Diskuse o preferenčním rozdílu mezi FOREACH a FOR není nová. Všichni víme, že FOREACH je pomalejší, ale ne všichni vědí proč.
Když jsem se začal učit .NET, jeden člověk mi řekl, že FOREACH je dvakrát pomalejší než FOR. Řekl to bez jakéhokoli důvodu. Bral jsem to jako samozřejmost.
Nakonec jsem se rozhodl prozkoumat rozdíl ve výkonu smyček FOREACH a FOR a napsat tento článek, abych diskutoval o nuancích.
Podívejme se na následující kód:
foreach (var item in Enumerable.Range(0, 128))
{
Console.WriteLine(item);
}FOREACH je syntaktický cukr. V tomto konkrétním případě jej kompilátor převede na následující kód:
IEnumerator<int> enumerator = Enumerable.Range(0, 128).GetEnumerator();
try
{
while (enumerator.MoveNext())
{
int item = enumerator.Current;
Console.WriteLine(item);
}
}
finally
{
if (enumerator != null)
{
enumerator.Dispose();
}
}Když to víme, můžeme předpokládat důvod, proč je FOREACH pomalejší než FOR:
- Vytváří se nový objekt. Říká se tomu Stvořitel.
- Metoda MoveNext je volána při každé iteraci.
- Každá iterace přistupuje k vlastnosti Current.
A je to! Není to však všechno tak snadné, jak to zní.
Naštěstí (nebo bohužel), C#/CLR může provádět optimalizace za běhu. Výhodou je, že kód funguje rychleji. Kon – vývojáři by si měli být vědomi těchto optimalizací.
Pole je typ hluboce integrovaný do CLR a CLR poskytuje řadu optimalizací pro tento typ. Smyčka FOREACH je iterovatelná entita, což je klíčový aspekt výkonu. Později v článku probereme, jak iterovat pole a seznamy pomocí statické metody Array.ForEach a metody List.ForEach.
Testovací metody
static double ArrayForWithoutOptimization(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < array.Length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForWithOptimization(int[] array)
{
int length = array.Length;
int sum = 0;
var watch = Stopwatch.StartNew();
for (int i = 0; i < length; i++)
sum += array[i];
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForeach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
foreach (var item in array)
sum += item;
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}
static double ArrayForEach(int[] array)
{
int sum = 0;
var watch = Stopwatch.StartNew();
Array.ForEach(array, i => { sum += i; });
watch.Stop();
return watch.Elapsed.TotalMilliseconds;
}Podmínky testu:
- Možnost „Optimalizovat kód“ je zapnutá.
- Počet prvků se rovná 100 000 000 (v poli i seznamu).
- Specifikace PC:Intel Core i-5 a 8 GB RAM.
Pole
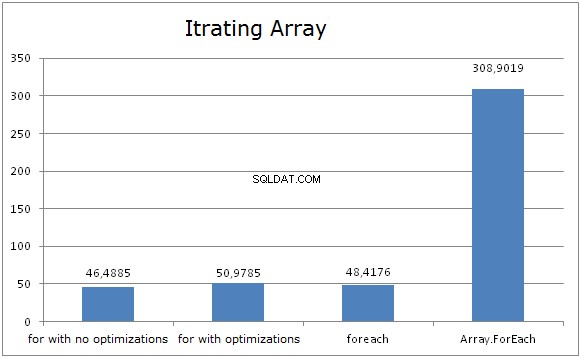
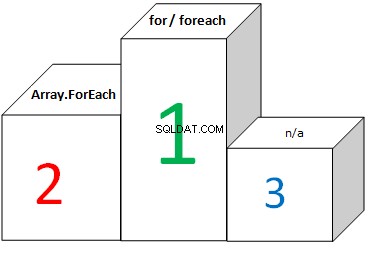
Diagram ukazuje, že FOR a FOREACH tráví stejné množství času při iteraci přes pole. A je to proto, že optimalizace CLR převádí FOREACH na FOR a používá délku pole jako maximální iterační hranici. Nezáleží na tom, zda je délka pole kešována nebo ne (při použití FOR), výsledek je téměř stejný.
