Toto je pátý a poslední díl ze série zabývající se řešením výzvy generátoru číselných řad. V 1. části, 2. části, 3. části a 4. části jsem se zabýval čistě T-SQL řešeními. Když jsem hádanku zveřejnil, několik lidí poznamenalo, že nejvýkonnějším řešením by pravděpodobně bylo řešení založené na CLR. V tomto článku tento intuitivní předpoklad vyzkoušíme. Konkrétně se budu věnovat řešením založeným na CLR, která zveřejnili Kamil Kosno a Adam Machanic.
Mnohokrát děkujeme Alanu Bursteinovi, Joe Obbishovi, Adamu Machanicovi, Christopheru Fordovi, Jeffu Modenovi, Charliemu, NoamGr, Kamilu Kosnovi, Dave Masonovi, Johnu Nelsonovi #2, Edu Wagnerovi, Michaelu Burbeovi a Paulu Whiteovi za sdílení vašich nápadů a komentářů.
Testuji v databázi s názvem testdb. Pomocí následujícího kódu vytvořte databázi, pokud neexistuje, a povolte I/O a časové statistiky:
-- DB a statsSET NOCOUNT ON;SET STATISTICS IO, TIME ON;GO IF DB_ID('testdb') JE NULL CREATE DATABASE testdb;GO USE testdb;GO Pro jednoduchost vypnu přísné zabezpečení CLR a učiním databázi důvěryhodnou pomocí následujícího kódu:
-- Povolte CLR, zakažte přísné zabezpečení CLR a nastavte databázi jako důvěryhodnouEXEC sys.sp_configure 'zobrazit pokročilá nastavení', 1;RECONFIGURE; EXEC sys.sp_configure 'clr povoleno', 1;EXEC sys.sp_configure 'přísné zabezpečení clr', 0;RECONFIGURE; EXEC sys.sp_configure 'zobrazit pokročilé nastavení', 0;RECONFIGURE; ALTER DATABASE testdb NASTAVIT DŮVĚRYHODNÉ ZAPNUTO; GO
Dřívější řešení
Než se budu věnovat řešením založeným na CLR, pojďme se rychle podívat na výkon dvou nejvýkonnějších řešení T-SQL.
Nejvýkonnější řešení T-SQL, které nepoužívalo žádné trvalé základní tabulky (jiné než fiktivní prázdnou tabulku columnstore pro dávkové zpracování), a proto nezahrnovalo žádné I/O operace, bylo řešení implementované ve funkci dbo.GetNumsAlanCharlieItzikBatch. Toto řešení jsem popsal v části 1.
Zde je kód k vytvoření fiktivní prázdné tabulky columnstore, kterou používá dotaz funkce:
PŘEHNEJTE TABULKU, POKUD EXISTUJE dbo.BatchMe;GO VYTVOŘIT TABULKU dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);GO
A zde je kód s definicí funkce:
VYTVOŘIT NEBO ZMĚNIT FUNKCI dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT =1, @high AS BIGINT) VRÁTÍ TABLEASRETURN S L0 AS ( VYBERTE 1 AS c FROM (VALUES(1),(1),(1),(1) ),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ), L1 AS ( VYBERTE 1 JAKO c Z L0 JAKO KŘÍŽOVÉ PŘIPOJENÍ L0 AS B ), L2 AS ( VYBERTE 1 JAKO c Z L1 JAKO KŘÍŽOVÉ SPOJE L1 JAKO B ), L3 AS ( VYBERTE 1 JAKO c FROM L2 AS A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) AS rownum FROM L3 ) SELECT TOP (@high - @low + 1) rownum AS rn, @high + 1 - rownum AS op, @low - 1 + rownum AS n FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 =0 ORDER BY rownum;GO
Nejprve otestujme funkci požadující řadu 100 milionů čísel s agregací MAX aplikovanou na sloupec n:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Připomeňme, že tato testovací technika se vyhýbá přenosu 100 milionů řádků volajícímu a také se vyhýbá úsilí v režimu řádků spojené s přiřazování proměnných při použití techniky přiřazování proměnných.
Zde jsou časové statistiky, které jsem získal pro tento test na svém počítači:
Čas CPU =6719 ms, uplynulý čas =6742 ms .Provedení této funkce samozřejmě neprodukuje žádné logické čtení.
