V nedávném tipu jsem popsal scénář, kdy se zdálo, že instance SQL Server 2016 zápasí s časy kontrolních bodů. Protokol chyb byl naplněn alarmujícím počtem položek FlushCache, jako je tento:
FlushCache: cleaned up 394031 bufs with 282252 writes in 65544 ms (avoided 21 new dirty bufs) for db 19:0
average writes per second: 4306.30 writes/sec
average throughput: 46.96 MB/sec, I/O saturation: 53644, context switches 101117
last target outstanding: 639360, avgWriteLatency 1 Z tohoto problému jsem byl trochu zmatený, protože systém rozhodně nebyl žádný flákač – spousta jader, 3 TB paměti a úložiště XtremIO. A žádná z těchto zpráv FlushCache nebyla nikdy spárována s výmluvnými 15 sekundovými I/O varováními v protokolu chyb. Přesto, když tam naskládáte spoustu databází s vysokými transakcemi, může se zpracování kontrolních bodů pěkně zpomalit. Ani ne tak kvůli přímému I/O, ale spíše kvůli většímu usmíření, které je třeba provést s obrovským počtem špinavých stránek (nejen z zavázaných transakce) rozptýlené v tak velkém množství paměti a potenciálně čekající na lazywriter (protože pro celou instanci existuje pouze jedna).
Rychle jsem si „osvěžil“ několik velmi cenných příspěvků:
- Jak fungují kontrolní body a co se zaznamenává
- Kontrolní body databáze (SQL Server)
- Co dělá kontrolní bod pro tempdb?
- Mýtus SQL Server DBA denně:(15/30) kontrolní bod zapisuje pouze stránky z potvrzených transakcí
- Zprávy FlushCache nemusí být skutečným zablokováním IO
- Nepřímý kontrolní bod a tempdb – dobrý, špatný a neúnosný plánovač
- Změňte cílovou dobu obnovení databáze
- Jak to funguje:Kdy je do protokolu chyb serveru SQL Server přidána zpráva FlushCache?
- Změny v chování kontrolních bodů SQL Server 2016
- Cílový interval obnovy a nepřímý kontrolní bod – nová výchozí hodnota 60 sekund v SQL Server 2016
- SQL 2016 – prostě běží rychleji:Nepřímý kontrolní bod výchozí
- SQL Server:velká RAM a DB Checkpointing
Rychle jsem se rozhodl, že chci sledovat trvání kontrolních bodů pro několik z těchto problematických databází, před a po změně jejich cílového intervalu obnovy z 0 (starý způsob) na 60 sekund (nový způsob). V lednu jsem si vypůjčil relaci Extended Events od kamarádky a kolegyně z Kanady Hannah Vernon:
CREATE EVENT SESSION CheckpointTracking ON SERVER
ADD EVENT sqlserver.checkpoint_begin
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
, ADD EVENT sqlserver.checkpoint_end
(
WHERE
(
sqlserver.database_id = 19 -- db4
OR sqlserver.database_id = 78 -- db2
