Service Pack 2 pro SQL Server 2014 byl vydán minulý měsíc (přečtěte si poznámky k vydání zde) a obsahuje nový příkaz DBCC:DBCC CLONEDATABASE . Byl jsem docela nadšený, když jsem viděl tento příkaz představený, protože poskytuje velmi snadné způsob kopírování databázového schématu, včetně statistik , který lze použít k testování výkonu dotazu bez nutnosti veškerého prostoru potřebného pro data v databázi. Konečně jsem si udělal čas na otestování DBCC CLONEDATABASE a porozumět omezením a musím říct, že to byla docela zábava.
Základy
Začal jsem vytvořením klonu databáze AdventureWorks2014 a spuštěním dotazu na zdrojovou databázi a poté na klonovou databázi:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Když se podívám na výstup I/O a TIME, vidím, že dotaz na zdrojovou databázi trval déle a vygeneroval mnohem více I/O, což se očekává, protože klonová databáze v sobě nemá žádná data:
/* SOURCE databáze */
SQL Server Execution Times:
Čas CPU =0 ms, uplynulý čas =0 ms.
Čas analýzy a kompilace serveru SQL Server:
Čas CPU =0 ms, uplynulý čas =4 ms.
(121317 ovlivněných řádků)
Tabulka 'SalesOrderHeader'. Počet skenů 0, logické čtení 371567, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Podrobnosti prodejní objednávky'. Počet skenů 5, logické čtení 1361, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
(1 dotčený řádek)
Časy spuštění serveru SQL:
Čas CPU =686 ms, uplynulý čas =2548 ms.
/* CLONE databáze */
SQL Server Execution Times:
Čas CPU =0 ms, uplynulý čas =0 ms.
Čas analýzy a kompilace serveru SQL Server:
Čas CPU =12 ms, uplynulý čas =12 ms.
(0 ovlivněných řádků)
Tabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'SalesOrderHeader'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Podrobnosti prodejní objednávky'. Počet skenů 5, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
(1 dotčený řádek)
SQL Server Execution Times:
Čas CPU =0 ms, uplynulý čas =83 ms.
Pokud se podívám na prováděcí plány, jsou stejné pro obě databáze kromě skutečných hodnot (množství dat, které plánem skutečně prošlo):
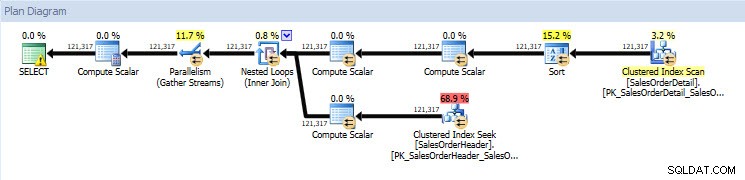 Databáze Query Plan for AdventureWorks2014
Databáze Query Plan for AdventureWorks2014
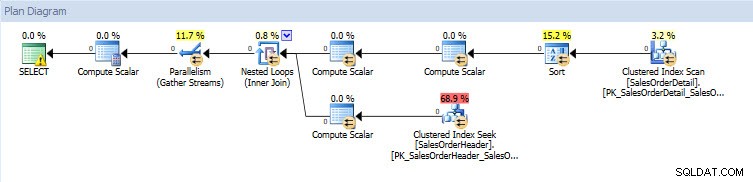 Plán dotazů pro databázi AdventureWorks2014_CLONE
Plán dotazů pro databázi AdventureWorks2014_CLONE
Zde je hodnota DBCC CLONEDATABASE je zřejmé – mohu získat prázdnou kopii databáze komukoli (podpora produktů Microsoft, můj kolega DBA atd.) a nechat ho znovu vytvořit a prošetřit problém, a nepotřebují k tomu potenciálně stovky GB místa na disku to. Melissin červencový T-SQL úterní příspěvek obsahuje podrobné informace o tom, co se děje během procesu klonování, takže doporučuji přečíst si ho pro více informací.
Je to tak?
Ale... mohu udělat více s DBCC CLONEDATABASE ? To je skvělé, ale myslím, že s prázdnou kopií databáze můžu dělat spoustu dalších věcí. Pokud si přečtete dokumentaci pro DBCC CLONEDATABASE , uvidíte tento řádek:
Moje první myšlenka byla:„optimalizátor dotazů – hmm… mohu to použít jako možnost pro testování upgradů ?“
No, klonovaná databáze je pouze pro čtení, ale myslel jsem si, že bych stejně zkusil změnit některé možnosti. Pokud bych například mohl změnit režim kompatibility, bylo by to opravdu skvělé, protože bych pak mohl testovat změny CE v SQL Server 2014 i SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Zobrazuje se mi chyba:
Zpráva 3906, úroveň 16, stav 1Nepodařilo se aktualizovat databázi "AdventureWorks2014_CLONE", protože databáze je pouze pro čtení.
Zpráva 5069, úroveň 16, stav 1
Příkaz ALTER DATABASE se nezdařil.
