V části 1 a části 2 této série jsem pokryl logické nebo koncepční aspekty výrazů pojmenovaných tabulek obecně a konkrétně odvozených tabulek. Tento a příští měsíc se budu věnovat aspektům fyzického zpracování odvozených tabulek. Připomeňme si z části 1 samostatnost fyzických dat princip relační teorie. Předpokládá se, že relační model a standardní dotazovací jazyk, který je na něm založen, se mají zabývat pouze koncepčními aspekty dat a ponechat detaily fyzické implementace, jako je ukládání, optimalizace, přístup a zpracování dat, na databázové platformě (implementace ). Na rozdíl od koncepčního zacházení s daty, které je založeno na matematickém modelu a standardním jazyce, a proto je velmi podobné v různých systémech správy relačních databází, není fyzické zpracování dat založeno na žádném standardu, a proto má tendenci být velmi specifický pro platformu. Ve svém pokrytí fyzického ošetření pojmenovaných tabulkových výrazů v seriálu se zaměřuji na ošetření v Microsoft SQL Server a Azure SQL Database. Fyzické zacházení na jiných databázových platformách může být zcela odlišné.
Připomeňme, že to, co spustilo tuto řadu, je určitý zmatek, který existuje v komunitě SQL Server kolem výrazů pojmenovaných tabulek. Jak z hlediska terminologie, tak z hlediska optimalizace. Některým terminologickým úvahám jsem se věnoval v prvních dvou dílech seriálu a více se jim budu věnovat v budoucích článcích při probírání CTE, zobrazení a inline TVF. Pokud jde o optimalizaci pojmenovaných tabulkových výrazů, dochází k nejasnostem v následujících položkách (zde zmiňuji odvozené tabulky, protože na to je zaměřen tento článek):
- Trvalost: Je někde uložená odvozená tabulka? Uchovává se na disku a jak pro něj SQL Server zpracovává paměť?
- Projekce sloupce: Jak funguje párování indexů s odvozenými tabulkami? Pokud například odvozená tabulka promítá určitou podmnožinu sloupců z nějaké základní tabulky a nejvzdálenější dotaz promítá podmnožinu sloupců z odvozené tabulky, je SQL Server dostatečně chytrý, aby zjistil optimální indexování na základě konečné podmnožiny sloupců. že je to vlastně potřeba? A co oprávnění; potřebuje uživatel oprávnění ke všem sloupcům, na které se odkazuje ve vnitřních dotazech, nebo pouze k těm posledním, které jsou skutečně potřeba?
- Vícenásobné odkazy na aliasy sloupců: Pokud má odvozená tabulka sloupec výsledků, který je založen na nedeterministickém výpočtu, např. volání funkce SYSDATETIME, a vnější dotaz má více odkazů na tento sloupec, bude výpočet proveden pouze jednou nebo samostatně pro každý vnější odkaz ?
- Uvolnění/náhrada/vložení: Zruší SQL Server vnořený nebo vložený dotaz na odvozenou tabulku? To znamená, že SQL Server provádí substituční proces, při kterém převede původní vnořený kód na jeden dotaz, který jde přímo proti základním tabulkám? A pokud ano, existuje způsob, jak instruovat SQL Server, aby se vyhnul tomuto procesu rozkládání?
To vše jsou důležité otázky a odpovědi na tyto otázky mají významný dopad na výkon, takže je dobré mít jasnou představu o tom, jak se s těmito položkami na SQL Server zachází. Tento měsíc se budu zabývat prvními třemi položkami. O čtvrté položce je toho hodně co říct, takže jí příští měsíc (část 4) věnuji samostatný článek.
Ve svých příkladech použiji ukázkovou databázi nazvanou TSQLV5. Skript, který vytváří a naplňuje TSQLV5, najdete zde a jeho ER diagram zde.
