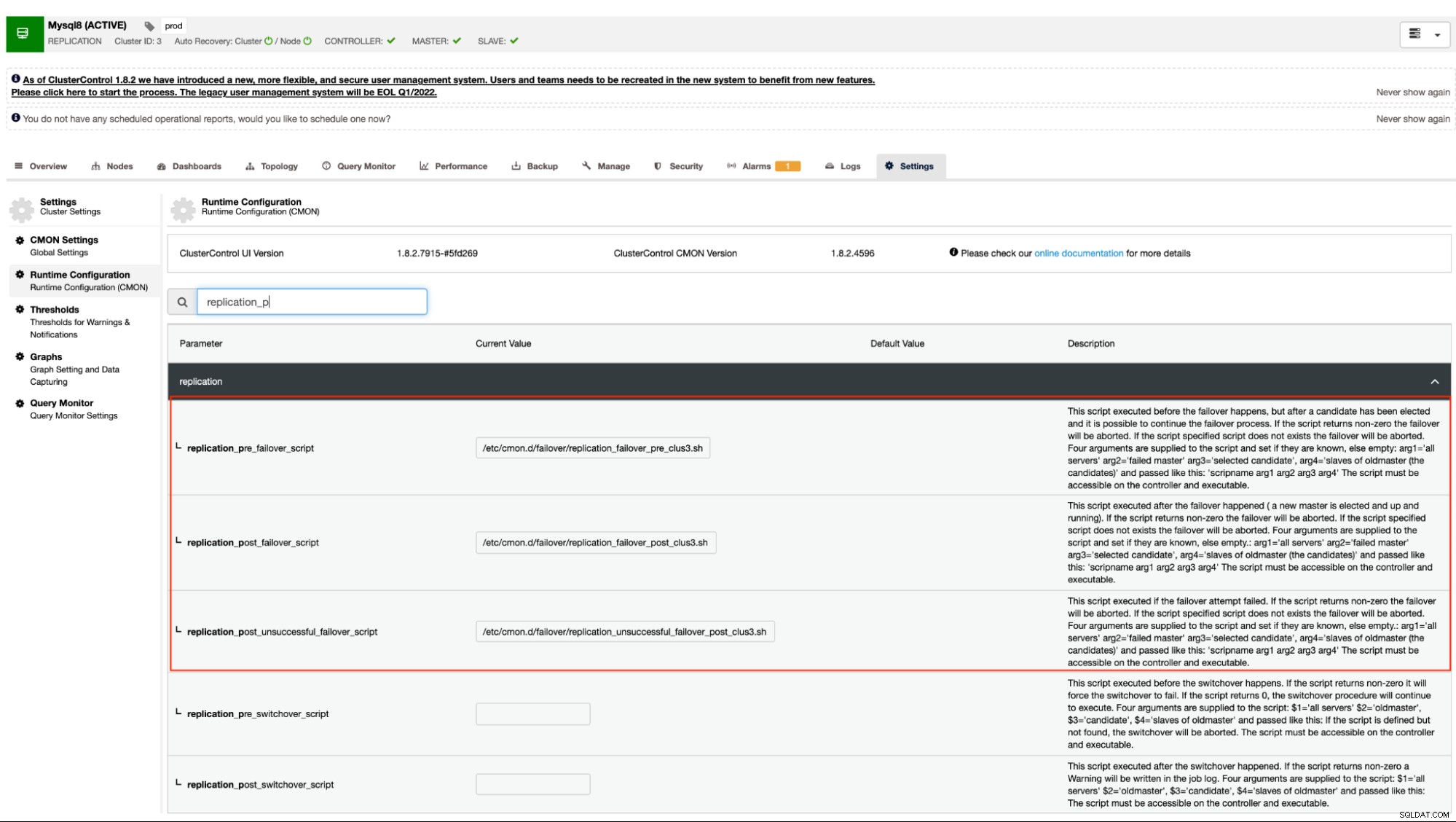
Podpora před/po skriptu replikace při selhání klastru
Jak již bylo zmíněno, tento mechanismus podporují varianty MySQL, které používají asynchronní (včetně semisynchronní) replikaci a streamingovou replikaci pro PostgreSQL/TimescaleDB. ClusterControl má následující možnosti konfigurace, které lze použít pro háky před a po skriptu. V zásadě lze tyto možnosti konfigurace nastavit prostřednictvím jejich konfiguračních souborů nebo je lze nastavit prostřednictvím webového uživatelského rozhraní (tím se budeme zabývat později).
