Úvod
Zjistit, jaký druh databázové infrastruktury potřebujete, aby odpovídal výkonu, spolehlivosti a požadavkům na škálování vašich aplikací, může být obtížný úkol. Volby, které provedete pro topologii databáze, mohou ovlivnit, jak celý zásobník aplikací reaguje na různé typy použití a jaké scénáře selhání může zohlednit. Z tohoto důvodu je důležité porozumět svým možnostem a učinit informované rozhodnutí, které bude v souladu s vašimi cíli.
Existuje mnoho různých způsobů, jak přejít od jediné databáze, která zpracovává všechny potřeby vaší infrastruktury, ke složitějším systémům. Spolu s tím je třeba zvážit mnoho kompromisů.
V této příručce představíme některé z nejběžnějších vzorů pro infrastrukturu relačních databází a způsob, jakým jsou v souladu s různými vzory použití. Projdeme si výhody jednotlivých konfigurací a také některé nedostatky, se kterými je třeba počítat. Budeme také mluvit o dopadu různých rozhodnutí na celkovou složitost vašich operací. Jakmile skončíte, měli byste být schopni se lépe rozhodnout, jaké návrhy nejlépe vyhovují vašim aktuálním potřebám a se kterými možnostmi budete chtít experimentovat, když se vaše potřeby budou měnit.
Svislé měřítko
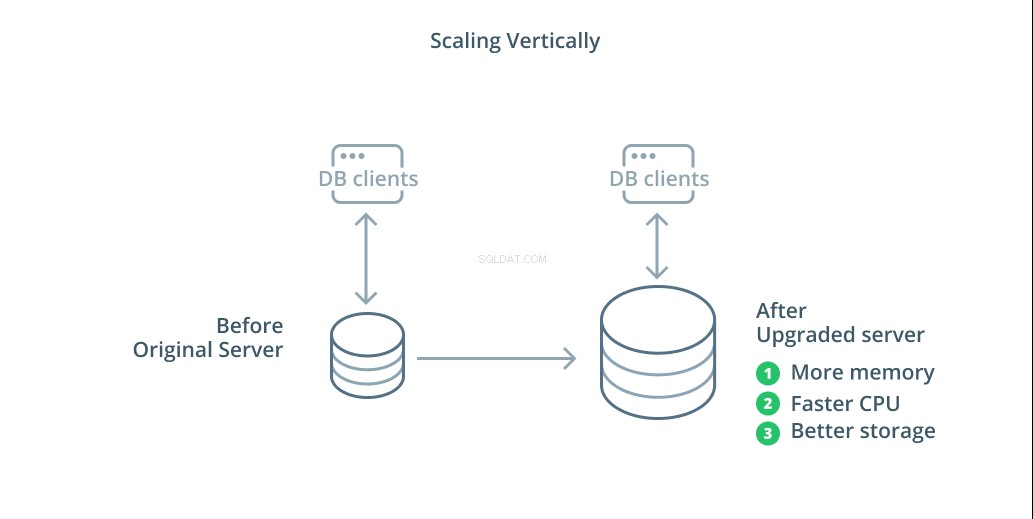
Nejjednodušším způsobem škálování databázového systému je vertikální škálování. Svislé měřítko , nazývané také zvětšení , znamená přidání kapacity serveru, který spravuje vaši databázi. Zvýšením výpočetního výkonu, alokace paměti nebo úložné kapacity můžete zvýšit výkon a objem, který databázový systém zvládne, aniž by se zvýšila složitost systému jako celku.
Obecně platí, že škálování databáze je dobrým prvním krokem, protože zvyšuje možnosti databáze, aniž by to ovlivnilo topologii vaší infrastruktury. Škálování je také obvykle poměrně jednoduché, protože stroj s větší kapacitou může být konfigurován jako sledovač replikace, dokud není synchronizován, a poté může být spuštěno převzetí služeb při selhání, aby se z něj stal nový primární server.
Zvyšování má však svá omezení, protože množství zdrojů, které lze rozumně přidělit jednomu počítači, je omezené. Představuje také jediný bod selhání, pokud nejsou nakonfigurováni žádní následovníci replikace, aby převzali řízení v případě problémů. Tyto obavy řeší některé další možnosti škálování.
