Bod zlomu je termín, který jsem poprvé slyšel použít guru ladění výkonu SQL Serveru a dlouholetá členka poradního výboru SentryOne Kimberly Tripp – má o něm skvělou sérii blogů. Bod zvratu je práh, při kterém se plán dotazů „překlopí“ od hledání nepokrývajícího neshlukovaného indexu ke skenování seskupeného indexu nebo haldy. Základní vzorec, který není pevným pravidlem, protože existují různé jiné ovlivňující faktory, je tento:
- Ke skenování seskupeného indexu (nebo tabulky) často dojde, když odhadované řádky překročí 33 % počtu stránek v tabulce
- Pokud je odhadovaný počet řádků pod 25 % stránek v tabulce, často dochází k vyhledávání neshlukovaného vyhledávání plus klíče.
- V rozmezí 25 % až 33 % to může být oběma směry
Všimněte si, že existují další „body zlomu“ optimalizátoru, například při krytí index překlopí z hledání na skenování nebo když dotaz půjde paralelně, ale ten, na který se zaměřujeme, je nepokrývající neshlukovaný index scénář, protože bývá nejběžnější – je těžké pokrýt každý dotaz! Je to také potenciálně nejnebezpečnější pro výkon, a když uslyšíte někoho odkazovat na bod zlomu indexu SQL Serveru, obvykle myslí toto.
