Poprvé představeno v SQL Server 2017 Enterprise Edition, adaptivní spojení umožňuje za běhu přechod z dávkového režimu hash spojení do režimu řádkového korelovaného indexovaného spojení vnořených smyček (použít) za běhu. Pro stručnost budu odkazovat na „korelované indexované spojení vnořených smyček“ jako použít v celém zbytku tohoto článku. Pokud si potřebujete zopakovat rozdíl mezi vnořenými smyčkami a aplikací, přečtěte si můj předchozí článek.
Zda adaptivní spojení přejde z hašovacího spojení, aby se použilo za běhu, závisí na hodnotě označené Adaptivní prahové řádky na Adaptivní připojení operátor prováděcího plánu. Tento článek ukazuje, jak adaptivní spojení funguje, obsahuje podrobnosti o výpočtu prahu a pokrývá důsledky některých provedených návrhů.
Úvod
Jedna věc, kterou chci, abyste v tomto díle měli na paměti, je adaptivní připojení vždy spustí se jako spojení hash v dávkovém režimu. To platí i v případě, že plán provádění uvádí, že adaptivní spojení se očekává, že bude spuštěno v režimu řádků.
Jako každé hašovací spojení i adaptivní spojení čte všechny řádky dostupné na vstupu sestavení a zkopíruje požadovaná data do hašovací tabulky. Varianta hašovacího spojení v dávkovém režimu ukládá tyto řádky v optimalizovaném formátu a rozděluje je pomocí jedné nebo více hašovacích funkcí. Jakmile je spotřebován vstup sestavení, hashovací tabulka je plně vyplněna a rozdělena, připravena na spojení hash, aby mohlo začít kontrolovat shodu řádků na straně sondy.
Toto je bod, kde se adaptivní spojení rozhoduje, zda pokračovat v dávkovém režimu hash spojení nebo použít přechod do režimu řádků. Pokud je počet řádků v hašovací tabulce menší než práh hodnota, spojení se přepne na použití; jinak spojení pokračuje jako hash spojení zahájením čtení řádků ze vstupu sondy.
Pokud dojde k přechodu na spojení aplikace, plán provádění znovu nepřečte řádky použité k naplnění hashovací tabulky k řízení operace aplikace. Místo toho interní komponenta známá jako adaptivní čtečka vyrovnávací paměti rozšíří řádky již uložené v hashovací tabulce a zpřístupní je na vyžádání pro vnější vstup operátoru aplikace. S adaptivní čtečkou vyrovnávací paměti jsou spojeny náklady, ale jsou mnohem nižší než náklady na úplné přetočení vstupu sestavení.
Výběr adaptivního spojení
Optimalizace dotazu zahrnuje jednu nebo více fází logického průzkumu a fyzické implementace alternativ. V každé fázi, kdy optimalizátor zkoumá fyzické možnosti pro logiku join, může zvážit alternativy jak dávkového spojení hash, tak použití režimu řádků.
Pokud jedna z těchto možností fyzického spojení tvoří součást nejlevnějšího řešení nalezeného v aktuální fázi – a druhý typ spojení může poskytnout stejné požadované logické vlastnosti – optimalizátor označí skupinu logického spojení jako potenciálně vhodné pro adaptivní spojení. Pokud ne, zvažování adaptivního spojení zde končí (a nespustí se žádná rozšířená událost adaptivního spojení).
Normální provoz optimalizátoru znamená, že nejlevnější nalezené řešení bude zahrnovat pouze jednu z možností fyzického spojení – buď hash, nebo použít, podle toho, která měla nejnižší odhadované náklady. Další věc, kterou optimalizátor udělá, je vytvoření a náklady na novou implementaci typu spojení, které nebylo vybrán jako nejlevnější.
Vzhledem k tomu, že současná fáze optimalizace již skončila s nalezením nejlevnějšího řešení, je pro adaptivní spojení provedeno speciální kolo průzkumu a implementace jedné skupiny. Nakonec optimalizátor vypočítá adaptivní práh .
