Od vydání SQL Serveru 2017 pro Linux Microsoft do značné míry změnil celou hru. Umožnil zcela nový svět možností pro jejich slavnou relační databázi a nabídl to, co bylo do té doby dostupné pouze v prostoru Windows.
Vím, že puristický DBA by mi hned řekl, že předinstalovaná verze SQL Server 2019 Linux má několik rozdílů, pokud jde o funkce, s ohledem na její protějšek Windows, jako například:
- Žádný SQL Server Agent
- Žádný FileStream
- Žádné systémové rozšířené uložené procedury (např. xp_cmdshell)
Byl jsem však natolik zvědavý, že jsem si pomyslel:„Co když je lze alespoň do určité míry srovnat s věcmi, které umí oba? Stiskl jsem tedy spoušť na několika virtuálních počítačích, připravil několik jednoduchých testů a shromáždil data, která vám představím. Uvidíme, jak se věci vyvinou!
Počáteční úvahy
Zde jsou specifikace každého virtuálního počítače:
- Windows
- OS Windows 10
- 4 vCPU
- 4 GB RAM
- 30 GB SSD
- Linux
- Ubuntu Server 20.04 LTS
- 4 vCPU
- 4 GB RAM
- 30 GB SSD


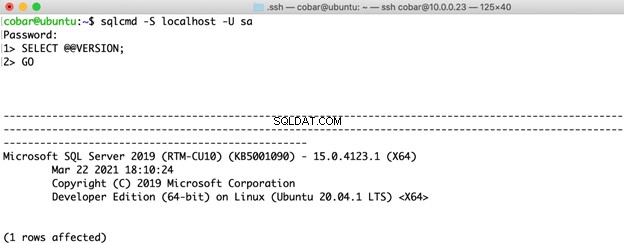
Pro verzi SQL Server jsem vybral tu úplně nejnovější pro oba operační systémy:SQL Server 2019 Developer Edition CU10
V každém nasazení byla jedinou povolenou věcí Okamžitá inicializace souboru (ve výchozím nastavení povolena v systému Linux, povolena ručně v systému Windows). Kromě toho zůstaly výchozí hodnoty pro zbytek nastavení.
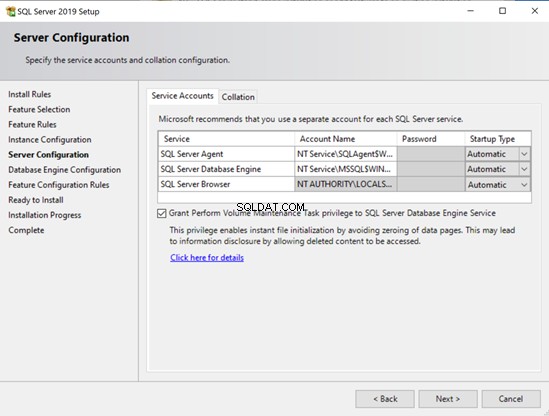
- V systému Windows můžete povolit okamžitou inicializaci souboru pomocí průvodce instalací.
Tento příspěvek se nebude zabývat specifičností práce okamžité inicializace souboru v Linuxu. Nechám vám však odkaz na vyhrazený článek, který si můžete přečíst později (všimněte si, že po technické stránce bude trochu těžší).
Co test obsahuje?
- V každé instanci SQL Server 2019 jsem nasadil testovací databázi a vytvořil jednu tabulku pouze s jedním polem (NVARCHAR(MAX)).
- Pomocí náhodně vygenerovaného řetězce 1 000 000 znaků jsem provedl následující kroky:
- *Vložte X počet řádků do testovací tabulky.
- Změřte, jak dlouho trvalo dokončení příkazu INSERT.
- Změřte velikost souborů MDF a LDF.
- Smažte všechny řádky v testovací tabulce.
- **Změřte, jak dlouho trvalo dokončení příkazu DELETE.
- Změřte velikost souboru LDF.
- Zrušte testovací databázi.
- Vytvořte testovací databázi znovu.
- Opakujte stejný cyklus.
*X bylo provedeno pro 1 000, 5 000, 10 000, 25 000 a 50 000 řádků.
**Vím, že příkaz TRUNCATE odvádí práci mnohem efektivněji, ale mým cílem je dokázat, jak dobře je každý protokol transakcí spravován pro operaci odstranění v každém operačním systému.
Pokud se chcete ponořit hlouběji, můžete přejít na webovou stránku, kterou jsem použil ke generování náhodného řetězce.
