JPA (Java Persistence Anotace ) je standardní řešení Java k překlenutí mezery mezi objektově orientovanými doménovými modely a relačními databázovými systémy. Cílem je mapovat třídy Java na relační tabulky a vlastnosti těchto tříd na řádky v tabulce. To mění sémantiku celkové zkušenosti s kódováním Java bezproblémovou spoluprací dvou různých technologií v rámci stejného programovacího paradigmatu. Tento článek poskytuje přehled a jeho podpůrnou implementaci v Javě.
Přehled
Relační databáze jsou možná nejstabilnější ze všech perzistentních technologií, které jsou k dispozici ve výpočetní technice, namísto všech složitostí, které s tím souvisí. Je to proto, že dnes, dokonce i ve věku takzvaných „velkých dat“, jsou relační databáze „NoSQL“ neustále žádané a prosperují. Relační databáze jsou stabilní technologií nikoli pouhými slovy, ale svou existencí v průběhu let. NoSQL může být dobré pro práci s velkým množstvím strukturovaných dat v podniku, ale četné transakční zátěže se lépe zvládají prostřednictvím relačních databází. S relačními databázemi je také spojeno několik skvělých analytických nástrojů.
Pro komunikaci s relační databází standardizovala ANSI jazyk nazvaný SQL (Structured Query Language ). Příkaz napsaný v tomto jazyce lze použít jak pro definování, tak pro manipulaci s daty. Problémem SQL při jednání s Javou je však to, že mají neodpovídající syntaktickou strukturu a velmi odlišnou v jádru, což znamená, že SQL je procedurální, zatímco Java je objektově orientovaná. Hledá se tedy fungující řešení, aby Java mohla mluvit objektově orientovaným způsobem a relační databáze by si stále byla schopna vzájemně rozumět. JPA je odpovědí na tuto výzvu a poskytuje mechanismus k vytvoření fungujícího řešení mezi těmito dvěma.
Vztah k mapování objektů
Java programy komunikují s relačními databázemi pomocí JDBC (Připojení k databázi Java ) API. Ovladač JDBC je klíčem ke konektivitě a umožňuje programu Java manipulovat s databází pomocí rozhraní JDBC API. Jakmile je spojení navázáno, Java program spustí SQL dotazy ve formě String s pro komunikaci operací vytváření, vkládání, aktualizace a odstraňování. To je dostatečné pro všechny praktické účely, ale nepohodlné z pohledu programátora Java. Co když lze strukturu relačních tabulek přemodelovat na čisté třídy Java a pak s nimi můžete pracovat obvyklým objektově orientovaným způsobem? Struktura relační tabulky je logickou reprezentací dat v tabulkové formě. Tabulky se skládají ze sloupců popisujících atributy entit a řádky jsou kolekce entit. Například tabulka ZAMĚSTNANEC může obsahovat následující entity s jejich atributy.
| Emp_number | Jméno | číslo_oddělení | Plat | Místo |
| 112233 | Petře | 123 | 1200 | LA |
| 112244 | Ray | 234 | 1300 | NY |
| 112255 | Sandip | 123 | 1400 | NJ |
| 112266 | Kalpana | 234 | 1100 | LA |
Řádky jsou jedinečné podle primárního klíče (emp_number) v rámci tabulky; to umožňuje rychlé vyhledávání. Tabulka může souviset s jednou nebo více tabulkami pomocí nějakého klíče, jako je cizí klíč (dept_no), který se vztahuje k ekvivalentnímu řádku v jiné tabulce.
Podle specifikace Java Persistence 2.1 JPA přidává podporu pro generování schémat, metody konverze typů, použití grafu entit v dotazech a operaci hledání, nesynchronizovaný kontext persistence, vyvolání uložené procedury a vkládání do tříd posluchačů entit. Zahrnuje také vylepšení dotazovacího jazyka Java Persistence, rozhraní Criteria API a mapování nativních dotazů.
Stručně řečeno, dělá vše pro to, aby navodil iluzi, že při práci s relačními databázemi neexistuje žádná procedurální část a vše je objektově orientované.