Trvalost
Někteří lidé intuitivně předpokládají, že SQL Server přetrvává výsledek části tabulkového výrazu odvozené tabulky (výsledek vnitřního dotazu) v pracovní tabulce. K datu tohoto psaní tomu tak nebylo; nicméně vzhledem k tomu, že úvahy o perzistenci jsou volbou dodavatele, Microsoft by se mohl rozhodnout to v budoucnu změnit. SQL Server je skutečně schopen uchovat mezilehlé výsledky dotazů v pracovních tabulkách (obvykle v databázi tempdb) jako součást zpracování dotazu. Pokud se tak rozhodne, uvidíte v plánu nějakou formu spoolového operátora (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Volba SQL Serveru, zda chcete něco v pracovní tabulce zařadit nebo ne, však aktuálně nemá nic společného s vaším použitím výrazů pojmenované tabulky v dotazu. SQL Server někdy zařazuje mezivýsledky z důvodů výkonu, jako je zamezení opakované práce (ačkoli v současné době nesouvisí s používáním výrazů pojmenovaných tabulek) a někdy z jiných důvodů, jako je ochrana před Halloweenem.
Jak již bylo zmíněno, příští měsíc se dostanu k detailům rozkládání odvozených tabulek. Pro tuto chvíli postačí říci, že SQL Server normálně aplikuje proces unnesting/inlining na odvozené tabulky, kde nahradí vnořené dotazy dotazem na podkladové základní tabulky. No, trochu to zjednodušuji. Není to tak, že by SQL Server doslova převáděl původní řetězec dotazu T-SQL s odvozenými tabulkami na nový řetězec dotazu bez těchto; SQL Server spíše aplikuje transformace na vnitřní logický strom operátorů a výsledkem je, že odvozené tabulky se obvykle odpojí. Když se podíváte na plán provádění pro dotaz zahrnující odvozené tabulky, nevidíte o nich žádnou zmínku, protože pro většinu optimalizačních účelů neexistují. Vidíte přístup k fyzickým strukturám, které uchovávají data pro podkladové základní tabulky (hromada, indexy B-stromu rowstore a columnstore indexy pro tabulky založené na disku a stromové a hash indexy pro tabulky optimalizované pro paměť).
Existují případy, které brání SQL Serveru v zrušení vnoření odvozené tabulky, ale ani v těchto případech SQL Server neuchová výsledek výrazu tabulky v pracovní tabulce. Podrobnosti spolu s příklady poskytnu příští měsíc.
Vzhledem k tomu, že SQL Server neuchovává odvozené tabulky, spíše přímo interaguje s fyzickými strukturami, které uchovávají data pro podkladové základní tabulky, je otázka, jak se zachází s pamětí pro odvozené tabulky, diskutabilní. Pokud jsou podkladové základní tabulky diskové, je třeba jejich relevantní stránky zpracovat ve fondu vyrovnávacích pamětí. Pokud jsou podkladové tabulky optimalizované pro paměť, je třeba zpracovat jejich příslušné řádky v paměti. Ale to se neliší od toho, když se dotazujete na podkladové tabulky přímo sami bez použití odvozených tabulek. Takže zde není nic zvláštního. Když používáte odvozené tabulky, SQL Server pro ně nemusí uplatňovat žádné zvláštní úvahy o paměti. Pro většinu účelů optimalizace dotazů neexistují.
Pokud máte případ, kdy potřebujete uchovat výsledek nějakého mezikroku v pracovní tabulce, musíte používat dočasné tabulky nebo proměnné tabulky – nikoli pojmenované tabulkové výrazy.
Projekce sloupce a slovo na SELECT *
Projekce je jedním z původních operátorů relační algebry. Předpokládejme, že máte vztah R1 s atributy x, y a z. Projekce R1 na nějakou podmnožinu jeho atributů, např. x a z, je nový vztah R2, jehož záhlaví je podmnožinou promítnutých atributů z R1 (v našem případě x a z) a jehož tělem je množina n-tic. vytvořené z původní kombinace projektovaných hodnot atributů z n-tic R1.
