Databáze je kritickou a důležitou součástí každé firmy nebo organizace. Rostoucí trendy předpovídají, že 82 % podniků očekává v příštích 12 měsících nárůst počtu databází. Hlavní výzvou každého DBA je zjistit, jak se vypořádat s masivním nárůstem dat, a to bude nejdůležitější cíl. Jak můžete zvýšit výkon databáze, snížit náklady a eliminovat prostoje, abyste svým uživatelům poskytli nejlepší možný zážitek? Je komprese dat možnost? Začněme a uvidíme, jak mohou být některé ze stávajících funkcí užitečné pro řešení takových situací.
V tomto článku se dozvíme, jak nám řešení komprese dat může pomoci optimalizovat řešení správy dat. V této příručce se budeme zabývat následujícími tématy:
- Přehled komprese
- Výhody komprese
- Nástin dat je technika komprese
- Diskuse o různých typech komprese dat
- Fakta o kompresi dat
- Aspekty implementace
- a další…
Komprese
Komprese je technika, a tedy operace citlivá na zdroje, ale s hardwarovými kompromisy. Je třeba myslet na nasazení komprese dat pro následující výhody:
- Efektivní správa prostoru
- Efektivní technika snižování nákladů
- Snadná správa zálohování databáze
- Efektivní využití N/W šířky pásma
- Bezpečné a rychlejší obnovení nebo obnovení
- Lepší výkon – snižuje nároky na paměť systému
Poznámka: Pokud je SQL Server omezen na CPU nebo paměť, nemusí komprese vyhovovat vašemu prostředí.
Komprese dat se vztahuje na:
- Hromady
- Seskupené indexy
- Neshlukované indexy
- Oddíly
- Indexovaná zobrazení
Poznámka: Velké objekty nejsou komprimovány (například LOB a BLOB)
Nejlépe se hodí pro následující aplikace:
- Tabulky protokolů
- Auditní tabulky
- Tabulky faktů
- Přehledy
Úvod
Komprese dat je technologie, která existuje od SQL Server 2008. Myšlenka komprese dat spočívá v tom, že v rámci databáze můžete selektivně vybírat tabulky, indexy nebo oddíly. I/O je nadále úzkým hrdlem při přesouvání informací mezi vstupy a výstupy z databáze. Komprese dat využívá výhody tohoto typu a pomáhá zvýšit efektivitu databáze. Protože víme, že rychlost sítě je mnohem nižší než rychlost zpracování, je možné dosáhnout zvýšení efektivity použitím výpočetního výkonu ke kompresi dat v databázi, aby se pohybovala rychleji. A pak znovu použijte výpočetní výkon, abyste dekomprimovali data na druhém konci. Obecně platí, že komprese dat snižuje prostor obsazený daty. Technika komprese dat je dostupná pro každou databázi a je podporována všemi edicemi SQL Server 2016 SP1. Předtím byla dostupná pouze na SQL Server Enterprise nebo Developer Edition, nikoli na Standard nebo Express.
Podpora funkcí

Typy komprese dat
V rámci SQL Serveru jsou k dispozici dva typy komprese dat, na úrovni řádků a na úrovni stránky.
Komprese na úrovni řádků funguje za scénou a převádí jakékoli datové typy s pevnou délkou na typy s proměnnou délkou. Zde se předpokládá, že data jsou často uložena v pevné délce typu, jako je char 100, a ve skutečnosti nevyplňují celých 100 znaků pro každý záznam. Malé zisky lze dosáhnout odstraněním tohoto nadbytečného prostoru ze stolu. Samozřejmě, pokud vaše datové tabulky nepoužívají textová a numerická pole s pevnou délkou, nebo pokud ano a ve skutečnosti ukládáte plně povolený počet znaků a číslic, pak budou zisky komprese v rámci schématu na úrovni řádků minimální. v nejlepším případě.
Koncept komprese je rozšířen na všechny datové typy s pevnou délkou, včetně char, int a float. SQL Server umožňuje šetřit místo ukládáním dat, jako by to byl typ s proměnnou velikostí; data se objeví a budou se chovat jako pevná délka.
