Tento blog je druhou částí Implementace nastavení více datových center pro PostgreSQL. V tomto úderu si ukážeme, jak nasadit PostgreSQL v tomto typu prostředí a jak převzít selhání v případě selhání hlavního serveru pomocí funkce automatického obnovení ClusterControl.
V tuto chvíli budeme předpokládat, že máte konektivitu mezi datovými centry (jak jsme viděli v první části tohoto blogu) a máte potřebné servery pro tento úkol (jak jsme také zmínili v předchozí část).
Nasazení klastru PostgreSQL
Pro tento úkol použijeme ClusterControl, takže budeme předpokládat, že jej máte nainstalovaný (může být nainstalován na stejném serveru Load Balancer, ale pokud můžete použít jiný, ještě lepší).
Přejděte na svůj server ClusterControl a vyberte možnost ‚Deploy‘. Pokud již máte spuštěnou instanci PostgreSQL, musíte místo toho vybrat ‚Importovat existující server/databázi‘.
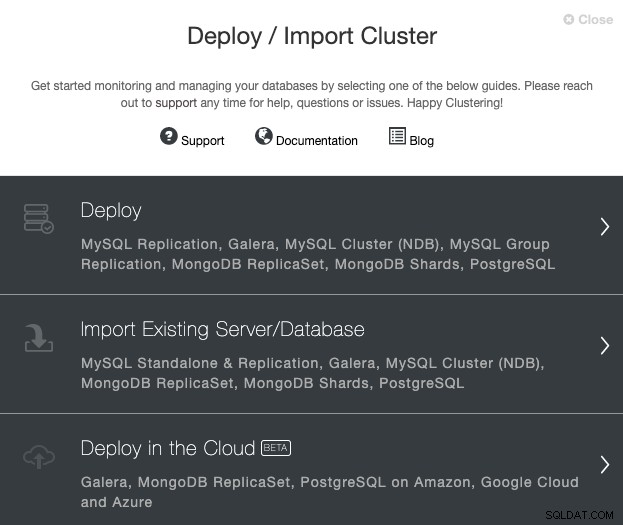
Při výběru PostgreSQL musíte zadat uživatele, klíč nebo heslo a port na připojte se pomocí SSH k našim hostitelům PostgreSQL. Potřebujete také název svého nového clusteru a pokud chcete, aby ClusterControl nainstaloval odpovídající software a konfigurace za vás.
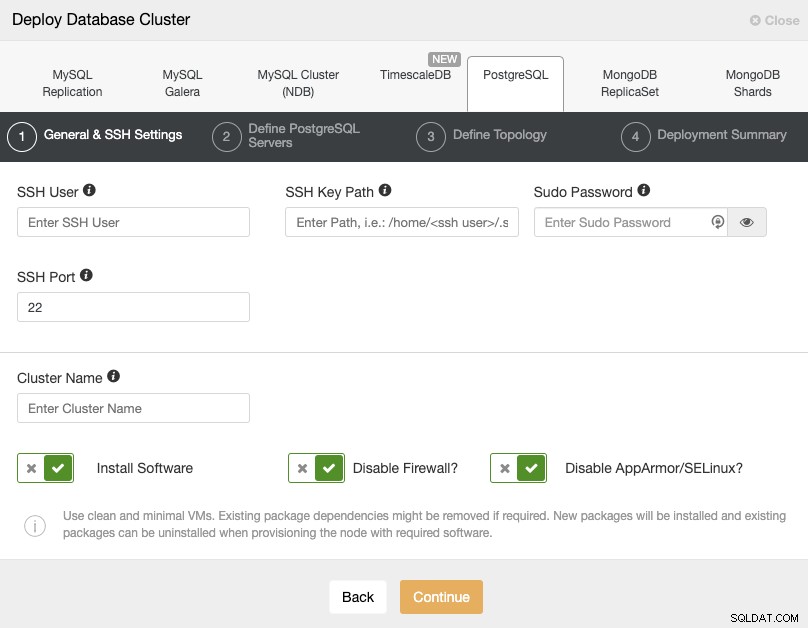
Zde zkontrolujte uživatelské požadavky ClusterControl pro tento úkol, ale pokud jste postupovali V předchozím blogu byste zde měli použít „vzdáleného“ uživatele a správný port SSH (jak jsme zmínili, doporučuje se použít jiný, pokud k němu místo VPN používáte veřejnou IP adresu).