Pokud je některá z předchozích prací neúspěšná, spustí se rozšířená událost adaptive_join_skipped s důvodem.
Pokud je zpracování adaptivního spojení úspěšné, zobrazí se Concat operátor se přidá do interního plánu nad hash a použije alternativy s adaptivní čtečkou vyrovnávací paměti a všemi požadovanými adaptéry dávkového/řádkového režimu. Pamatujte, že za běhu se spustí pouze jedna z alternativ spojení v závislosti na počtu skutečně nalezených řádků ve srovnání s adaptivním prahem.
The Concat operátor a jednotlivé alternativy hash/použít se obvykle v konečném plánu realizace nezobrazují. Místo toho se nám nabízí jediné Adaptivní připojení operátor. Toto je pouze rozhodnutí o prezentaci – Concat a spojení jsou stále přítomna v kódu spuštěném prováděcím strojem SQL Server. Další podrobnosti o tom můžete najít v částech Dodatek a související četba tohoto článku.
Adaptivní práh
Žádost je obecně levnější než hash spojení pro menší počet řídicích řádků. Hašovací spojení má dodatečné počáteční náklady na vytvoření své hašovací tabulky, ale nižší náklady na řádek, když začíná zjišťovat shody.
Obecně existuje bod, kdy se odhadované náklady na přihlášku a spojení hash budou rovnat. Tuto myšlenku pěkně ilustroval Joe Sack ve svém článku Introducing Batch Mode Adaptive Joins:
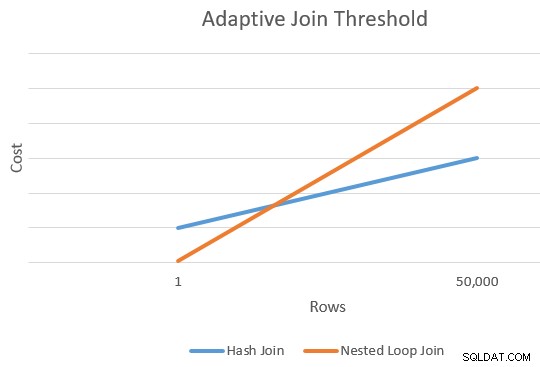
Výpočet prahu
V tomto okamžiku má optimalizátor jediný odhad pro počet řádků vstupujících do vstupu sestavení spojení hash a použití alternativ. Obsahuje také odhadované náklady na hash a operátory aplikací jako celek.
To nám dává jediný bod na pravém okraji oranžové a modré čáry v diagramu výše. Optimalizátor potřebuje pro každý typ spojení další referenční bod, aby mohl „kreslit čáry“ a najít průsečík (doslova nekreslí čáry, ale máte představu).
Aby našel druhý bod pro čáry, optimalizátor požádá obě spojení, aby vytvořily nový odhad nákladů na základě odlišné (a hypotetické) mohutnosti vstupu. Pokud byl první odhad mohutnosti více než 100 řádků, požádá spojení o odhad nových nákladů na jeden řádek. Pokud byla původní mohutnost menší nebo rovna 100 řádkům, druhý bod je založen na vstupní mohutnosti 10 000 řádků (takže existuje dostatečně slušný rozsah pro extrapolaci).
V každém případě jsou výsledkem dvě různé ceny a počty řádků pro každý typ spojení, což umožňuje „kreslení“ čar.
Vzorec křižovatky
Najít průsečík dvou přímek na základě dvou bodů pro každou přímku je problém s několika dobře známými řešeními. SQL Server používá jeden na základě determinantů jak je popsáno na Wikipedii:
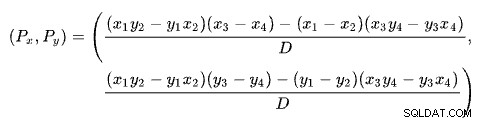
kde:
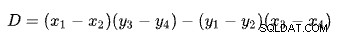
První řádek je definován body (x1 , y1 ) a (x2 , y2 ). Druhá čára je dána body (x3 , y3 ) a (x4 , y4 ). Křižovatka je v (Px , Py ).