Dále to otestujeme s pořadím pomocí techniky přiřazení proměnné:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Mám následující časové statistiky pro toto provedení:
Čas CPU =9468 ms, uplynulý čas =9531 ms .Připomeňme, že tato funkce nevede k řazení při požadavku na data uspořádaná podle n; v zásadě získáte stejný plán, ať už požadujete objednaná data nebo ne. Většinu času navíc v tomto testu ve srovnání s předchozím můžeme připsat 100 milionům přiřazení proměnných v režimu řádků.
Nejvýkonnějším řešením T-SQL, které používalo trvalou základní tabulku, a proto vedlo k některým I/O operacím, i když jen velmi málo, bylo řešení Paula Whitea implementované ve funkci dbo.GetNums_SQLkiwi. Toto řešení jsem popsal v části 4.
Zde je Paulův kód pro vytvoření tabulky columnstore používané funkcí i funkcí samotnou:
-- Helper columnstore tableDROP TABLE IF EXISTS dbo.CS; -- 64 tisíc řádků (dost na 4 B řádků při křížovém spojení) -- sloupec 1 je vždy nula -- sloupec 2 je (1...65536) SELECT -- zadejte celé číslo NOT NULL -- (vše je normalizováno na 64 bitů columnstore/batch mode každopádně) n1 =ISNULL(CONVERT(celé číslo, 0), 0), n2 =ISNULL(CONVERT(celé číslo, N.rn), 0)INTO dbo.CSFROM ( SELECT rn =ROW_NUMBER() OVER (ORDER BY @@SPID) FROM master.dbo.spt_values AS SV1 CROSS JOIN master.dbo.spt_values AS SV2 ORDER BY rn ASC OFFSET 0 ŘÁDKŮ NAČÍT DALŠÍ POUZE 65536 ŘÁDKŮ) JAKO N; -- Jedna komprimovaná skupina řádků o 65 536 řádcích VYTVOŘTE KLUSTROVANÝ INDEX COLUMNSTORE CCI NA dbo.CS S (MAXDOP =1);GO -- Funkce CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi( @low bigint =1, @high table ASTURNRETURN)RETURNS .rn, n =@nízká - 1 + N.rn, op =@vysoká + 1 - N.rn FROM ( SELECT -- Použijte @@TRANCOUNT místo @@SPID, pokud se vám líbí všechny vaše dotazy serial rn =ROW_NUMBER() OVER (OBJEDNAT PODLE @@SPID ASC) OD dbo.CS JAKO N1 PŘIPOJIT dbo.CS JAKO N2 -- Křížové spojení hash v dávkovém režimu -- Datový typ Integer not null vyhnout se zbytkům sondy hash -- Toto je vždy 0 =0 NA N2. n1 =N1.n1 KDE -- Pokuste se vyhnout SQRT na záporných číslech a povolte zjednodušení -- na jediné konstantní skenování, pokud @nízká> @vysoká (s literály) -- Žádné spouštěcí filtry v dávkovém režimu @vysoká>=@nízká -- Hrubý filtr:-- Omezte každou stranu křížové spojení na SQRT(cílový počet řádků) -- IIF se vyhýbá SQRT na záporných číslech s parametry AND N1.n2 <=CONVERT(celé číslo, CEILING(SQRT(CONVERT(plovoucí, IIF(@vysoký>=@nízký, @vysoký) - @nízká + 1, 0))))) A N2.n2 <=CONVERT(celé číslo, CEILING(SQRT(CONVERT(plovoucí, IIF(@vysoká>=@nízká, @vysoká - @nízká + 1, 0))) ))) ) AS N WHERE -- Přesný filtr:-- Filtr v dávkovém režimu s omezeným křížovým spojením na přesný počet potřebných řádků -- Zabrání optimalizaci zavedení režimu řádku Top s následujícím skalárním výpočtem v režimu řádků @low - 2 + N.rn <@high;GO
Nejprve to otestujeme bez pořadí pomocí agregační techniky, výsledkem je plán všech dávkových režimů:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Mám následující statistiky času a I/O pro toto provedení:
Čas CPU =2922 ms, uplynulý čas =2943 ms .Tabulka 'CS'. Počet skenování 2, logická čtení 0, fyzická čtení 0, stránkovací server čte 0, čtení napřed čtení 0, stránkový server napřed čtení 0, lob logické čtení 44 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.
Tabulka 'CS'. Segment čte 2, segment přeskočen 0.
