[ Část 1 | Část 2 | Část 3 | Část 4 ]
Halloweenský problém může mít řadu důležitých dopadů na prováděcí plány. V této závěrečné části seriálu se podíváme na triky, které může optimalizátor použít, aby se vyhnul Halloweenskému problému při sestavování plánů pro dotazy, které přidávají, mění nebo mažou data.
Pozadí
V průběhu let byla vyzkoušena řada přístupů, jak se Halloweenskému problému vyhnout. Jednou z prvních technik bylo jednoduše se vyhnout vytváření plánů provádění, které by zahrnovaly čtení a zápis do klíčů stejného indexu. To nebylo příliš úspěšné z hlediska výkonu, v neposlední řadě proto, že to často znamenalo skenování základní tabulky namísto použití selektivního neshlukovaného indexu k nalezení řádků, které se mají změnit.
Druhý přístup spočíval v úplném oddělení fází čtení a zápisu aktualizačního dotazu tak, že se nejprve nalezly všechny řádky, které se kvalifikovaly pro změnu, někde se uložily a teprve potom se změny začaly provádět. V SQL Server toto úplné oddělení fází je dosaženo umístěním dnes již známé Eager Table Spool na vstupní stranu operátoru aktualizace:
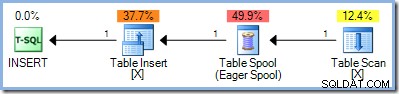
Spool čte všechny řádky ze svého vstupu a ukládá je do skryté tempdb pracovní stůl. Stránky této pracovní tabulky mohou zůstat v paměti nebo mohou vyžadovat fyzický diskový prostor, pokud je sada řádků velká nebo pokud je server pod tlakem paměti.
Úplné oddělení fází může být méně než ideální, protože obecně chceme spustit co největší část plánu jako potrubí, kde je každý řádek plně zpracován před přechodem na další. Pipelining má mnoho výhod, včetně toho, že se vyhnete nutnosti dočasného skladování a dotknete se každého řádku pouze jednou.
Optimalizátor serveru SQL
SQL Server jde mnohem dále než dvě dosud popsané techniky, i když samozřejmě obě zahrnuje jako možnosti. Optimalizátor dotazů SQL Server detekuje dotazy, které vyžadují ochranu Halloween, a určuje, kolik je vyžadována ochrana a používá nákladově založené analýzu, abychom našli nejlevnější způsob poskytování této ochrany.
Nejjednodušší způsob, jak pochopit tento aspekt Halloweenského problému, je podívat se na několik příkladů. V následujících částech je úkolem přidat rozsah čísel do existující tabulky – ale pouze čísla, která ještě neexistují:
CREATE TABLE dbo.Test( pk integer NOT NULL, CONSTRAINT PK_Test PRIMARY KEY CLUSTERED (pk));
5 řádků
První příklad zpracovává rozsah čísel od 1 do 5 včetně:
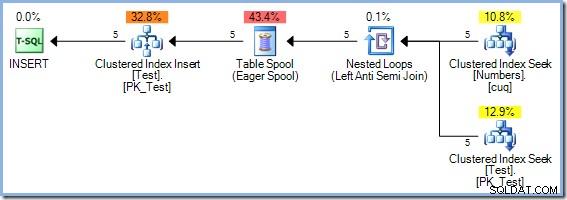
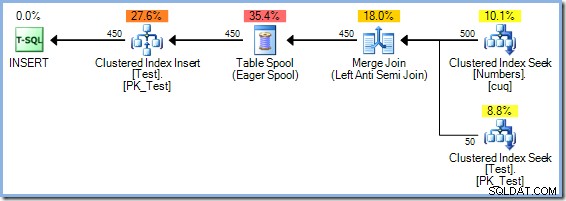
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n MEZI 1 A 5 A NEEXISTUJE ( SELECT NULL FROM dbo.Test AS t WHERE t.pk =Num.n );Vzhledem k tomu, že tento dotaz čte z klíčů stejného indexu v tabulce Test a zapisuje do nich, plán provádění vyžaduje ochranu Halloween. V tomto případě optimalizátor používá úplnou separaci fází pomocí Eager Table Spool:
50 řádků
S pěti řádky nyní v testovací tabulce spustíme znovu stejný dotaz a změníme
WHEREklauzule pro zpracování čísel od 1 do 50 včetně :
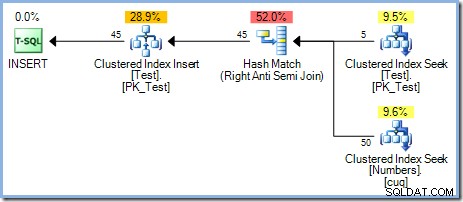
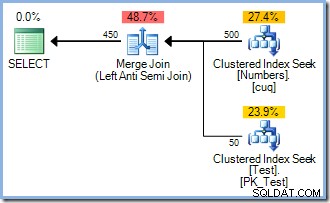
Tento plán poskytuje správnou ochranu proti Halloweenskému problému, ale neobsahuje Eager Table Spool. Optimalizátor rozpozná, že operátor spojení Hash Match blokuje vstup sestavení; všechny řádky jsou načteny do hashovací tabulky předtím, než operátor zahájí proces párování pomocí řádků ze vstupu sondy. V důsledku toho tento plán přirozeně poskytuje oddělení fází (pouze pro testovací stůl) bez potřeby cívky.