Naše schéma má počet řádků na ose x a odhadované náklady na ose y. Zajímá nás počet řad, kde se čáry protínají. To je dáno vzorcem pro Px . Pokud bychom chtěli znát odhadovanou cenu na křižovatce, bylo by to Py .
Pro Px řádků, odhadované náklady na aplikační řešení a řešení hash join by byly stejné. Toto je adaptivní práh, který potřebujeme.
Fungovaný příklad
Zde je příklad použití vzorové databáze AdventureWorks2017 a následujícího indexovacího triku od Itzika Ben-Gana k získání bezpodmínečného zvážení spuštění v dávkovém režimu:
-- Itzikův trik VYTVOŘIT NEZAHRNUTÝ INDEX SLOUPCE BatchModeON Sales.SalesOrderHeader (SalesOrderID)WHERE SalesOrderID =-1AND SalesOrderID =-2; -- Testovací dotazSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123;
Plán provádění zobrazuje adaptivní připojení s prahovou hodnotou 1502,07 řádky:
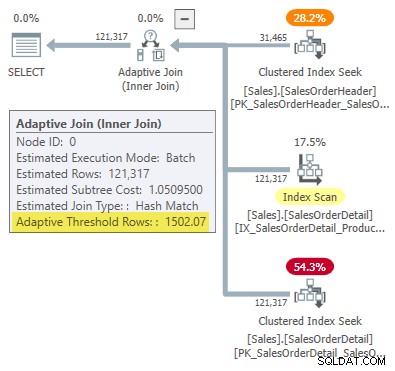
Odhadovaný počet řádků řídících adaptivní spojení je 31 465 .
Společné náklady
V tomto zjednodušeném případě můžeme najít odhadované náklady na podstrom pro hash a použít alternativy spojení pomocí tipů:
-- HashSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123IN, HASHD JOIN, 1 MAXOP JO>
-- PoužítSELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OPTION, (LOOP1>OPTION);
To nám dává jeden bod na řádku pro každý typ spojení:

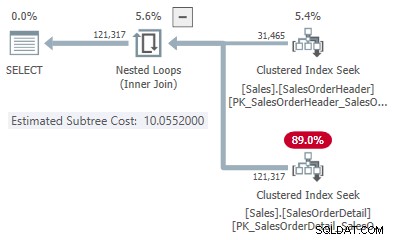
- 31 465 řádků
- Cena hash 1,05083
- Použijte cenu 10,0552
Druhý bod na lince
Protože odhadovaný počet řádků je více než 100, pocházejí druhé referenční body ze speciálních interních odhadů založených na jednom vstupním řádku spojení. Bohužel neexistuje snadný způsob, jak získat přesná čísla nákladů pro tuto interní kalkulaci (více o tom budu mluvit brzy).
Prozatím vám ukážu pouze čísla nákladů (s použitím úplné interní přesnosti spíše než šesti významných čísel uvedených v plánech realizace):
- Jeden řádek (interní výpočet)
- Cena hash 0,999027422729
- Použijte cenu 0,547927305023
- 31 465 řádků
- Cena hash 1,05082787359
- Použijte cenu 10,0552890166
Jak se očekávalo, použití spojení je levnější než hash pro malou mohutnost vstupu, ale mnohem dražší pro očekávanou mohutnost 31 465 řádků.