Může to znít divně, ale ukládání délky pole do mezipaměti může ovlivnit výkon. Při použití pole .Délka jako hranice iterace, JIT testuje index, aby se dostal do pravého okraje za cyklem. Tato kontrola se provádí pouze jednou.
Je velmi snadné tuto optimalizaci zničit. Případ, kdy je proměnná uložena do mezipaměti, je stěží optimalizován.
Array.foreach předvedl nejhorší výsledky. Jeho implementace je poměrně jednoduchá:
public static void ForEach<T>(T[] array, Action<T> action)
{
for (int index = 0; index < array.Length; ++index)
action(array[index]);
}Tak proč to běží tak pomalu? Používá FOR pod kapotou. Důvodem je volání AKČNÍho delegáta. Ve skutečnosti je při každé iteraci volána metoda, což snižuje výkon. Navíc delegáti nejsou svoláváni tak rychle, jak bychom chtěli.
Seznamy

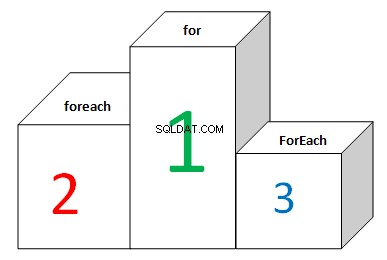
Výsledek je úplně jiný. Při iteraci seznamů FOR a FOREACH ukazují různé výsledky. Neexistuje žádná optimalizace. FOR (s ukládáním délky seznamu do mezipaměti) ukazuje nejlepší výsledek, zatímco FOREACH je více než 2krát pomalejší. Je to proto, že se pod kapotou zabývá MoveNext a Current. List.ForEach i Array.ForEach ukazují nejhorší výsledek. Delegáti jsou vždy voláni virtuálně. Implementace této metody vypadá takto:
public void ForEach(Action<T> action)
{
int num = this._version;
for (int index = 0; index < this._size && num == this._version; ++index)
action(this._items[index]);
if (num == this._version)
return;
ThrowHelper.ThrowInvalidOperationException(ExceptionResource.InvalidOperation_EnumFailedVersion);
}Každá iterace volá delegáta akce. Také kontroluje, zda se seznam změnil, a pokud ano, vyvolá výjimku.
List interně používá model založený na poli a metoda ForEach používá k iteraci index pole, což je výrazně rychlejší než použití indexeru.
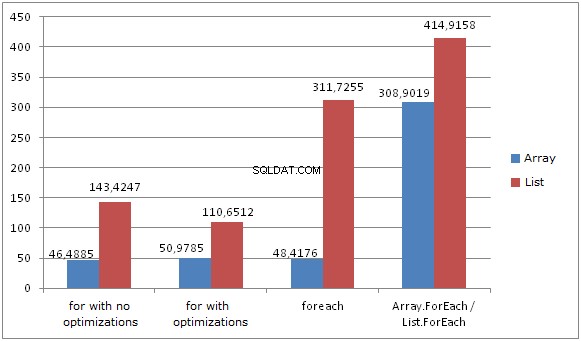
Konkrétní čísla
- Smyčka FOR bez ukládání délky do mezipaměti a FOREACH pracují na polích o něco rychleji než FOR s ukládáním délky do mezipaměti.
- Pole.Foreach výkon je přibližně 6krát pomalejší než výkon FOR / FOREACH.
- Smyčka FOR bez ukládání délky do mezipaměti funguje na seznamech 3krát pomaleji ve srovnání s poli.
- Smyčka FOR s ukládáním délky do mezipaměti funguje na seznamech 2krát pomaleji ve srovnání s poli.
- Smyčka FOREACH funguje na seznamech 6krát pomaleji ve srovnání s poli.
Zde je žebříček seznamů:
A pro pole:
Závěr
Toto vyšetřování se mi opravdu líbilo, zejména proces psaní, a doufám, že se vám to líbilo také. Jak se ukázalo, FOREACH je rychlejší na polích než FOR s délkovým chasingem. Ve strukturách seznamu je FOREACH pomalejší než FOR.
Kód vypadá lépe při použití FOREACH a moderní procesory jej umožňují. Pokud však potřebujete vysoce optimalizovat svou kódovou základnu, je lepší použít FOR.
Co myslíte, která smyčka běží rychleji, FOR nebo FOREACH?