Pokud jste například uložili hodnotu 100 do int SQL Server nemusí používat všech 32 bitů, místo toho jednoduše používá 8 bitů (1 bajt).
Komprese na úrovni stránky posouvá věci na jinou úroveň. Za prvé, automaticky aplikuje kompresi na úrovni řádků na datová pole s pevnou délkou, takže tyto zisky automaticky získáte ve výchozím nastavení. Pak navíc používá něco, čemu se říká komprese předpon a další techniku zvanou komprese slovníku.
Komprese řádků
Komprese řádků je vnitřní úrovní komprese, která ukládá řetězce pevných znaků pomocí formátu s proměnnou délkou bez ukládání prázdných znaků. Následující kroky se provádějí při kompresi na úrovni řádků.
- Všechny číselné datové typy jako int , plovoucí , desítkové, a peníze jsou převedeny na datové typy s proměnnou délkou. Například 125 uložený ve sloupci a datový typ sloupce je celé číslo. Pak víme, že k uložení celočíselné hodnoty se používají 4 bajty. Ale 125 lze uložit do 1 bajtu, protože do 1 bajtu lze uložit hodnoty od 0 do 255. Takže 125 lze uložit jako malý int , takže lze uložit 3 bajty.
- Char a Nchar datové typy jsou uloženy jako datové typy s proměnnou délkou. Například „SQL“ je uloženo v znaku (20) sloupec typu. Ale po kompresi budou použity pouze 3 bajty. Po kompresi dat není u tohoto typu dat uložen žádný prázdný znak.
- Metadata záznamu jsou omezena.
- Hodnoty NULL a 0 jsou optimalizovány a nezabírá se žádný prostor.
Komprese stránky
Komprese stránek je pokročilá úroveň komprese dat. Ve výchozím nastavení komprese stránky také implementuje kompresi na úrovni řádků. Komprese stránky je rozdělena do dvou typů
- komprese předpon a
- Komprese slovníku.
Komprese předpon
Při kompresi předpon pro každou stránku je pro každý sloupec na stránce načtena společná hodnota ze všech řádků a uložena pod záhlavím každého sloupce. Nyní je v každém řádku místo běžné hodnoty uložen odkaz na tuto hodnotu.
Komprese slovníku
Slovníková komprese je podobná kompresi prefixů, ale společné hodnoty se načítají ze všech sloupců a ukládají se do druhého řádku za záhlavím. Slovníková komprese hledá přesné shody hodnot ve všech sloupcích a řádcích na každé stránce.
Pro následující databázové objekty můžeme provést kompresi na úrovni řádků a stránek.
- Tabulka uložená na hromadě.
- Celá tabulka uložená jako seskupený index.
- Indexované zobrazení.
- Neshlukovaný index.
- Rozdělené indexy a tabulky.
Poznámka: Kompresi dat můžeme provést buď při vytváření jako CREATE TABLE, CREATE INDEX nebo po vytvoření pomocí příkazu ALTER s možností REBUILD jako ALTER TABLE …. PŘESTAVIT S.
Ukázka
WideWorldImporters databáze se používá během celého dema. Také DW v reálném čase databáze je považována za operaci komprese.
Pojďme si projít jednotlivé kroky podrobně:
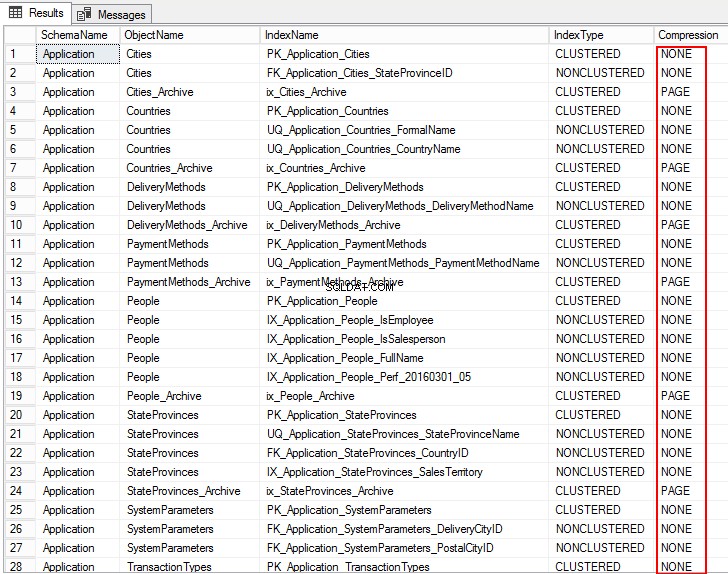
1. Chcete-li zobrazit nastavení komprese pro objekty v databázi, spusťte následující T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Následující výstup zobrazuje typ komprese jako PAGE, ROW a pro několik tabulek je to NONE. To znamená, že není nakonfigurován pro kompresi.