Výpočet křižovatky
Zapojením těchto čísel mohutnosti a nákladů do vzorce průsečíku čar získáte následující:
-- Hash body (x =mohutnost; y =cena) DECLARE @x1 float =1, @y1 float =0,999027422729, @x2 float =31465, @y2 float =1,05082787359; -- Použijte body (x =mohutnost; y =cena) DECLARE @x3 float =1, @y3 float =0,547927305023, @x4 float =31465, @y4 float =10,0552890166; -- Vzorec:SELECT Práh =( (@x1 * @y2 - @y1 * @x2) * (@x3 - @x4) - (@x1 - @x2) * (@x3 * @y4 - @y3 * @x4 )) / ( (@x1 - @x2) * (@y3 - @y4) - (@y1 - @y2) * (@x3 - @x4)); -- Vrátí 1502,06521571273
Zaokrouhleno na šest platných číslic tento výsledek odpovídá 1502,07 řádky zobrazené v plánu provádění adaptivního spojení:
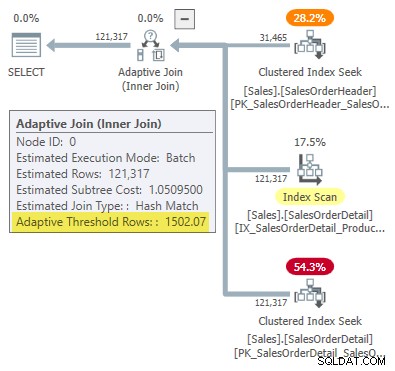
Vada nebo design?
Pamatujte, že SQL Server potřebuje čtyři body, aby „vykreslil“ počet řádků versus nákladové řádky, aby našel prahovou hodnotu adaptivního spojení. V tomto případě to znamená najít odhady nákladů pro kardinality jednoho řádku a 31 465 řádků pro implementace aplikace a hash join.
Optimalizátor volá rutinu s názvem sqllang!CuNewJoinEstimate vypočítat tyto čtyři náklady na adaptivní spojení. Bohužel zde nejsou žádné příznaky trasování ani rozšířené události, které by poskytovaly praktický přehled o této aktivitě. Běžné příznaky trasování používané ke zkoumání chování optimalizátoru a nákladů na zobrazení zde nefungují (pokud vás zajímají další podrobnosti, podívejte se na přílohu).
Jediný způsob, jak získat odhady nákladů na jeden řádek, je připojit ladicí program a nastavit bod přerušení po čtvrtém volání CuNewJoinEstimate v kódu pro sqllang!CardSolveForSwitch . K získání tohoto zásobníku volání na SQL Server 2019 CU12 jsem použil WinDbg:

V tomto bodě kódu jsou náklady s pohyblivou řádovou čárkou s dvojitou přesností uloženy ve čtyřech paměťových místech, na která odkazují adresy na rsp+b0 , rsp+d0 , rsp+30 a rsp+28 (kde rsp je registr CPU a offsety jsou v šestnáctkové soustavě):

Zobrazená čísla nákladů podstromu operátora odpovídají číslům použitým ve vzorci pro výpočet prahu adaptivního spojení.
O těchto jednořadých odhadech nákladů
Možná jste si všimli, že odhadované náklady na podstrom pro spojení jednoho řádku se zdají poměrně vysoké vzhledem k množství práce spojené se spojením jednoho řádku:
- Jeden řádek
- Cena hash 0,999027422729
- Použijte cenu 0,547927305023
Pokud se pokusíte vytvořit jednořádkové plány provádění vstupu pro spojení hash a použít příklady, uvidíte hodně nižší odhadované náklady na podstrom na spojení než ty, které jsou uvedeny výše. Podobně spuštění původního dotazu s cílem řádku jeden (nebo počet výstupních řádků spojení očekávaný pro vstup jednoho řádku) také vytvoří odhadované náklady způsobem nižší než zobrazeno.
Důvodem je CuNewJoinEstimate rutina odhaduje jeden řádek případ způsobem, který si myslím, že většina lidí nepovažuje za intuitivní.
Konečná cena se skládá ze tří hlavních složek:
- Cena vstupního podstromu sestavení
- Místní náklady na připojení
- Cena vstupního podstromu sondy
Položky 2 a 3 závisí na typu spojení. U hašovacího spojení zohledňují náklady na přečtení všech řádků ze vstupu sondy, jejich porovnání (nebo ne) s jedním řádkem v hašovací tabulce a předání výsledků dalšímu operátoru. V případě žádosti náklady pokrývají jedno vyhledávání na nižším vstupu do spojení, interní náklady samotného spojení a vrácení odpovídajících řádků nadřazenému operátorovi.
Nic z toho není neobvyklé ani překvapivé.