Zde jsou části kódu TSQL, které jsem použil pro testy v každém operačním systému:
Linuxové kódy TSQL
Vytvoření databáze a tabulek
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= '/var/opt/mssql/data/test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= '/var/opt/mssql/data/test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.ubuntu(
long_string NVARCHAR(MAX) NOT NULL
)
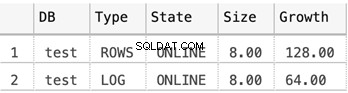
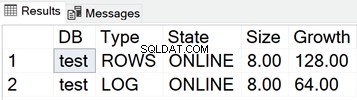
Velikost souborů MDF a LDF pro testovací databázi
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Níže uvedený snímek obrazovky ukazuje velikosti datových souborů, když v databázi není nic uloženo:
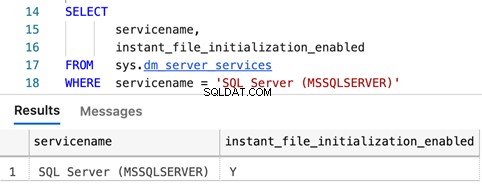
Dotazy k určení, zda je povolena okamžitá inicializace souboru
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'

Windows TSQL kódy
Vytvoření databáze a tabulek
DROP DATABASE IF EXISTS test
CREATE DATABASE test
ON
(FILENAME= 'S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test.mdf', NAME = test, FILEGROWTH = 128MB)
LOG ON
(FILENAME= ''S:\Program Files\Microsoft SQL Server\MSSQL15.WINDOWS\MSSQL\DATA\test_log.ldf',NAME = test_log, FILEGROWTH = 64MB);
CREATE TABLE test.dbo.windows(
long_string NVARCHAR(MAX) NOT NULL
)
Velikost souborů MDF a LDF pro testovací databázi
SELECT
DB_NAME(database_id) AS 'DB',
type_desc AS 'Type',
state_desc AS 'State',
CONVERT(DECIMAL(10,2),size*8/1024) AS 'Size',
CONVERT(DECIMAL(10,2),growth*8/1024) AS 'Growth'
FROM sys.master_files
WHERE DB_NAME(database_id) = 'test'
Následující snímek obrazovky ukazuje velikosti datových souborů, když v databázi není nic uloženo:
Dotaz na zjištění, zda je povolena okamžitá inicializace souboru
SELECT
servicename,
instant_file_initialization_enabled
FROM sys.dm_server_services
WHERE servicename = 'SQL Server (MSSQLSERVER)'
Skript pro provedení příkazu INSERT:
@limit -> zde jsem zadal počet řádků, které se mají vložit do testovací tabulky
Pro Linux, protože jsem skript provedl pomocí SQLCMD, dal jsem funkci DATEDIFF na úplný konec. Dává mi vědět, kolik sekund celé spuštění trvá (u varianty Windows jsem mohl jednoduše nahlédnout do časovače v SQL Server Management Studio).
Celý řetězec 1 000 000 znaků jde místo „XXXX“. Uvádím to tak, abych to v tomto příspěvku pěkně představil.
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
DECLARE @i INT;
DECLARE @limit INT;
SET @StartTime = GETDATE();
SET @i = 0;
SET @limit = 1000;
WHILE(@i < @limit)
BEGIN
INSERT INTO test.dbo.ubuntu VALUES('XXXX');
SET @i = @i + 1
END
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Skript pro provedení příkazu DELETE
SET NOCOUNT ON
GO
DECLARE @StartTime DATETIME;
SET @StartTime = GETDATE();
DELETE FROM test.dbo.ubuntu;
SELECT DATEDIFF(SECOND,@StartTime,GETDATE()) AS 'Elapsed Seconds';
Získané výsledky
Všechny velikosti jsou vyjádřeny v MB. Všechna měření časování jsou vyjádřena v sekundách.
| INSERT Time | 1 000 záznamů | 5 000 záznamů | 10 000 záznamů | 25 000 záznamů | 50 000 záznamů |
| Linux | 4 | 23 | 43 | 104 | 212 |
| Windows | 4 | 28 | 172 | 531 | 186 |
| Velikost (MDF) | 1 000 záznamů | 5 000 záznamů | 10 000 záznamů | 25 000 záznamů | 50 000 záznamů |
| Linux | 264 | 1032 | 2056 | 5128 | 10184 |
| Windows | 264 | 1032 | 2056 | 5128 | 10248 |
| Velikost (LDF) | 1 000 záznamů | 5 000 záznamů | 10 000 záznamů | 25 000 záznamů | 50 000 záznamů |
| Linux | 104 | 264 | 360 | 552 | 148 |
| Windows | 136 | 328 | 392 | 456 | 584 |
| SMAZAT čas | 1 000 záznamů | 5 000 záznamů | 10 000 záznamů | 25 000 záznamů | 50 000 záznamů |
| Linux | 1 | 1 | 74 | 215 | 469 |
| Windows | 1 | 63 | 126 | 357 | 396 |
| DELETE Size (LDF) | 1 000 záznamů | 5 000 záznamů | 10 000 záznamů | 25 000 záznamů | 50 000 záznamů |
| Linux | 136 | 264 | 392 | 584 | 680 |
| Windows | 200 | 328 | 392 | 456 | 712 |
Klíčové statistiky
- Velikost MDF byla v průběhu celého testu v podstatě stejná, na samém konci se mírně lišila (ale nic moc šíleného).
- Načasování INSERTů bylo v Linuxu většinou lepší, kromě samotného konce, kdy Windows „vyhrál kolo“.
- Velikost souboru protokolu transakcí byla v Linuxu lépe zpracována po každém kole INSERTů.
- Časování pro DELETE bylo v Linuxu z větší části lepší, kromě samotného konce, kde Windows „vyhrál kolo“ (připadá mi zvláštní, že Windows vyhrál i poslední kolo INSERT).
- Velikost souborů protokolu transakcí po každém kole DELETE byla do značné míry shodná, pokud jde o vzestupy a pády mezi nimi.
- Rád bych otestoval 100 000 řádků, ale měl jsem trochu málo místa na disku, tak jsem to omezil na 50 000.
Závěr
Na základě výsledků získaných z tohoto testu bych řekl, že neexistuje žádný pádný důvod tvrdit, že varianta Linuxu funguje exponenciálně lépe než její protějšek Windows. Samozřejmě se v žádném případě nejedná o formální test, na kterém se můžete při takovém rozhodnutí opřít. Nicméně samotné cvičení pro mě bylo dostatečně zajímavé.
Tipoval bych, že SQL Server 2019 pro Windows je někdy trochu pozadu (ne o moc) kvůli vykreslování GUI na pozadí, což se na straně plotu Ubuntu Server neděje.
Pokud silně spoléháte na funkce a možnosti, které jsou exkluzivní pro Windows (alespoň v době psaní tohoto článku), rozhodně do toho jděte. V opačném případě jen stěží uděláte špatnou volbu tím, že půjdete do jednoho přes druhého.