Oddělení odpovědnosti za příkazový dotaz (CQRS) a repliky pouze pro čtení
Dalším primárním způsobem škálování vaší databázové infrastruktury je škálování. Rozšíření znamená, že místo zvýšení kapacity jednoho serveru zvýšíte počet serverů vyhrazených pro obsluhu konkrétní potřeby. Takže přidáte kapacitu přidáním dalších strojů do vaší infrastruktury.
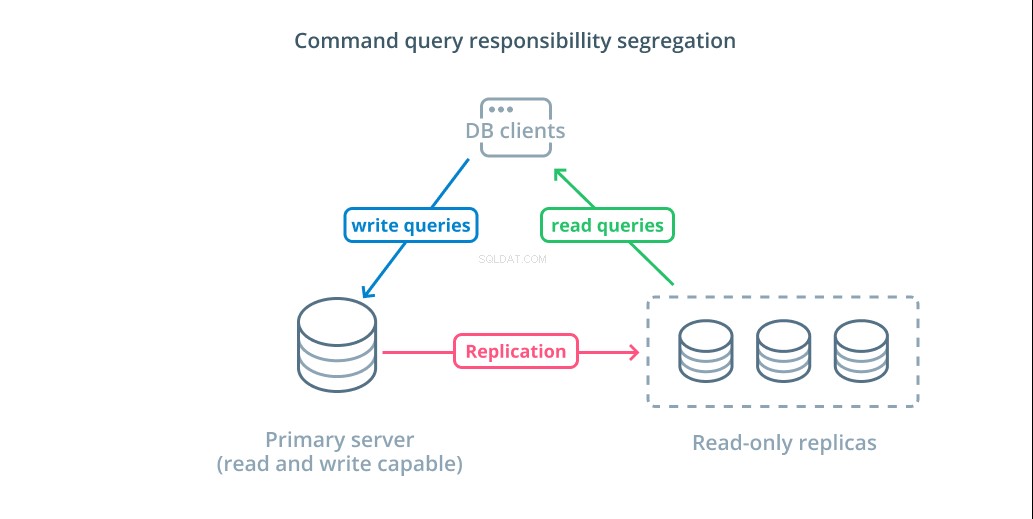
Oddělení odpovědnosti za příkazový dotaz (CQRS) je termín používaný k popisu přidávání logiky k oddělení dotazů, které mutují data (dotazy pro zápis) od těch, které ne (dotazy pro čtení). To vám umožňuje směrovat tyto různé kategorie požadavků na různé hostitele, abyste pomohli distribuovat zátěž.
Nejzákladnější infrastrukturou pro využití tohoto návrhu je primární server, který může přijímat dotazy pro čtení a zápis v kombinaci s jedním nebo více replikovanými servery následujícími po primárním serveru, který může přijímat dotazy pro čtení. Tento návrh je vhodný pro vzory používání aplikací, které vyžadují velké množství čtení, protože operace čtení může zpracovávat kterýkoli z databázových serverů.
Tento systém navíc poskytuje vaší architektuře určitou redundanci, protože systém bude stále fungovat, pokud některý ze serverů selže. Pokud následovník selže, požadavky na čtení mohou být směrovány na jiné servery. Pokud dojde k výpadku primárního serveru, může být jeden ze sledujících replik povýšen na přijímání dotazů na zápis.
Multiprimární replikace
I když vám používání CQRS s replikami pouze pro čtení pomáhá řešit vyšší počet požadavků na čtení, výrazně neovlivňuje výkon vaší infrastruktury při zápisu. Chcete-li zvýšit počet zápisů, které vaše architektura zvládne, musíte zvážit, zda můžete přijmout návrh multiprimární replikace.