Pojďme otestovat funkci s pořadím pomocí techniky přiřazení proměnných:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Stejně jako u předchozího řešení se i toto řešení vyhýbá explicitnímu řazení v plánu, a proto získá stejný plán, ať už o objednaná data požádáte nebo ne. Ale opět, tento test přináší další penalizaci hlavně kvůli zde použité technice přiřazení proměnných, což má za následek, že část přiřazení proměnných v plánu je zpracována v režimu řádků.
Zde jsou statistiky času a I/O, které jsem získal pro toto provedení:
Čas CPU =6985 ms, uplynulý čas =7033 ms .Tabulka 'CS'. Počet skenování 2, logická čtení 0, fyzická čtení 0, stránkovací server čte 0, čtení napřed čtení 0, stránkový server napřed čtení 0, lob logické čtení 44 , Lob fyzické čtení 0, Lob stránkovací server čte 0, Lob čtení napřed čte 0, Lob stránkový server čtení napřed čte 0.
Tabulka 'CS'. Segment čte 2, segment přeskočen 0.
Řešení CLR
Kamil Kosno i Adam Machanic nejprve poskytli jednoduché řešení pouze pro CLR a později přišli se sofistikovanější kombinací CLR+T-SQL. Začnu s Kamilovými řešeními a poté se zaměřím na Adamova řešení.
Řešení Kamil Kosno
Zde je kód CLR použitý v Kamilově prvním řešení k definování funkce nazvané GetNums_KamilKosno1:
using System;using System.Data.SqlTypes;using System.Collections;veřejná částečná třída GetNumsKamil1{ [Microsoft.SqlServer.Server.SqlFunction(FillRowMethodName ="GetNums_KamilKosno1_Fill", Kamimer TableDefinition1] public GetNumsKamilnos (SqlInt64 low, SqlInt64 high) { return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0) :new GetNumsCS(low.Value, high.Value); } public static void GetNums_KamilKosno1_Fill(Object o, out SqlInt64 n) { n =(long)o; } private class GetNumsCS :IEnumerator { public GetNumsCS(long from, long to) { _lowrange =from; _current =_lowrange - 1; _highrange =do; } public bool MoveNext() { _current +=1; if (_current> _highrange) return false; else return true; } public object Current { get { return _current; } } public void Reset() { _current =_lowrange - 1; } long _lowrange; dlouhý _aktuální; dlouhý _vysoký rozsah; }} Funkce přijímá dva vstupy nazvané low a high a vrátí tabulku se sloupcem BIGINT s názvem n. Funkce je typu streamování a vrací řádek s dalším číslem v řadě na řádek požadavku z volajícího dotazu. Jak vidíte, Kamil zvolil formalizovanější metodu implementace rozhraní IEnumerator, která zahrnuje implementaci metod MoveNext (posune čítač, aby se dostal na další řádek), Current (získá řádek na aktuální pozici čítače) a Reset (nastaví enumerátor do výchozí polohy, která je před prvním řádkem).
Proměnná obsahující aktuální číslo v řadě se nazývá _current. Konstruktor nastaví _current na dolní hranici požadovaného rozsahu mínus 1 a totéž platí pro metodu Reset. Metoda MoveNext posouvá _current o 1. Pokud je pak _current větší než horní hranice požadovaného rozsahu, metoda vrátí hodnotu false, což znamená, že již nebude volána. V opačném případě vrátí hodnotu true, což znamená, že bude volána znovu. Metoda Current přirozeně vrací _current. Jak vidíte, docela základní logika.
Nazval jsem projekt Visual Studio GetNumsKamil1 a použil pro něj cestu C:\Temp\. Zde je kód, který jsem použil k nasazení funkce v databázi testdb:
FUNKCE DROP, POKUD EXISTUJE dbo.GetNums_KamilKosno1; ZRUŠTE SESTAVU, POKUD EXISTUJE GetNumsKamil1;GO VYTVOŘIT SESTAVU GetNumsKamil1 FROM 'C:\Temp\GetNumsKamil1\GetNumsKamil1\bin\Debug\GetNumsKamil1.dll';PŘEJÍT VYTVOŘIT FUNKCI,PROVEDENÍ FUNKCE,ASlS1 ASIGNO. TABLE(n BIGINT) ORDER(n) JAKO EXTERNÍ NÁZEV GetNumsKamil1.GetNumsKamil1.GetNums_KamilKosno1;GO
Všimněte si použití klauzule ORDER v příkazu CREATE FUNCTION. Funkce vydává řádky v n řazení, takže když je třeba řádky zpracovat v plánu v n řazení, na základě této klauzule SQL Server ví, že se může vyhnout řazení v plánu.