Bod zvratu v předchozích verzích Plan Explorer
Plan Explorer již dříve ukázal čistý efekt bodu zvratu, když je ve hře sniffování parametrů v Analýze indexu konkrétně prostřednictvím Odhad (imated) Operation řádku v Parametry podokno:
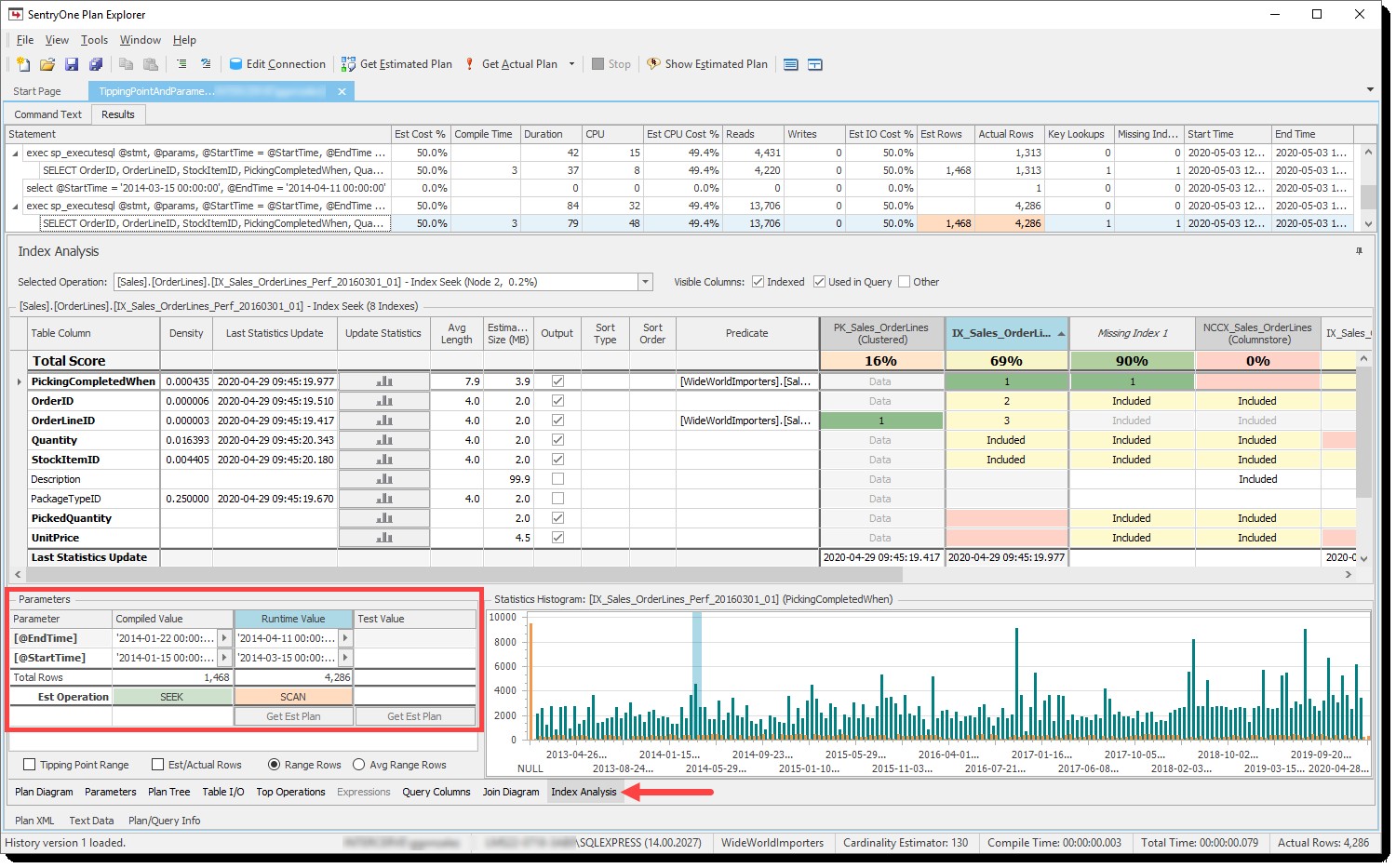 Odhadovaná operace pro kompilované a runtime parametry na základě počtu řádků
Odhadovaná operace pro kompilované a runtime parametry na základě počtu řádků
Pokud jste ještě neprozkoumali modul Indexová analýza, doporučuji vám tak učinit. Přestože diagram plánu a další funkce Průzkumníka plánu jsou skvělé, upřímně řečeno, analýza indexů je místo, kde byste měli trávit většinu času při ladění dotazů a indexů. Podívejte se na hloubkový přehled funkcí a scénářů od Aarona Bertranda zde a na skvělý průvodce indexem od Devona Leanna Wilsona zde.
