Ve svém předchozím článku jsem zahájil novou sérii o západkách tím, že jsem vysvětlil, co to je, proč jsou potřeba a mechaniku, jak fungují, a důrazně doporučuji, abyste si tento článek přečetli před tímto. V tomto článku budu diskutovat o západce FGCB_ADD_REMOVE a ukážu, jak může být úzkým hrdlem.
Co je to západka FGCB_ADD_REMOVE?
Většina názvů tříd latch je svázána přímo s datovou strukturou, kterou chrání. Západka FGCB_ADD_REMOVE chrání datovou strukturu nazvanou FGCB nebo řídicí blok skupiny souborů a pro každou online skupinu souborů každé online databáze v instanci SQL Server bude existovat jedna z těchto západek. Kdykoli je soubor ve skupině souborů přidán, zahozen, zvětšen nebo zmenšen, musí být latch získán v režimu EX a při zjišťování dalšího souboru, ze kterého se má alokovat, musí být latch získán v režimu SH, aby se zabránilo jakýmkoli změnám skupiny souborů. (Nezapomeňte, že alokace rozsahu pro skupinu souborů se provádějí opakovaně prostřednictvím souborů ve skupině souborů a také vezměte v úvahu proporcionální vyplnění , který zde vysvětluji.)
Jak se západka stane úzkým hrdlem?
Nejběžnější scénář, kdy se tato západka stane úzkým hrdlem, je následující:
- Existuje jednosouborová databáze, takže všechna přidělení musí pocházet z jednoho datového souboru
- Nastavení automatického růstu pro soubor je nastaveno na velmi malé (pamatujte, že před SQL Server 2016 bylo výchozí nastavení automatického růstu pro datové soubory 1 MB!)
- Existuje mnoho souběžných operací vyžadujících přidělení prostoru (např. neustálé zatížení vkládáním z mnoha klientských připojení)
V tomto případě, i když existuje pouze jeden soubor, vlákno vyžadující alokaci stále musí získat latch FGCB_ADD_REMOVE v režimu SH. Poté se pokusí alokovat z jednoho datového souboru, uvědomí si, že v něm není místo, a poté získá západku v režimu EX, aby pak mohl soubor rozšířit.
Představme si, že se osm vláken běžících na osmi samostatných plánovačích pokouší alokovat současně a všechna si uvědomují, že v souboru není místo, takže jej potřebují rozšířit. Každý se pokusí získat západku v režimu EX. Pouze jeden z nich jej bude moci získat a bude pokračovat v rozšiřování souboru a ostatní budou muset čekat s typem čekání LATCH_EX a popisem prostředku FGCB_ADD_REMOVE plus adresou paměti zámku.
Sedm čekajících vláken je v čekací frontě FIFO (first-in-first-out). Když vlákno provádějící růst souboru dokončí, uvolní západku a udělí ji prvnímu čekajícímu vláknu. Tento nový majitel západky jde vypěstovat soubor a zjistí, že už byl vyrostlý a není co dělat. Uvolní tedy západku a udělí ji dalšímu čekajícímu vláknu. A tak dále.
Všech sedm čekajících vláken čekalo na latch v režimu EX, ale po udělení latch nakonec neudělalo nic, takže všech sedm vláken v podstatě promarnilo uplynulý čas, přičemž množství promarněného času se u každého vlákna o něco dále zvyšuje. byla to fronta FIFO.
Zobrazení úzkého místa
Nyní vám ukážu přesný scénář výše pomocí rozšířených událostí. Vytvořil jsem jednosouborovou databázi s malým nastavením automatického růstu a stovkami souběžných připojení pouhým vkládáním dat do tabulky.
Mohu použít následující rozšířenou relaci události, abych viděl, co se děje:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Relace sleduje, když vlákno vstoupí do čekací fronty latch, když frontu opustí (tj. když je mu uděleno latch) a když dojde k nárůstu datového souboru. Použití sledování kauzality znamená, že můžeme vidět časovou osu akcí každého vlákna.
Pomocí SQL Server Management Studio mohu vybrat možnost Sledovat živá data pro relaci rozšířené události a zobrazit veškerou aktivitu rozšířené události. Chcete-li udělat totéž, v okně Živá data klikněte pravým tlačítkem na jeden z názvů sloupců v horní části a změňte vybrané sloupce tak, aby byly takto:
Nechal jsem pracovní zátěž několik minut běžet, abych dosáhl ustáleného stavu, a pak jsem viděl dokonalý příklad scénáře, který jsem popsal výše:
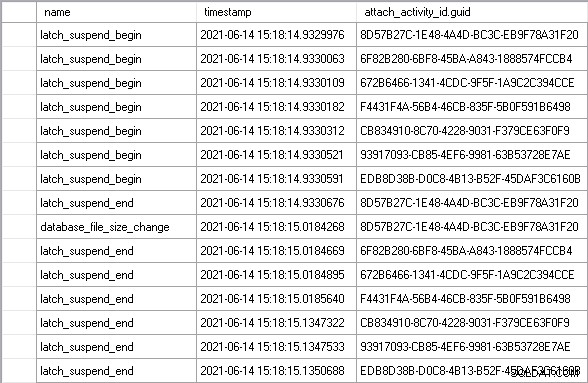
Pomocí attach_activity_id.guid hodnoty k identifikaci různých vláken, můžeme vidět, že sedm vláken začne čekat na latch během 61,5 mikrosekund. Vlákno s hodnotou GUID začínající 8D57 získá latch v režimu EX (latch_suspend_end událost) a poté soubor okamžitě zvětší (database_file_size_change událost). Vlákno 8D57 poté uvolní západku a udělí ji v režimu EX vláknu 6F82, které čekalo 85 milisekund. Nemá co dělat, takže uděluje západku vláknu 672B. A tak dále, dokud vláknu EDB8 nebude udělena závora, po čekání 202 milisekund.
Celkem šest vláken, která čekala bez důvodu, čekalo téměř 1 sekundu. Část této doby je doba čekání na signál, kde i když bylo vláknu uděleno latch, stále se musí posunout na začátek spustitelné fronty plánovače, než se dostane do procesoru a spustí kód. Možná byste řekli, že to není férové měřítko času stráveného čekáním na západku, ale je to tak, protože doba čekání na signál by nevznikla, kdyby vlákno nemuselo čekat.
Kromě toho si můžete myslet, že zpoždění 200 milisekund není tolik, ale vše závisí na dohodách o úrovni služeb pro danou pracovní zátěž. Máme několik velkoobjemových klientů, kde spuštění dávky trvá déle než 200 milisekund, není to v produkčním systému povoleno!
Shrnutí
Pokud na svém serveru sledujete čekání a všimnete si, že LATCH_EX je jedním z nejčastějších čekání, můžete použít kód v tomto příspěvku, abyste zjistili, zda FGCB_ADD_REMOVE není jedním z viníků.
Nejjednodušší způsob, jak se ujistit, že vaše pracovní zatížení nenaráží na úzké hrdlo FGCB_ADD_REMOVE, je ujistit se, že neexistují žádná nastavení automatického růstu datových souborů, která jsou nakonfigurována pomocí výchozích nastavení před SQL Server 2016. V sys.master_files zobrazení, výchozí 1 MB se zobrazí jako datový soubor (type_desc sloupec nastavený na ŘÁDKY) s hodnotou is_percent_growth sloupec nastaven na 0 a sloupec růstu nastaven na 128.
Poskytování doporučení, jak by měl být autogrow nastaven, je úplně jiná diskuse, ale nyní víte o potenciálním dopadu na výkon, který by mohl mít neměnnost výchozích hodnot v dřívějších verzích.