Otestujme funkci, nejprve agregační technikou, když není potřeba objednávat:
SELECT MAX(n) AS mx FROM dbo.GetNums_KamilKosno1(1, 100000000);
Mám plán zobrazený na obrázku 1.
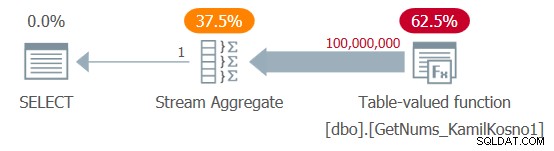 Obrázek 1:Plán pro funkci dbo.GetNums_KamilKosno1
Obrázek 1:Plán pro funkci dbo.GetNums_KamilKosno1
O tomto plánu není moc co říci, kromě skutečnosti, že všichni operátoři používají režim provádění řádku.
Mám následující časové statistiky pro toto provedení:
Čas CPU =37375 ms, uplynulý čas =37488 ms .A samozřejmě nešlo o žádné logické čtení.
Pojďme otestovat funkci s pořadím pomocí techniky přiřazení proměnných:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNums_KamilKosno1(1, 100000000) ORDER BY n;
Získal jsem plán znázorněný na obrázku 2 pro toto provedení.
 Obrázek 2:Plán pro funkci dbo.GetNums_KamilKosno1 s ORDER BY
Obrázek 2:Plán pro funkci dbo.GetNums_KamilKosno1 s ORDER BY
Všimněte si, že v plánu není žádné řazení, protože funkce byla vytvořena s klauzulí ORDER(n). Existuje však určité úsilí, abychom zajistili, že řádky jsou skutečně vysílány z funkce ve slíbeném pořadí. To se provádí pomocí operátorů Segment a Sequence Project, které se používají k výpočtu čísel řádků, a operátoru Assert, který přeruší provádění dotazu, pokud test selže. Tato práce má lineární škálování – na rozdíl od škálování n log n, které byste získali, kdyby bylo vyžadováno řazení – ale stále to není levné. Pro tento test mám následující časové statistiky:
Čas CPU =51531 ms, uplynulý čas =51905 ms .Výsledky mohou být pro některé překvapivé – zejména pro ty, kteří intuitivně předpokládali, že řešení založená na CLR budou fungovat lépe než řešení T-SQL. Jak můžete vidět, doby provádění jsou o řád delší než u našeho nejvýkonnějšího řešení T-SQL.
Kamilovo druhé řešení je hybrid CLR-T-SQL. Kromě nízkých a vysokých vstupů přidává funkce CLR (GetNums_KamilKosno2) skokový vstup a vrací hodnoty mezi nízkým a vysokými hodnotami, které jsou od sebe vzdáleny. Zde je kód CLR, který Kamil použil ve svém druhém řešení:
použitím System;použitím System.Data.SqlTypes;použitím System.Collections; veřejná částečná třída GetNumsKamil2{ [Microsoft.SqlServer.Server.SqlFunction(DataAccess =Microsoft.SqlServer.Server.DataAccessKind.None, IsDeterministic =true, IsPrecise =true, FillRowMethodName ="GetNums_Fill", BIGINTstatic) public ="n TableDefinition" IEnumerator GetNums_KamilKosno2(SqlInt64 low, SqlInt64 high, SqlInt64 step) { return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0, step.Value) :new GetNumsCS(low.Value, high.Value, step.Value); } public static void GetNums_Fill(Object o, out SqlInt64 n) { n =(long)o; } private class GetNumsCS :IEnumerator { public GetNumsCS(dlouhý od, dlouhý do, dlouhý krok) { _lowrange =from; _krok =krok; _current =_lowrange - _step; _highrange =do; } public bool MoveNext() { _current =_current + _step; if (_current> _highrange) return false; else return true; } public object Current { get { return _current; } } public void Reset() { _current =_lowrange - _step; } long _lowrange; dlouhý _aktuální; dlouhý _vysoký rozsah; dlouhý _krok; }} Projekt VS jsem pojmenoval GetNumsKamil2, umístil ho také do cesty C:\Temp\ a použil následující kód k jeho nasazení v databázi testdb:
-- Vytvořit sestavení a funkciDROP FUNKCE, POKUD EXISTUJE dbo.GetNums_KamilKosno2;DROP SESTAVENÍ, POKUD EXISTUJE GetNumsKamil2;PŘEJÍT VYTVOŘIT SESTAVENÍ GetNumsKamil2 FROM 'C:\Temp\GetNumsKamil2\bugtion2\buggetN\Demp; .GetNums_KamilKosno2 (@nízký JAKO VELKÝ =1, @vysoký JAKO VELKÝ, @krok JAKO VELKÝ) VRÁTÍ TABLE (n BIGINT) OBJEDNÁVKU(n) JAKO EXTERNÍ NÁZEV GetNumsKamil2.GetNumsKamil2.GetNums_2;>Jako příklad použití funkce uvádíme požadavek na vygenerování hodnot mezi 5 a 59 s krokem 10:
SELECT n FROM dbo.GetNums_KamilKosno2(5, 59, 10);Tento kód generuje následující výstup:
n---51525354555Pokud jde o část T-SQL, Kamil použil funkci nazvanou dbo.GetNums_Hybrid_Kamil2 s následujícím kódem:
VYTVOŘIT NEBO ZMĚNIT FUNKCI dbo.GetNums_Hybrid_Kamil2(@nízká JAK VELKÁ, @vysoká JAK VELKÁ) VRÁTÍ TABLEASRETURN SELECT TOP (@vysoká - @nízká + 1) V.n OD dbo.GetNums_KamilKosno2(@low,01) KŘÍŽOVÉ POUŽITÍ (HODNOTY(0+GN.n),(1+GN.n),(2+GN.n),(3+GN.n),(4+GN.n), (5+GN.n ),(6+GN.n),(7+GN.n),(8+GN.n),(9+GN.n)) AS V(n);GOJak můžete vidět, funkce T-SQL vyvolá funkci CLR se stejnými vstupy @low a @high, které dostává, a v tomto příkladu používá velikost kroku 10. Dotaz používá CROSS APPLY mezi výsledkem funkce CLR a konstruktor tabulky -hodnoty, který generuje konečná čísla přidáním hodnot v rozsahu 0 až 9 na začátek kroku. Filtr TOP se používá k zajištění toho, že nezískáte více než požadovaný počet čísel.
Důležité: Měl bych zdůraznit, že Kamil zde předpokládá použití filtru TOP na základě řazení podle čísla výsledku, což ve skutečnosti není zaručeno, protože dotaz nemá klauzuli ORDER BY. Pokud buď přidáte klauzuli ORDER BY pro podporu TOP, nebo nahradíte TOP filtrem WHERE, abyste zaručili deterministický filtr, mohlo by to zcela změnit výkonnostní profil řešení.
V každém případě nejprve otestujme funkci bez pořadí pomocí agregační techniky:
SELECT MAX(n) AS mx FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000);Získal jsem plán znázorněný na obrázku 3 pro toto provedení.
Obrázek 3:Plán pro funkci dbo.GetNums_Hybrid_Kamil2
Opět platí, že všichni operátoři v plánu používají režim provádění řádku.
Mám následující časové statistiky pro toto provedení:
Čas CPU =13985 ms, uplynulý čas =14069 ms .A přirozeně žádná logická čtení.
Pojďme otestovat funkci s objednávkou:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000) ORDER BY n;Mám plán zobrazený na obrázku 4.
Obrázek 4:Plán pro funkci dbo.GetNums_Hybrid_Kamil2 s ORDER BY
Protože výsledná čísla jsou výsledkem manipulace s dolní hranicí kroku vráceného funkcí CLR a delta přidaná v konstruktoru tabulkové hodnoty, optimalizátor nedůvěřuje, že výsledná čísla jsou generována v požadovaném pořadí, a přidává do plánu explicitní řazení.
Mám následující časové statistiky pro toto provedení:
Čas CPU =68703 ms, uplynulý čas =84538 ms .Zdá se tedy, že když není potřeba žádná objednávka, Kamilovo druhé řešení je lepší než to první. Ale když je potřeba pořádek, je to naopak. V každém případě jsou řešení T-SQL rychlejší. Osobně bych věřil správnosti prvního řešení, ale ne druhému.
Řešení od Adama Machanice
Adamovo první řešení je také základní funkce CLR, která neustále zvyšuje počítadlo. Jen místo toho, aby použil více zapojeného formalizovaného přístupu jako Kamil, použil Adam jednodušší přístup, který vyvolá příkaz výnosu na řádek, který je třeba vrátit.