2. Chcete-li odhadnout kompresi, spusťte následující systémovou uloženou proceduru sp_estimate_data_compression_savings . V tomto případě se uložená procedura provede v tabulkách PurchaseOrderLines.
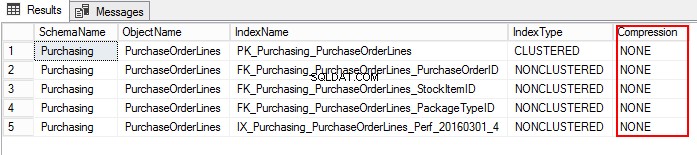
3. Zjistíme nastavení komprese PurchaseOrderLines spuštěním následujícího T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

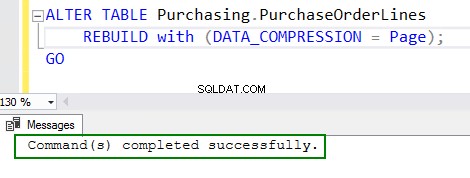
4. Povolte kompresi spuštěním příkazu ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
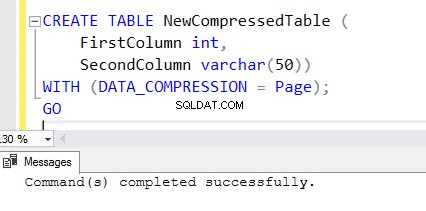
5. Chcete-li vytvořit novou tabulku s funkcí umožňující kompresi, přidejte na konec příkazu CREATE TABLE klauzuli WITH. Níže můžete vidět příkaz CREATE TABLE použitý k vytvoření NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakta o kompresi dat
Pojďme si projít některé aktuální informace o kompresi
- Na systémové tabulky nelze použít kompresi
- V tabulce nelze povolit kompresi, pokud velikost řádku přesáhne 8060 bajtů.
- Komprimovaná data se ukládají do mezipaměti ve fondu vyrovnávacích pamětí; znamená to rychlejší dobu odezvy
- Povolení komprese může způsobit změnu plánů dotazů, protože data jsou uložena pomocí jiného počtu stránek a počtu řádků na stránku.
- Neshlukované indexy nedědí vlastnost komprese
- Když je na haldě vytvořen seskupený index, zdědí seskupený index stav komprese haldy, pokud není určen alternativní stav komprese.
- Komprese na úrovni ROW a PAGE lze povolit a zakázat, offline nebo online.
- Pokud se nastavení haldy změní, všechny indexy bez klastrů je třeba znovu vytvořit.
- Požadavky na místo na disku pro povolení nebo zakázání komprese řádků nebo stránky jsou stejné jako pro vytváření nebo opětovné sestavení indexu.
- Když jsou oddíly rozděleny pomocí příkazu ALTER PARTITION, oba oddíly zdědí atribut komprese dat původního oddílu.
- Když jsou dva oddíly sloučeny, výsledný oddíl zdědí atribut komprese dat cílového oddílu.
- Chcete-li přepnout oddíl, musí vlastnost komprese dat oddílu odpovídat vlastnosti komprese tabulky.
- Tabulky a indexy Columnstore jsou vždy uloženy s kompresí Columnstore.
- Komprese dat není kompatibilní s řídkými sloupci, takže tabulku nelze komprimovat.
Scénář v reálném čase
Pojďme si projít techniku komprese dat a porozumět klíčovým parametrům komprese dat.