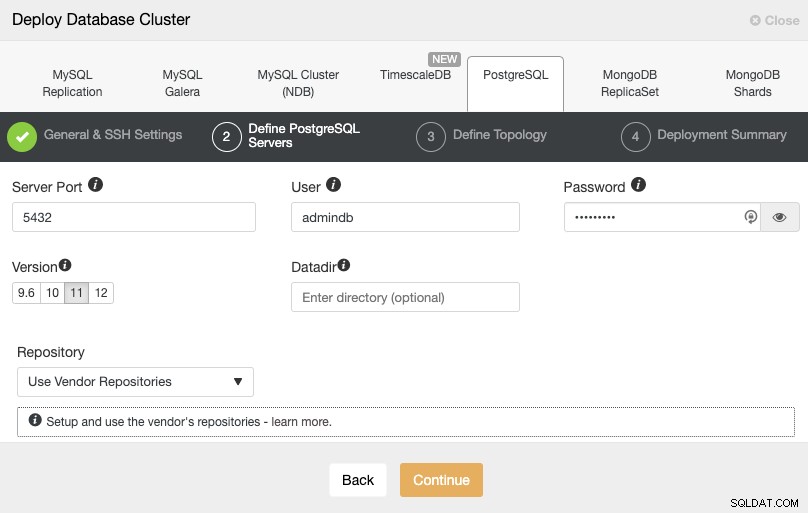
Po nastavení přístupových informací SSH musíte definovat uživatele databáze, verze a datadir (volitelné). Můžete také určit, které úložiště chcete použít. V dalším kroku musíte přidat své servery do clusteru, který se chystáte vytvořit.
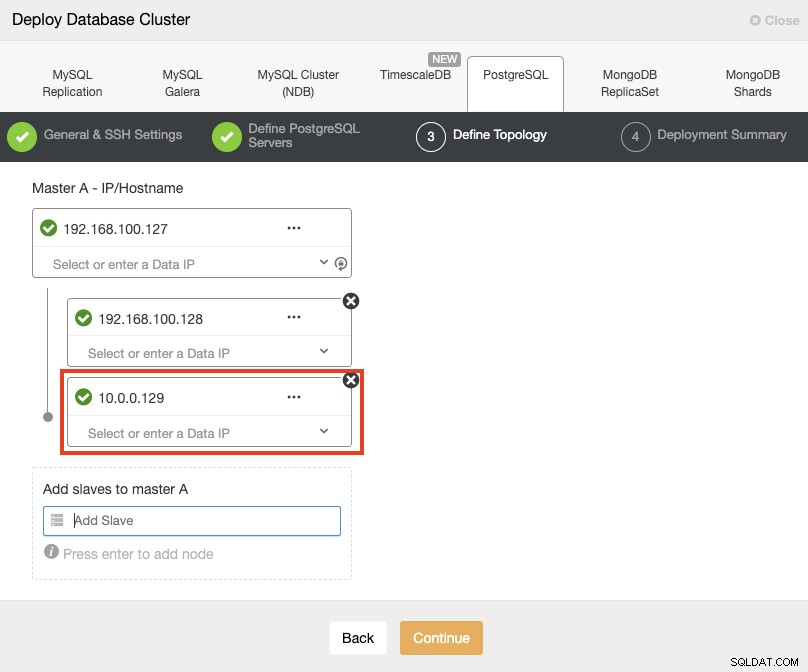
Při přidávání serverů můžete zadat IP nebo název hostitele. V této části použijete veřejné IP adresy svých serverů, a jak vidíte v červeném poli, používám pro druhý pohotovostní uzel jinou síť. ClusterControl nemá žádná omezení ohledně sítě, která má být použita. Jediným požadavkem je mít SSH přístup k uzlu.
