Dělení oddílů je funkce serveru SQL Server, která se často implementuje ke zmírnění problémů souvisejících se správou, úkoly údržby nebo zamykáním a blokováním. Správa velkých tabulek se může zjednodušit pomocí dělení a může zlepšit škálovatelnost a dostupnost. Kromě toho může být vedlejším produktem rozdělování lepší výkon dotazů. Není to záruka ani dané, a není to hlavní důvod pro implementaci dělení, ale stojí za to si to prohlédnout, když rozdělujete velkou tabulku.
Pozadí
Rychlý přehled:funkce vytváření oddílů serveru SQL Server je k dispozici pouze ve verzích Enterprise a Developer Edition. Rozdělení lze implementovat během počátečního návrhu databáze nebo jej lze zavést poté, co tabulka již obsahuje data. Pochopte, že změna existující tabulky s daty na dělenou tabulku není vždy rychlá a jednoduchá, ale při dobrém plánování je to docela proveditelné a výhody lze rychle realizovat.
Dělená tabulka je taková, kde jsou data rozdělena do menších fyzických struktur na základě hodnoty pro konkrétní sloupec (nazývaný rozdělovací sloupec, který je definován ve funkci rozdělení). Pokud chcete data oddělit podle roku, můžete jako rozdělovací sloupec použít sloupec s názvem DateSold a všechna data za rok 2013 by byla umístěna v jedné struktuře, všechna data za rok 2012 by byla umístěna v jiné struktuře atd. Tyto samostatné sady dat umožňují cílenou údržbu (můžete přestavět pouze oddíl indexu, nikoli celý index) a umožňují rychlé přidávání a odebírání dat, protože je lze připravit předem, než budou skutečně přidány do tabulky nebo z ní odstraněny.
Nastavení
Abych prozkoumal rozdíly ve výkonu dotazů pro dělenou a nerozdělenou tabulku, vytvořil jsem dvě kopie tabulky Sales.SalesOrderHeader z databáze AdventureWorks2012. Nerozdělená tabulka byla vytvořena pouze s klastrovaným indexem na SalesOrderID, tradičním primárním klíči pro tabulku. Druhá tabulka byla rozdělena na OrderDate s OrderDate a SalesOrderID jako klastrovací klíč a neměla žádné další indexy. Všimněte si, že existuje mnoho faktorů, které je třeba vzít v úvahu při rozhodování, který sloupec použít pro rozdělení. Rozdělení často, ale rozhodně ne vždy, používá k definování hranic diskového oddílu pole data. Jako takový byl pro tento příklad vybrán OrderDate a k simulaci typické aktivity proti tabulce SalesOrderHeader byly použity vzorové dotazy. Příkazy k vytvoření a naplnění obou tabulek si můžete stáhnout zde.
Po vytvoření tabulek a přidání dat byly stávající indexy ověřeny a poté statistiky aktualizovány pomocí FULLSCAN:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader';GOEXEC sp_helpindex 'Sales.Part_SalesOrderHeader';PŘEJÍTE AKTUALIZOVAT STATISTIKY [Prodej].[Big_SalesOrderHeader] S FULLSTAT_SCAN]]LESSSELECTPart.WITH; '.' + so.name AS [Tabulka], ss.name AS [Statistika], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Řádek Úpravy]OD sys.stats JAKO ssINNER PŘIPOJIT sys.objects JAK tak ON ss.[id_objektu] =tak.[id_objektu]VNITŘNÍ PŘIPOJENÍ k sys.schemas JAKO sch ON tak.[schema_id] =sch.[schema_id]VNĚJŠÍ POUŽIŤ sys.dm_db_stats_properties (so.[object_id], ss.stats_id) JAKO spWHERE tak.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader'))AND ss.Kromě toho mají obě tabulky přesně stejnou distribuci dat a minimální fragmentaci.