Připomeňme, že tělo vztahu – je to soubor n-tic – podle definice nemá žádné duplikáty. Je tedy samozřejmé, že n-tice výsledného vztahu jsou odlišnou kombinací hodnot atributů promítnutých z původního vztahu. Pamatujte však, že tělo tabulky v SQL je vícemnožinou řádků, nikoli množinou, a SQL normálně duplicitní řádky neodstraní, pokud mu k tomu nedáte pokyn. Vzhledem k tabulce R1 se sloupci x, y a z může následující dotaz potenciálně vracet duplicitní řádky, a proto se neřídí sémantikou operátora projekce relační algebry, která vrací množinu:
SELECT x, zFROM R1;
Přidáním klauzule DISTINCT odstraníte duplicitní řádky a budete přesněji dodržovat sémantiku relační projekce:
SELECT DISTINCT x, zFROM R1;
Samozřejmě existují případy, kdy víte, že výsledek vašeho dotazu má odlišné řádky bez potřeby klauzule DISTINCT, např. když podmnožina sloupců, které vracíte, obsahuje klíč z dotazované tabulky. Pokud je například x klíč v R1, výše uvedené dva dotazy jsou logicky ekvivalentní.
V každém případě si vzpomeňte na otázky, které jsem zmínil dříve ohledně optimalizace dotazů zahrnujících odvozené tabulky a projekci sloupců. Jak funguje porovnávání indexů? Pokud odvozená tabulka promítá určitou podmnožinu sloupců z nějaké základní tabulky a nejvzdálenější dotaz promítá podmnožinu sloupců z odvozené tabulky, je SQL Server dostatečně chytrý na to, aby zjistil optimální indexování na základě konečné podmnožiny sloupců, která je ve skutečnosti potřeboval? A co oprávnění; potřebuje uživatel oprávnění ke všem sloupcům, na které se odkazuje ve vnitřních dotazech, nebo pouze k těm posledním, které jsou skutečně potřeba? Předpokládejme také, že dotaz na tabulkový výraz definuje sloupec výsledků, který je založen na výpočtu, ale vnější dotaz tento sloupec nepromítá. Vyhodnocuje se vůbec výpočet?
Začněme poslední otázkou, zkusme to. Zvažte následující dotaz:
USE TSQLV5;GO SELECT custid, city, 1/0 AS div0errorFROM Sales.Customers;
Jak byste očekávali, tento dotaz selže s chybou dělení nulou:
Msg 8134, Level 16, State 1Chyba dělení nulou.
Dále definujte odvozenou tabulku nazvanou D na základě výše uvedeného dotazu a ve vnějším dotazu projektu D pouze na zákazníka a město, například takto:
SELECT custid, cityFROM ( SELECT custid, city, 1/0 AS div0error FROM Sales.Customers ) AS D;
Jak již bylo zmíněno, SQL Server normálně používá zrušení vnoření/substituce, a protože v tomto dotazu není nic, co by bránilo vnoření (více o tom příští měsíc), je výše uvedený dotaz ekvivalentní následujícímu dotazu:
SELECT custid, cityFROM Sales.Customers;
Opět zde trochu zjednodušuji. Realita je o něco složitější, než tyto dva dotazy, které jsou považovány za skutečně identické, ale k těmto složitostem se dostanu příští měsíc. Jde o to, že výraz 1/0 se ani nezobrazuje v plánu provádění dotazu a není vůbec vyhodnocen, takže výše uvedený dotaz běží úspěšně bez chyb.
Přesto musí být tabulkový výraz platný. Zvažte například následující dotaz:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;
I když vnější dotaz promítá pouze sloupec ze sady seskupení vnitřního dotazu, vnitřní dotaz není platný, protože se pokouší vrátit sloupce, které nejsou součástí sady seskupení ani nejsou obsaženy v agregační funkci. Tento dotaz se nezdaří s následující chybou:
Msg 8120, Level 16, State 1Sloupec 'Sales.Customers.custid' je ve výběrovém seznamu neplatný, protože není obsažen ani v agregační funkci, ani v klauzuli GROUP BY.
Dále se pojďme zabývat otázkou porovnávání indexů. Pokud vnější dotaz promítá pouze podmnožinu sloupců z odvozené tabulky, bude SQL Server dostatečně chytrý na to, aby provedl porovnávání indexů pouze na základě vrácených sloupců (a samozřejmě jakýchkoli dalších sloupců, které jinak hrají smysluplnou roli, jako je filtrování, seskupování a tak dále)? Ale než se vypořádáme s touto otázkou, možná se divíte, proč se s tím vůbec obtěžujeme. Proč by měl vnitřní dotaz vracet sloupce, které vnější dotaz nepotřebuje?