Hm Mohu změnit model obnovení?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Můžu. To se nezdá fér. No, je to jen pro čtení, můžu to změnit?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
ANO! Než se začnete příliš vzrušovat, dovolte mi zanechat tuto poznámku z dokumentace přímo zde:
Poznámka Nově vygenerovaná databáze generovaná z DBCC CLONEDATABASE není podporována pro použití jako produkční databáze a je primárně určena pro účely odstraňování problémů a diagnostické účely. Po vytvoření databáze doporučujeme klonovanou databázi odpojit.Zopakuji tento řádek z dokumentace a zvýrazním ho tučně a červeně jako přátelský, ale extrémně důležitý připomenutí:
Nově vygenerovaná databáze vygenerovaná z DBCC CLONEDATABASE není podporována pro použití jako produkční databáze a je primárně určena pro účely odstraňování problémů a diagnostické účely.To je v pořádku, rozhodně jsem to nehodlal použít pro výrobu, ale teď to mohu použít pro testování! NYNÍ mohu změnit režim kompatibility a NYNÍ jej mohu zálohovat a obnovit v jiné instanci pro testování!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
JE TO VELKÉ.
Ve svém posledním příspěvku jsem mluvil o příznaku trasování 2389 a testování s novým nástrojem Cardinality Estimator, protože, přátelé, potřebujete testovat s novým CE před upgradem. Pokud neprovedete testování a v rámci upgradu změníte režim kompatibility na 120 (SQL Server 2014) nebo 130 (SQL Server 2016), riskujete, že budete pracovat v protipožárním režimu, pokud narazíte na regrese s novým CE. Nyní můžete být v pohodě a výkon může být po upgradu ještě lepší. Ale... nechtěli byste si být jisti?
Velmi často, když zmiňuji testování před upgradem, je mi řečeno, že neexistuje žádné prostředí, ve kterém by bylo možné testování provádět. Vím, že někteří z vás mají testovací prostředí. Někteří z vás mají Test, Dev, QA, UAT a kdo ví co ještě. Máte štěstí.
Pro ty z vás, kteří uvádějí, že nemáte žádné testovací prostředí, ve kterém byste mohli testovat, vám dávám DBCC CLONEDATABASE . S tímto příkazem nemáte žádnou omluvu, abyste nespouštěli nejčastěji prováděné dotazy a těžké zásahy proti klonu vaší databáze. I když nemáte testovací prostředí, máte svůj vlastní stroj. Zálohujte databázi klonů z produkce, zrušte klon, obnovte zálohu do místní instance a poté otestujte. Databáze klonů zabírá na disku velmi málo místa a nevzniknou žádné spory o paměť nebo I/O, protože nejsou žádná data. Budete být schopen ověřit plány dotazů z klonu oproti plánům z vaší produkční databáze. Dále, pokud obnovíte na SQL Server 2016, můžete do testování začlenit Query Store! Povolte Query Store, proveďte testování v původním režimu kompatibility, poté upgradujte režim kompatibility a otestujte znovu. Můžete použít Query Store k porovnání dotazů vedle sebe! (Můžete říct, že právě teď tančím na židli?)
Úvahy
Opět by to nemělo být nic, co byste použili ve výrobě, a vím, že byste to neudělali, ale je třeba to opakovat, protože ve svém současném stavu DBCC CLONEDATABASE není zcela dokončeno . To je uvedeno v článku znalostní báze pod podporovanými objekty; objekty, jako jsou tabulky optimalizované pro paměť a tabulky souborů, se nekopírují, není podporován fulltext atd.
Databáze klonů nyní není bez nevýhod. Pokud neúmyslně spustíte nové sestavení indexu nebo aktualizaci statistik v této databázi, právě jste vymazali svá testovací data. Ztratíte původní statistiky, což je to, co jste pravděpodobně opravdu chtěli na prvním místě. Pokud například zkontroluji statistiky pro seskupený index na SalesOrderHeader právě teď, dostanu toto:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Původní statistiky pro SalesOrderHeader
Původní statistiky pro SalesOrderHeader
Nyní, když aktualizuji statistiky podle této tabulky, dostanu toto:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Aktualizované (prázdné) statistiky pro SalesOrderHeader
Aktualizované (prázdné) statistiky pro SalesOrderHeader
Jako další zabezpečení je pravděpodobně dobré zakázat automatické aktualizace statistik:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Pokud se stane, že neúmyslně aktualizujete statistiky, spusťte DBCC CLONEDATABASE a projít procesem zálohování a obnovy není tak těžké a během chvilky to zautomatizujete.
Data můžete přidávat do databáze. To by mohlo být užitečné, pokud chcete experimentovat se statistikami (např. různé vzorkovací frekvence, filtrované statistiky) a máte dostatek místa pro uložení kopie dat tabulky.
Bez dat v databázi zjevně nezískáte spolehlivě reprezentativní data o trvání a I/O. To je v pořádku. Pokud potřebujete data o skutečném využití zdrojů, pak potřebujete kopii své databáze se všemi daty v ní. DBCC CLONEDATABASE je opravdu o testování výkonu dotazu; a je to. V žádném případě to nenahrazuje tradiční testování upgradu – ale je to nová možnost pro ověření, jak SQL Server optimalizuje dotaz s různými verzemi a režimy kompatibility. Šťastné testování!