Chcete-li zkontrolovat místo, které každá tabulka používá, spusťte následující T-SQL. Výstup dotazu nám poskytuje podrobné informace o použití každé tabulky. To by byl rozhodující faktor pro implementaci komprese dat.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
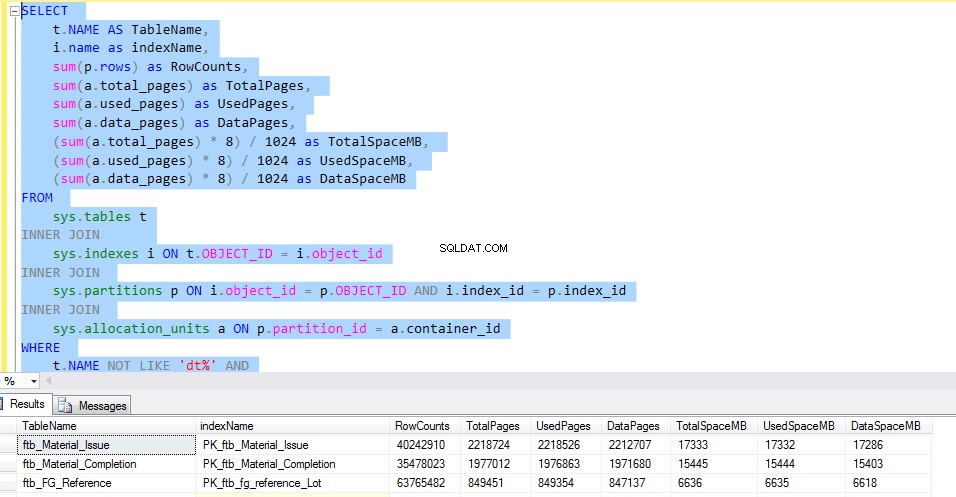
Podívejme se na ftb_material_Issue tabulka faktů. Tabulka faktů má číselné datové typy BIGINT.
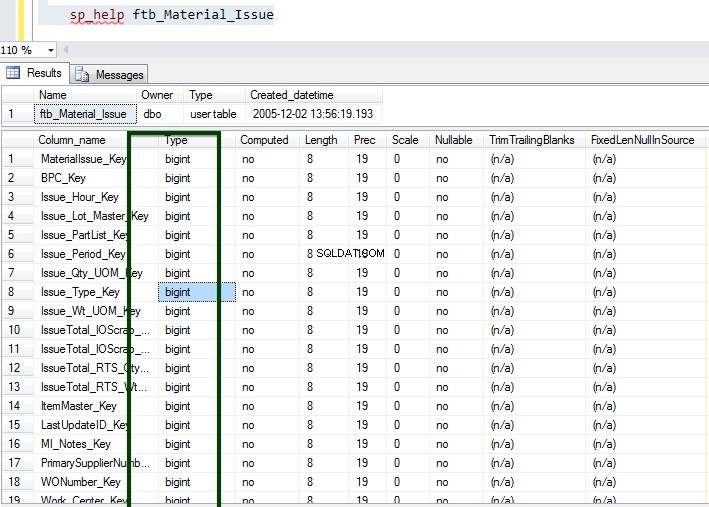
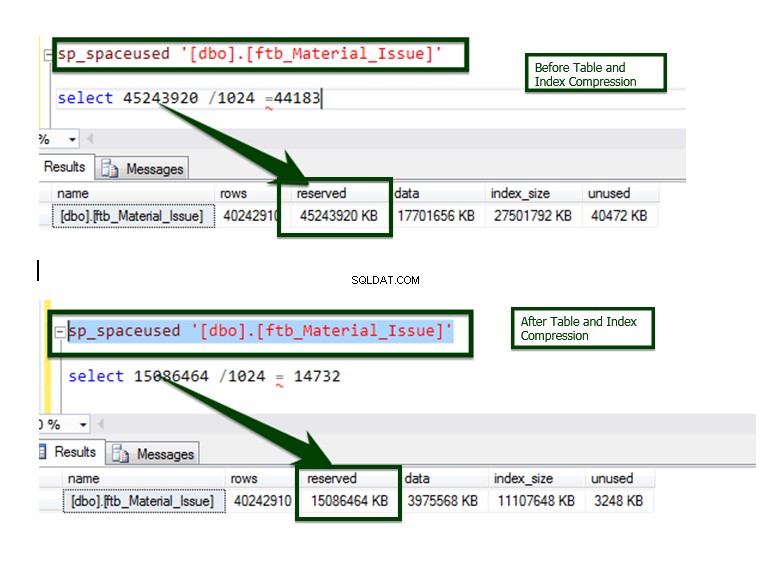
Nyní spusťte uloženou proceduru sp_spaceused, abyste porozuměli podrobnostem tabulky. Více o příkazu sp_spaceused se můžete dozvědět zde.