Výkon pro jednoduchý dotaz
Před přidáním jakýchkoli dalších indexů byl proveden základní dotaz pro obě tabulky, aby se vypočítaly celkové částky vydělané prodejcem za objednávky zadané v prosinci 2012:
SELECT [SalesPersonID], SUM([TotalDue])FROM [Sales].[Big_SalesOrderHeader]WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31'GROUP BY [Sales] SELECT]SalesPerson [SalesPersonID], SUM([TotalDue])OD [Sales].[Part_SalesOrderHeader]KAM [Datum objednávky] BETWEEN '2012-12-01' A '2012-12-31'GROUP BY [SalesID]; STATISTIKA IO VÝSTUPTabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Big_SalesOrderHeader'. Počet skenů 9, logické čtení 2710440, fyzické čtení 2226, čtení napřed 2658769, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.Tabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Part_SalesOrderHeader'. Počet skenů 9, logické čtení 248128, fyzické čtení 3, čtení napřed 245030, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
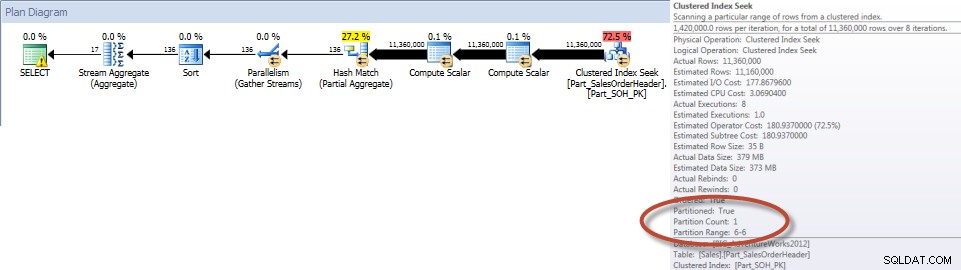
Součty podle prodejců za prosinec – Nerozdělená tabulka
Součty podle prodejců za prosinec – rozdělená tabulkaPodle očekávání musel dotaz na nerozdělenou tabulku provést úplné prohledání tabulky, protože neexistoval žádný index, který by jej podporoval. Naproti tomu dotaz na dělenou tabulku potřeboval pouze pro přístup k jedné části tabulky.
Abychom byli spravedliví, pokud by se jednalo o dotaz spouštěný opakovaně s různými rozsahy dat, existoval by příslušný neseskupený index. Například:
VYTVOŘTE NEZAHRNUTÝ INDEX [Big_SalesOrderHeader_SalesPersonID]NA [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);Po vytvoření tohoto indexu se při opětovném spuštění dotazu statistiky I/O sníží a plán se změní tak, aby se používal index bez klastrů:
STATISTIKA IO VÝSTUPTabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Big_SalesOrderHeader'. Počet skenů 9, logické čtení 42901, fyzické čtení 3, čtení napřed 42346, logické čtení 0, fyzické čtení 0, čtení napřed 0.
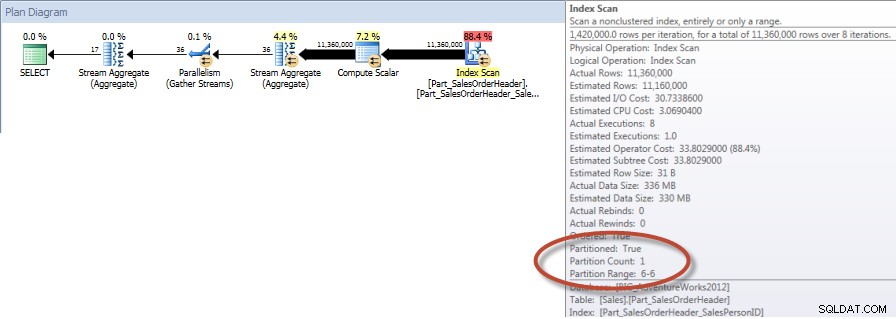
Součty podle prodejců za prosinec – NCI na nerozděleném stoleS podpůrným indexem vyžaduje dotaz na Sales.Big_SalesOrderHeader výrazně méně čtení než skenování seskupeného indexu proti Sales.Part_SalesOrderHeader, což není neočekávané, protože seskupený index je mnohem širší. Pokud vytvoříme srovnatelný neshlukovaný index pro Sales.Part_SalesOrderHeader, uvidíme podobná I/O čísla:
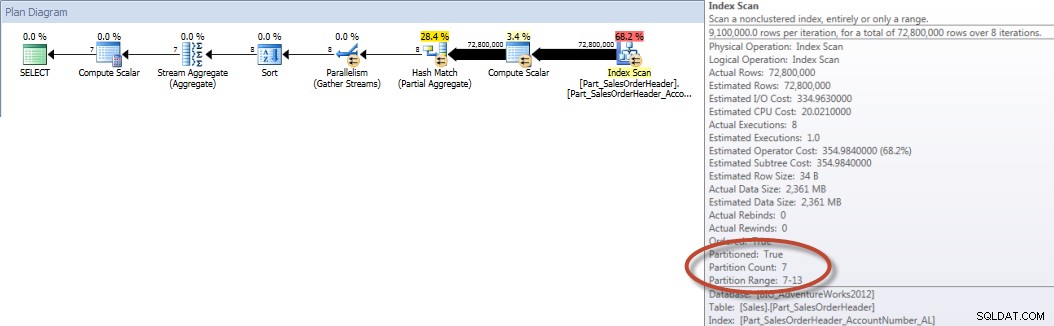
