Replikace databáze je technologie pro distribuci dat z primárního serveru na sekundární servery. Replikace funguje na konceptu Master-Slave, kde Master databáze distribuuje data na jeden nebo více podřízených serverů. Replikaci lze nastavit mezi více instancemi SQL Serveru na stejném serveru NEBO ji lze nastavit mezi více databázovými servery v rámci stejných nebo geograficky oddělených datových center.
Používání replikace SQL Serveru má dvě hlavní výhody:
- Pomocí replikace můžeme získat data téměř v reálném čase, která lze použít pro účely vytváření zpráv. Pokud například chcete oddělit zatížení OLTP náročné na zápis na jednom serveru a zatížení náročné na čtení na jiném serveru, můžete nastavit replikaci tak, aby byla data na obou serverech synchronizována.
- Druhou výhodou je, že můžete naplánovat spuštění replikace v konkrétní čas. Pokud například chcete, aby server sestav obsahoval data dokončeného dne, můžete odpovídajícím způsobem naplánovat snímek replikace. Pro práci s aktuálními daty nepotřebujeme psát další logiku.
Replikace nabízí velkou flexibilitu. Pomocí replikace můžeme odfiltrovat řádky a také můžeme replikovat podmnožinu dat libovolné tabulky. Můžeme změnit replikovaná data nebo replikovat pouze aktualizovat a vložit a ignorovat odstranění. Můžeme také replikovat data z jiného databázového systému, jako je Oracle.
Součásti replikace
Existuje sedm základních součástí replikace serveru SQL Server. Následuje seznam:
- Vydavatel.
- Distributor.
- Předplatitel.
- Články.
- Publikace.
- Přihlášení k odběru.
- Vytáhněte odběr.
Níže jsou uvedeny podrobnosti:
Články
Článek je databázový objekt, jako je tabulka SQL nebo uložená procedura. Jak jsem uvedl výše, pomocí replikace můžeme filtrovat data nebo můžeme replikovat vybraný sloupec tabulky, takže sloupce nebo řádky tabulky jsou považovány za články.
Publikace
Články nelze replikovat, dokud se nestanou součástí publikace. Publikace je skupina objektů Články/databáze. Představuje také datovou sadu, která bude replikována SQL Serverem.
Vydavatel
Publisher obsahuje hlavní databázi, která obsahuje data, která je třeba publikovat. Určuje, jaká data by měla být distribuována všem účastníkům.
Distributor
Distributor je mostem mezi vydavatelem a předplatitelem. Distributor shromažďuje všechna zveřejněná data a uchovává je až do odeslání všem odběratelům. Je to most mezi vydavatelem a předplatitelem. Podporuje více vydavatelů a koncept předplatitelů. Konfigurace distributora na samostatné instanci SQL nebo samostatném serveru není povinná. Pokud jej nenakonfigurujeme, může vydavatel fungovat jako distributor. Organizace, které mají replikaci ve velkém měřítku, mohou nakonfigurovat distributora na samostatném systému.
Odběratelé
Předplatitel je konec zdroje nebo cíl, do kterého budou přenášena data nebo replikovaná publikace. V replikaci je jeden vydavatel, může mít více odběratelů.
Přihlášení k odběru
V předplatném push vydavatel aktualizuje data předplatiteli. V předplatném Push je předplatitel pasivní. Vydavatel zasílá články nebo publikace všem svým odběratelům. Na základě požadavku organizace můžete v průvodci vytvářením replikace na obrazovce vybrat předplatné, které se má použít. Replikace transakcí a replikace peer-to-peer využívá předplatné Push k udržení dostupnosti dat v reálném čase.
Vytažení odběru
V předplatném Pull si všichni předplatitelé vyžádají nová data nebo aktualizovaná data od svého vydavatele. V předplatném pull můžeme řídit, jaká data nebo změny dat jsou pro předplatitele potřeba. Je to užitečné, když změněná data nepotřebujeme okamžitě.
Typy replikace
SQL Server podporuje tři typy replikace:
- Transakční replikace.
- Replikace snímku.
- Sloučit replikaci.
Transakční replikace
Transakční replikace, jakékoli změny schématu, změny dat v databázi vydavatele budou replikovány do databáze odběratelů. Kdykoli v databázi vydavatele dojde k jakékoli operaci aktualizace, odstranění nebo vložení, změny jsou sledovány a tyto změny jsou odeslány do databází odběratelů. Transakční replikace odesílá přes síť pouze omezené množství dat. Navíc změny probíhají téměř v reálném čase, a proto je lze použít k nastavení místa DR nebo je lze použít k rozšíření operací podávání zpráv. Transakční replikace je ideální pro následující situace:
- Pokud chcete nastavit systém, kde by se změny provedené u vydavatele měly okamžitě projevit na odběratelích.