V zákulisí provádíme výpočet bodu zlomu a předpovídáme operaci indexu (vyhledávání nebo skenování) na základě odhadovaných řádků a počtu stránek v tabulce pro kompilované i runtime parametry a poté barevně označíme přidružené buňky tak, aby můžete rychle zjistit, zda se shodují. Pokud ne, jako ve výše uvedeném příkladu, může to být silným indikátorem, že máte problém s čicháním parametrů.
Histogram statistik graf odráží rozložení hodnot pro úvodní klíč indexu pomocí sloupců pro stejné řádky (oranžová) a rozsah řádků (zelenomodrá). Toto jsou stejné hodnoty, které získáte z DBCC SHOW_STATISTICS nebo sys.dm_db_stats_histogram . Části distribuce, které jsou ovlivněny jak kompilovanými, tak runtime parametry, jsou zvýrazněny, abyste získali přibližnou představu o tom, kolik řádků se týká každého z nich. Jednoduše vyberte buď Zkompilovaná hodnota nebo Hodnota za běhu sloupec pro zobrazení vybraného rozsahu:
 Histogramový graf zobrazující rozsah zasažený parametry běhového prostředí
Histogramový graf zobrazující rozsah zasažený parametry běhového prostředí
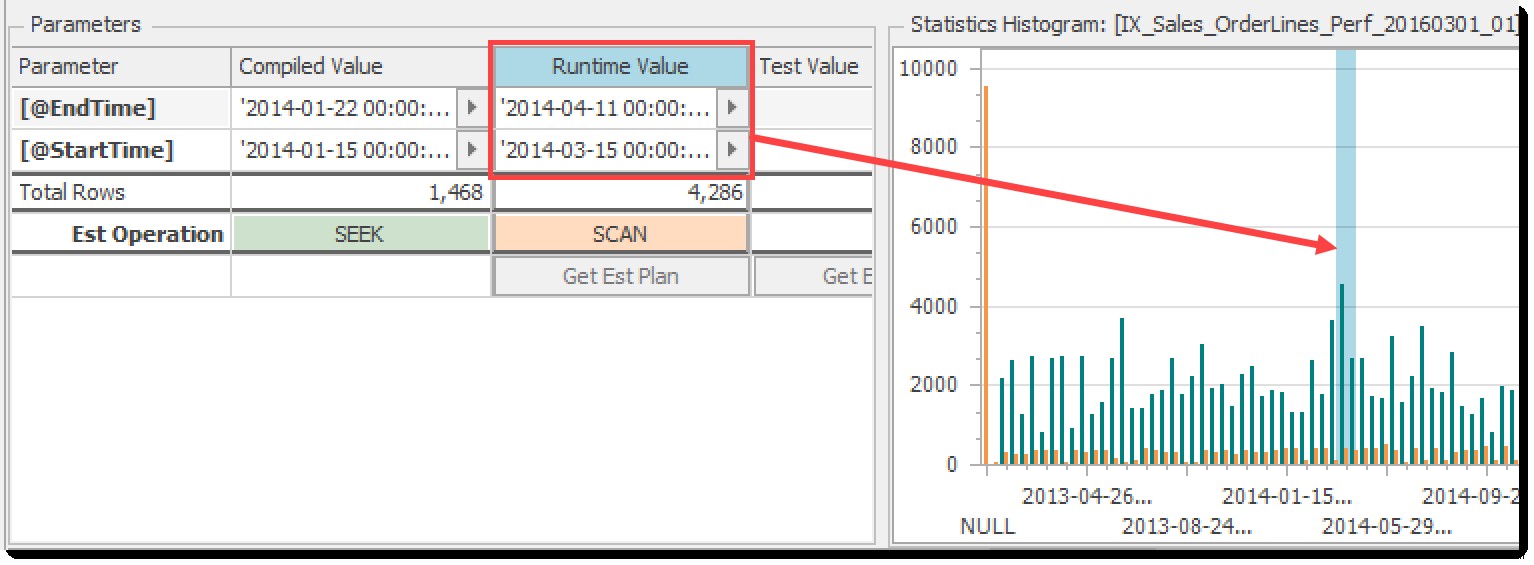
Nové ovládací prvky a vizuální prvky