Zde je Adamův kód CLR pro jeho první řešení, definující funkci streamování nazvanou GetNums_AdamMachanic1:
použití System.Data.SqlTypes;použití System.Collections; veřejná částečná třída GetNumsAdam1{ [Microsoft.SqlServer.Server.SqlFunction( FillRowMethodName ="GetNums_AdamMachanic1_fill", TableDefinition ="n BIGINT")] public static IEnumerable GetNums_AdamMachanic1(SqlInt_In) min.min.64 min. var max_int =max.Value; for (; min_int <=max_int; min_int++) { return return (min_int); } } public static void GetNums_AdamMachanic1_fill(object o, out long i) { i =(long)o; }};Řešení je tak elegantní ve své jednoduchosti. Jak vidíte, funkce přijímá dva vstupy nazvané min a max představující dolní a horní hraniční body požadovaného rozsahu a vrací tabulku s BIGINT sloupcem nazvaným n. Funkce inicializuje proměnné min_int a max_int s hodnotami vstupních parametrů příslušné funkce. Funkce pak spustí smyčku tak dlouhou jako min_int <=max_int, která v každé iteraci poskytne řádek s aktuální hodnotou min_int a zvýší min_int o 1. To je vše.
Pojmenoval jsem projekt GetNumsAdam1 ve VS, umístil jsem ho do C:\Temp\ a k jeho nasazení jsem použil následující kód:
-- Vytvořit sestavení a funkci FUNKCE DROP, POKUD EXISTUJE dbo.GetNums_AdamMachanic1;DROP SESTAVENÍ, POKUD EXISTUJE GetNumsAdam1;PŘEJÍT VYTVOŘIT SESTAVU GetNumsAdam1 Z 'C:\Temp\GetNumsAdam1\GetNumsdll\GetNumsAdam\'GetNumsdll\'ums .GetNums_AdamMachanic1(@nízké JAKO VELKÉ =1, @vysoké JAKO VELKÉ) VRÁTÍ TABULU (n BIGINT) OBJEDNÁVKU(n) JAKO EXTERNÍ NÁZEV GetNumsAdam1.GetNumsAdam1.GetNums_AdamMachanic1;GOK otestování pomocí agregační techniky jsem použil následující kód pro případy, kdy na pořadí nezáleží:
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic1(1, 100000000);Mám plán znázorněný na obrázku 5 pro toto provedení.
Obrázek 5:Plán pro funkci dbo.GetNums_AdamMachanic1
Plán je velmi podobný plánu, který jste viděli dříve pro Kamilovo první řešení, a totéž platí pro jeho provedení. Mám následující časové statistiky pro toto provedení:
Čas CPU =36687 ms, uplynulý čas =36952 ms .A samozřejmě nebylo potřeba žádné logické čtení.
Pojďme otestovat funkci s pořadím pomocí techniky přiřazení proměnných:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNums_AdamMachanic1(1, 100000000) ORDER BY n;Získal jsem plán znázorněný na obrázku 6 pro toto provedení.
Obrázek 6:Plán pro funkci dbo.GetNums_AdamMachanic1 s ORDER BY
Plán opět vypadá podobně jako ten, který jste viděli dříve u Kamilova prvního řešení. Nebylo potřeba explicitní řazení, protože funkce byla vytvořena s klauzulí ORDER, ale plán zahrnuje nějakou práci na ověření, že řádky jsou skutečně vráceny v pořadí, jak bylo slíbeno.
Mám následující časové statistiky pro toto provedení:
Čas CPU =55047 ms, uplynulý čas =55498 ms .Ve svém druhém řešení Adam také zkombinoval část CLR a část T-SQL. Zde je Adamův popis logiky, kterou použil ve svém řešení:
„Snažil jsem se vymyslet, jak obejít problém konverzace SQLCLR a také hlavní problém tohoto generátoru čísel v T-SQL, kterým je skutečnost, že nemůžeme jednoduše vytvořit magické řádky.CLR je dobrá odpověď na druhý díl, ale samozřejmě ho brzdí první číslo. Takže jako kompromis jsem vytvořil T-SQL TVF [nazývaný GetNums_AdamMachanic2_8192] napevno zakódovaný s hodnotami 1 až 8192. (Poměrně libovolná volba, ale příliš velká a QO se v ní začíná trochu dusit.) Dále jsem upravil svou funkci CLR [ pojmenované GetNums_AdamMachanic2_8192_base] pro výstup dvou sloupců, "max_base" a "base_add", a nechal vypsat řádky jako:
- max_base, base_add
——————
8191, 1
8192, 8192
8192, 16384
…
8192, 99991552
257, 99999744
Nyní je to jednoduchá smyčka. Výstup CLR je odeslán do T-SQL TVF, který je nastaven tak, aby vracel pouze řádky "max_base" z pevně zakódované sady. A pro každý řádek přidá k hodnotě "base_add", čímž vygeneruje požadovaná čísla. Klíčem je, myslím, to, že můžeme generovat N řádků pouze s jediným logickým křížovým spojením a funkce CLR musí vrátit pouze 1/8192 tolik řádků, takže je dostatečně rychlá, aby fungovala jako základní generátor.“
Logika se zdá docela přímočará.