Odpověď je jednoduchá, zkrátit kód tím, že vnitřní dotaz použije nechvalně známý SELECT *. Všichni víme, že použití SELECT * je špatný postup, ale je tomu tak především v případě, že se používá v nejvzdálenějším dotazu. Co když zadáte dotaz na tabulku s určitým záhlavím a později se toto záhlaví změní? Aplikace může skončit s chybami. I když neskončíte s chybami, můžete skončit generováním zbytečného síťového provozu tím, že vrátíte sloupce, které aplikace ve skutečnosti nepotřebuje. Navíc v takovém případě využíváte indexování méně optimálně, protože snižujete šance na shodu krycích indexů, které jsou založeny na skutečně potřebných sloupcích.
To znamená, že se ve skutečnosti cítím docela pohodlně pomocí SELECT * v tabulkovém výrazu, protože vím, že stejně promítnu pouze skutečně potřebné sloupce v nejvzdálenějším dotazu. Z logického hlediska je to docela bezpečné s několika drobnými výhradami, ke kterým se brzy dostanu. To je za předpokladu, že se v takovém případě porovnávání indexů provádí optimálně, a to je dobrá zpráva.
Chcete-li to demonstrovat, předpokládejme, že potřebujete dotaz na tabulku Sales.Orders a vrátíte tři nejnovější objednávky pro každého zákazníka. Plánujete definovat odvozenou tabulku s názvem D na základě dotazu, který počítá čísla řádků (výsledkový sloupec rownum), které jsou rozděleny podle custid a seřazené podle data objednávky DESC, orderid DESC. Vnější dotaz bude filtrovat z D (relační omezení ) pouze řádky, kde rownum je menší nebo rovno 3, a projekt D na custid, orderdate, orderid a rownum. Nyní má Sales.Orders více sloupců než ty, které potřebujete promítnout, ale pro stručnost chcete, aby vnitřní dotaz používal SELECT * plus výpočet čísla řádku. To je bezpečné a bude to z hlediska porovnávání indexů řešeno optimálně.
Chcete-li vytvořit optimální index pokrytí pro podporu vašeho dotazu, použijte následující kód:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Zde je dotaz, který archivuje daný úkol (nazýváme ho Dotaz 1):
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Všimněte si SELECT * vnitřního dotazu a seznamu explicitních sloupců vnějšího dotazu.
Plán pro tento dotaz, jak jej vykreslil SentryOne Plan Explorer, je znázorněn na obrázku 1.
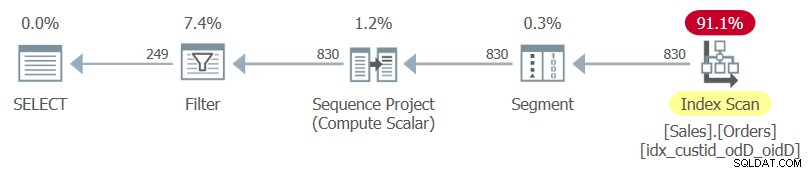 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
Všimněte si, že jediný index použitý v tomto plánu je optimální krycí index, který jste právě vytvořili.
Pokud zvýrazníte pouze vnitřní dotaz a prozkoumáte plán jeho provádění, uvidíte použitý seskupený index tabulky, po kterém bude následovat operace řazení.
Tak to je dobrá zpráva.
Co se týče oprávnění, to je jiný příběh. Na rozdíl od porovnávání indexů, kde nepotřebujete, aby index zahrnoval sloupce, na které odkazují vnitřní dotazy, pokud nakonec nejsou potřeba, musíte mít oprávnění ke všem odkazovaným sloupcům.