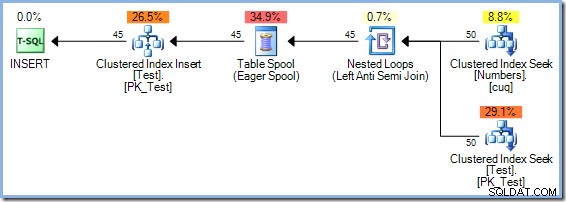
Optimalizátor zvolil plán spojení Hash Match před spojením Nested Loops zobrazeným v 5řádkovém plánu z důvodů založených na nákladech. 50řádkový plán Hash Match má celkové odhadované náklady 0,0347345 Jednotky. Můžeme vynutit dříve použitý plán Nested Loops s nápovědou, abychom viděli, proč optimalizátor nezvolil vnořené smyčky:
Tento plán má odhadovanou cenu 0,0379063 jednotek včetně cívky, o něco více než plán Hash Match.
500 řádků
S 50 řádky nyní v testovací tabulce dále zvyšujeme rozsah čísel na 500 :
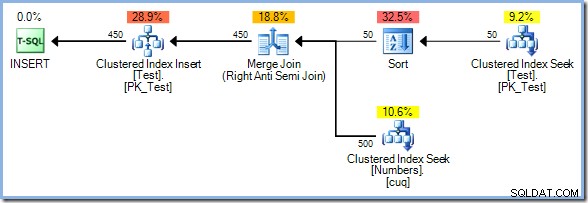
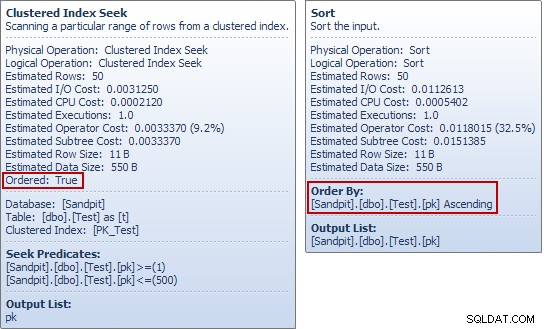
Tentokrát optimalizátor zvolí spojení Merge Join a opět zde není žádná Eager Table Spool. Operátor řazení zajišťuje v tomto plánu nezbytné oddělení fází. Plně spotřebuje svůj vstup, než vrátí první řádek (třídění nemůže vědět, který řádek seřadí jako první, dokud neuvidí všechny řádky). Optimalizátor rozhodl, že řazení 50 řádky z testovací tabulky by byly levnější než eager-spooling 450 řádky těsně před operátorem aktualizace.
Plán Sort plus Merge Join má odhadovanou cenu 0,0362708 Jednotky. Alternativy plánu Hash Match a Nested Loops vyjdou na 0,0385677 jednotek a 0,112433 jednotek.