...
)
)
ADD TARGET package0.event_file
(
SET filename = N'L:\SQL\CP\CheckPointTracking.xel',
max_file_size = 50, -- MB
max_rollover_files = 50
)
WITH
(
MAX_MEMORY = 4096 KB,
MAX_DISPATCH_LATENCY = 30 SECONDS,
TRACK_CAUSALITY = ON,
STARTUP_STATE = ON
);
GO
ALTER EVENT SESSION CheckpointTracking ON SERVER
STATE = START; Označil jsem čas, kdy jsem každou databázi změnil, a poté analyzoval výsledky z dat Extended Events pomocí dotazu zveřejněného v původním tipu. Výsledky ukázaly, že po změně na nepřímé kontrolní body každá databáze přešla z kontrolních bodů v průměru 30 sekund na kontrolní body s průměrem kratším než desetina sekundy (a ve většině případů také mnohem méně kontrolních bodů). Z této grafiky lze vybalit mnoho, ale toto jsou nezpracovaná data, která jsem použil k prezentaci svého argumentu (kliknutím zvětšíte):
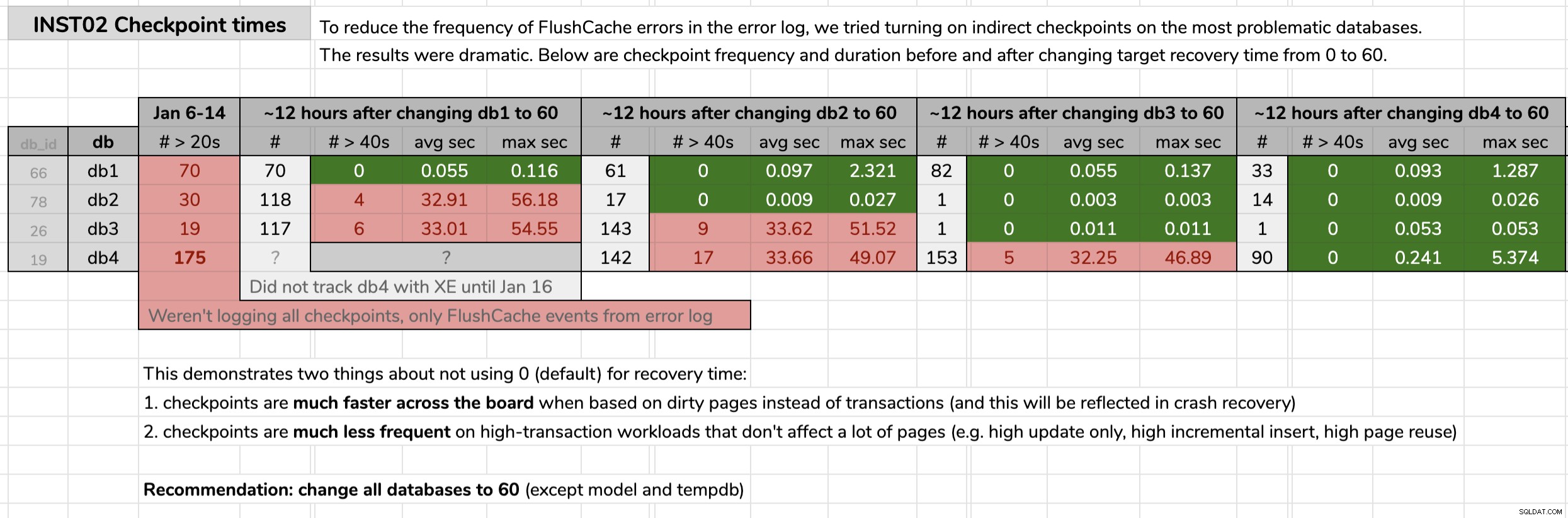 Moje důkazy
Moje důkazy
Jakmile jsem dokázal svůj názor napříč těmito problematickými databázemi, dostal jsem zelenou k implementaci do všech našich uživatelských databází v našem prostředí. Nejprve jsem ve vývoji a poté v produkci spustil následující pomocí dotazu CMS, abych získal měřidlo, o kolika databázích jsme mluvili:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += CASE
WHEN (ag.role = N'PRIMARY' AND ag.ag_status = N'READ_WRITE') OR ag.role IS NULL THEN N'
ALTER DATABASE ' + QUOTENAME(d.name) + N' SET TARGET_RECOVERY_TIME = 60 SECONDS;'
ELSE N'
PRINT N''-- fix ' + QUOTENAME(d.name) + N' on Primary.'';'
END
FROM sys.databases AS d
OUTER APPLY
(
SELECT role = s.role_desc,
ag_status = DATABASEPROPERTYEX(c.database_name, N'Updateability')
FROM sys.dm_hadr_availability_replica_states AS s
INNER JOIN sys.availability_databases_cluster AS c
ON s.group_id = c.group_id
AND d.name = c.database_name
WHERE s.is_local = 1
) AS ag
WHERE d.target_recovery_time_in_seconds <> 60
AND d.database_id > 4
AND d.[state] = 0
AND d.is_in_standby = 0
AND d.is_read_only = 0;
SELECT DatabaseCount = @@ROWCOUNT, Version = @@VERSION, cmd = @sql;
--EXEC sys.sp_executesql @sql; Několik poznámek k dotazu:
database_id > 4
Nechtěl jsem se dotknoutmastervůbec a nechtěl jsem měnittempdbale protože nejsme na nejnovější SQL Server 2017 CU (viz KB #4497928 z jednoho důvodu, že podrobnosti jsou důležité). To druhé vylučujemodel, protože změna modelu by ovlivnilatempdbpři příštím převzetí služeb při selhání / restartu. Mohl jsem změnitmsdba možná se k tomu někdy vrátím, ale zaměřil jsem se zde na databáze uživatelů.