- Vydavatel má vysokou nízkou INSERT, UPDATES a DELETE.
- Pokud chcete nastavit význam heterogenní replikace, vydavatele nebo předplatitele pro jiné databáze než SQL Server, jako je Oracle.
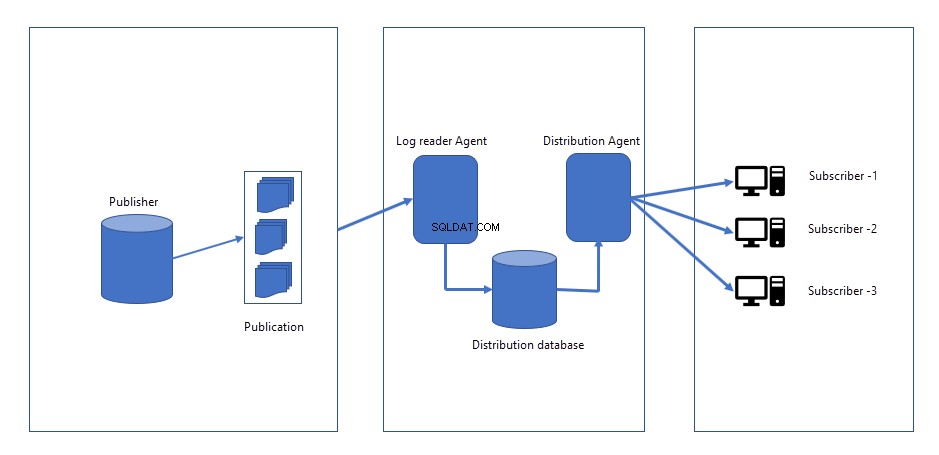
Po provedení jakýchkoli změn v databázi vydavatele se změny zaznamenají do souboru protokolu v databázi vydavatele. Stránky distributora/vydavatele, budou vytvořeny dvě pracovní pozice.
- Agent snímku :Úloha agenta snímku generuje snímek schématu, dat objektů, které chceme replikovat nebo publikovat. Soubory snímku lze uložit na vydavatelský server nebo do síťového umístění. Když replikaci zahájíme poprvé, vytvoří snímek a použije jej na všechny odběratele. Snapshot agent zůstává nečinný, dokud není spuštěn ručně nebo naplánován na spuštění v konkrétní čas.
- Agent čtečky protokolů :Úloha agenta pro čtení protokolů běží nepřetržitě. Přečte provedené změny (INSERT, UPDATES a DELETE) z transakčního protokolu databáze vydavatele a odešle je distribučnímu agentovi.
- Distribuční agent :Jakmile jsou změny načteny z agenta pro čtení protokolů, distribuční agent odešle všechny změny předplatitelům.
Když konfigurujeme transakční replikaci, provádí následující činnosti
- Zahájí se pořízením Prvního snímku publikačních dat a databázových objektů a snímku použitého u odběratelů.
- Agent pro čtení protokolů průběžně sleduje T-Log vydavatele a pokud dojde k nějakým změnám, zašle je distributorovi nebo přímo předplatitelům.
Následující obrázek znázorňuje, jak transakční replikace funguje:
Výhody:
- Replikaci transakcí lze použít jako záložní SQL server nebo ji lze použít pro vyrovnávání zátěže nebo oddělení systému hlášení a systému OLTP.
- Server vydavatele replikuje data na server předplatitele s nízkou latencí.
- Pomocí transakční replikace lze implementovat replikaci na úrovni objektu.
- Transakční replikaci lze použít, když potřebujete chránit méně dat a měli byste mít plán rychlé obnovy dat.
Nevýhody:
- Jakmile se replikace nastaví, změny schématu na vydavateli se na předplatitelském serveru nepoužijí. Tyto změny musíme provést ručně tak, že vygenerujeme nový snímek a použijeme jej na předplatitele.
- Pokud změníme servery, musíme překonfigurovat replikaci.
- Pokud se transakční replikace používá jako nastavení DR, musíme přepnout na selhání ručně.