Něco zvláštního na řazení
Pokud jste tyto příklady spouštěli pro sebe, možná jste si všimli něčeho zvláštního na posledním příkladu, zvláště pokud jste se podívali na tipy nástroje Průzkumník plánů pro hledání a řazení testovací tabulky:
Seek vytvoří uspořádaný stream pk hodnoty, tak jaký má smysl řazení ve stejném sloupci bezprostředně poté? Abychom na tuto (velmi rozumnou) otázku odpověděli, začneme tím, že se podíváme pouze na
SELECTčástINSERTdotaz:VYBERTE číslo.n Z dbo.Numbers JAKO NumWHERE Num.n MEZI 1 A 500 A NEEXISTUJE ( VYBERTE 1 Z dbo.Test AS t WHERE t.pk =Num.n )ORDER BY Num.n;Tento dotaz vytvoří níže uvedený plán provádění (s nebo bez
ORDER BYPřidal jsem k vyřešení určitých technických námitek, které byste mohli mít):
Všimněte si, že chybí operátor řazení. Proč tedy
INSERTplán zahrnuje řazení? Jednoduše, abyste se vyhnuli Halloweenskému problému. Optimalizátor považoval za provedení nadbytečné řazení (s vestavěným oddělením fází) byl nejlevnější způsob, jak provést dotaz a zaručit správné výsledky. Chytrý.Úrovně a vlastnosti halloweenské ochrany
Optimalizátor SQL Server má specifické funkce, které mu umožňují uvažovat o úrovni Halloweenské ochrany (HP) požadované v každém bodě plánu dotazů a podrobném účinku, který má každý operátor. Tyto extra funkce jsou začleněny do stejného rámce vlastností, který optimalizátor používá ke sledování stovek dalších důležitých informací během svých vyhledávacích aktivit.
Každý operátor má požadováno Vlastnost HP a doručeno majetek HP. Povinné vlastnost označuje úroveň HP potřebnou v daném bodě stromu pro správné výsledky. Doručeno vlastnost odráží HP poskytnuté aktuálním operátorem a kumulativní Efekty HP poskytované jeho podstromem.
Optimalizátor obsahuje logiku, která určuje, jak každý fyzický operátor (například výpočetní skalární) ovlivňuje úroveň HP. Prozkoumáním široké škály alternativ plánu a odmítnutím plánů, kde je dodaný HP nižší než požadovaný HP u operátora aktualizace, má optimalizátor flexibilní způsob, jak najít správné a efektivní plány, které ne vždy vyžadují Eager Table Spool.
Naplánujte změny pro ochranu Halloweenu
Viděli jsme, že optimalizátor přidal redundantní řazení pro ochranu Halloween v předchozím příkladu Merge Join. Jak si můžeme být jisti, že je to efektivnější než jednoduchá Eager Table Spool? A jak můžeme vědět, které funkce plánu aktualizací jsou k dispozici pouze pro ochranu Halloweenu?
Na obě otázky lze odpovědět (samozřejmě v testovacím prostředí) pomocí nezdokumentovaného příznaku trasování 8692 , což nutí optimalizátor používat Eager Table Spool pro ochranu Halloweenu. Připomeňme, že plán Merge Join s nadbytečným řazením měl odhadované náklady 0,0362708 jednotky pro optimalizaci magie. Můžeme to porovnat s alternativou Eager Table Spool rekompilací dotazu s povoleným příznakem trasování 8692:
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n MEZI 1 A 500 A NEEXISTUJE ( VYBERTE 1 Z dbo.Test AS t WHERE t.pk =Num.n )MOŽNOST ( QUERYTRACEON 8692);
Plán Eager Spool má odhadovanou cenu 0,0378719 jednotek (až z 0,0362708 s nadbytečným řazením). Zde uvedené rozdíly v nákladech nejsou příliš významné kvůli triviální povaze úkolu a malé velikosti řádků. Aktualizační dotazy v reálném světě se složitými stromy a větším počtem řádků často vytvářejí plány, které jsou mnohem efektivnější díky schopnosti optimalizátoru serveru SQL Server hluboce přemýšlet o Halloweenské ochraně.