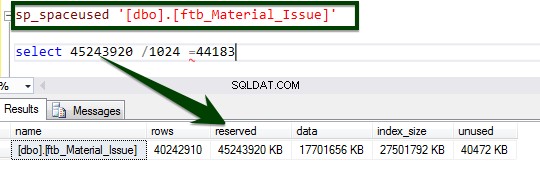
Povolte kompresi na úrovni tabulky spuštěním následujícího T-SQL. Na serveru bylo spuštěno následující T-SQL a komprimace stránky na úrovni tabulky trvala 34 minut a 14 sekund.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
Během provádění příkazu tabulky ALTER můžete vidět kolísání CPU a I/O.
Nyní proveďte srovnání komprese dat Před v/s po. Velikost tabulky přibližně ~45 GB se sníží na ~15 GB.
Proces je implementován na většině objektů pomocí automatického skriptu a zde je konečný výsledek srovnání.
Porovnání dat mezi před a po operaci komprese indexu.

Shrnutí
Komprese dat je velmi účinná technika ke snížení velikosti dat; menší množství dat vyžaduje méně I/O procesů. Přidání komprese do databáze zvyšuje zatížení požadavků na CPU. Budete se muset ujistit, že máte dostupnou kapacitu pro zpracování, abyste těmto změnám mohli efektivně vyhovět. Je tedy lepší udělat si nejprve malý průzkum a podívat se na typy zisků, které lze očekávat, než použijete úpravy umožňující kompresi dat. Je to velmi výhodné v nastavení cloudové databáze, kde jsou zahrnuty náklady.
Postupně komprese (nedělejte je všechny najednou) a komprimujte během období nízké aktivity. Komprese dat a komprese záloh pěkně koexistují a mohou vést k další úspoře úložného prostoru, takže do toho a dopřejte si to.
Nejen, že komprese snižuje velikost fyzických souborů, ale také snižuje diskové vstupy a výstupy, což může výrazně zvýšit výkon mnoha databázových aplikací spolu se zálohami databáze.
Rozhodování o implementaci komprese je snazší, pokud známe základní infrastrukturu a obchodní požadavky. K pochopení a odhadu úspor komprese můžeme rozhodně použít dostupný systémový postup. Tato uložená procedura neposkytuje žádné takové podrobnosti, které by vám řekly, jak komprese pozitivně nebo negativně ovlivní váš systém. Je zřejmé, že existují kompromisy pro jakýkoli druh komprese. Pokud máte stejné vzory velkých dat, pak je komprese klíčem k úspoře místa. S rostoucím výkonem CPU a každý systém vázaný na vícejádrové struktury může komprese vyhovovat mnoha systémům. Doporučil bych otestovat vaše systémy. Otestujte, zda výkon nebude negativně ovlivněn. Pokud index obsahuje mnoho aktualizací a mazání, náklady na CPU na kompresi a dekomprimaci dat mohou převážit nad úsporami I/O a RAM z komprese dat. Ne každá databáze nebo tabulka bude automaticky vhodným kandidátem na použití komprese, takže je nejlepší udělat si nejprve malý průzkum, abyste viděli, jaké druhy zisků lze očekávat, než použijete úpravy umožňující kompresi dat ve vašich databázích. Musíte otestovat kompresi, abyste zjistili, zda funguje dobře ve vašem prostředí, protože nemusí fungovat dobře v databázích s těžkými vložkami.
Odkazy
Edice a podporované funkce SQL Server 2016
Komprese dat
Implementace komprese řádků
Implementace komprese stránky