Je velmi snadné dokázat, že následující dva výrazy dávají přesně stejný výsledek:první den aktuálního měsíce.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); A jejich výpočet trvá přibližně stejně dlouho:
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
V mém systému trvalo dokončení obou dávek asi 175 sekund.
Proč byste tedy preferovali jednu metodu před druhou? Když jeden z nich opravdu zahrává s odhady mohutnosti .
Jako rychlý základ porovnejme tyto dvě hodnoty:
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Všimněte si, že skutečné hodnoty zde uvedené se budou měnit v závislosti na tom, kdy čtete tento příspěvek – „dnes“ odkazovaný v komentáři je 5. září 2013, den byl napsán tento příspěvek. Například v říjnu 2013 bude výstup být 2013-10-01 a 1786-04-01 .)
S tím mimo, dovolte mi ukázat vám, co tím myslím…
Repro
Vytvořme velmi jednoduchou tabulku pouze se shlukovaným DATE sloupec a načtěte 15 000 řádků s hodnotou 1786-05-01 a 50 řádků s hodnotou 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
A pak se podívejme na skutečné plány pro tyto dva dotazy:
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Grafické plány vypadají správně:
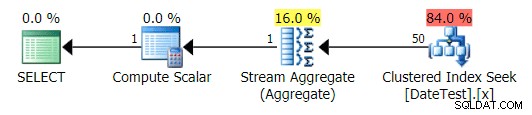
Grafický plán pro DATEDIFF(MONTH, 0, GETDATE()) dotaz
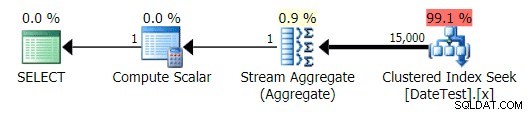
Grafický plán pro DATEDIFF(MONTH, GETDATE(), 0) dotaz
Ale odhadované náklady jsou mimo mísu – všimněte si, o kolik vyšší jsou odhadované náklady u prvního dotazu, který vrací pouze 50 řádků, ve srovnání s druhým dotazem, který vrací 15 000 řádků!

Mřížka výpisů s odhadovanými náklady
A karta Top Operations ukazuje, že první dotaz (hledá 2013-09-01 ) odhadoval, že by našel 15 000 řádků, zatímco ve skutečnosti našel pouze 50; druhý dotaz ukazuje opak:očekával, že najde 50 řádků odpovídajících 1786-05-01 , ale našel 15 000. Na základě nesprávných odhadů mohutnosti, jako je tento, si jistě dokážete představit, jaký drastický dopad by to mohlo mít na složitější dotazy na mnohem větší soubory dat.
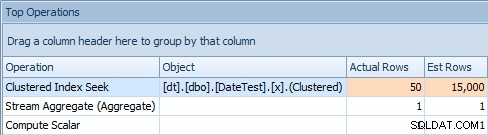
Hlavní karta Operace pro první dotaz [DATEDIFF(MONTH, 0, GETDATE())]
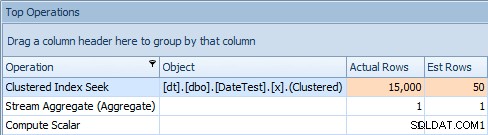
Hlavní karta Operace pro druhý dotaz [DATEDIFF(MONTH, 0, GETDATE())]
Mírně odlišná varianta dotazu používající jiný výraz pro výpočet začátku měsíce (zmíněný na začátku příspěvku) nevykazuje tento příznak:
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Plán je velmi podobný dotazu 1 výše, a pokud byste se nepodívali blíže, mysleli byste si, že tyto plány jsou ekvivalentní:
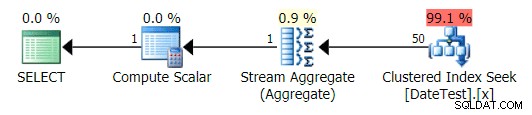
Grafický plán pro dotaz jiný než DATEDIFF
Když se však podíváte na záložku Top Operations zde, uvidíte, že odhad je neúprosný:
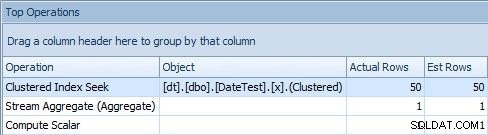
Hlavní operace zobrazující přesné odhady
U této konkrétní velikosti dat a dotazu je čistý dopad na výkon (zejména trvání a čtení) do značné míry irelevantní. A je důležité poznamenat, že samotné dotazy stále vracejí správná data; jde jen o to, že odhady jsou špatné (a mohly by vést k horšímu plánu, než jsem zde předvedl). To znamená, že pokud odvozujete konstanty pomocí DATEDIFF v rámci vašich dotazů tímto způsobem byste skutečně měli otestovat tento dopad ve vašem prostředí.