Výše uvedené funkce byly hezké, ale na chvíli jsem měl pocit, že bychom mohli udělat víc, abychom věci objasnili. Takže v nejnovější verzi Plan Explorer (2020.8.7) má spodní část podokna Parametry nějaké nové ovládací prvky s přidruženými vizuálními prvky na grafu histogramu:
 Nové ovládací prvky pro vizuály histogramu
Nové ovládací prvky pro vizuály histogramu
Všimněte si, že histogram zobrazený ve výchozím nastavení je pro index použitý dotazem pro přístup k vybrané tabulce, ale můžete kliknout na jakékoli jiné záhlaví indexu nebo sloupec tabulky v mřížce a zobrazit jiný histogram.
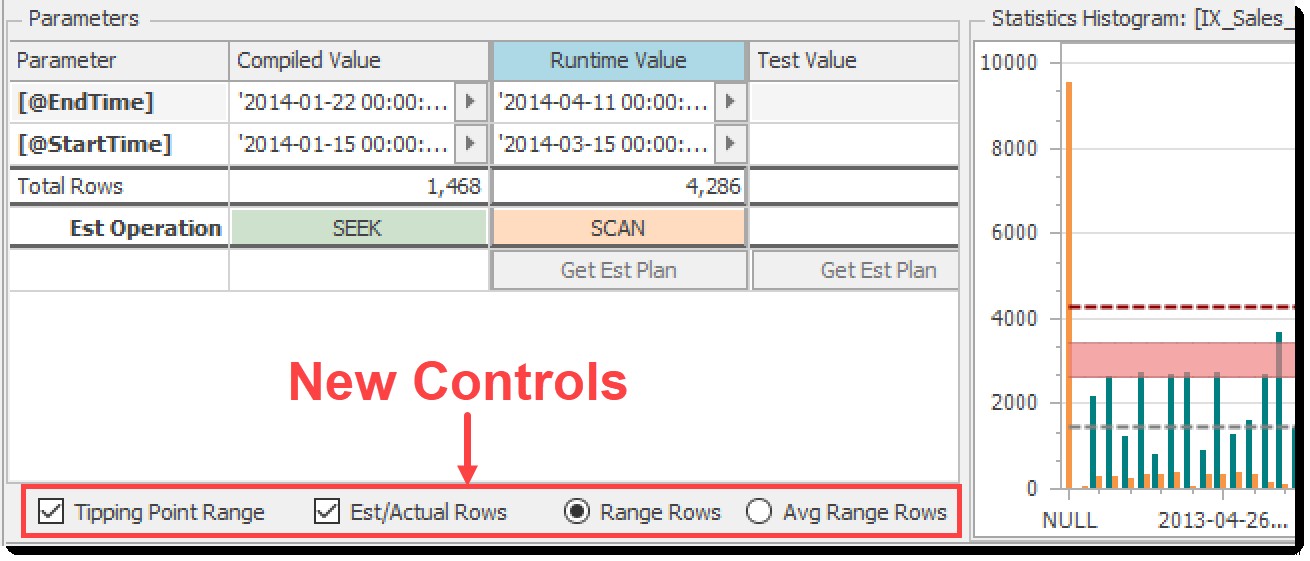
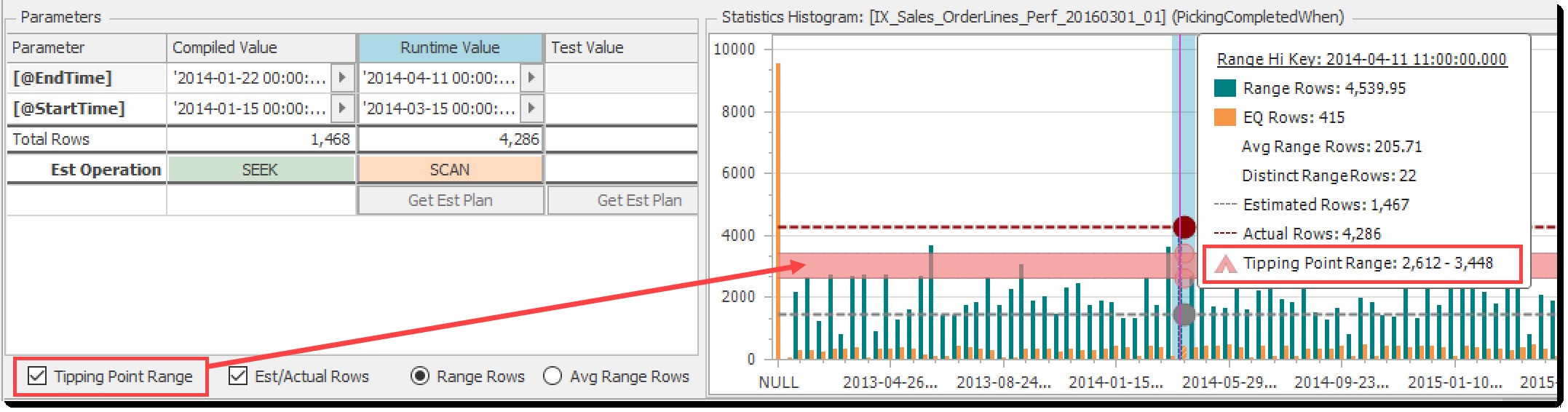
Rozsah bodu zvratu
Rozsah bodu zvratu zaškrtávací políčko přepíná světle červený pruh zobrazený v grafu histogramu:
 Přepnout pro pásmo zvratného bodu
Přepnout pro pásmo zvratného bodu
Pokud jsou odhadované řádky pod tímto rozsahem, optimalizátor upřednostní vyhledávání + vyhledávání a nad ním prohledávání tabulky. Uvnitř rozsahu může kdokoli hádat.