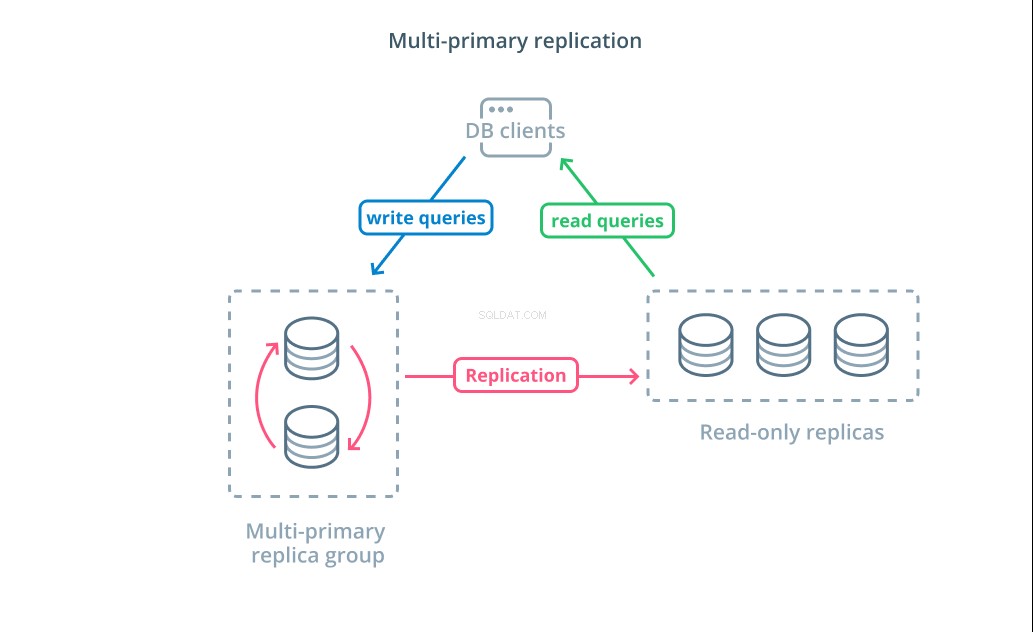
Multiprimární replikace je forma replikace, kde více serverů může přijímat požadavky na zápis. Některé systémy jsou nakonfigurovány tak, aby požadavky na zápis mohl zpracovávat jakýkoli server, zatímco jiné jsou navrženy tak, že základní skupina primárních serverů zpracovává zápisy s větším počtem sledujících pouze pro čtení. Bez ohledu na implementaci zvyšuje multiprimární replikace počet serverů, které jsou odpovědné za zápisové dotazy.
I když tento design zní na začátku ideálně, existují některé velké problémy, které brání tomu, aby se stal široce přijatým vzorem. Přestože požadavky na zápis může zpracovávat více serverů, stále se musí koordinovat, aby replikovaly změny mezi svými servery a vyřešily konflikty ve změnách dat. To může vést buď k dlouhé době odezvy při vyjednávání konfliktů, nebo k možnosti nekonzistence dat.
Každý systém volí svůj vlastní přístup k řešení těchto problémů. Toto je ukázka teorému CAP — prohlášení popisující souhru mezi konzistencí, dostupností a tolerancí rozdělení v distribuovaných systémech – v akci. Některé systémy nabízejí slabší záruky konzistence pro zachování dostupnosti, zatímco jiné databáze odmítají přijmout změny, pokud jejich kolegové nemohou koordinovat transakci v době zápisu. Výběr přístupu, který nejlépe vyhovuje vašim potřebám, je důležitým faktorem při rozhodování mezi různými implementacemi.
Ukládání dotazů do mezipaměti
I když použití replik jen pro čtení představuje způsob, jak zvýšit dostupné databáze, které mohou reagovat na požadavky čtení, nezlepšuje výkon základních dotazů u složitých operací čtení. Stále se očekává, že jeden ze serverů provede operaci čtení pokaždé, když je vznesen požadavek, i když jsou výsledky identické s předchozím vyhledáváním.