[state] / is_read_only / is_in_standby
Musíme se ujistit, že databáze, které se snažíme změnit, jsou online a nejsou pouze pro čtení (narazil jsem na jednu, která byla aktuálně nastavena pouze na čtení a k té se budu muset vrátit později).
OUTER APPLY (...)
Chceme omezit naše akce na databáze, které jsou buď primární v AG, nebo vůbec nejsou v AG (a také musíme počítat s distribuovanými AG, kde můžeme být primární a místní, ale stále nemůžeme být zapisovatelní) . Pokud náhodou spustíte kontrolu na sekundárním zařízení, nemůžete tam problém vyřešit, ale přesto byste na to měli dostat varování. Děkujeme Eriku Darlingovi za pomoc s touto logikou a Taylor Martell za motivující vylepšení.
- Pokud máte instance se staršími verzemi, jako je SQL Server 2008 R2 (jednu jsem našel!), budete to muset trochu upravit, protože
target_recovery_time_in_secondssloupec tam neexistuje. V jednom případě jsem musel použít dynamické SQL, abych to obešel, ale také jste mohli dočasně přesunout nebo odstranit tam, kde tyto instance spadají do vaší hierarchie CMS. Také byste nemohli být líní jako já a spustit kód v Powershell namísto okna dotazu CMS, kde byste mohli snadno odfiltrovat databáze s libovolným počtem vlastností, než narazíte na problémy při kompilaci.
Ve výrobě bylo 102 instancí (asi polovina) a celkem 1 590 databází používajících staré nastavení. Všechno bylo na SQL Server 2017, tak proč bylo toto nastavení tak rozšířené? Protože byly vytvořeny předtím, než se nepřímé kontrolní body staly výchozím nastavením v SQL Server 2016. Zde je ukázka výsledků:
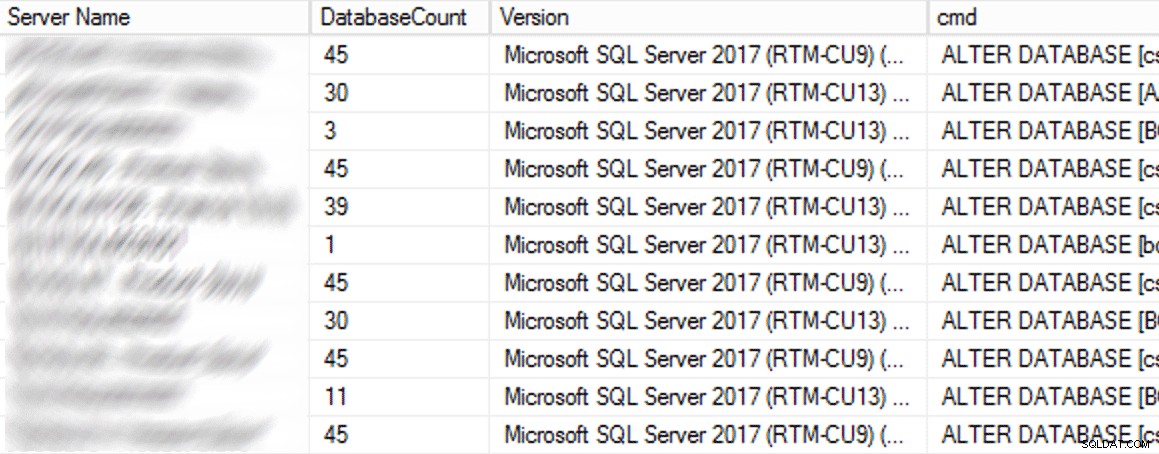 Částečné výsledky z dotazu CMS.
Částečné výsledky z dotazu CMS.
Poté jsem znovu spustil dotaz CMS, tentokrát s sys.sp_executesql bez komentáře. Trvalo to asi 12 minut, než bylo spuštěno ve všech 1 590 databázích. Během hodiny jsem již dostával zprávy o lidech, kteří zaznamenali významný pokles CPU na některých rušnějších instancích.
Ještě mám co dělat. Potřebuji například otestovat potenciální dopad na tempdb a zda má náš případ použití nějakou váhu pro hororové příběhy, které jsem slyšel. A musíme se ujistit, že nastavení 60 sekund je součástí naší automatizace a všech požadavků na vytvoření databáze, zejména těch, které jsou skriptovány nebo obnovovány ze záloh.