Nyní naše komunita pro analýzu velkých dat začala naplno využívat Apache Spark pro zpracování velkých dat. Zpracování může pro ad-hoc dotazy, předem sestavené dotazy, zpracování grafů, strojové učení a dokonce i pro streamování dat.
Pochopení Spark Job Submission je proto pro komunitu velmi důležité. Rozšiřte se o to, že se s vámi rádi podělíme o poznatky o krocích zahrnutých v odeslání úlohy Apache Spark.
V zásadě má dva kroky,

Předání úlohy
Úloha Spark je odeslána automaticky, když jsou na RDD provedeny akce jako count ().
Interně runJob() bude volána na SparkContext a poté zavolána do plánovače, který běží jako součást derivace.
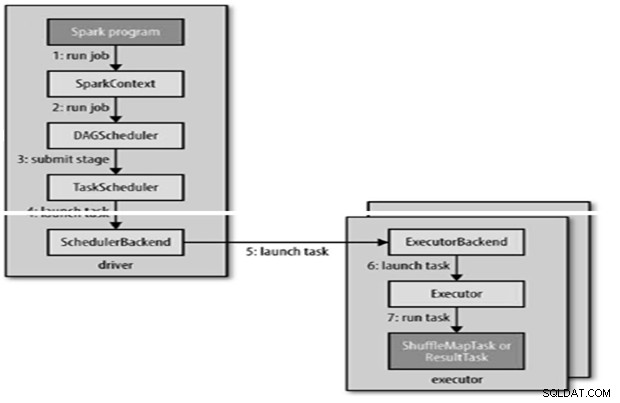
DAG Construction
Existují dva typy konstrukcí DAG,

- Jednoduchá úloha Spark je taková, která nepotřebuje míchání, a proto má pouze jednu fázi složenou z výsledných úloh, jako je úloha pouze na mapě v MapReduce
- Složitá úloha Spark zahrnuje operace seskupování a vyžaduje jednu nebo více fází náhodného přehrávání.
- Plánovač DAG společnosti Spark změní úlohu na dvě fáze.
- Plánovač DAG je zodpovědný za rozdělení fáze na úkoly, které se předkládají plánovači úloh.
- Každé úloze dává plánovač DAG přednost umístění, aby plánovač úloh mohl využít datovou lokalitu.
- Podřízené fáze jsou odesílány, až když je rodiče úspěšně dokončí.
Plánování úloh
- Plánovač úloh odešle sadu úloh; používá svůj seznam exekutorů, kteří jsou pro aplikaci spuštěni, a vytváří mapování úkolů k exekutorům, které bere v úvahu preference umístění.
- Plánovač úloh přiděluje exekutorům, kteří mají volná jádra, každé úloze je standardně přiděleno jedno jádro. Lze jej změnit parametrem spark.task.cpus.
- Spark používá Akka, což je platforma založená na hercích pro vytváření vysoce škálovatelných distribuovaných aplikací řízených událostmi.
- Spark nepoužívá Hadoop RPC pro vzdálená volání.
Provedení úlohy
Exekutor spustí úlohu následovně,
- Zajišťuje, že JAR a závislosti souborů pro úlohu jsou aktuální.
- Zruší serializaci kódu úlohy.
- Kód úlohy se provede.
- Úloha vrátí výsledky ovladači, který se sestaví do konečného výsledku, který se vrátí uživateli.
Reference
- The Hadoop Definitive Guide
- Analytics &Big Data Open Source Community
Tento článek se původně objevil zde. Znovu publikováno se svolením. Své stížnosti na porušení autorských práv odešlete zde.