[ Část 1 | Část 2 | Část 3 | Část 4 ]
MERGE příkaz (zavedený v SQL Server 2008) nám umožňuje provádět kombinaci INSERTs , UPDATE a DELETE operace pomocí jediného příkazu. Problémy s Halloweenskou ochranou pro MERGE jsou většinou kombinací požadavků jednotlivých operací, ale existuje několik důležitých rozdílů a několik zajímavých optimalizací, které se týkají pouze MERGE .
Jak se vyhnout halloweenskému problému s MERGE
Začneme tím, že se znovu podíváme na příklad Demo a Staging z druhé části:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Jak si možná vzpomínáte, tento příklad byl použit k ukázce INSERTs vyžaduje halloweenskou ochranu, když je v SELECT také odkazováno na cílovou tabulku vložení část dotazu (EXISTS doložka v tomto případě). Správné chování pro INSERTs výše uvedené je pokusit se přidat obě 1234 hodnot a následně selhat s PRIMARY KEY porušení. Bez oddělení fází, INSERTs by nesprávně přidal jednu hodnotu a dokončil by se bez vyvolání chyby.
Plán provádění INSERT
Výše uvedený kód má jeden rozdíl od kódu použitého ve druhé části; byl přidán index bez klastrů do pracovní tabulky. INSERTs plán provádění stále vyžaduje však halloweenskou ochranu:
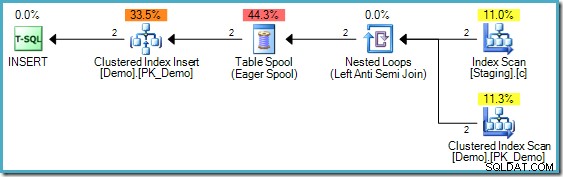
Prováděcí plán MERGE
Nyní zkuste stejnou logickou vložku vyjádřenou pomocí MERGE syntaxe:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
V případě, že nejste obeznámeni se syntaxí, logikou je porovnat řádky v tabulkách Staging a Demo na hodnotě SomeKey a pokud v cílové (Demo) tabulce není nalezen žádný odpovídající řádek, vložíme nový řádek. Toto má přesně stejnou sémantiku jako předchozí INSERT...WHERE NOT EXISTS kód, samozřejmě. Prováděcí plán je však zcela odlišný:
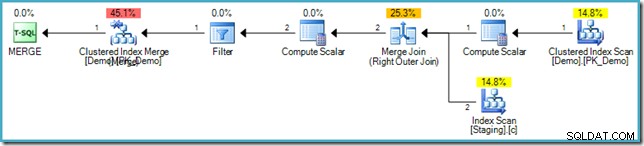
Všimněte si, že v tomto plánu chybí Eager Table Spool. Navzdory tomu dotaz stále vytváří správnou chybovou zprávu. Zdá se, že SQL Server našel způsob, jak provést MERGE plánujte iterativně a přitom respektujte logické oddělení fází vyžadované standardem SQL.
Optimalizace vyplňování děr
Za správných okolností může optimalizátor SQL Server rozpoznat, že MERGE příkaz je vyplňování děr , což je jen další způsob, jak říci, že příkaz přidává pouze řádky tam, kde existuje mezera v klíči cílové tabulky.
Aby se tato optimalizace použila, hodnoty použité v WHEN NOT MATCHED BY TARGET klauzule musí přesně odpovídat ON část USING doložka. Cílová tabulka musí mít také jedinečný klíč (požadavek, který splňuje PRIMARY KEY v tomto případě). Pokud jsou tyto požadavky splněny, MERGE prohlášení nevyžaduje ochranu před Halloweenským problémem.
Samozřejmě, MERGE prohlášení je logicky žádné více či méně vyplňování děr než původní INSERT...WHERE NOT EXISTS syntax. Rozdíl je v tom, že optimalizátor má úplnou kontrolu nad implementací MERGE příkaz, zatímco INSERTs syntaxe by vyžadovala, aby uvažoval o širší sémantice dotazu. Člověk může snadno vidět, že INSERTs je také zaplňování děr, ale optimalizátor nepřemýšlí o věcech stejným způsobem jako my.
Pro ilustraci přesné shody požadavek, který jsem zmínil, zvažte následující syntaxi dotazu, která není těžit z optimalizace vyplňování otvorů. Výsledkem je plná Halloweenská ochrana poskytovaná Eager Table Spool:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Jediný rozdíl je v násobení jednou v VALUES klauzule – něco, co nemění logiku dotazu, ale co stačí k tomu, aby se zabránilo použití optimalizace vyplňování děr.