Odhad (implicitní)/skutečné řádky
Odhad/skutečné řádky checkbox přepíná zobrazení odhadovaných řádků (z kompilovaných parametrů) a skutečných řádků (z runtime parametrů). Šipky v níže uvedené tabulce znázorňují vztah mezi tímto ovládacím prvkem a souvisejícími prvky:
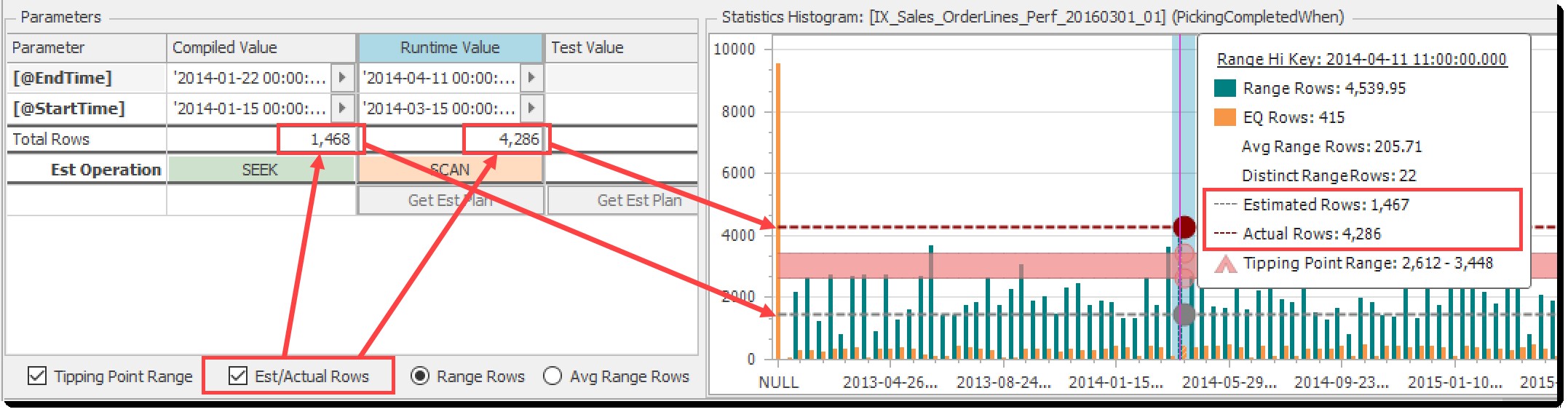 Přepnout na odhadované a skutečné řádky v grafu histogramu
Přepnout na odhadované a skutečné řádky v grafu histogramu
V tomto příkladu je jasné, že odhadované řádky jsou pod bodem zvratu a skutečné vrácené řádky jsou nad ním, což se odráží v rozdílu mezi uvedenými odhadovanými a skutečnými operacemi (Seek vs Scan). Toto je klasické čichání parametrů, ilustrované!
V budoucím příspěvku se budu věnovat tomu, jak to souvisí s tím, co vidíte na schématu plánu a mřížce prohlášení. Mezitím je zde soubor relace Plan Explorer, který obsahuje tento příklad (sniffování parametrů vyhledávání po skenování) a také příklad skenování za účelem hledání. Oba využívají rozšířenou databázi WideWorldImporters.
Řádky rozsahu nebo řádky průměrného rozsahu
Předchozí verze Průzkumníka plánů skládaly stejné řádky a řádky rozsahu do jednoho sloupce, aby představovaly celkový počet řádků v segmentu histogramu. To funguje dobře, když máte predikát nerovnosti nebo rozsahu, jak je uvedeno výše, ale pro predikáty rovnosti to nedává moc smysl. To, co opravdu chcete vidět, jsou řádky průměrného rozsahu, protože to je to, co optimalizátor použije pro odhad. Bohužel nebyl způsob, jak to získat.
V novém histogramu Průzkumníka plánů nyní namísto skládaných sloupců používáme seskupené sloupce se stejnými řádky a řádky rozsahu vedle sebe a vy pomocí Řádky rozsahu / Řádky průměrného rozsahu určete, zda se mají podle potřeby zobrazovat řádky celkového nebo průměrného rozsahu. volič. Více o tom již brzy…
Zabalení
Z těchto nových funkcí jsem opravdu nadšený a doufám, že je pro vás budou užitečné. Vyzkoušejte je stažením nového Průzkumníka plánů. Toto byl pouze stručný úvod a těším se, že zde pokryjem několik různých scénářů. Jako vždy nám dejte vědět, co si myslíte!