Nákladové překvapení
Překvapení přichází na straně sestavení spojení (položka 1 v seznamu). Dalo by se očekávat, že optimalizátor provede nějaký efektní výpočet pro zmenšení již vypočítaných nákladů na podstrom pro 31 465 řádků na jeden průměrný řádek nebo něco podobného.
Ve skutečnosti jak odhady hašování, tak i použití jednořádkových odhadů spojení jednoduše používají celé náklady podstromu pro původní odhad mohutnosti 31 465 řádků. V našem běžícím příkladu má tento „podstrom“ hodnotu 0,54456 náklady na hledání skupinového indexu v dávkovém režimu v tabulce záhlaví:
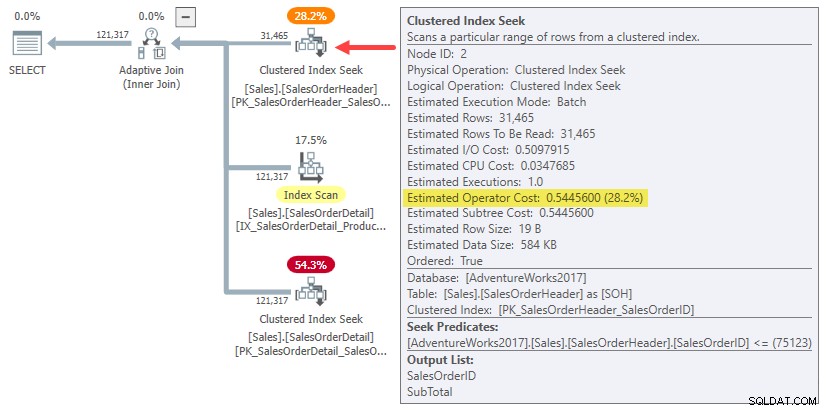
Aby bylo jasno:odhadované náklady na straně sestavení pro alternativy spojení jednoho řádku používají vstupní náklady vypočítané pro 31 465 řádků. To by vám mělo připadat trochu divné.
Připomínáme, že náklady na jeden řádek vypočítané pomocí CuNewJoinEstimate byly následující:
- Jeden řádek
- Cena hash 0,999027422729
- Použijte cenu 0,547927305023
Můžete vidět, že celkové ceně aplikace (~0,54793) dominuje 0,54456 náklady na podstrom na straně sestavení, s nepatrnou částkou navíc za jediné hledání na vnitřní straně, zpracování malého počtu výsledných řádků v rámci spojení a jejich předání nadřazenému operátoru.
Odhadované náklady na spojení jednoho řádku hash jsou vyšší, protože testovací strana plánu sestává z úplného prohledávání indexu, kde musí spojením projít všechny výsledné řádky. Celkové náklady na jednořádkové spojení hash jsou o něco nižší než původní náklady 1,05095 pro příklad s 31 465 řádky, protože v tabulce hash je nyní pouze jeden řádek.
Důsledky
Dalo by se očekávat, že odhad spojení jednoho řádku bude zčásti založen na nákladech na dodání jednoho řádku do vstupu řízení spojení. Jak jsme viděli, v případě adaptivního spojení to neplatí:alternativy aplikace i hash jsou spojeny s plnou odhadovanou cenou za 31 465 řádků. Zbytek spojení stojí skoro tak, jak by se dalo očekávat u vstupu sestavení jednoho řádku.
Toto intuitivně podivné uspořádání je důvodem, proč je obtížné (možná nemožné) ukázat prováděcí plán odrážející vypočítané náklady. Potřebovali bychom sestavit plán, který dodá 31 465 řádků do horního vstupu spojení, ale bude stát samotné spojení a jeho vnitřní vstup, jako by byl přítomen pouze jeden řádek. Těžký dotaz.
Důsledkem toho všeho je zvednutí bodu nejvíce vlevo na našem diagramu protínajících se čar směrem nahoru po ose y. To ovlivní sklon čáry a tím i průsečík.