VYTVOŘTE NEZAHRNUTÝ INDEX [Part_SalesOrderHeader_SalesPersonID]NA [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);STATISTIKA IO VÝSTUPTabulka 'Part_SalesOrderHeader'. Počet skenů 9, logické čtení 42894, fyzické čtení 1, čtení napřed 42378, logické čtení 0, fyzické čtení 0, čtení dopředu 0.
Součty podle prodejců za prosinec – NCI na děleném stole s eliminacíA pokud se podíváme na vlastnosti neshlukovaného indexového skenování, můžeme ověřit, že engine přistupoval pouze k jednomu oddílu (6).
Jak bylo uvedeno původně, rozdělení není obvykle implementováno pro zlepšení výkonu. Ve výše uvedeném příkladu nemá dotaz na dělenou tabulku výrazně lepší výkon, pokud existuje vhodný neseskupený index.
Výkon pro ad-hoc dotaz
Dotaz na rozdělenou tabulku může v některých případech překonat stejný dotaz proti nerozdělené tabulce, například když dotaz musí používat seskupený index. I když je ideální, aby většinu dotazů podporovaly neshlukované indexy, některé systémy umožňují dotazy uživatelů ad-hoc a jiné mají dotazy, které se mohou spouštět tak zřídka, že nezaručují podporu indexů. Proti tabulce SalesOrderHeader může uživatel spustit následující dotaz, aby našel objednávky z prosince 2012, které bylo nutné odeslat do konce roku, ale neodeslaly se, pro konkrétní skupinu zákazníků a s celkovou splatností vyšší než 1000 $:
SELECT[SalesOrderID],[Datum objednávky],[Datum splatnosti],[Datum odeslání],[Číslo účtu],[ID zákazníka],[ID osoby prodeje],[SubTotal],[TotalDue]OD [Prodeje].[Big_Sadertal]WuDREHe ]> 1000AND [CustomerID] BETWEEN 10000 AND 20000AND [Datum objednávky] MEZI '2012-12-01' AND '2012-12-31'AND [DueDate] <'2012-12-31'AND> 12.12.2012 -31';GO SELECT[SalesOrderID],[Datum objednávky],[Datum splatnosti],[Datum expedice],[Číslo účtu],[ID zákazníka],[ID osoby prodeje],[SubTotal],[TotalDue]OD [Prodeje][Wrt_HERESales][Wrt_HERESales] [TotalDue]> 1000AND [CustomerID] MEZI 10000 A 20000AND [Datum objednávky] MEZI '2012-12-01' A '2012-12-31'A [DueDate] <'2012-12-12-3>01'2012-12-3 -12-31';GOSTATISTIKA IO VÝSTUPTabulka 'Big_SalesOrderHeader'. Počet skenů 9, logické čtení 2711220, fyzické čtení 8386, čtení napřed 2662400, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Part_SalesOrderHeader'. Počet skenování 9, logické čtení 248128, fyzické čtení 0, čtení napřed 243792, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
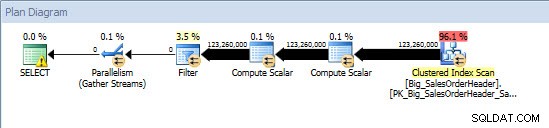
Ad-Hoc dotaz – Nerozdělená tabulka