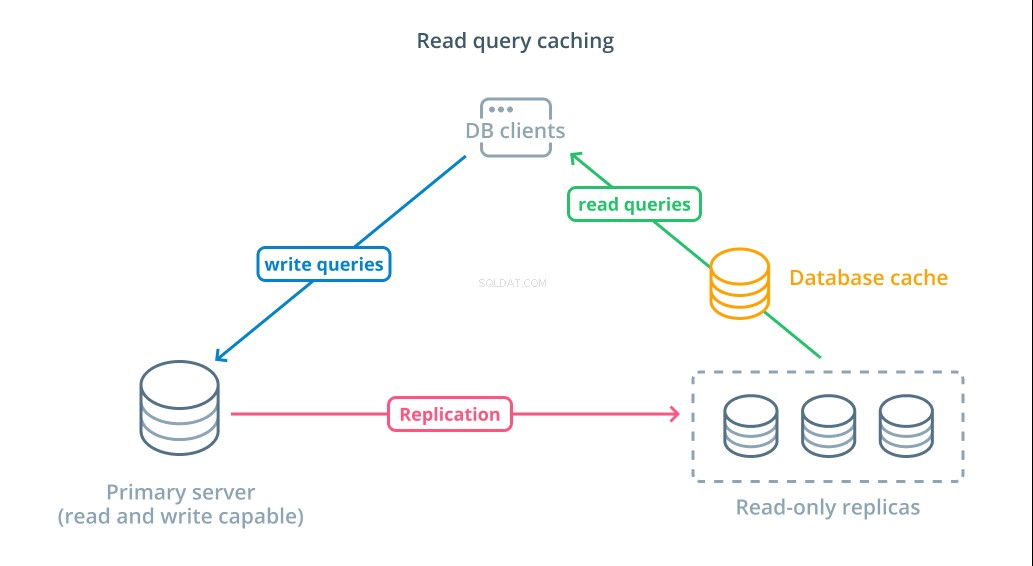
Chcete-li zkrátit dobu odezvy, ukládání dotazu do mezipaměti vrstvu lze zavést. Přidání mezipaměti mezi vaše databázové klienty a samotné databáze může výrazně zkrátit dobu dotazování pro běžné požadavky. Aplikace může požadovat výsledky čtení z mezipaměti a přijímat je téměř okamžitě, pokud jsou k dispozici. V případech, kdy výsledky nejsou nalezeny v mezipaměti, jsou načteny ze samotné databáze a přidány do mezipaměti pro příště.
Konfigurace ukládání do mezipaměti tímto způsobem je neuvěřitelně efektivní pro scénáře, kde se data pravděpodobně nezmění při každém požadavku. Je to užitečné zejména pro drahé čtecí dotazy, které konzultují více tabulek a zahrnují složité operace spojení. Tyto výsledky lze provést jednou a poté je uložit pro budoucí dotazy.
V případech, kdy se data mění rychleji, mezipaměť pro čtení nemusí zdaleka tolik pomoci. V závislosti na nakonfigurovaném chování mezipaměti riskují, že v těchto situacích vrátí zastaralá data, a měly by být implementovány promyšlené strategie zrušení platnosti mezipaměti, aby se zastaralá data při změně odstranila z mezipaměti.
Sdílení dat
Dosud návrhy, o kterých jsme diskutovali, měly segmentované databázové komponenty podle toho, zda reagují na požadavky zápisu či nikoli. Dalším způsobem rozdělení odpovědnosti je však rozdělení skutečného souboru dat na více částí.
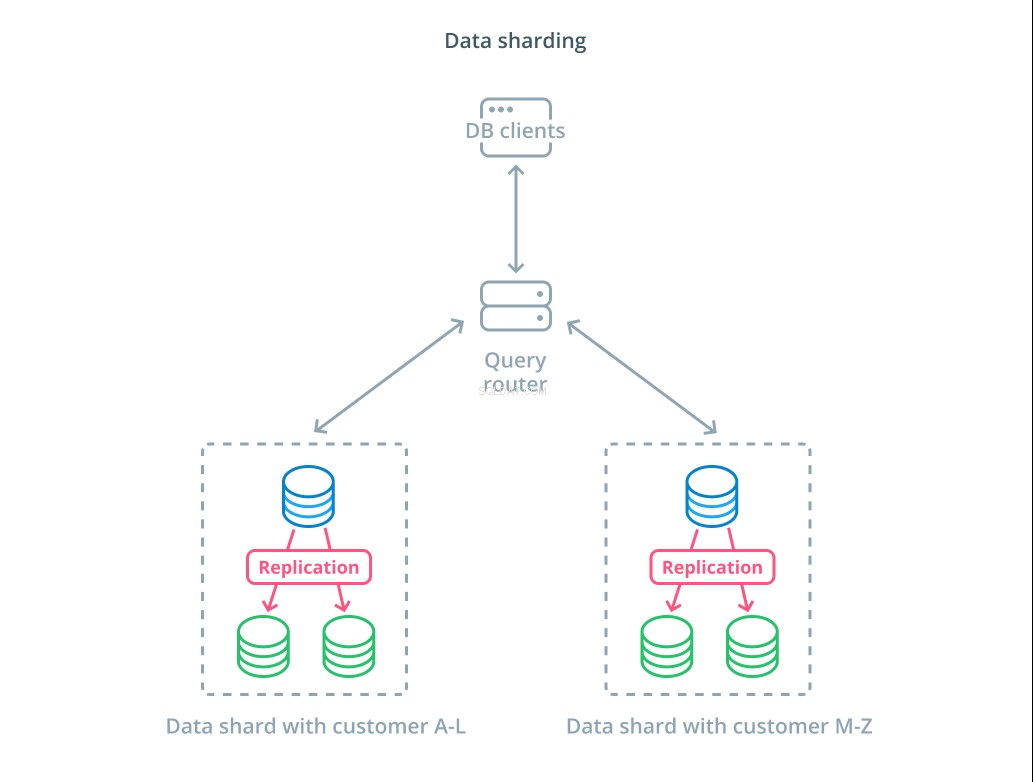