Podle našeho předchozího příkladu by tyto adresy IP měly být:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)V posledním kroku si můžete vybrat, zda bude vaše replikace synchronní nebo asynchronní.
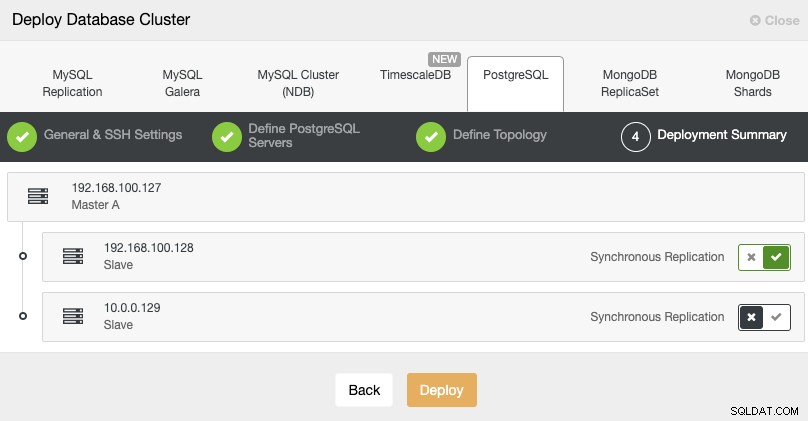
V tomto případě je důležité použít asynchronní replikaci pro váš vzdálený uzel , pokud ne, váš cluster může být ovlivněn latencí nebo problémy se sítí.
Stav vytváření nového clusteru můžete sledovat na monitoru aktivity ClusterControl.
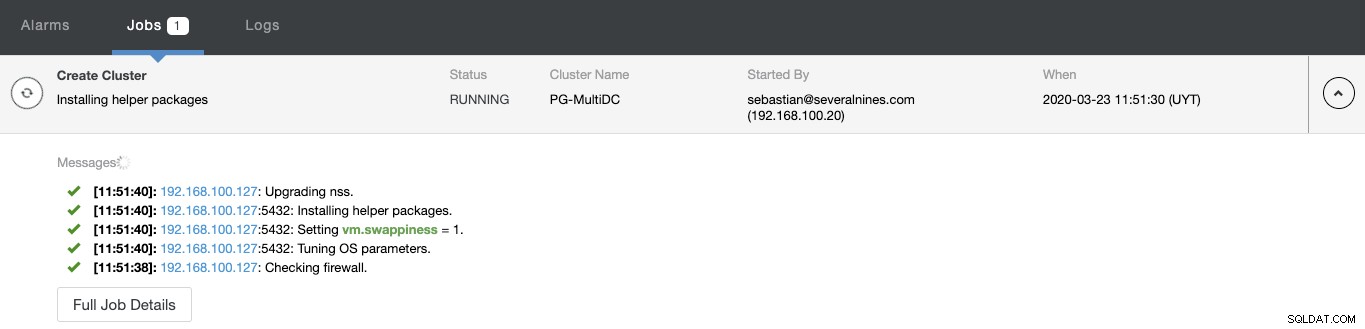
Po dokončení úlohy můžete svůj nový cluster PostgreSQL vidět v hlavní obrazovka ClusterControl.

Přidání nástroje pro vyrovnávání zatížení PostgreSQL (HAProxy)
Jakmile budete mít svůj cluster vytvořený, můžete na něm provádět několik úkolů, jako je přidání nástroje pro vyrovnávání zatížení (HAProxy) nebo nové repliky.