Další možnosti bez zařazování
Optimální umístění blokujícího operátora v rámci plánu není jedinou strategií, kterou má optimalizátor k dispozici, aby minimalizoval náklady na poskytování ochrany proti Halloweenskému problému. Může také uvažovat o rozsahu zpracovávaných hodnot, jak ukazuje následující příklad:
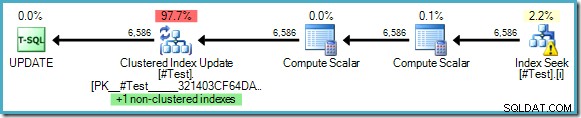
CREATE TABLE #Test( pk integer PRIMÁRNÍ KLÍČ IDENTITY, some_value integer); CREATE INDEX i ON #Test (some_value); -- Předstírejte, že tabulka má v it mnoho dat. AKTUALIZACE #TestSET some_value =10WHERE some_value =5;Plán provádění ukazuje, že není potřeba halloweenská ochrana, přestože čteme a aktualizujeme klíče společného indexu:
Optimalizátor vidí, že změna ‘nějaké_hodnoty’ z 5 na 10 nikdy nemůže způsobit, že by aktualizovaný řádek byl podruhé viděn funkcí Index Seek (která hledá pouze řádky, kde nějaká_hodnota je 5). Tato úvaha je možná pouze tam, kde jsou v dotazu použity doslovné hodnoty nebo kde dotaz specifikuje
OPTION (RECOMPILE), což umožňuje optimalizátoru načíst hodnoty parametrů pro jednorázový plán provádění.I v případě doslovných hodnot v dotazu může být optimalizátoru zabráněno v použití této logiky, pokud volba databáze
FORCED PARAMETERIZATIONjeON. V takovém případě jsou doslovné hodnoty v dotazu nahrazeny parametry a optimalizátor si již nemůže být jistý, že Halloween Protection není vyžadován (nebo nebude vyžadován, když je plán znovu použit s jinými hodnotami parametrů):
V případě, že vás zajímá, co se stane, když
FORCED PARAMETERIZATIONje povoleno a dotaz specifikujeOPTION (RECOMPILE), odpověď je taková, že optimalizátor sestaví plán pro sniffované hodnoty, a tak může použít optimalizaci. Jako vždy uOPTION (RECOMPILE), plán dotazů se specifickou hodnotou není uložen do mezipaměti pro opětovné použití.Nahoře
Tento poslední příklad ukazuje, jak
Topoperátor může odstranit potřebu Halloweenské ochrany:UPDATE TOP (1) tSET some_value +=1FROM #Test AS tWHERE some_value <=10;
Není vyžadována žádná ochrana, protože aktualizujeme pouze jeden řádek. Hledání indexu nemůže na aktualizovanou hodnotu narazit, protože kanál zpracování se zastaví, jakmile se aktualizuje první řádek. Tuto optimalizaci lze opět použít pouze v případě, že je v
TOPpoužita konstantní doslovná hodnota , nebo pokud je proměnná vracející hodnotu ‚1‘ vyčmuchána pomocíOPTION (RECOMPILE).Pokud změníme
TOP (1)v dotazu naTOP (2), optimalizátor zvolí Clustered Index Scan namísto Index Seek:
Neaktualizujeme klíče seskupeného indexu, takže tento plán nevyžaduje Halloweenskou ochranu. Vynucení použití neshlukovaného indexu s nápovědou v
TOP (2)dotaz ukazuje cenu ochrany:
Optimalizátor odhadl, že Clustered Index Scan bude levnější než tento plán (s dodatečnou Halloweenskou ochranou).
Šance a konce
Existuje několik dalších bodů, které bych chtěl uvést o ochraně Halloweenu, které dosud nenašly přirozené místo v sérii. První je otázka Halloweenské ochrany, když se používá úroveň izolace verzování řádků.
Verování řádků
SQL Server poskytuje dvě úrovně izolace,
READ COMMITTED SNAPSHOTaSNAPSHOT ISOLATIONkteré používají úložiště verzí v tempdb poskytnout konzistentní pohled na databázi na úrovni výpisů nebo transakcí. SQL Server by se při těchto úrovních izolace mohl zcela vyhnout Halloweenské ochraně, protože úložiště verzí může poskytovat data neovlivněná jakýmikoli změnami, které mohl aktuálně vykonávaný příkaz dosud provést. Tato myšlenka v současné době není implementována ve vydané verzi SQL Server, ačkoli Microsoft podal patent popisující, jak by to fungovalo, takže možná budoucí verze bude tuto technologii zahrnovat.Hromadné a předávané záznamy
Pokud jste obeznámeni s vnitřními strukturami haldových struktur, možná vás zajímá, zda může při generování předávaných záznamů v tabulce haldy nastat určitý Halloweenský problém. V případě, že je to pro vás novinka, bude záznam haldy předán, pokud je existující řádek aktualizován tak, že se již nevejde na původní datovou stránku. Modul za sebou zanechá útržek přesměrování a přesune rozšířený záznam na jinou stránku.