Vyplňování otvorů pomocí vnořených smyček
V předchozím příkladu optimalizátor zvolil spojení tabulek pomocí spojení Merge. Optimalizaci vyplňování děr lze také použít tam, kde je zvoleno spojení Nested Loops, ale to vyžaduje zvláštní záruku jedinečnosti na zdrojové tabulce a hledání indexu na vnitřní straně spojení. Abychom to viděli v akci, můžeme vymazat existující pracovní data, přidat jedinečnost do neshlukovaného indexu a vyzkoušet MERGE znovu:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Výsledný plán provádění opět využívá optimalizaci vyplňování děr, aby se vyhnul Halloweenské ochraně, pomocí spojení vnořených smyček a vnitřního vyhledávání do cílové tabulky:
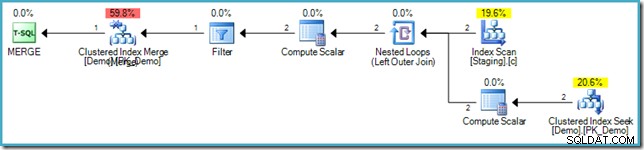
Vyhýbání se zbytečnému procházení indexu
Tam, kde se použije optimalizace vyplňování děr, může motor také použít další optimalizaci. Při čtení si dokáže zapamatovat aktuální pozici indexu cílovou tabulku (zpracovává se vždy jeden řádek, pamatujte) a znovu použijte tyto informace při provádění vkládání, namísto hledání v b-stromu k nalezení umístění vložení. Důvodem je, že aktuální pozice čtení je velmi pravděpodobně na stejné stránce, kam by měl být vložen nový řádek. Kontrola, zda řádek skutečně patří na tuto stránku, je velmi rychlá, protože zahrnuje kontrolu pouze nejnižšího a nejvyššího klíče, který je tam aktuálně uložen.
Kombinace eliminace Eager Table Spool a uložení indexové navigace na řádek může poskytnout významnou výhodu v pracovních zátěžích OLTP za předpokladu, že plán provádění je načten z mezipaměti. Náklady na kompilaci MERGE je spíše vyšší než u INSERTs , UPDATE a DELETE , takže plán opětovného použití je důležitým faktorem. Je také užitečné zajistit, aby stránky měly dostatek volného místa pro umístění nových řádků, čímž se zabrání dělení stránek. Toho je obvykle dosaženo běžnou údržbou indexu a přiřazením vhodného FILLFACTOR .
Zmiňuji úlohy OLTP, které obvykle obsahují velké množství relativně malých změn, protože MERGE optimalizace nemusí být dobrou volbou tam, kde je na jeden příkaz zpracováno velké množství řádků. Další optimalizace, jako jsou minimálně protokolované INSERTs nelze aktuálně kombinovat s výplní otvorů. Jako vždy by měly být výkonnostní charakteristiky porovnány, aby bylo zajištěno, že budou realizovány očekávané přínosy.
Optimalizace vyplňování děr pro MERGE vložky lze kombinovat s aktualizacemi a mazáními pomocí dodatečného MERGE doložky; každá operace změny dat je z hlediska Halloweenského problému posuzována samostatně.
Vyhýbání se připojení
Finální optimalizaci, na kterou se podíváme, lze použít tam, kde dojde k MERGE obsahuje operace aktualizace a odstranění, stejně jako vložení pro vyplňování děr a cílová tabulka má jedinečný seskupený index. Následující příklad ukazuje běžné MERGE vzor, do kterého se vkládají neodpovídající řádky a odpovídající řádky se aktualizují nebo mažou v závislosti na další podmínce:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
MERGE příkaz potřebný k provedení všech požadovaných změn je pozoruhodně kompaktní:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Prováděcí plán je docela překvapivý:

Žádná Halloweenská ochrana, žádné spojení mezi zdrojovou a cílovou tabulkou a nestává se často, že uvidíte operátor vložení seskupeného indexu následovaný sloučením seskupeného indexu do stejné tabulky. Toto je další optimalizace zaměřená na pracovní zátěže OLTP s vysokým opakovaným využitím plánu a vhodnou indexací.
Cílem je přečíst řádek ze zdrojové tabulky a okamžitě se pokusit jej vložit do cíle. Pokud dojde k porušení klíče, chyba je potlačena, operátor Insert vypíše konfliktní řádek, který našel, a tento řádek je poté zpracován pro operaci aktualizace nebo odstranění pomocí operátoru plánu sloučení jako obvykle.
Pokud je původní vložení úspěšné (bez porušení klíče), zpracování pokračuje dalším řádkem ze zdroje (operátor Merge zpracovává pouze aktualizace a mazání). Tato optimalizace prospívá především MERGE dotazy, kde většina zdrojových řádků vede k vložení. Opět je nutné pečlivé srovnávání, aby byl výkon lepší než použití samostatných příkazů.
Shrnutí
MERGE poskytuje několik jedinečných možností optimalizace. Za správných okolností se může vyhnout nutnosti přidat explicitní ochranu Halloween ve srovnání s ekvivalentem INSERTs operace, nebo možná i kombinace INSERTs , UPDATE a DELETE prohlášení. Další MERGE -specifické optimalizace mohou zabránit procházení b-stromu indexu, které je obvykle potřeba k nalezení pozice vložení pro nový řádek, a mohou také zabránit nutnosti zcela spojit zdrojové a cílové tabulky.
V poslední části této série se podíváme na to, jak optimalizátor dotazů zdůvodňuje potřebu halloweenské ochrany, a identifikujeme některé další triky, které může použít, aby nebylo nutné přidávat Eager Table Spools do plánů provádění, které mění data.
[ Část 1 | Část 2 | Část 3 | Část 4 ]