Než projdeme problém s výkonem předávaných záznamů a vyřešíme jej, musíme zkontrolovat strukturu tabulek SQL Server.
Přehled struktury tabulky
Na serveru SQL Server jsou základní jednotkou úložiště dat 8 kB stránky . Každá stránka začíná 96bajtovým záhlavím, které obsahuje systémové informace o této stránce. Poté budou řádky tabulky uloženy na datových stránkách sériově za záhlavím. Na konci stránky bude tabulka odsazení řádků, která obsahuje jeden záznam pro každý řádek, uložena naproti pořadí řádků na stránce. Tento záznam posunu řádku ukazuje, jak daleko je umístěn první bajt tohoto řádku od začátku stránky.
SQL Server nám poskytuje dva typy tabulek na základě struktury této tabulky. Seskupeny tabulka ukládá a třídí data na datových stránkách na základě předdefinovaných hodnot sloupce nebo sloupců indexového klíče Clustered. Kromě toho jsou datové stránky v seskupené tabulce setříděny a propojeny v propojeném seznamu na základě hodnot klíče indexu seskupení. B-strom struktura indexu Clustered poskytuje rychlou metodu přístupu k datům na základě hodnot klíče indexu Clustered. Pokud je vložen nový řádek nebo je aktualizována existující hodnota klíče v seskupené tabulce, SQL Server uloží novou hodnotu do správné logické pozice, která odpovídá velikosti vloženého řádku bez porušení kritérií řazení. Pokud je vložená nebo aktualizovaná hodnota větší než dostupné místo na datové stránce, stránka se rozdělí na dvě stránky, aby odpovídala nové hodnotě.
Druhým typem tabulek je Hromada tabulka, ve které nejsou data v rámci datových stránek řazena v žádném pořadí a stránky nejsou spolu propojeny, protože v této tabulce není definován žádný Clustered index, který by vynucoval jakákoli kritéria řazení. Sledování stránek, které nejsou seřazeny podle žádných kritérií řazení nebo propojené v tabulce haldy, není snadný úkol. Pro zjednodušení procesu sledování alokace stránek v tabulce haldy používá SQL Server mapu alokace indexu (IAM), jediné logické spojení mezi datovými stránkami v tabulce haldy, zachováním záznamu pro každou datovou stránku v tabulce nebo indexu v tabulce IAM. Chcete-li načíst data z tabulky haldy, SQL Server Engine prohledá IAM, aby našel rozsah, který tvoří 8 stránek, které ukládají požadovaná data.
Problém s předávanými záznamy
Pokud je do tabulky haldy vložen nový řádek, SQL Server Engine prohledá Page Free Space (PFS) ke sledování stavu přidělení a využití místa na každé datové stránce, abyste našli první dostupné umístění na datových stránkách, které odpovídá velikosti vloženého řádku. Poté bude řádek přidán na vybranou stránku. Pokud je vložená hodnota větší než dostupné místo na datových stránkách, bude do tabulky přidána nová stránka, aby bylo možné novou hodnotu vložit.
Na druhou stranu, pokud jsou stávající data v tabulce haldy upravena, například jsme aktualizovali řetězec s proměnnou délkou s větší velikostí dat a aktuální prostor nevyhovuje novým datům, data se přesunou do jiného fyzického umístění a Přeposlaný záznam budou vloženy do tabulky haldy v původním umístění dat, aby ukázaly na nové umístění těchto dat a zjednodušily umístění sledovacích dat. Nové umístění dat obsahuje také ukazatel, který ukazuje na ukazatel přesměrování, aby byl neustále aktualizován v případě přesunu dat z nového umístění a aby se zabránilo dlouhému řetězci ukazatelů přesměrování nebo jeho odstranění. To může také vést k odstranění záznamu o přeposílání.
I když metoda přesměrování Forwarded Records snižuje potřebu operací přestavby tabulek náročných na zdroje a neklastrovaných indexů k aktualizaci datových adres při každé změně umístění dat, zdvojnásobuje také počet čtení potřebných k načtení dat. SQL Server nejprve navštíví staré umístění, kde najde předaný záznam, který jej přesměruje do nového umístění dat. Poté přečte požadovaná data, přičemž operaci čtení provede dvakrát. Problém s předávanými záznamy navíc vede ke změně sekvenčního čtení dat na náhodné čtení dat, což negativně ovlivňuje výkon operace načítání dat v průběhu času.
Vytvořme následující hromadu ForwardRecordDemo tabulky pomocí příkazu CREATE TABLE T-SQL níže:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Poté naplňte tuto tabulku 3K záznamy pro účely testování pomocí příkazu INSERT INTO T-SQL níže:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identifikace problému s předávanými záznamy
Informace o typu tabulky a počtu stránek spotřebovaných při ukládání dat tabulky, stejně jako procento fragmentace indexu a počet předaných záznamů pro konkrétní tabulku lze zobrazit dotazem na sys.dm_db_index_physical_stats funkce dynamického řízení systému a přechodem na DETAILNÍ režimu vrátit počet záznamů přesměrování. Chcete-li to provést, použijte níže uvedený skript T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Jak můžete vidět z výsledku dotazu, předchozí tabulka je tabulka haldy, která nemá vytvořený žádný Clustered index, který by třídil data na stránkách a propojoval stránky mezi sebou. Řádky o velikosti 3 kB vložené do tabulky jsou přiřazeny k 15 datové stránky, bez přeposílaných záznamů a nulového procenta fragmentace, jak ukazuje výsledek níže:

Když definujete datový typ sloupce jako VARCHAR nebo NVARCHAR, hodnota zadaná v definici datového typu je maximální povolenou velikostí pro tento řetězec, aniž by bylo nutné toto množství plně rezervovat při ukládání hodnot na datové stránky. Například Jan jméno zaměstnance vložené do této tabulky vyhradí pouze 8 bajtů z maximálních 100 bajtů pro tento sloupec, přičemž je třeba vzít v úvahu, že uložení řetězce NVARCHAR zdvojnásobí bajty požadované pro sloupec VARCHAR, jak je znázorněno v DATALENGTH výsledek funkce níže:
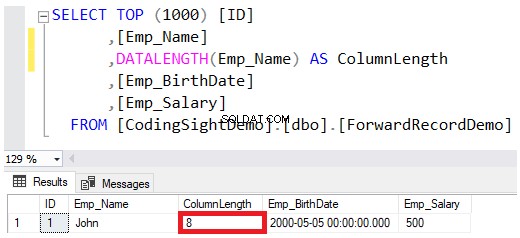
Pokud chcete aktualizovat hodnotu sloupce Emp_Name tak, aby obsahoval celé jméno zaměstnance Johna, použijte níže uvedený příkaz UPDATE:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Zkontrolujte délku aktualizovaného sloupce pomocí DATALENGTH funkce. Uvidíte, že délka sloupce Emp_Name v aktualizovaných řádcích byla rozšířena o 28 bajtů na každý sloupec, což je asi 3,5 další datové stránky k této tabulce, jak ukazuje výsledek níže:
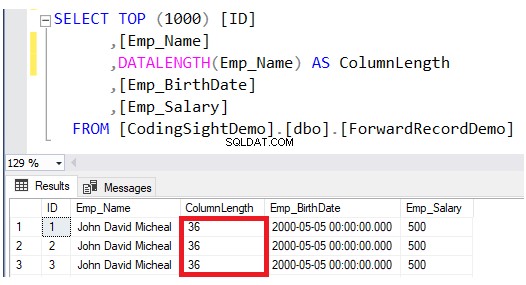
Poté zkontrolujte počet předávaných záznamů po operaci aktualizace dotazem na funkci dynamické správy systému sys.dm_db_index_physical_stats. Chcete-li to provést, použijte níže uvedený skript T-SQL:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Jak můžete vidět, aktualizace sloupce Emp_Name na 1000 záznamech s většími hodnotami řetězce, bez přidání nového záznamu, přiřadí extra 5 stránek do této tabulky, spíše než 3,5 stránky, jak se očekávalo dříve. K tomu dojde kvůli generování 484 přeposlané záznamy, aby ukazovaly na nová umístění přesouvaných dat. To může způsobit, že tabulka bude 33 % fragmentované, jak je jasně uvedeno níže:

Opět, pokud se vám podaří aktualizovat hodnotu sloupce Emp_Name tak, aby zahrnoval celé jméno zaměstnance Zaid, použijte níže uvedený příkaz UPDATE:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Zkontrolujte délku aktualizovaného sloupce pomocí DATALENGTH funkce. Uvidíte, že délka sloupce Emp_Name v aktualizovaných řádcích rozšířena o 22 bajtů na každý sloupec, což je asi 2,7 do této tabulky byly přidány další datové stránky, jak ukazuje výsledek níže:
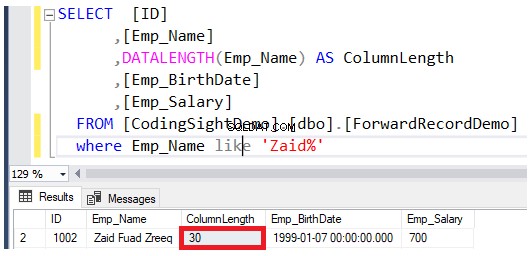
Po provedení operace aktualizace zkontrolujte počet přeposlaných záznamů. Můžete to provést dotazem na funkci dynamické správy systému sys.dm_db_index_physical_stats pomocí stejného skriptu T-SQL níže:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Výsledek vám ukáže, že aktualizace sloupce Emp_Name na dalších 1000 záznamech s většími hodnotami řetězce bez vložení nového řádku přiřadí další 4 stránek do této tabulky, spíše než 2,7 stránky, jak se očekávalo. K tomu dojde v důsledku generování dalších 417 přeposlané záznamy, aby ukázaly na nová umístění přesunutých dat a zachovali stejných 33 % procento fragmentace, jak je uvedeno níže:

Oprava problému s předávanými záznamy
Nejjednodušší způsob, jak vyřešit problém s předávanými záznamy, je odhadnout maximální délku řetězce, který bude uložen ve sloupci, a přiřadit jej pomocí pevné délky datový typ pro daný sloupec namísto použití datového typu s proměnnou délkou. Optimálním trvalým způsobem, jak vyřešit problém s předávanými záznamy, je přidat Clustered index k tomu stolu. Tímto způsobem bude tabulka kompletně převedena na Clusterovanou tabulku, která je řazena na základě hodnot Clustered index key. Bude řídit pořadí existujících dat, nově vložených a aktualizovaných dat, která neodpovídají aktuálnímu dostupnému prostoru na datové stránce, jak bylo popsáno dříve v úvodu tohoto článku.
Pokud přidání klastrovaného indexu do této tabulky není možností pro konkrétní požadavky, jako jsou pracovní tabulky nebo tabulky ETL, můžete problém s předávanými záznamy dočasně překonat sledováním předávaných záznamů a přebudováním tabulky haldy, abyste ji odstranili, což také aktualizovat všechny indexy bez clusterů v této tabulce haldy. Funkce opětovného sestavení tabulky haldy je zavedena v SQL Server 2008 pomocí ALTER TABLE…REBUILD Příkaz T-SQL.
Chcete-li vidět vliv předávaných záznamů na výkon na dotazy načítání dat, spusťte dotaz SELECT, který provádí vyhledávání na základě hodnot sloupce Emp_Name. Před provedením dotazu však povolte statistiky TIME a IO:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
V důsledku toho uvidíte, že 925 logické operace čtení se provádějí k získání požadovaných dat během 84 ms jak je uvedeno níže:

Chcete-li znovu sestavit tabulku haldy za účelem odstranění všech předávaných záznamů, použijte příkaz ALTER TABLE…REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Spusťte znovu stejný příkaz SELECT:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Statistiky TIME a IO vám ukážou, že pouze 21 logické operace čtení ve srovnání s 925 logické operace čtení se zahrnutými předávanými záznamy se provádějí za účelem získání požadovaných dat během 79 ms :

Chcete-li zkontrolovat počet přeposlaných záznamů po opětovném sestavení tabulky haldy, spusťte funkci dynamické správy systému sys.dm_db_index_physical_stats, použijte stejný skript T-SQL níže:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Uvidíte, že pouze 21 stránky s předchozími 3 stránky spotřebované pro předané záznamy, jsou přiřazeny k této tabulce pro ukládání dat, což je podobné odhadovanému výsledku, který jsme získali během operací vkládání a aktualizace dat (15+3,5+2,7). Po opětovném sestavení tabulky haldy jsou nyní všechny předané záznamy odstraněny. Výsledkem je tabulka bez fragmentace:

Problém s předávanými záznamy je důležitým problémem výkonu, který by správci databáze měli zvážit při plánování údržba haldového stolu. Předchozí výsledky jsou načteny z naší testovací tabulky, která obsahuje pouze 3K záznamy. Dokážete si představit počet stránek, které budou promarněny předávanými záznamy a snížením výkonu I/O kvůli čtení velkého počtu předávaných záznamů při čtení z obrovských tabulek!
Odkazy:
- Průvodce architekturou stránek a oblastí
- dm_db_index_physical_stats (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- Znalost „Přeposílaných záznamů“ může pomoci diagnostikovat těžko dohledatelné problémy s výkonem