Zde je kód používaný k definování funkce CLR s názvem GetNums_AdamMachanic2_8192_base:
použití System.Data.SqlTypes;použití System.Collections; public částečná třída GetNumsAdam2{ private struct row { public long max_base; public long base_add; } [Microsoft.SqlServer.Server.SqlFunction( FillRowMethodName ="GetNums_AdamMachanic2_8192_base_fill", TableDefinition ="max_base int, base_add int")] public static IEnumerable GetNums_AdamMachanic_l max. Sqint6 min.In; var max_int =max.Value; var min_group =min_int / 8192; var max_group =max_int / 8192; for (; min_group <=max_group; min_group++) { if (min_int> max_int) výtěžnost; var max_base =8192 - (min_int % 8192); if (min_group ==max_group &&max_int <(((max_int / 8192) + 1) * 8192) - 1) max_base =max_int - min_int + 1; výnos výnos ( new row() { max_base =max_base, base_add =min_int } ); min_int =(min_skupina + 1) * 8192; } } public static void GetNums_AdamMachanic2_8192_base_fill(object o, out long max_base, out long base_add) { var r =(row)o; max_base =r.max_base; base_add =r.base_add; }}; Projekt VS jsem pojmenoval GetNumsAdam2 a umístil do cesty C:\Temp\ jako u ostatních projektů. Zde je kód, který jsem použil k nasazení funkce v databázi testdb:
-- Vytvořit sestavení a funkciDROP FUNKCE, POKUD EXISTUJE dbo.GetNums_AdamMachanic2_8192_base;DROP SESTAVENÍ, POKUD EXISTUJE GetNumsAdam2;GO CREATE ASSEMBLY GetNumsAdam2 Z 'C:\Temp\GetGetNums\UmbinsAmbo\Deums .GetNums_AdamMachanic2_8192_base(@max_base JAKO VELKÉ, @add_base JAKO VELKÉ) TABULKA VRÁCENÍ (max_base BIGINT, base_add BIGINT) OBJEDNÁVKA(base_add) JAKO EXTERNÍ NÁZEV GetNumsAdam2.GetNumsAdams_base_2.GETZde je příklad použití GetNums_AdamMachanic2_8192_base s rozsahem 1 až 100M:
SELECT * FROM dbo.GetNums_AdamMachanic2_8192_base(1, 100000000);Tento kód generuje následující výstup, který je zde uveden ve zkrácené podobě:
max_base base_add-------------------- --------------------8191 18192 81928192 163848192 245768192 32768...8192 999669768192 999751688192 999833608192 99991552257 99999744 (ovlivněných 12208 řádků)Zde je kód s definicí funkce T-SQL GetNums_AdamMachanic2_8192 (zkráceně):
CREATE OR ALTER FUNCTION dbo.GetNums_AdamMachanic2_8192(@max_base AS BIGINT, @add_base AS BIGINT) VRÁTÍ TABLEASRETURN SELECT TOP (@max_base) V.i + @add_base AS val FROM (VALUES (20), (1), (3), (4), ... (8187), (8188), (8189), (8190), (8191) ) AS V(i);GODůležité: Také zde bych měl zdůraznit, že podobně jako to, co jsem řekl o druhém Kamilově řešení, Adam zde předpokládá, že filtr TOP bude extrahovat horní řádky na základě pořadí vzhledu řádků v konstruktoru tabulkových hodnot, což ve skutečnosti není zaručeno. Pokud přidáte klauzuli ORDER BY pro podporu TOP nebo změníte filtr na filtr WHERE, získáte deterministický filtr, který však může zcela změnit výkonnostní profil řešení.