Implementace JPA
JPA popisuje správu relačních dat v aplikaci Java. Je to specifikace a existuje řada jejích implementací. Některé populární implementace jsou Hibernate, EclipseLink a Apache OpenJPA. JPA definuje metadata prostřednictvím anotací v třídách Java nebo prostřednictvím konfiguračních souborů XML. K popisu metadat však můžeme použít jak XML, tak anotaci. V takovém případě konfigurace XML přepíše anotace. To je rozumné, protože anotace jsou psány pomocí kódu Java, zatímco konfigurační soubory XML jsou vůči kódu Java externí. Proto je třeba později, pokud vůbec nějaké, provést změny v metadatech; v případě konfigurace založené na anotacích vyžaduje přímý přístup ke kódu Java. To nemusí být vždy možné. V takovém případě můžeme zapsat novou nebo změněnou konfiguraci metadat do XML souboru bez jakéhokoli náznaku změny původního kódu a přesto mít požadovaný efekt. To je výhoda použití konfigurace XML. Konfigurace založená na anotacích je však pohodlnější a mezi programátory je oblíbenou volbou.
- Hibernace je populární a nejpokročilejší ze všech implementací JPA díky Red Hat. Používá vlastní vylepšení a přidané funkce, které lze použít navíc k implementaci JPA. Má větší komunitu uživatelů a je dobře zdokumentován. Některé z dalších proprietárních funkcí jsou podpora pro multi-tenancy, spojování nepřidružených entit v dotazech, správa časových razítek a tak dále.
- EclipseLink je založen na TopLink a je referenční implementací verzí JPA. Poskytuje standardní funkce JPA kromě některých zajímavých proprietárních funkcí, jako je podpora multi-tenancy, zpracování událostí změny databáze a tak dále.
Použití JPA v programu Java SE
Chcete-li použít JPA v programu Java, potřebujete poskytovatele JPA, jako je Hibernate nebo EclipseLink, nebo jakoukoli jinou knihovnu. Také potřebujete ovladač JDBC, který se připojuje ke konkrétní relační databázi. Například v následujícím kódu jsme použili následující knihovny:
- Poskytovatel: EclipseLink
- Ovladač JDBC: Ovladač JDBC pro MySQL (Connector/J)
Vytvoříme vztah mezi dvěma tabulkami – Zaměstnanec a Oddělení – jako jedna ku jedné a jedna k mnoha, jak je znázorněno na následujícím diagramu EER (viz obrázek 1).
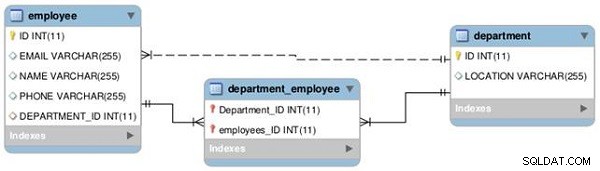
Obrázek 1: Vztahy tabulek
zaměstnanec tabulka je mapována na třídu entity pomocí anotace takto:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
A oddělení tabulka je mapována na třídu entity následovně:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
Konfigurační soubor persistence.xml , je vytvořen v META-INF adresář. Tento soubor obsahuje konfiguraci připojení, jako je použitý ovladač JDBC, uživatelské jméno a heslo pro přístup k databázi a další relevantní informace požadované poskytovatelem JPA k navázání připojení k databázi.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Entity samy nevydrží. Logika musí být použita k manipulaci s entitami za účelem řízení jejich trvalého životního cyklu. EntityManager rozhraní poskytované JPA umožňuje aplikaci spravovat a vyhledávat entity v relační databázi. Objekt dotazu vytvoříme pomocí EntityManager komunikovat s databází. Chcete-li získat EntityManager pro danou databázi použijeme objekt, který implementuje EntityManagerFactory rozhraní. Je zde statický metoda s názvem createEntityManagerFactory , v Perzistence třída, která vrací EntityManagerFactory pro jednotku perzistence zadanou jako řetězec argument. V následující základní implementaci jsme implementovali logiku.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Nyní jsme připraveni vytvořit hlavní rozhraní aplikace. Zde jsme z důvodu jednoduchosti a prostorových omezení implementovali pouze operaci vkládání.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Poznámka: Podrobné informace o rozhraních API použitých v předchozím kódu naleznete v příslušné dokumentaci rozhraní Java API. |
Závěr
Jak by mělo být zřejmé, základní terminologie kontextu JPA a Persistence je rozsáhlejší než zde uvedený pohled, ale začít rychlým přehledem je lepší než dlouhý složitý špinavý kód a jejich koncepční detaily. Pokud máte malé zkušenosti s programováním v základním JDBC, nepochybně oceníte, jak vám JPA může zjednodušit život. Postupně se do JPA ponoříme hlouběji, jak budeme pokračovat v nadcházejících článcích.