Abychom následovali náš předchozí příklad, přidejte nástroj pro vyrovnávání zatížení, který vám, jak jsme již zmínili, pomůže spravovat vaše prostředí HA. Chcete-li to provést, přejděte do ClusterControl -> Vybrat klastr PostgreSQL -> Akce klastru -> Přidat Load Balancer.
Sem musíte přidat informace, které ClusterControl použije k instalaci a konfiguraci HAProxy load balancer. Tento Load Balancer lze nainstalovat na stejný server ClusterControl, ale pokud můžete použít jiný, ještě lepší.
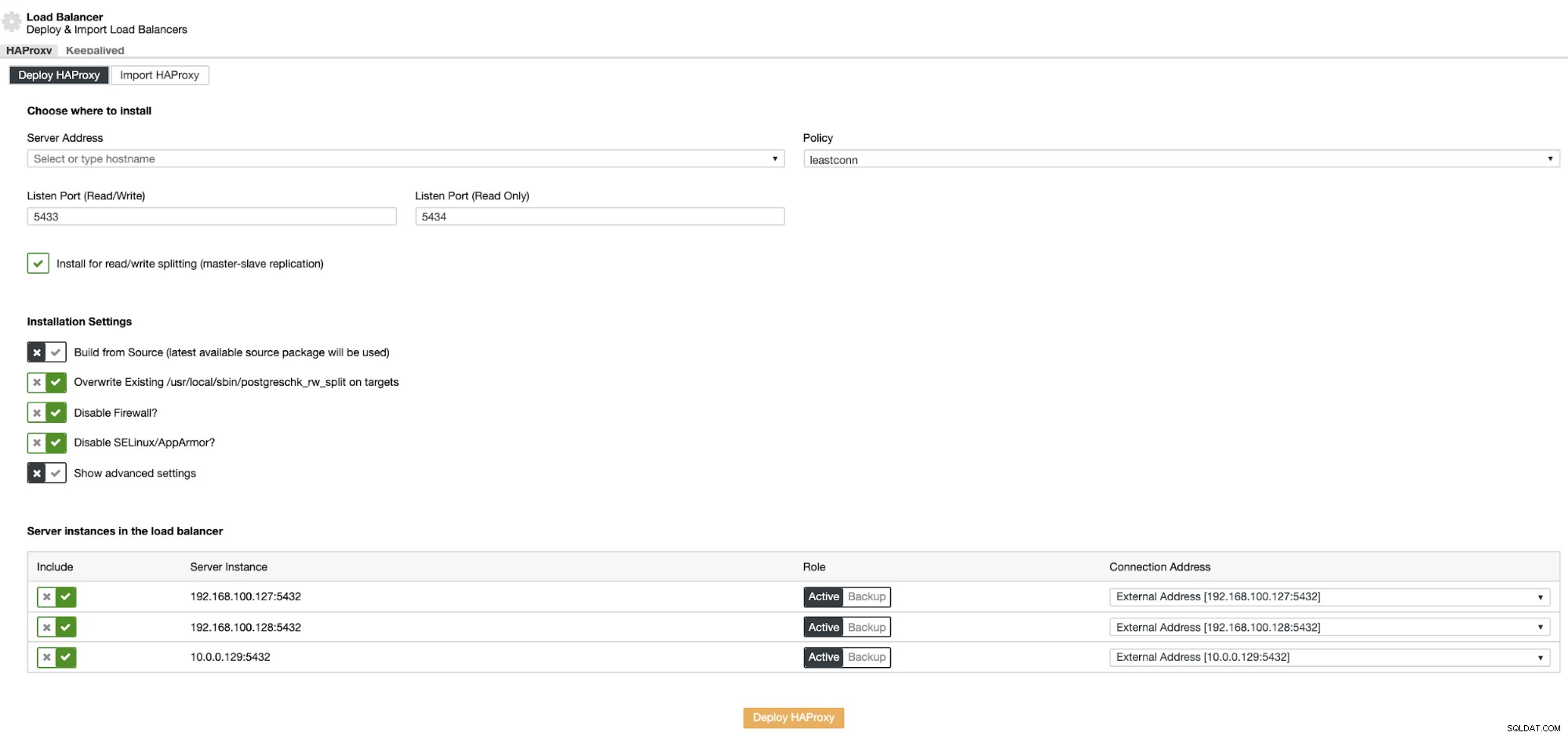
Informace, které je třeba uvést:
Akce:Nasazení nebo import.