Dalším praktickým efektem je, že vypočítaný práh adaptivního spojení nyní závisí na původním odhadu mohutnosti na vstupu sestavení hash, jak poznamenal Joe Obbish ve svém příspěvku na blogu z roku 2017. Pokud například změníme WHERE klauzule v testovacím dotazu na SOH.SalesOrderID <= 55000 , adaptivní práh sníží z 1502,07 na 1259,8 beze změny hash plánu dotazů. Stejný plán, jiný práh.
K tomu dochází, jak jsme viděli, interní jednořádkový odhad nákladů závisí na nákladech na sestavení pro původní odhad mohutnosti. To znamená, že různé počáteční odhady na straně sestavení poskytnou odlišné „posílení“ na ose y oproti jednořádkovému odhadu. Čára bude mít zase jiný sklon a jiný průsečík.
Intuice by naznačovala, že odhad jednoho řádku pro stejné spojení by měl vždy dávat stejnou hodnotu bez ohledu na další odhad mohutnosti na řádku (za předpokladu, že přesně stejné spojení se stejnými vlastnostmi a velikostí řádků má téměř lineární vztah mezi řízením řádky a náklady). To neplatí pro adaptivní spojení.
Podle návrhu?
Mohu vám s jistou jistotou říci, co SQL Server dělá při výpočtu prahu adaptivního spojení. Nemám žádný zvláštní přehled o proč dělá to takto.
Přesto existuje několik důvodů si myslet, že toto uspořádání je záměrné a vzniklo po náležitém zvážení a zpětné vazbě z testování. Zbytek této části pokrývá některé z mých úvah o tomto aspektu.
Adaptivní spojení není přímou volbou mezi normálním použitím a spojením hash v dávkovém režimu. Adaptivní spojení vždy začíná úplným vyplněním hashovací tabulky. Teprve po dokončení této práce se rozhodne, zda přejít na implementaci aplikace nebo ne.
Do této doby nám již vznikly potenciálně značné náklady naplněním a rozdělením spojení hash v paměti. To nemusí u jednořadého případu příliš záležet, ale s rostoucí mohutností se to stává postupně důležitějším. Neočekávané „zvýšení“ může být způsob, jak začlenit tyto skutečnosti do výpočtu při zachování přiměřených nákladů na výpočet.
Nákladový model SQL Serveru byl již dlouho poněkud zaujatý proti spojení vnořených smyček, pravděpodobně s určitým opodstatněním. I ideální případ použití s indexem může být v praxi pomalý, pokud potřebná data ještě nejsou v paměti a I/O subsystém není flash, zvláště s poněkud náhodným přístupem. Omezené množství paměti a pomalé I/O nebudou například uživatelům nižších cloudových databázových strojů zcela neznámé.
Je možné, že praktické testování v takových prostředích odhalilo, že intuitivně nákladné adaptivní spojení bylo příliš rychlé na přechod na aplikaci. Teorie je někdy skvělá pouze teoreticky.
Přesto současná situace není ideální; ukládání plánu do mezipaměti založeného na neobvykle nízkém odhadu mohutnosti způsobí, že adaptivní spojení bude mnohem méně ochotné přejít na aplikaci, než by tomu bylo s větším počátečním odhadem. Toto je celá řada problémů s citlivostí parametrů, ale pro mnohé z nás to bude nová úvaha tohoto typu.
Nyní je to také možné použití úplné vstupní ceny podstromu sestavení pro nejlevější bod protínajících se nákladových čar je jednoduše neopravená chyba nebo přehlédnutí. Mám pocit, že současná implementace je pravděpodobně záměrným praktickým kompromisem, ale potřebovali byste někoho, kdo má přístup k návrhovým dokumentům a zdrojovému kódu, aby to věděl jistě.
Shrnutí
Adaptivní spojení umožňuje serveru SQL Server přejít z dávkového režimu hash spojení na aplikaci poté, co byla tabulka hash plně naplněna. Toto rozhodnutí činí porovnáním počtu řádků v hašovací tabulce s předem vypočítaným adaptivním prahem.