Naše dokumentace uvádí, že toto jsou následující možnosti konfigurace, které mohou změnit mechanismus převzetí služeb při selhání pomocí háčků před/po skriptu:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Technicky platí, že jakmile v konfiguračním souboru /etc/cmon.d/cmon_
$ systemctl restart cmonPřípadně můžete také nastavit možnosti konfigurace tak, že přejdete do
Tento přístup by stále vyžadoval restartování služby cmon, než se projeví změny provedené pro tyto možnosti konfigurace pro háky před/po skriptu.
Příklad háčků před/po skriptu
V ideálním případě jsou háčky před/po skriptu vyhrazeny, když potřebujete pokročilé převzetí služeb při selhání, pro které ClusterControl nezvládne složitost nastavení vaší databáze. Pokud například provozujete různá datová centra se zpřísněným zabezpečením a chcete zjistit, zda upozornění na nedostupnost sítě není falešným pozitivním poplachem. Musí zkontrolovat, zda se primární a slave mohou navzájem dosáhnout a naopak, a také se mohou dostat z databázových uzlů jdoucích do hostitele ClusterControl.
Pojďme to udělat v našem příkladu a ukázat, jak z toho můžete mít prospěch.
Podrobnosti o serveru a skripty
V tomto příkladu používám klastr replikace MariaDB pouze s primární a replikou. Spravuje ClusterControl pro správu převzetí služeb při selhání.
ClusterControl =192.168.40.110
primární (debnode5) =192.168.30.50
replika (debnode9) =192.168.30.90
V primárním uzlu vytvořte skript, jak je uvedeno níže,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Ujistěte se, že soubor /opt/pre_failover.sh je spustitelný, tj.