Ad-Hoc dotaz – dělená tabulkaProti nerozdělené tabulce vyžadoval dotaz úplné prohledání seskupeného indexu, ale proti dělené tabulce dotaz prováděl hledání indexu seskupeného indexu, protože stroj používal eliminaci oddílů a četl pouze data, která nezbytně potřeboval. V tomto příkladu jde o významný rozdíl z hlediska I/O a v závislosti na hardwaru by to mohl být dramatický rozdíl v době provádění. Dotaz lze optimalizovat přidáním příslušného indexu, ale obvykle není možné indexovat každý single dotaz. Zejména u řešení, která umožňují ad-hoc dotazy, je fér říci, že nikdy nevíte, co uživatelé udělají. Dotaz se může spustit jednou a už se nikdy nespustí a vytvoření indexu poté je marné. Proto je při změně z nedělené tabulky na dělenou tabulku důležité vynaložit stejné úsilí a přístup jako běžné ladění indexu; chcete ověřit, že existují vhodné indexy pro podporu většiny dotazů.
Zarovnání výkonu a indexu
Dalším faktorem, který je třeba vzít v úvahu při vytváření indexů pro dělenou tabulku, je to, zda index zarovnat či nikoli. Indexy musí být zarovnány s tabulkou, pokud plánujete přepínat data do a z oddílů. Vytvořením neklastrovaného indexu v dělené tabulce se ve výchozím nastavení vytvoří zarovnaný index, kde se rozdělovací sloupec přidá jako zahrnutý sloupec do indexu.
Nezarovnaný index je vytvořen zadáním jiného schématu oddílu nebo jiné skupiny souborů. Sloupec rozdělení může být součástí indexu jako klíčový sloupec nebo zahrnutý sloupec, ale pokud není použito schéma rozdělení tabulky nebo je použita jiná skupina souborů, index nebude zarovnán.
Zarovnaný index je rozdělen stejně jako tabulka – data budou existovat v samostatných strukturách – a proto může dojít k odstranění oddílu. Nezarovnaný index existuje jako jedna fyzická struktura a v závislosti na predikátu nemusí poskytovat očekávaný přínos pro dotaz. Zvažte dotaz, který počítá prodeje podle čísla účtu, seskupené podle měsíce:
VYBERTE DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])OD [Sales].[Part_SalesOrderHeader]KDE [Datum objednávky] MEZI '2013-01-01' A '2013-07-31' SKUPINA PODLE ČÁSTI (MONTH,[OrderDate])ORDER BY DATEPART(MONTH,[OrderDate]);Pokud nejste s dělením tolik obeznámeni, můžete vytvořit index podobný tomuto, který bude dotaz podporovat (všimněte si, že je určena PRIMÁRNÍ skupina souborů):
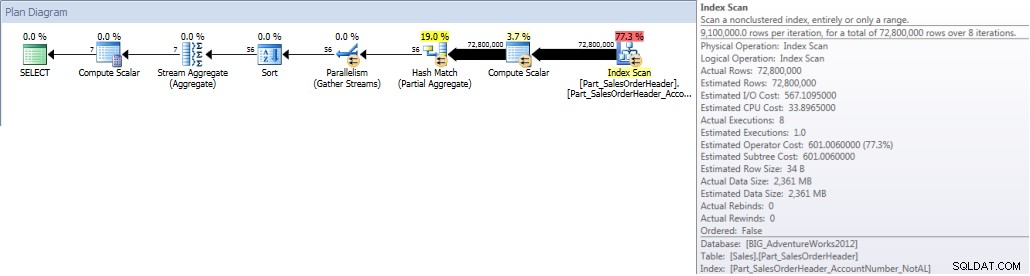
VYTVOŘTE NEZAHRNUTÝ INDEX [Part_SalesOrderHeader_AccountNumber_NotAL]NA [Sales].[Part_SalesOrderHeader]([AccountNumber])NA [PRIMARY];Tento index není zarovnán, i když obsahuje Datum objednávky, protože je součástí primárního klíče. Sloupce jsou také zahrnuty, pokud vytvoříme zarovnaný index, ale všimněte si rozdílu v syntaxi:
VYTVOŘTE NEZAHRNUTÝ INDEX [Part_SalesOrderHeader_AccountNumber_AL]NA [Sales].[Part_SalesOrderHeader]([AccountNumber]);Jaké sloupce v indexu existují, můžeme ověřit pomocí sp_helpindex od Kimberly Tripp:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader';
sp_helpindex pro Sales.Part_SalesOrderHeaderKdyž spustíme náš dotaz a přinutíme jej použít nezarovnaný index, prohledá se celý index. I když je OrderDate součástí indexu, není to hlavní sloupec, takže modul musí zkontrolovat hodnotu OrderDate pro každé AccountNumber, aby zjistil, zda spadá mezi 1. lednem 2013 a 31. červencem 2013:
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])OD [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL]))WHERE [ETWEENDDATUM' AND10' B1'B1' 2013-07-31'GROUP BY DATEPART(MONTH,[OrderDate])ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIKA IO VÝSTUPTabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Part_SalesOrderHeader'. Počet skenů 9, logické čtení 786861, fyzické čtení 1, čtení napřed 770929, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
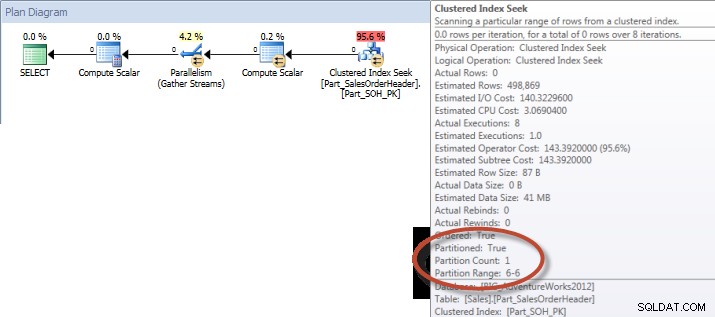
Součty účtu podle měsíce (leden – červenec 2013) pomocí ne Zarovnané NCI (vynucené)Naproti tomu, když je dotaz nucen použít zarovnaný index, lze použít eliminaci oddílu a je potřeba méně vstupů/výstupů, i když OrderDate není úvodním sloupcem v indexu.
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber])OD [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL]))WHERE [Order'Date] 2'1-01 MEZI 2013-07-31'GROUP BY DATEPART(MONTH,[OrderDate])ORDER BY DATEPART(MONTH,[OrderDate]);STATISTIKA IO VÝSTUPTabulka 'Pracovní stůl'. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka 'Part_SalesOrderHeader'. Počet skenů 9, logické čtení 456258, fyzické čtení 16, čtení napřed 453241, logické čtení 0, fyzické čtení 0, čtení napřed 0.
Součty na účtu podle měsíce (leden – červenec 2013) pomocí zarovnaného NCI (vynucené)Shrnutí
Rozhodnutí zavést rozdělení je takové, které vyžaduje náležité zvážení a plánování. Snadná správa, zlepšená škálovatelnost a dostupnost a omezení blokování jsou běžné důvody pro tabulky oddílů. Zlepšení výkonu dotazů není důvodem pro použití dělení, i když to může být v některých případech prospěšný vedlejší efekt. Pokud jde o výkon, je důležité zajistit, aby váš plán implementace zahrnoval kontrolu výkonu dotazů. Potvrďte, že vaše indexy nadále náležitě podporují vaše dotazy po tabulka je rozdělena na oddíly a ověřte, zda dotazy využívající klastrované a neklastrované indexy těží z eliminace oddílů tam, kde je to možné.