Adresa serveru:IP adresa vašeho HAProxy serveru (může to být stejná IP adresa ClusterControl).
Port pro naslouchání (čtení/zápis):Port pro režim čtení/zápis.
Port pro naslouchání (pouze pro čtení):Port pro režim pouze pro čtení.
Zásady:Může to být:
- leastconn:Server s nejnižším počtem připojení přijme připojení.
- roundrobin:Každý server se používá v tazích podle své váhy.
- zdroj:Zdrojová IP adresa je hašována a vydělena celkovou váhou běžících serverů, aby se určilo, který server obdrží požadavek.
Instalovat pro rozdělení čtení/zápisu:Pro replikaci master-slave.
Sestavit ze zdroje:Můžete zvolit Instalovat ze správce balíčků nebo sestavit ze zdroje.
A musíte vybrat, které servery chcete přidat do konfigurace HAProxy.
Můžete také nakonfigurovat pokročilá nastavení, jako je uživatel správce, název backendu, časové limity a další.
Po dokončení konfigurace a potvrzení nasazení můžete sledovat průběh v části Aktivita v uživatelském rozhraní ClusterControl.
A až to skončí, můžete přejít na ClusterControl -> Nodes -> HAProxy a zkontrolujte aktuální stav.
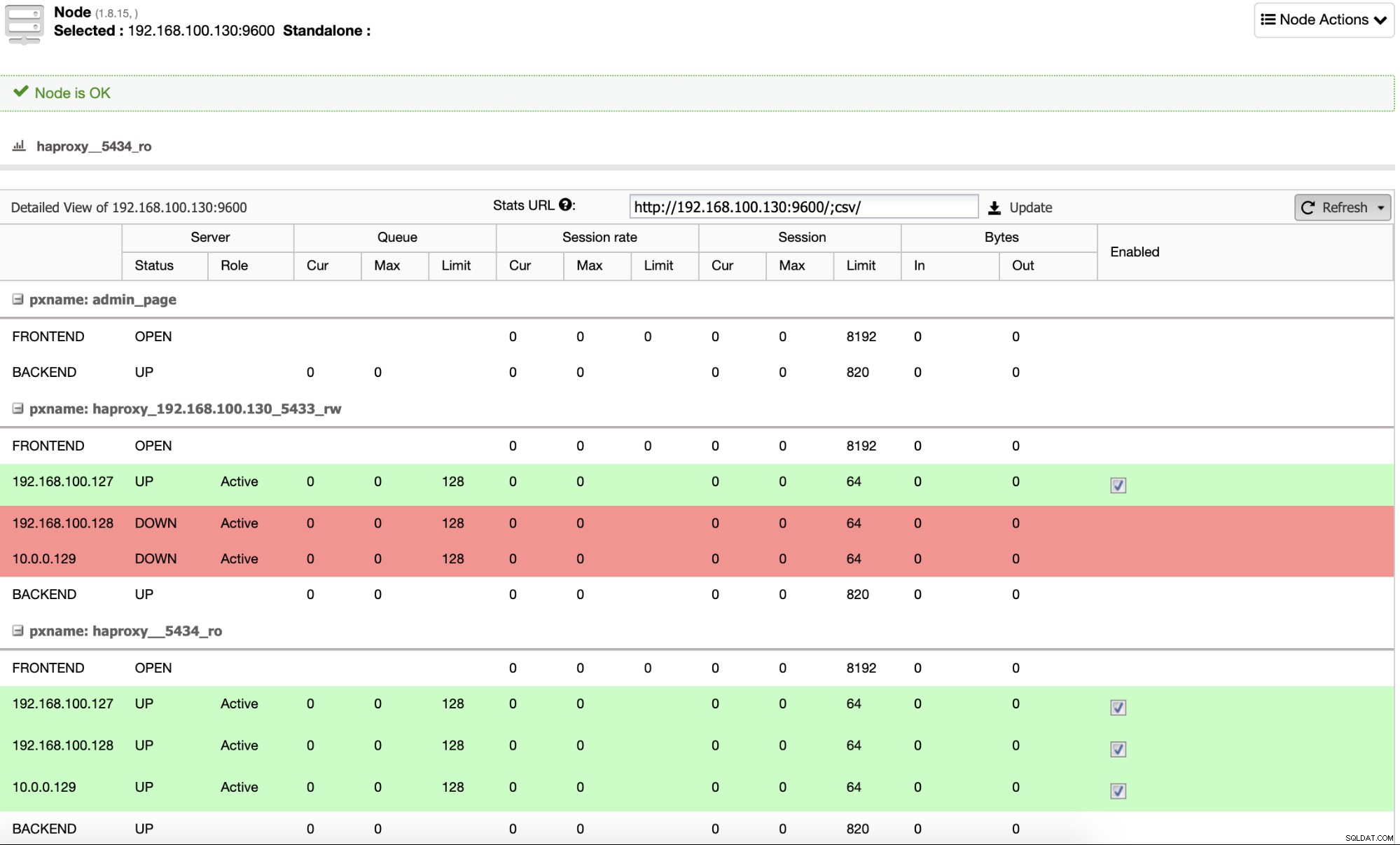
Ve výchozím nastavení nakonfiguruje ClusterControl HAProxy se dvěma různými porty, jedním pro čtení- Zápis, který bude použit pro aplikaci nebo uživatele k zápisu (a čtení) dat, a další pro Read-Only, který bude použit pro vyrovnávání čtecího provozu mezi všemi uzly. Na portu Read-Write je povolen pouze hlavní uzel a v případě selhání hlavního uzlu ClusterControl povýší nejpokročilejší podřízený na hlavní a překonfiguruje tento port tak, aby deaktivoval starý hlavní uzel a povolil nový. Tímto způsobem může vaše aplikace stále fungovat v případě selhání hlavní databáze, protože provoz je přesměrován Load Balancerem na správný uzel.
Své HAProxy servery můžete také sledovat v sekci Dashboard.
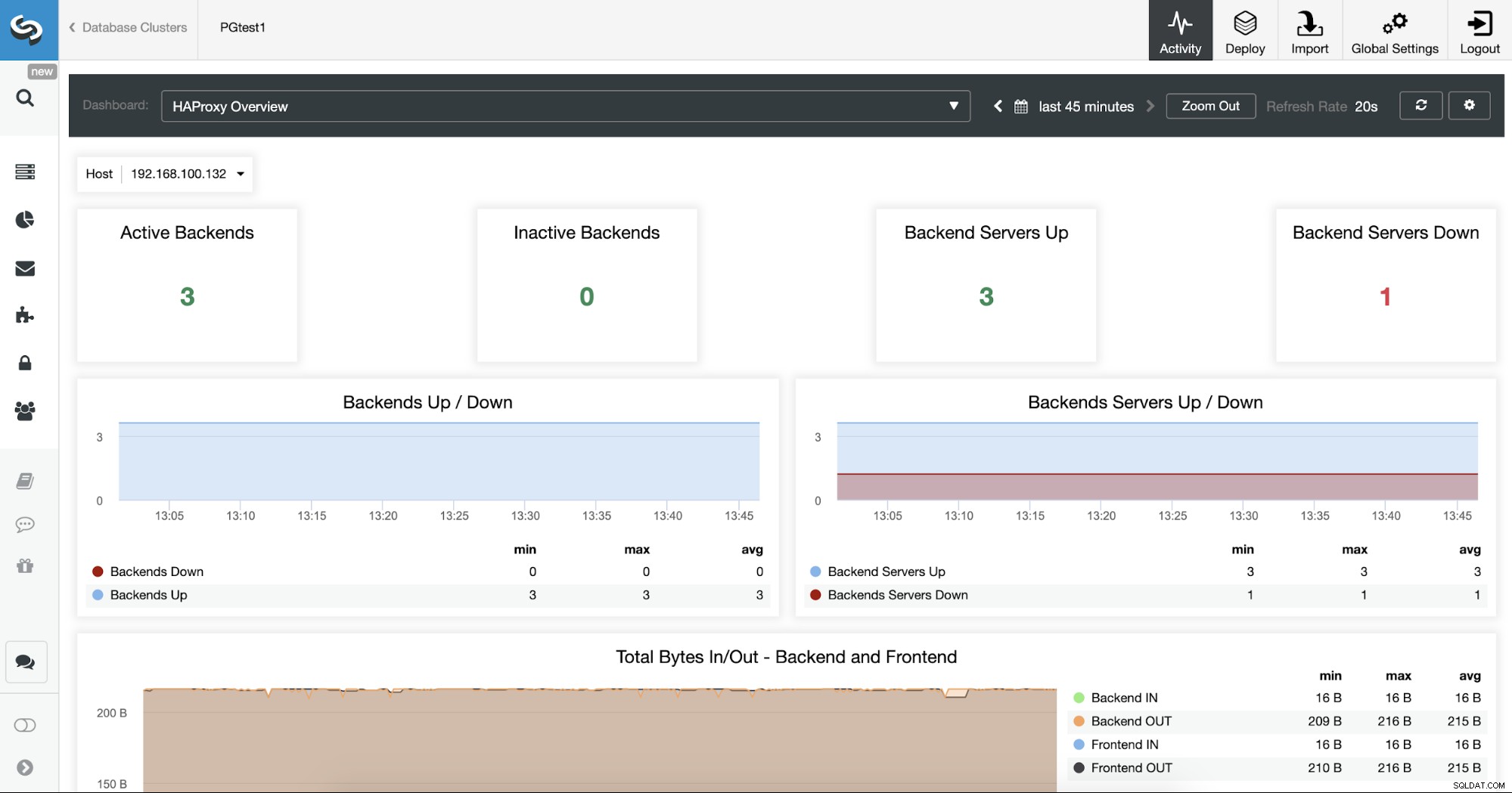
Nyní můžete vylepšit svůj návrh HA přidáním nového uzlu HAProxy do vzdáleného datového centra a konfigurace služby Keepalived mezi nimi. Keepalived vám umožní používat virtuální IP adresu, která je přiřazena aktivnímu uzlu Load Balancer. Pokud tento uzel selže, bude tato virtuální IP migrována do sekundárního uzlu HAProxy, takže když budete mít tuto IP nakonfigurovanou ve vaší aplikaci, umožníte, aby vše fungovalo v případě problému s Load Balancer.
Veškerou tuto konfiguraci lze provést pomocí ClusterControl.
Závěr
Sledováním tohoto dvoudílného blogu můžete implementovat nastavení více datových center pro PostgreSQL s vysokou dostupností a konektivitou SSH mezi datovým centrem, abyste se vyhnuli složitosti konfigurace VPN.
Použitím asynchronní replikace pro vzdálený uzel se vyhnete jakémukoli problému souvisejícímu s latencí a výkonem sítě a pomocí ClusterControl budete mít automatické (nebo manuální) převzetí služeb při selhání v případě selhání (mimo jiné několik funkcí). Toto by mohl být nejjednodušší způsob, jak dosáhnout této topologie, a doufáme, že to bude pro vás užitečné.