Problém může nastat, pokud plán obsahující skenování haldy aktualizuje záznam tak, že je předán dál. Skenování haldy může znovu narazit na řádek, když pozice skenování dosáhne stránky s předávaným záznamem. Na serveru SQL Server se tomuto problému zabrání, protože Storage Engine zaručuje, že bude vždy okamžitě následovat ukazatele předávání. Pokud kontrola narazí na záznam, který byl předán dál, bude jej ignorovat. S tímto zabezpečením se optimalizátor dotazů nemusí o tento scénář starat.
SCHEMABINDING a skalární funkce T-SQL
Existuje jen velmi málo příležitostí, kdy je použití skalární funkce T-SQL dobrý nápad, ale pokud nějakou musíte použít, měli byste si být vědomi důležitého účinku, který může mít ohledně Halloweenské ochrany. Pokud není skalární funkce deklarována pomocí
SCHEMABINDINGSQL Server předpokládá, že funkce přistupuje k tabulkám. Pro ilustraci zvažte jednoduchou skalární funkci T-SQL níže:CREATE FUNCTION dbo.ReturnInput( @value integer)RETURNS integerASBEGIN RETURN @value;END;Tato funkce nemá přístup k žádným tabulkám; ve skutečnosti nedělá nic kromě vrácení hodnoty parametru, která mu byla předána. Nyní se podívejte na následující
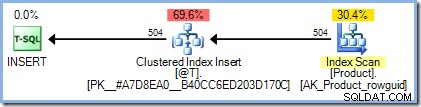
INSERTdotaz:DECLARE @T AS TABLE (ProductID celé číslo PRIMÁRNÍ KLÍČ); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;Prováděcí plán je přesně takový, jaký bychom očekávali, bez nutnosti Halloweenské ochrany:
Přidání naší funkce nicnedělání má však dramatický efekt:
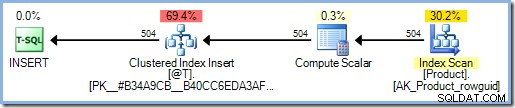
DECLARE @T AS TABLE (ProductID celé číslo PRIMÁRNÍ KLÍČ); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID)FROM AdventureWorks2012.Production.Product AS p;
Prováděcí plán nyní zahrnuje Eager Table Spool pro ochranu Halloweenu. SQL Server předpokládá, že funkce přistupuje k datům, což může opět zahrnovat čtení z tabulky Produkt. Jak si možná vzpomínáte,
INSERTplán, který obsahuje odkaz na cílovou tabulku na straně čtení plánu, vyžaduje plnou halloweenskou ochranu, a pokud optimalizátor ví, může to tak být i v tomto případě.Přidání
SCHEMABINDINGvolba k definici funkce znamená, že SQL Server prozkoumá tělo funkce, aby určil, ke kterým tabulkám přistupuje. Nenajde žádný takový přístup, a tak nepřidá žádnou Halloweenskou ochranu:ALTER FUNCTION dbo.ReturnInput( @value integer)RETURNS integerWITH SCHEMABINDINGASBEGIN RETURN @value;END;GODECLARE @T AS TABLE (ProductID int PRIMARY KEY); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;
Tento problém se skalárními funkcemi T-SQL ovlivňuje všechny aktualizační dotazy –
INSERT,UPDATE,DELETEaMERGE. Poznání, kdy narazíte na tento problém, je složitější, protože zbytečná Halloweenská ochrana se ne vždy zobrazí jako další Eager Table Spool a volání skalárních funkcí mohou být skryta například v pohledech nebo definicích vypočítaných sloupců.[ Část 1 | Část 2 | Část 3 | Část 4 ]