Chcete-li to demonstrovat, použijte následující kód k vytvoření uživatele s názvem user1 a přiřazení některých oprávnění (oprávnění SELECT pro všechny sloupce z Sales.Customers a pouze pro tři sloupce z Sales.Orders, které jsou nakonec relevantní ve výše uvedeném dotazu):
VYTVOŘIT UŽIVATELE user1 BEZ PŘIHLÁŠENÍ; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custisd, orderdate, orderid) TO user1;
Spusťte následující kód k zosobnění uživatele1:
EXECUTE AS USER ='user1';
Zkuste vybrat všechny sloupce z Sales.Orders:
SELECT * FROM Sales.Orders;
Podle očekávání se kvůli nedostatku oprávnění u některých sloupců zobrazí následující chyby:
Msg 230, Level 14, State 1Oprávnění SELECT bylo odepřeno ve sloupci 'empid' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230 , Úroveň 14, Stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'požadované datum' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'shippeddate' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, Stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'shipperid' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno pro sloupec 'doprava' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno pro sloupec 'shipname' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno u sloupce 'shipaddress' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Oprávnění SELECT bylo odepřeno pro sloupec 'shipcity' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
The SELECT oprávnění bylo odepřeno pro sloupec 'lodní region' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo zamítnuto ve sloupci 'shippostalcode' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Oprávnění SELECT bylo odepřeno dne sloupec 'shipcountry' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Vyzkoušejte následující dotaz, promítání a interakci pouze se sloupci, pro které má uživatel1 oprávnění:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Přesto se zobrazí chyby oprávnění sloupců kvůli nedostatku oprávnění u některých sloupců, na které odkazuje vnitřní dotaz prostřednictvím jeho SELECT *:
Msg 230, Level 14, State 1Oprávnění SELECT bylo odepřeno ve sloupci 'empid' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230 , Úroveň 14, Stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'požadované datum' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'shippeddate' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, Stav 1
Oprávnění SELECT bylo odepřeno ve sloupci 'shipperid' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno pro sloupec 'doprava' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno pro sloupec 'shipname' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo odepřeno u sloupce 'shipaddress' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Oprávnění SELECT bylo odepřeno pro sloupec 'shipcity' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
The SELECT oprávnění bylo odepřeno pro sloupec 'lodní region' objektu 'Objednávky', databáze 'TSQLV5', schéma 'Prodej'.
Zpráva 230, úroveň 14, stav 1
Oprávnění SELECT bylo zamítnuto ve sloupci 'shippostalcode' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Msg 230, Level 14, State 1
Oprávnění SELECT bylo odepřeno dne sloupec 'shipcountry' objektu 'Orders', databáze 'TSQLV5', schéma 'Sales'.
Pokud je ve vaší společnosti skutečně zvykem přidělovat uživatelům oprávnění pouze k relevantním sloupcům, se kterými potřebují interakci, mělo by smysl použít trochu delší kód a být explicitní ohledně seznamu sloupců ve vnitřních i vnějších dotazech, takhle:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;Tentokrát dotaz běží bez chyb.
Další variantou, která vyžaduje, aby uživatel měl oprávnění pouze k relevantním sloupcům, je explicitně uvést názvy sloupců v seznamu SELECT vnitřního dotazu a použít SELECT * ve vnějším dotazu, například takto:
SELECT *FROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;Tento dotaz také běží bez chyb. Tuto verzi však vidím jako verzi náchylnou k chybám pro případ, že by později došlo k nějakým změnám v nějaké vnitřní úrovni vnoření. Jak již bylo zmíněno dříve, podle mě je nejlepším postupem explicitně vyjádřit seznam sloupců v nejvzdálenějším dotazu. Takže pokud nemáte žádné obavy z nedostatku oprávnění k některým sloupcům, cítím se dobře s SELECT * ve vnitřních dotazech, ale s explicitním seznamem sloupců v nejvzdálenějším dotazu. Pokud je použití konkrétních oprávnění pro sloupce ve společnosti běžnou praxí, pak je nejlepší jednoduše vyjádřit názvy sloupců na všech úrovních vnoření. Pamatujte, že explicitní vyjádření názvů sloupců na všech úrovních vnoření je ve skutečnosti povinné, pokud je váš dotaz použit v objektu vázaném na schéma, protože vazba schématu neumožňuje použití SELECT * kdekoli v dotazu.
V tomto okamžiku spusťte následující kód k odebrání indexu, který jste vytvořili dříve na Sales.Orders:
PUSTI INDEX, POKUD EXISTUJE idx_custid_odD_oidD ON Sales.Orders;Existuje další případ s podobným dilematem týkajícím se legitimity použití SELECT *; ve vnitřním dotazu predikátu EXISTS.