Sharding je proces rozdělení logické datové sady na menší podmnožiny za účelem distribuce jejich správy na různé stroje. Každý databázový server zpracovává pouze část dat a je zaveden mechanik směrování, který rozumí, které stroje jsou zodpovědné za jaké části dat.
Sharding se obvykle provádí ve scénářích, kde je operace s celou datovou sadou najednou zbytečná nebo neobvyklá. Soubor dat je segmentován na základě hodnoty každého záznamu pro konkrétní klíč, známý jako sharding key . Můžete například ručně skartovat data na základě polohy zákazníků. Můžete také automaticky fragmentovat pomocí hashovacího algoritmu, abyste určili, které uzly by měly zpracovávat které klíče. To může vašemu systému pomoci vyhnout se nevyvážené distribuci v případech, kdy je klíčový prostor fragmentu rozmístěn nerovnoměrně.
Sharding vnáší do datových systémů poměrně dost složitosti a není vhodný pro všechny scénáře. Operace, které interagují s více fragmenty, utrpí značné snížení výkonu, protože získávají výsledky od každého člena. K tomu může dojít u agregovaných dotazů nebo v případě, že konkrétní zlomkový klíč není znám předem. Kromě toho může nerovnoměrná alokace fragmentů také způsobit neefektivitu a úzká místa, která je třeba opravit vyvážením distribuce celého souboru dat.
Decentralizovaná správa funkčních dat
Spíše než rozdělení hodnot datové sady do více segmentů má v mnoha případech větší smysl používat různé databáze pro různé funkční účely. Pokud například máte službu účtů a službu produktů, můžete mít vyhrazené databáze, které se shodují s každým problémem, a pomoci vám nezávisle škálovat různé komponenty.