Replikace snímku
Replikace snímků vygeneruje úplný obrázek/snímek publikace podle definovaného plánu a odešle soubory snímků předplatitelům. Když dojde k replikaci snímku, cílová data budou nahrazena novým snímkem. Replikace snímků je nejlepší volbou, když jsou data méně nestálá. Například hlavní tabulky jako City, Zipcode, Pincode jsou nejlepšími kandidáty na replikaci snímků.
Při konfiguraci replikace snímků jsou definovány následující důležité součásti:
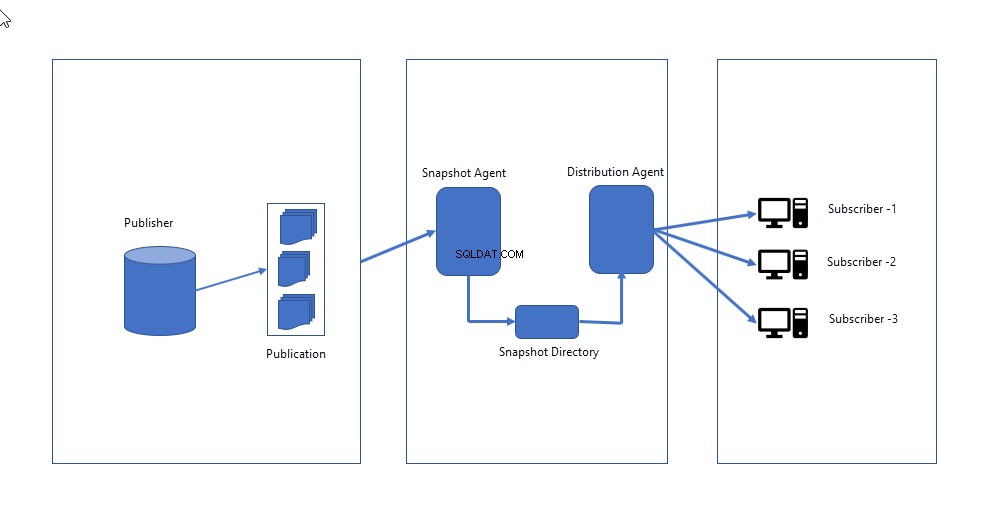
- Agent snímku :Vytvoří kompletní obraz schématu a dat definovaných v publikaci a odešle jej distributorovi. Snapshot agent zůstane nečinný, dokud nebude spuštěn ručně NEBO naplánován na spuštění v konkrétní čas.
- Distributorský agent :Odešle soubory snímků předplatitelům a použije schéma a data nahrazením stávajícího.
Replikace snímků provádí následující činnosti:
- Podle definovaného plánu umístí agent snímku sdílený zámek na schéma a data, která mají být publikována.
- Celý snímek publikovaných dat zkopírován na konec distributora. Snapshot agent vytvoří tři soubory
- Soubor do vytvořeného databázového schématu publikovaných dat.
- Soubor BCP pro export dat v tabulkách SQL
- Indexovat soubory pro export dat indexu.
- Jakmile jsou soubory vytvořeny, agent snímku uvolní sdílené zámky na publikovaná data a data.
- Agenti distribuce spouštějí a nahrazují schéma odběratele a data pomocí souborů vytvořených agentem snímku.
Následující obrázek ukazuje, jak funguje replikace snímků.
Výhody
- Nastavení replikace snímků je velmi jednoduché. Pokud se data nemění často, je replikace snímků velmi vhodnou volbou.
- Můžete určit, kdy chcete odeslat data. Například hlavní tabulka, která má velký objem dat, ale mění se méně často, než můžete replikovat data, když je provoz nízký.
Nevýhody
- Snímek generovaný agentem snímku obsahuje změněná a nezměněná publikovaná data, takže snímek přenášený přes síť může způsobit zpoždění a ovlivnit další operace.
- S přibývajícími daty se zvětšuje velikost snímku a vytvoření a distribuce snímku odběratelům zabere více času.
Sloučit replikaci
Slučovací replikaci lze použít, když potřebujeme spravovat změny na více serverech a tyto změny je třeba konsolidovat.