Zvažte následující dotaz (budeme ho nazývat Dotaz 2):
SELECT custidFROM Sales.Customers AS CWHERE EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid =C.custid);Plán pro tento dotaz je znázorněn na obrázku 2.
Obrázek 2:Plán pro dotaz 2
Při použití porovnávání indexů optimalizátor usoudil, že index idx_nc_custid je krycí index na Sales.Orders, protože obsahuje sloupec custid – jediný skutečně relevantní sloupec v tomto dotazu. A to navzdory skutečnosti, že tento index kromě custid neobsahuje žádný jiný sloupec a že vnitřní dotaz v predikátu EXISTS říká SELECT *. Chování se zatím zdá podobné jako při použití SELECT * v odvozených tabulkách.
Tento dotaz se liší tím, že běží bez chyb, a to navzdory skutečnosti, že uživatel1 nemá oprávnění k některým sloupcům z Sales.Orders. Existuje argument, který ospravedlňuje, že zde nejsou vyžadována oprávnění pro všechny sloupce. Koneckonců, predikát EXISTS potřebuje pouze zkontrolovat existenci odpovídajících řádků, takže seznam SELECT vnitřního dotazu je opravdu bezvýznamný. Pravděpodobně by bylo nejlepší, kdyby SQL v takovém případě vůbec nevyžadoval seznam SELECT, ale ta loď už odplula. Dobrou zprávou je, že seznam SELECT je fakticky ignorován – jak z hlediska porovnávání indexů, tak z hlediska požadovaných oprávnění.
Zdá se také, že existuje další rozdíl mezi odvozenými tabulkami a EXISTS při použití SELECT * ve vnitřním dotazu. Zapamatujte si tento dotaz z předchozího článku:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;Pokud si vzpomínáte, tento kód vygeneroval chybu, protože vnitřní dotaz je neplatný.
Zkuste stejný vnitřní dotaz, ale tentokrát v predikátu EXISTS (tento výrok budeme nazývat Příkaz 3):
POKUD EXISTUJE ( VYBERTE * Z Sales.Customers GROUP PODLE zemí ) TISKNOUT 'To funguje! Díky Dmitri Korotkevitch za tip!';Kupodivu SQL Server považuje tento kód za platný a běží úspěšně. Plán tohoto kódu je znázorněn na obrázku 3.
Obrázek 3:Plán pro prohlášení 3
Tento plán je totožný s plánem, který byste získali, kdyby byl vnitřní dotaz pouze SELECT * FROM Sales.Customers (bez GROUP BY). Koneckonců, kontrolujete existenci skupin, a pokud existují řádky, přirozeně existují skupiny. Každopádně si myslím, že skutečnost, že SQL Server považuje tento dotaz za platný, je chyba. Jistě, SQL kód by měl být platný! Ale chápu, proč by někteří mohli tvrdit, že seznam SELECT v dotazu EXISTS má být ignorován. V každém případě plán používá prozkoumané levé poloviční spojení, které nemusí vracet žádné sloupce, ale pouze prozkoumá tabulku a zkontroluje existenci jakýchkoli řádků. Index na Customers může být jakýkoli index.