Nakonec je zde nejvzdálenější funkce T-SQL, dbo.GetNums_AdamMachanic2, kterou koncový uživatel volá, aby získal číselnou řadu:
VYTVOŘIT NEBO ZMĚNIT FUNKCI dbo.GetNums_AdamMachanic2(@nízká JAKO BIGINT =1, @vysoká JAKO BIGINT) VRACÍ TABLEASRETURN SELECT Y.val AS n FROM ( SELECT max_base, base_add FROM @dbo.GetNums_8igh)92low AS X CROSS APPLY dbo.GetNums_AdamMachanic2_8192(X.max_base, X.base_add) AS YGOTato funkce používá operátor CROSS APPLY k aplikaci vnitřní funkce T-SQL dbo.GetNums_AdamMachanic2_8192 na řádek vrácený vnitřní funkcí CLR dbo.GetNums_AdamMachanic2_8192_base.
Nejprve otestujme toto řešení pomocí agregační techniky, když na pořadí nezáleží:
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic2(1, 100000000);Získal jsem plán znázorněný na obrázku 7 pro toto provedení.
Obrázek 7:Plán pro funkci dbo.GetNums_AdamMachanic2
Pro tento test mám následující časové statistiky:
SQL Server čas analýzy a kompilace :Čas CPU =313 ms, uplynulý čas =339 ms .
SQL Server doba provedení :Čas CPU =8859 ms, uplynulý čas =8849 ms .Nebyla potřeba žádná logická čtení.
Doba provádění není špatná, ale všimněte si vysoké doby kompilace kvůli použitému konstruktoru velkých hodnot tabulky. Zaplatili byste tak vysokou dobu kompilace bez ohledu na velikost rozsahu, který požadujete, takže to je obzvláště složité při použití funkce s velmi malými rozsahy. A toto řešení je stále pomalejší než ta T-SQL.
Pojďme otestovat funkci s objednávkou:
DECLARE @n JAKO BIGINT; SELECT @n =n FROM dbo.GetNums_AdamMachanic2(1, 100000000) ORDER BY n;Získal jsem plán znázorněný na obrázku 8 pro toto provedení.
Obrázek 8:Plán pro funkci dbo.GetNums_AdamMachanic2 s ORDER BY
Stejně jako v případě Kamilova druhého řešení je v plánu potřeba explicitní řazení, což představuje značnou výkonnostní penalizaci. Zde jsou časové statistiky, které jsem získal pro tento test:
Doba provedení:CPU čas =54891 ms, uplynulý čas =60981 ms .Navíc je tu stále vysoká penalizace doby kompilace, přibližně třetina sekundy.
Závěr
Bylo zajímavé testovat řešení založená na CLR pro výzvu číselné řady, protože mnoho lidí zpočátku předpokládalo, že nejvýkonnějším řešením bude pravděpodobně řešení založené na CLR. Kamil a Adam použili podobné přístupy, přičemž první pokus použili jednoduchou smyčku, která inkrementuje čítač a poskytne řádek s další hodnotou na iteraci, a sofistikovanější druhý pokus, který kombinuje části CLR a T-SQL. Osobně mi není příjemné, že v Kamilově i Adamově druhém řešení spoléhali na nedeterministický TOP filtr, a když jsem jej při vlastním testování převedl na deterministický, mělo to nepříznivý dopad na výkon řešení. . Ať tak či onak, naše dvě řešení T-SQL fungují lépe než ta CLR a nevedou k explicitnímu řazení v plánu, když potřebujete seřadit řádky. Takže opravdu nevidím hodnotu v pokračování cesty CLR. Obrázek 9 obsahuje shrnutí výkonu řešení, která jsem představil v tomto článku.
Obrázek 9:Časové srovnání výkonu
Pro mě by měl být GetNums_AlanCharlieItzikBatch řešením volby, když nevyžadujete absolutně žádnou I/O stopu, a GetNums_SQKWiki by měla být preferována, když vám nevadí malá I/O stopa. Samozřejmě můžeme vždy doufat, že Microsoft jednoho dne přidá tento kriticky užitečný nástroj jako vestavěný, a doufejme, že pokud/až tak učiní, bude to výkonné řešení, které podporuje dávkové zpracování a paralelismus. Nezapomeňte tedy hlasovat pro tuto žádost o vylepšení funkcí a možná dokonce přidejte své komentáře, proč je to pro vás důležité.
Práce na této sérii mě opravdu bavila. Během procesu jsem se hodně naučil a doufám, že vy také.