Když nakonfigurujeme slučovací replikaci, vytvoří se následující součásti:
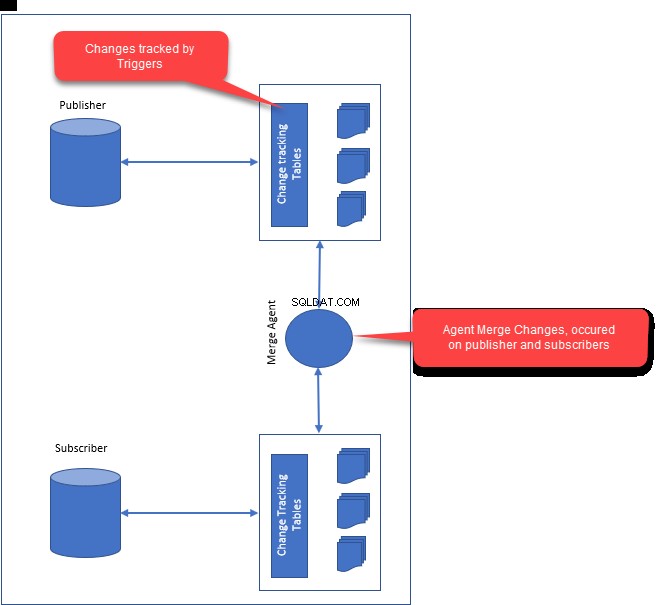
- Agent snímku :Agent snímku generuje první snímek dat publikace a databázových objektů. Jakmile bude snímek vytvořen, bude distribuován všem odběratelům.
- Agent sloučení :Slučovací agent je zodpovědný za řešení konfliktů mezi vydavatelem a odběrateli. Jakékoli konflikty jsou vyřešeny pomocí agenta sloučení, který používá řešení konfliktů. V závislosti na tom, jak jste nakonfigurovali řešení konfliktů, konflikty vyřeší agent sloučení.
Když nakonfigurujeme slučovací replikaci, provádí následující činnosti:
- Iniciuje se pořízením snímku publikačních dat a databázových objektů a snímku použitého u odběratelů.
- Při konfiguraci slučovací replikace vytváří spouštěče pro vydavatele a odběratele. Spouštěče jsou zodpovědné za sledování následných změn a úprav tabulek u vydavatele a odběratelů.
- Když se vydavatel a předplatitelé připojí k síti, budou změny datových řádků a úprava schématu vzájemně synchronizovány. Při slučování změn vydavatele a odběratelů řeší slučovací agent konflikty na základě podmínek definovaných ve slučovacím agentovi.
Slučovací replikace se používá v prostředích server-klient a je ideální pro situace, kdy předplatitelé potřebují načíst data od vydavatele, provádět změny offline a poté synchronizovat změny s vydavatelem a ostatními předplatiteli.
Mohou nastat praktické situace, kdy stejný řádek změní různí vydavatelé a předplatitelé. V té době se agent Merge podívá na to, jaké řešení konfliktů je definováno, a podle toho provede změny.
SQL Server jednoznačně identifikuje sloupec pomocí globálně jedinečného identifikátoru pro každý řádek v publikované tabulce. Pokud tabulka již má sloupec s jedinečným identifikátorem, SQL Server tento sloupec automaticky použije. V opačném případě přidá do tabulky sloupec rowguid a vytvoří index založený na sloupci.
Spouštěče budou vytvořeny na publikovaných tabulkách na vydavatelích i odběratelích. Používají se ke sledování změn na základě změn řádků nebo sloupců.
Následující obrázek ukazuje, jak funguje slučovací replikace:
Výhody:
- Toto je jediný způsob, jak zvládnout konsolidaci změn na více serverových datech.
Nevýhody:
- Replikace a synchronizace obou konců zabere spoustu času.
- Je nízká konzistence, protože musí být synchronizováno mnoho stran.
- Pokud jsou stejné řádky ovlivněny u více než jednoho odběratele a vydavatele, může dojít ke konfliktům při slučování replikace. Lze to opravit pomocí řešení konfliktů, ale zkomplikuje to nastavení replikace.
Kód T-SQL pro kontrolu konfigurace replikace
Nakonfiguroval jsem replikaci snímku a transakční replikaci na dvou instancích mého počítače. Pomocí dynamické správy SQL (DMV) můžeme zkontrolovat konfiguraci replikace. Pro kontrolu konfigurace replikace můžeme použít T-SQL kód. Kód skriptu vyplní následující:
- Název databáze předplatitelů.
- Jméno vydavatele.
- Typ předplatného.
- Databáze vydavatelů.
- Jméno replikačního agenta.
Níže je skript:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Následuje výstup:

Shrnutí
V tomto článku jsem vysvětlil:
- Základ a výhody Replikace a jejích komponent.
- Transakční replikace.
- Replikace snímku.
- Sloučit replikaci.