$ chmod +x /opt/pre_failover.shPotom použijte tento skript k zapojení přes cron. V tomto příkladu jsem vytvořil soubor /etc/cron.d/ccfailover s následujícím obsahem:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shVe své replice použijte následující kroky, které jsme provedli pro primární, kromě změny názvu hostitele. Podívejte se na to, co mám níže ve své replice:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"a ujistěte se, že skript vyvolaný v našem cronu je spustitelný,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shPřed/post skripty ClusterControl
V této ukázce je moje cluster_id 3. Jak je uvedeno dříve v naší dokumentaci, vyžaduje to, aby tyto skripty byly umístěny v našem hostiteli řadiče CC. Takže v mém /etc/cmon.d/cmon_3.cnf mám následující:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shNásledující skript „před“ převzetí služeb při selhání určuje, zda byly oba uzly schopny dosáhnout hostitele řadiče CC. Viz následující:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Ukázka převzetí služeb při selhání
Nyní se pokusíme simulovat výpadek sítě na primárním uzlu a uvidíme, jak bude reagovat. V mém primárním uzlu vyřazuji síťové rozhraní, které se používá ke komunikaci s replikou a řadičem CC.
example@sqldat.com:~# ip link set enp0s8 downBěhem prvního pokusu o převzetí služeb při selhání se CC podařilo spustit můj předběžný skript, který se nachází na adrese /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Níže se podívejte, jak to funguje:
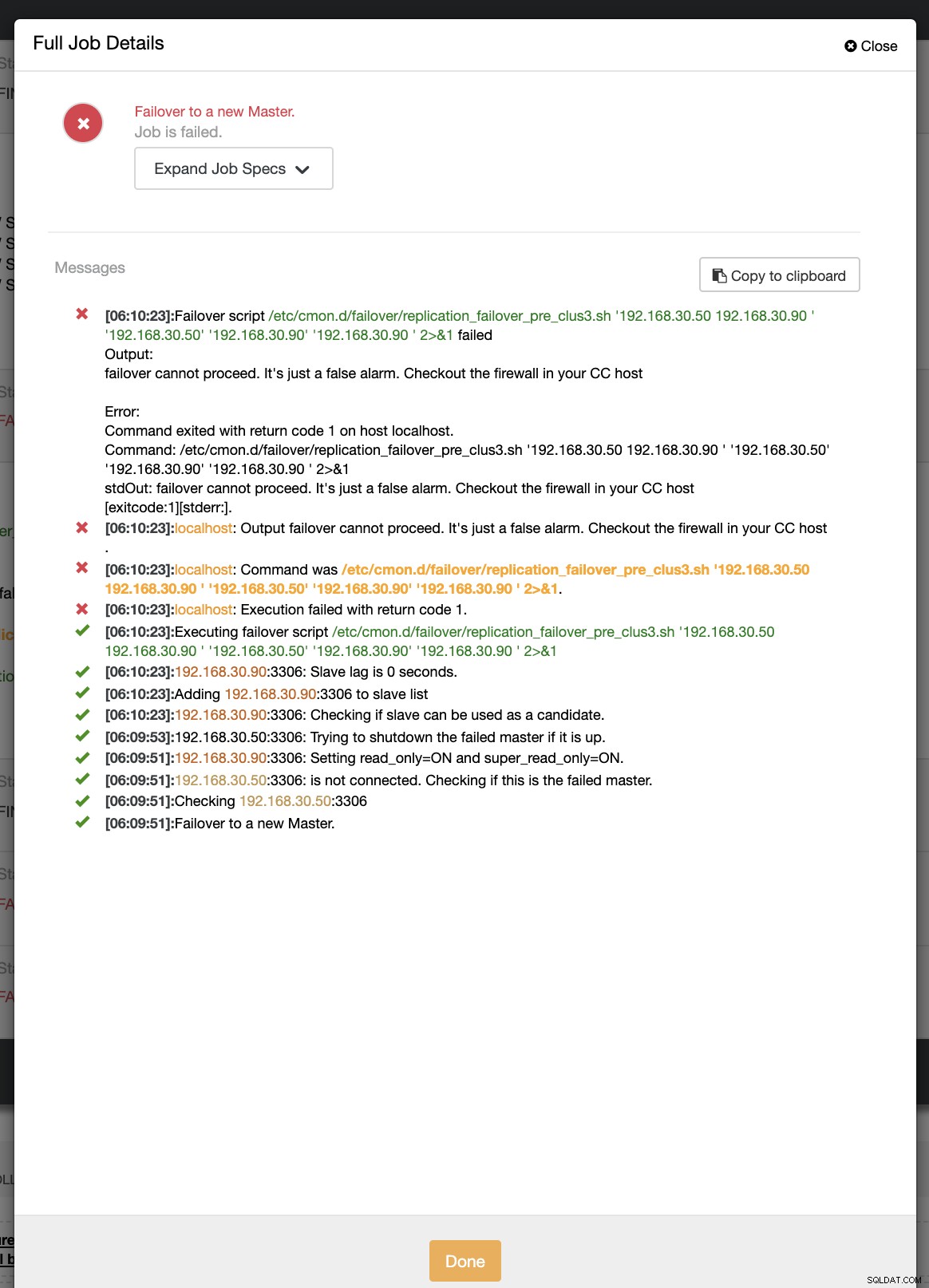