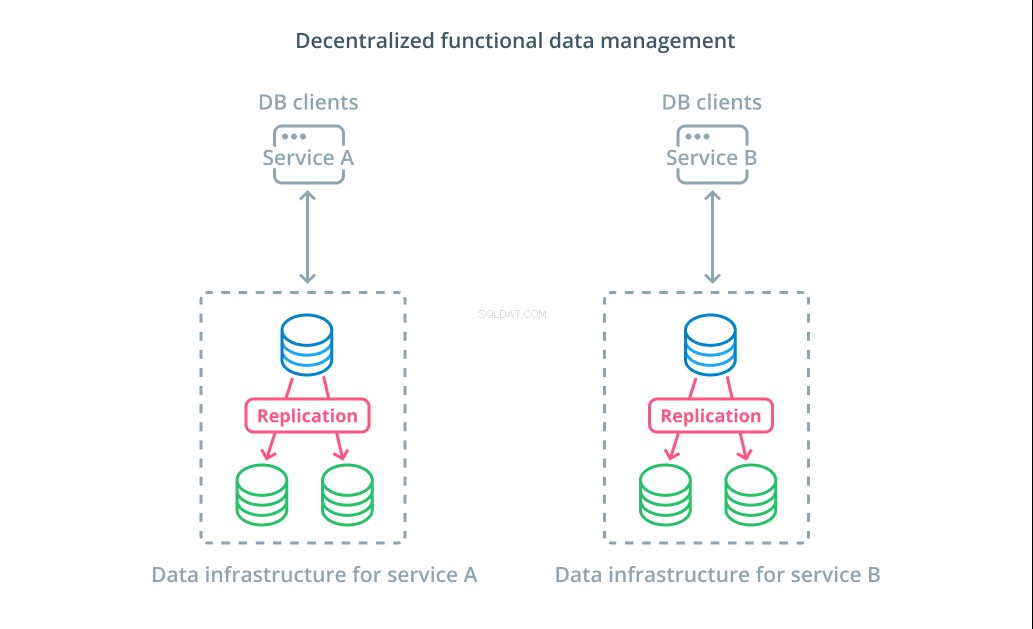
Funkční správa dat vám umožňuje rozdělit vaši databázovou infrastrukturu a spravovat každou část podle potřeb jejích klientů. Každá funkční část může být škálována pomocí jakékoli strategie, která dává největší smysl. Umožňuje vám navrhnout schéma databáze a nasadit jej na místo, které nejlépe odpovídá vzorům konkrétního případu použití, namísto toho, aby sloužilo celé organizaci.
Pro mnoho organizací má tato strategie důležité výhody, které přesahují vlastnosti skutečných systémů. Decentralizace správy dat může menším týmům umožnit vlastnit svá vlastní data bez koordinace změn s ostatními stranami. Dobře se hodí k cílenému oddělení zájmů podporovaných architekturami aplikací orientovaných na mikroslužby.
Bezserverové databáze
Různé kompromisy, které musíte vyhodnotit, a množství infrastruktury, od které se očekává, že budete spravovat pro správné škálování, mohou být pro mnoho lidí ohromující. Jednou z možností, jak tuto složitost snížit, je využít výhod databázových služeb, které spravují infrastrukturu a škálují za vás.
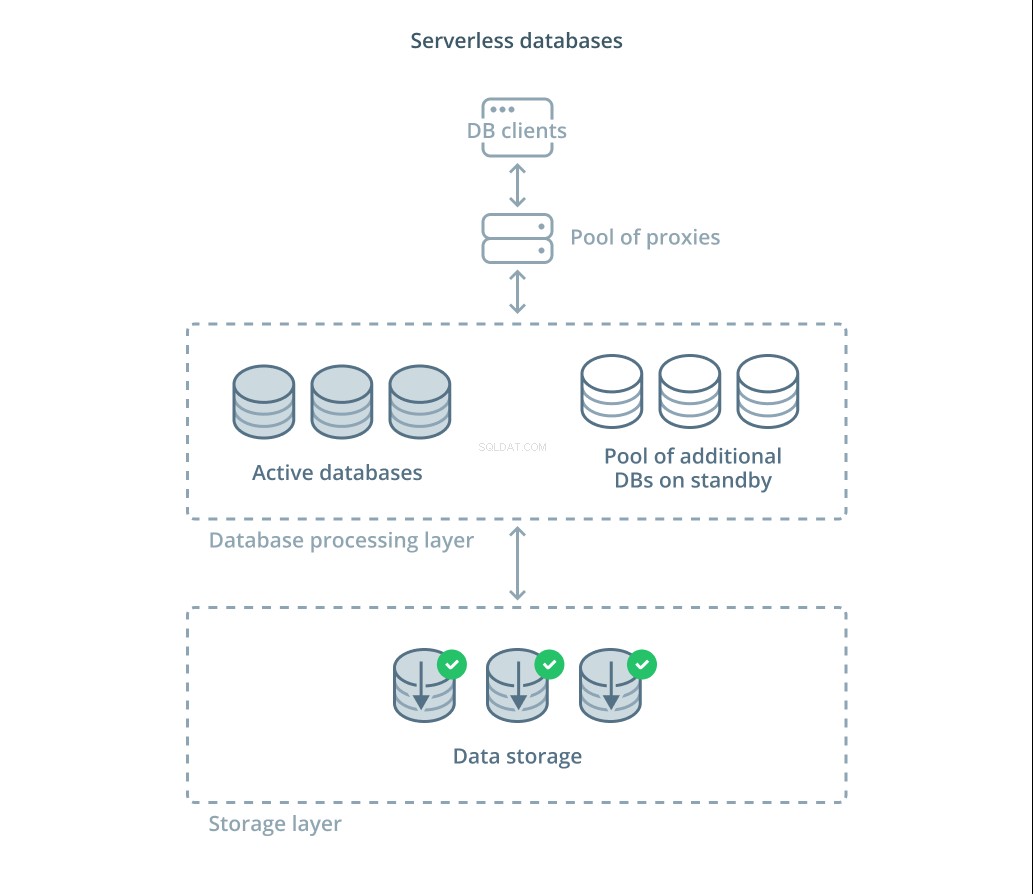
Bezserverové databáze jsou kategorií služeb, které oddělují ukládání dat od zpracování dat, aby bylo možné snadno škálovat zdroje v reakci na změny poptávky.