Proč se to tedy děje?
Jednoduše řečeno, SQL Server má DATEDIFF chyba, kdy při vyhodnocování výrazu pro odhad mohutnosti zamění druhý a třetí argument. Zdá se, že to zahrnuje neustálé skládání, alespoň periferně; v tomto článku Books Online je mnohem více podrobností o neustálém skládání, ale bohužel tento článek neodhaluje žádné informace o této konkrétní chybě.
Existuje oprava – nebo existuje?
Existuje článek znalostní báze (KB #2481274), který tvrdí, že problém řeší, ale má několik vlastních problémů:
- Článek znalostní báze tvrdí, že problém byl vyřešen v různých aktualizacích Service Pack nebo kumulativních aktualizacích pro SQL Server 2005, 2008 a 2008 R2. Tento příznak je však stále přítomen ve větvích, které tam nejsou výslovně zmíněny, i když od vydání článku zaznamenaly mnoho dalších CU. Tento problém mohu stále reprodukovat na SQL Server 2008 SP3 CU #8 (10.0.5828) a SQL Server 2012 SP1 CU #5 (11.0.3373).
- Nezapomíná se zmínit, že chcete-li mít z opravy prospěch, musíte zapnout příznak trasování 4199 (a „těžit“ ze všech ostatních způsobů, kterými může konkrétní příznak trasování ovlivnit optimalizátor). Skutečnost, že tento příznak trasování je pro opravu vyžadována, je zmíněna v související položce Connect, #630583, ale tato informace se nedostala zpět do článku znalostní báze. Ani článek znalostní báze, ani položka Connect neposkytují žádný pohled na příčinu (že argumenty pro
DATEDIFFbyly během hodnocení vyměněny). Pozitivní je, že spouštění výše uvedených dotazů se zapnutým příznakem trasování (pomocíOPTION (QUERYTRACEON 4199)) přináší plány, které nemají problém s nesprávným odhadem.
- Doporučuje vám to vyřešit problém pomocí dynamického SQL. V mých testech pomocí jiného výrazu (například výše uvedeného, který nepoužívá
DATEDIFF) překonal problém v moderních sestaveních SQL Server 2008 i SQL Server 2012. Doporučení dynamického SQL je zde zbytečně složité a pravděpodobně přehnané, protože problém by mohl vyřešit jiný výraz. Ale pokud byste měli používat dynamické SQL, udělal bych to tímto způsobem namísto způsobu, který doporučují v článku KB, především kvůli minimalizaci rizik vkládání SQL:DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(Můžete přidat
OPTION (RECOMPILE)tam, v závislosti na tom, jak chcete, aby SQL Server zpracovával sniffování parametrů.)To vede ke stejnému plánu jako předchozí dotaz, který nepoužívá
DATEDIFF, se správnými odhady a 99,1 % nákladů v hledání seskupeného indexu.Dalším přístupem, který by vás mohl svádět (a vámi, myslím tím mě, když jsem poprvé začal zkoumat), je použití proměnné k výpočtu hodnoty předem:
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Problém s tímto přístupem je, že s proměnnou skončíte se stabilním plánem, ale mohutnost bude založena na odhadu (a typ odhadu bude záviset na přítomnosti nebo nepřítomnosti statistik) . V tomto případě jsou zde odhadované vs. skutečné:
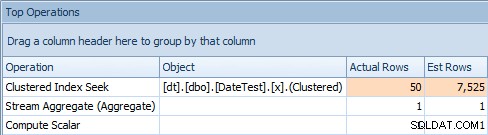
Hlavní karta Operace pro dotaz, který používá proměnnouTo zjevně není správné; zdá se, že SQL Server uhodl, že proměnná bude odpovídat 50 % řádků v tabulce.