V tomto okamžiku můžete spustit následující kód, abyste zastavili vydávání se za uživatele user1 a zrušili jej:
REVERT; DROP USER IF EXISTS user1;Zpět k tomu, že považuji za pohodlnou praxi používat SELECT * ve vnitřních úrovních vnořování, čím více úrovní máte, tím více tato praxe zkracuje a zjednodušuje váš kód. Zde je příklad se dvěma úrovněmi vnoření:
SELECT orderid, orderyear, custid, empid, shipperidFROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear FROM ( SELECT *, YEAR(orderdate) AS orderyear FROM Sales.Orders ) AS D1 ) AS D2WHERE orderdate =konec roku;Existují případy, kdy tuto praxi nelze použít. Například když vnitřní dotaz spojuje tabulky se společnými názvy sloupců, jako v následujícím příkladu:
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Sales.Customers i Sales.Orders mají sloupec nazvaný custid. K definování odvozené tabulky D používáte tabulkový výraz, který je založen na spojení mezi dvěma tabulkami. Pamatujte, že záhlaví tabulky je sada sloupců a jako sada nemůžete mít duplicitní názvy sloupců. Tento dotaz se proto nezdaří s následující chybou:
Msg 8156, Level 16, State 1
Sloupec 'custid' byl pro 'D' zadán vícekrát.Zde musíte být explicitní ohledně názvů sloupců ve vnitřním dotazu a ujistěte se, že buď vrátíte custid pouze z jedné z tabulek, nebo přiřadíte jedinečné názvy sloupců výsledným sloupcům pro případ, že chcete vrátit oba. Častěji byste použili předchozí přístup, například takto:
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O. orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Opět můžete být explicitní s názvy sloupců ve vnitřním dotazu a použít SELECT * ve vnějším dotazu, například takto:
SELECT *FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Prodej .Zákazníci AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;Ale jak jsem již zmínil dříve, považuji za špatný postup nevyjadřovat se explicitně o názvech sloupců v nejvzdálenějším dotazu.
Vícenásobné odkazy na aliasy sloupců
Pokračujme k další položce – více odkazů na odvozené sloupce tabulky. Pokud má odvozená tabulka sloupec výsledků, který je založen na nedeterministickém výpočtu a vnější dotaz obsahuje více odkazů na tento sloupec, bude výpočet vyhodnocen pouze jednou nebo samostatně pro každý odkaz?
Začněme tím, že se předpokládá, že více odkazů na stejnou nedeterministickou funkci v dotazu bude vyhodnoceno nezávisle. Jako příklad zvažte následující dotaz:
VYBERTE NEWID() AS mynevid1, NEWID() AS mynevid2;Tento kód generuje následující výstup zobrazující dva různé GUID:
myneid1 mynevid2----------------------------------- --------- ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406Naopak, pokud máte odvozenou tabulku se sloupcem, který je založen na nedeterministickém výpočtu a vnější dotaz má více odkazů na tento sloupec, předpokládá se, že výpočet bude vyhodnocen pouze jednou. Zvažte následující dotaz (tento dotaz budeme nazývat Dotaz 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2FROM ( SELECT NEWID() AS mynewid ) AS D;Plán pro tento dotaz je znázorněn na obrázku 4.
Obrázek 4:Plán pro dotaz 4
Všimněte si, že v plánu je pouze jedno vyvolání funkce NEWID. Proto výstup zobrazuje stejné GUID dvakrát:
myneid1 mynevid2----------------------------------- --------- ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74AE74AVýše uvedené dva dotazy tedy nejsou logicky ekvivalentní a existují případy, kdy vkládání/substituce neprobíhá.
U některých nedeterministických funkcí je trochu složitější demonstrovat, že více vyvolání v dotazu je zpracováno samostatně. Vezměte si jako příklad funkci SYSDATETIME. Má přesnost 100 nanosekund. Jaká je pravděpodobnost, že dotaz, jako je následující, skutečně zobrazí dvě různé hodnoty?
VYBERTE SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;Pokud se nudíte, můžete opakovaně mačkat F5, dokud se to nestane. Pokud máte důležitější věci na práci se svým časem, můžete raději spustit smyčku, například:
DECLARE @i AS INT =1; WHILE EXISTS( SELECT * FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;Například, když jsem spustil tento kód, dostal jsem 1971.
Pokud se chcete ujistit, že nedeterministická funkce je vyvolána pouze jednou, a spoléhat se na stejnou hodnotu ve více odkazech dotazu, ujistěte se, že definujete tabulkový výraz se sloupcem založeným na vyvolání funkce a máte na tento sloupec více odkazů. z vnějšího dotazu, jako je to (tento dotaz budeme nazývat Dotaz 5):
SELECT mydt AS mydt1, mydt AS mydt1FROM ( SELECT SYSDATETIME() AS mydt ) AS D;Plán pro tento dotaz je znázorněn na obrázku 5.
Obrázek 5:Plán pro dotaz 5
Notice in the plan that the function is invoked only once.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;Shrnutí
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.