Vrstva úložiště dat je zodpovědná za udržování skutečných dat spravovaných systémem. Před touto vrstvou je nasazena vrstva škálovatelných databázových procesorových jednotek, aby zvládla skutečné zpracování dotazů na datové sady. Počet jednotek aktivních v kteroukoli danou chvíli je přímo vázán na aktuální využití, takže je alokováno více zdrojů, když poptávka vrcholí, a pokud se situace uklidní, procesorové jednotky se vrátí do pohotovostního režimu.
Dotazy jsou předávány databázovým procesorům prostřednictvím směrovacího proxy, který ví, jak předávat požadavky aktivním uzlům a kdy žádat o další zdroje.
Bezserverové databáze mají mnoho stejných vlastností jako tradiční databázové služby, které implementují funkce automatického škálování. Oba mohou alokovat kapacitu na základě poptávky. Bezserverové databáze však umožňují oddělit náklady na úložiště od nákladů na zpracování a mohou škálovat zpracování až na nulu, když není potřeba. Navíc bezserverová řešení mají tendenci být schopna škálovat mnohem rychleji, aby uspokojila poptávku ve srovnání s automatickým škálováním nabízeným tradičními nabídkami.
I když se pro někoho mohou databáze bez serveru hodit, nejsou to stříbrná kulka. V případech, kdy databázové procesory byly zmenšen na nulu, může docházet ke zpožděním ve zpracování kvůli studeným startům. Kromě toho může proudění přes spojení mezi různými komponentami v bezserverovém databázovém zásobníku vést k další latenci.
Bezserverové databázové platformy mohou být také obtížné z provozního hlediska. Nasazení a změny databáze může být obtížnější odůvodnit a sledovat. Lokální vývojové prostředí se také může výrazně lišit od produkčního prostředí kvůli dynamickému stavu databázového systému. A konečně, stejně jako u jakékoli jiné cloudové služby, používání bezserverových databází vás může potenciálně vystavit nebezpečí uzamčení dodavatele. Při navrhování na platformě bez serveru je důležité pamatovat na tyto kompromisy.
Závěr
Existuje mnoho způsobů, jak navrhnout, nasadit a spravovat databázovou infrastrukturu, protože požadavky na vaše aplikace se stávají závažnějšími. Každé řešení má své silné stránky a omezení, kterým je důležité porozumět při hledání vhodného pro vaše prostředí.
Informace o tom, jak databázová infrastruktura ovlivňuje dostupnost, výkon a integritu vašich dat, vám umožní vyhnout se nákladným chybám a implementacím, které neposkytují záruky, které potřebujete. Pokud některý z výše uvedených návrhů nesplňuje vaše požadavky, možná budete moci zkombinovat některé prvky různých přístupů, abyste získali další výhody.
Chcete-li se dozvědět více o obecných vzorcích uvedených výše, zde jsou některé další zdroje, které si můžete prohlédnout:
- Zvětšení versus zmenšení
- Oddělení odpovědnosti za příkazový dotaz
- Multiprimární replikace
- Ukládání přečtených dotazů do mezipaměti
- Sdílení dat
- Decentralizovaná správa dat
- Bezserverové databáze