SQL Server 2014
V SQL Server 2014 jsem našel trochu jiný problém. První dva dotazy jsou opraveny (změnami v odhadu mohutnosti nebo jinými opravami), což znamená, že DATEDIFF argumenty se již nepřepínají. Hurá!
Zdá se však, že do řešení použití jiného výrazu byla zavedena regrese – nyní trpí nepřesným odhadem (založeným na stejném 50% odhadu jako při použití proměnné). Toto jsou dotazy, které jsem spustil:
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Zde je tabulka výkazů porovnávající odhadované náklady a skutečné metriky doby běhu:
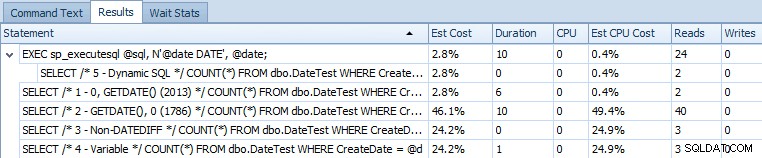
Odhadované náklady na 5 vzorových dotazů na SQL Server 2014
A toto jsou jejich odhadované a skutečné počty řádků (sestavené pomocí Photoshopu):

Odhadovaný a skutečný počet řádků pro 5 dotazů na SQL Server 2014
Z tohoto výstupu je zřejmé, že výraz, který dříve řešil problém, nyní zavedl jiný. Nejsem si jistý, zda se jedná o příznak běhu v CTP (např. něco, co bude opraveno), nebo zda jde skutečně o regresi.
V tomto případě nemá příznak trasování 4199 (sám o sobě) žádný účinek; nový odhad mohutnosti dělá odhady a jednoduše není správný. Zda to vede ke skutečnému problému s výkonem, závisí hodně na mnoha dalších faktorech mimo rozsah tohoto příspěvku.
Pokud narazíte na tento problém, můžete – alespoň u současných CTP – obnovit staré chování pomocí OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . Příznak trasování 9481 deaktivuje nový estimátor mohutnosti, jak je popsáno v těchto poznámkách k vydání (které jistě v určitém okamžiku zmizí nebo se alespoň přesunou). To zase obnoví správné odhady pro jiné než DATEDIFF verzi dotazu, ale bohužel stále neřeší problém, kdy se odhaduje na základě proměnné (a použití samotného TF9481 bez TF4199 nutí první dva dotazy vrátit se ke starému chování při výměně argumentů).
Závěr
Přiznám se, že to pro mě bylo velké překvapení. Děkuji Martinu Smithovi a t-clausen.dk za to, že vydrželi a přesvědčili mě, že jde o skutečný problém, nikoli o domnělý problém. Také velké díky Paulu Whiteovi (@SQL_Kiwi), který mi pomohl zachovat si zdravý rozum a připomněl mi věci, které bych neměl říkat. :-)
Jelikož jsem si této chyby nebyl vědom, byl jsem skálopevně přesvědčen, že lepší plán dotazů byl vygenerován jednoduše změnou textu dotazu, nikoli kvůli konkrétní změně. Jak se ukázalo, někdy jde o změnu dotazu, kterou byste předpokládali nebude žádný rozdíl, ve skutečnosti bude. Pokud tedy máte ve svém prostředí nějaké podobné vzorce dotazů, doporučuji je otestovat a ujistit se, že odhady mohutnosti vycházejí správně. A poznamenejte si je, abyste je při upgradu znovu otestovali.