Je zřejmé, že se to nezdaří, protože časové razítko, které bylo zaznamenáno, ještě není delší než minuta nebo to bylo jen před několika sekundami, kdy se primární jednotka stále dokázala spojit s CC řadičem. Je zřejmé, že to není dokonalý přístup, když se zabýváte skutečným scénářem. ClusterControl však dokázal vyvolat a spustit skript perfektně podle očekávání. A co když to skutečně dosáhne více než minuty (tj.> 60 sekund)?
Při našem druhém pokusu o převzetí služeb při selhání, protože časové razítko dosáhlo více než 60 sekund, se to považuje za skutečně pozitivní, a to znamená, že musíme provést převzetí služeb při selhání, jak bylo zamýšleno. CC to dokázalo dokonale vykonat a dokonce provést post skript tak, jak bylo zamýšleno. To lze vidět v protokolu úloh. Viz snímek obrazovky níže:
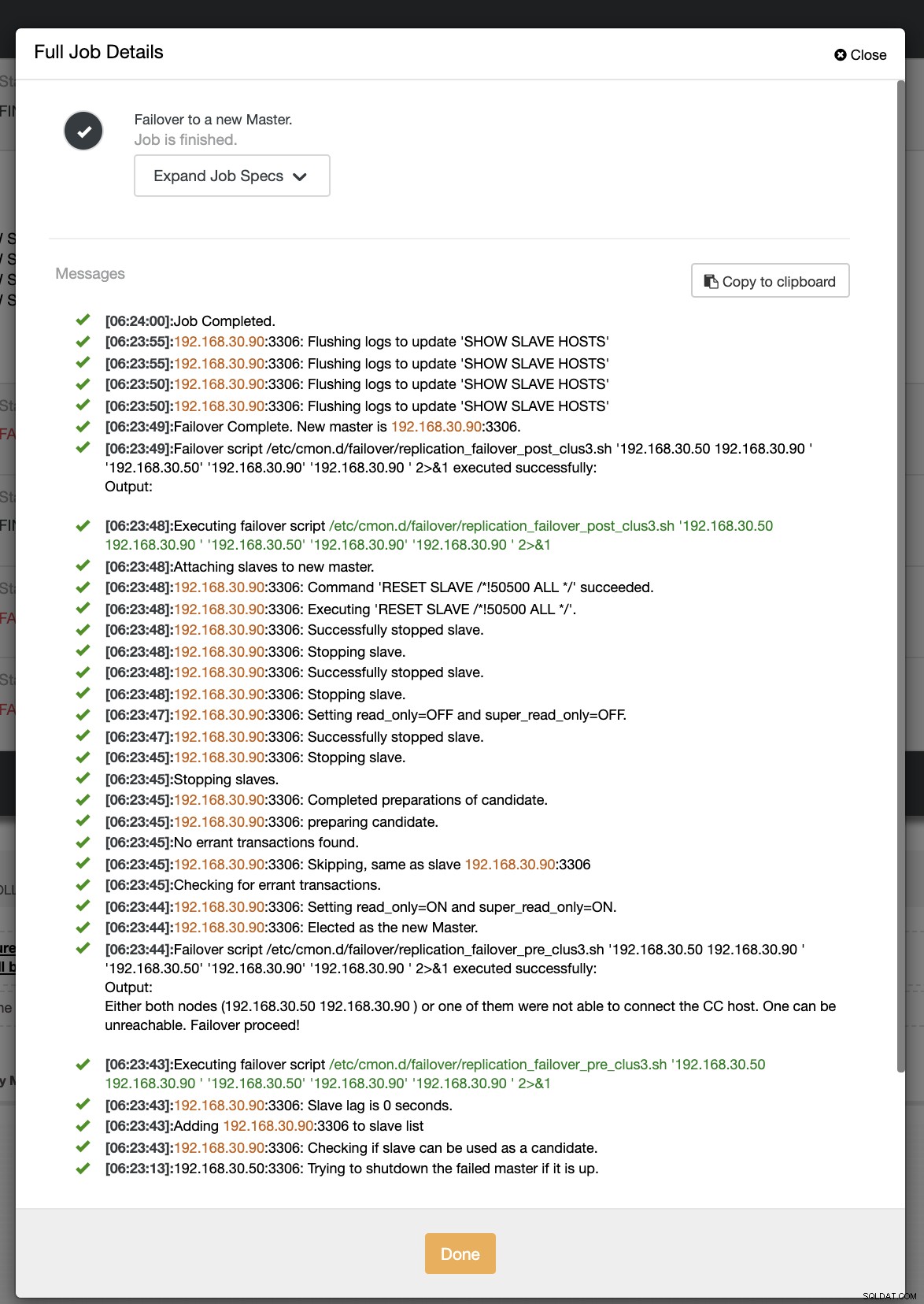
Ověřením, zda byl spuštěn můj skript příspěvku, bylo možné vytvořit protokol soubor v adresáři CC /tmp podle očekávání,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtskript po převzetí služeb při selhání na clusteru 3 s argumenty:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
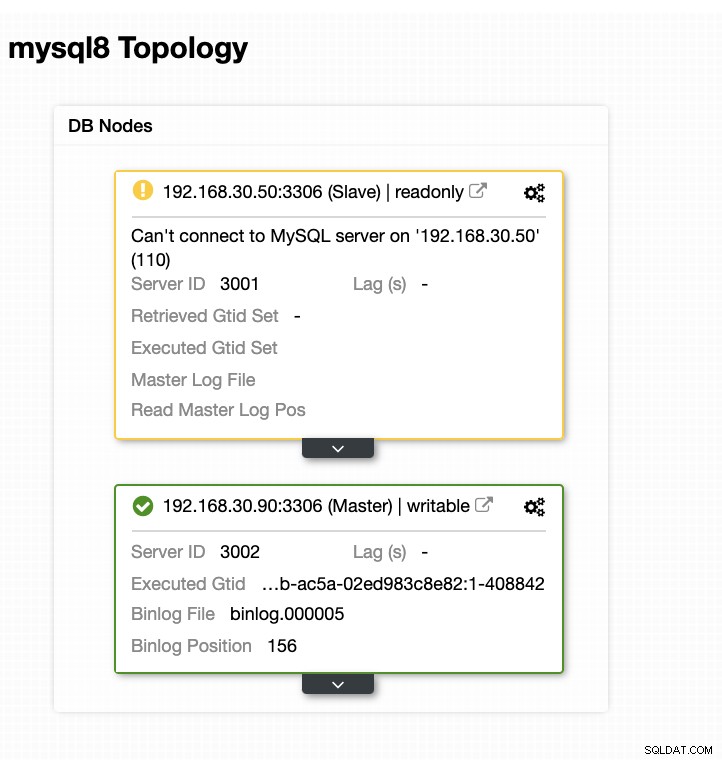
Moje topologie byla změněna a převzetí služeb při selhání bylo úspěšné!
Závěr
Pro jakékoli komplikované nastavení databáze, které můžete mít, když je vyžadováno pokročilé převzetí služeb při selhání, mohou být velmi užitečné skripty pre/post, aby bylo možné věci dosáhnout. Protože ClusterControl tyto funkce podporuje, ukázali jsme, jak je výkonný a užitečný. I přes svá omezení vždy existují způsoby, jak učinit věci dosažitelnými a užitečnými, zejména v produkčním prostředí.