Prahová hodnota se vypočítá na základě předpovědi, kde jsou stejné náklady na použití a na připojení hash. K nalezení tohoto bodu SQL Server vytvoří druhý interní odhad nákladů na spojení pro jinou mohutnost vstupu sestavení – obvykle jeden řádek.
Překvapivě odhadované náklady na jednořádkový odhad zahrnují úplné náklady na sestavení podstromu pro původní odhad mohutnosti (neškálované na jeden řádek). To znamená, že prahová hodnota závisí na původním odhadu mohutnosti na vstupu sestavení.
V důsledku toho může mít adaptivní spojení neočekávaně nízkou prahovou hodnotu, což znamená, že u adaptivního spojení je mnohem méně pravděpodobné, že přejde od spojení hash. Není jasné, zda je toto chování záměrné.
Související čtení
- Představujeme adaptivní spojení v dávkovém režimu od Joe Sacka
- Pochopení adaptivních spojení v dokumentaci k produktu
- Adaptive Join Internals od Dima Pilugin
- Jak fungují adaptivní spojení v dávkovém režimu? na serveru Database Administrators Stack Exchange od Erika Darlinga
- Adaptivní regrese spojení od Joe Obbishe
- Pokud chcete adaptivní spojení, potřebujete širší indexy a je větší lepší? od Erika Darlinga
- Parameter Sniffing:Adaptive Joins od Brenta Ozara
- Inteligentní zpracování dotazů Q&A od Joe Sacka
Příloha
Tato část pokrývá několik aspektů adaptivního spojení, které bylo obtížné zahrnout do hlavního textu přirozeným způsobem.
Rozšířený adaptivní plán
Můžete se pokusit podívat se na vizuální reprezentaci interního plánu pomocí nezdokumentovaného příznaku trasování 9415, jak jej poskytl Dima Pilugin ve svém vynikajícím článku o adaptivním spojení internals, na který odkazuje výše. Když je tento příznak aktivní, adaptivní plán spojení pro náš běžící příklad bude následující:
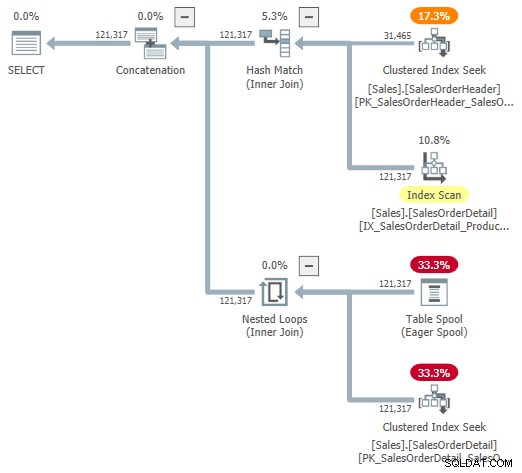
Toto je užitečná reprezentace pro usnadnění porozumění, ale není zcela přesná, úplná nebo konzistentní. Například tabulka Spool neexistuje – je to výchozí reprezentace pro adaptivní čtečku vyrovnávací paměti čtení řádků přímo z hašovací tabulky v dávkovém režimu.
Vlastnosti operátora a odhady mohutnosti jsou také trochu všude. Výstup ze čtečky adaptivní vyrovnávací paměti („spool“) by měl mít 31 465 řádků, nikoli 121 317. Cena podstromu aplikace je nesprávně omezena cenou nadřazeného operátora. To je normální pro showplan, ale v kontextu adaptivního spojení to nedává smysl.
Existují i další nekonzistence – příliš mnoho na to, aby je bylo možné vyjmenovat – ale to se může stát s nezdokumentovanými příznaky trasování. Rozšířený plán zobrazený výše není určen pro použití koncovými uživateli, takže to možná není úplně překvapivé. Poselstvím je nespoléhat se příliš na čísla a vlastnosti uvedené v této nezdokumentované podobě.
Na závěr bych měl také zmínit, že dokončený standardní operátor adaptivního plánu spojení není zcela bez problémů s konzistencí. Ty vycházejí do značné míry výhradně ze skrytých detailů.
Například zobrazené vlastnosti adaptivního spojení pocházejí ze směsi základních Concat , Hash Join a Použít operátory. Můžete vidět provádění dávkového režimu hlášení adaptivního spojení pro spojení vnořených smyček (což není možné) a zobrazený uplynulý čas je ve skutečnosti zkopírován ze skrytého Concat , nikoli konkrétní spojení, které se provedlo za běhu.
Obvyklí podezřelí
Můžeme můžeme získat užitečné informace z druhů nezdokumentovaných příznaků trasování, které se běžně používají k prohlížení výstupu optimalizátoru. Například:
SELECT SOH.SubTotalFROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOH.SalesOrderID <=75123OrderID <=75123OPTION ( QUERY04,8CERYQUEON3TRA);Výstup (silně upraven pro čitelnost):
*** Výstupní strom:***
Karta PhyOp_ExecutionModeAdapter(BatchToRow)=121317 Cena=1,05095
- PhyOp_Concat (dávková) karta=121317 Cena=1,05325
- PhyOp_HashJoinx_jtInner (dávka) karta=121317 Cena=1,05083
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cena=0,54456
- PhyOp_Filter(batch) Card=121317 Cena=0,397185
- PhyOp_Range Sales.SalesOrderDetail Card=121317 Cena=0,338953
- Karta PhyOp_ExecutionModeAdapter(RowToBatch)=121317 Cena=10,0798
- PhyOp_Apply Card=121317 Cena=10,0553
- Karta PhyOp_ExecutionModeAdapter(BatchToRow)=31465 Cena=0,544623
- PhyOp_Range Sales.SalesOrderHeader Card=31465 Cena=0,54456 [** 3 **]
- PhyOp_Filter Card=3,85562 Cena=9,00356
- PhyOp_Range Sales.SalesOrderDetail Card=3,85562 Cena=8,94533
- Karta PhyOp_ExecutionModeAdapter(BatchToRow)=31465 Cena=0,544623
- PhyOp_Apply Card=121317 Cena=10,0553
To poskytuje určitý přehled o odhadovaných nákladech pro případ plné kardinality s hashem a použitím alternativ bez psaní samostatných dotazů a používání nápověd. Jak je uvedeno v hlavním textu, tyto příznaky trasování nejsou účinné v CuNewJoinEstimate , takže tímto způsobem nemůžeme přímo vidět opakované výpočty pro případ s 31 465 řádky ani žádné podrobnosti pro odhady s jedním řádkem.
Merge Join a Row Mode Hash Join
Adaptivní spojení nabízejí pouze přechod z dávkového režimu hash spojení do režimu použití řádků. Důvody, proč není spojení hash v režimu řádků podporováno, naleznete v části Otázky a odpovědi týkající se inteligentního zpracování dotazů v části Související čtení. Stručně řečeno, má se za to, že spojení hash v režimu řádků by byla příliš náchylná k regresím výkonu.
Další možností by bylo přepnutí do režimu řádkového sloučení, ale optimalizátor to v současné době nezohledňuje. Pokud tomu dobře rozumím, je nepravděpodobné, že se v budoucnu tímto směrem rozšíří.
Některé úvahy jsou stejné jako pro spojení hash v režimu řádků. Kromě toho bývají plány spojení sloučení méně snadno zaměnitelné s hash join, i když se omezíme na indexované spojení spojení (žádné explicitní řazení).
Mezi hash a použít je také mnohem větší rozdíl než mezi hashem a sloučením. Hash i merge jsou vhodné pro větší vstupy a použít se lépe hodí pro menší řídicí vstup. Sloučení spojení není tak snadno paralelní jako spojení hash a neškáluje se tak dobře se zvyšujícím se počtem vláken.
Vzhledem k tomu, že motivací pro adaptivní spojení je lépe se vypořádat s významně různé vstupní velikosti – a pouze hašovací spojení podporuje zpracování v dávkovém režimu – volba dávkového haše versus použití řádku je přirozenější. Konečně, tři možnosti adaptivního spojení by výrazně zkomplikovaly výpočet prahu pro potenciálně malý zisk.