PostgreSQL 11 byl vydán 10. října 2018 a podle plánu, u příležitosti 23. výročí stále populárnější open source databáze.
I když je úplný seznam změn k dispozici v obvyklých Poznámkách k vydání, stojí za to se podívat na přepracovanou stránku Feature Matrix, která stejně jako oficiální dokumentace prošla od své první verze změnou, což usnadňuje zjištění změn, než se ponoříte do podrobností. .
Například na stránce Poznámky k verzi je „Vazba kanálu pro autentizaci SCAM“ skryta pod zdrojovým kódem, zatímco matice ji má v sekci Zabezpečení. Pro zvědavé je zde snímek obrazovky rozhraní:
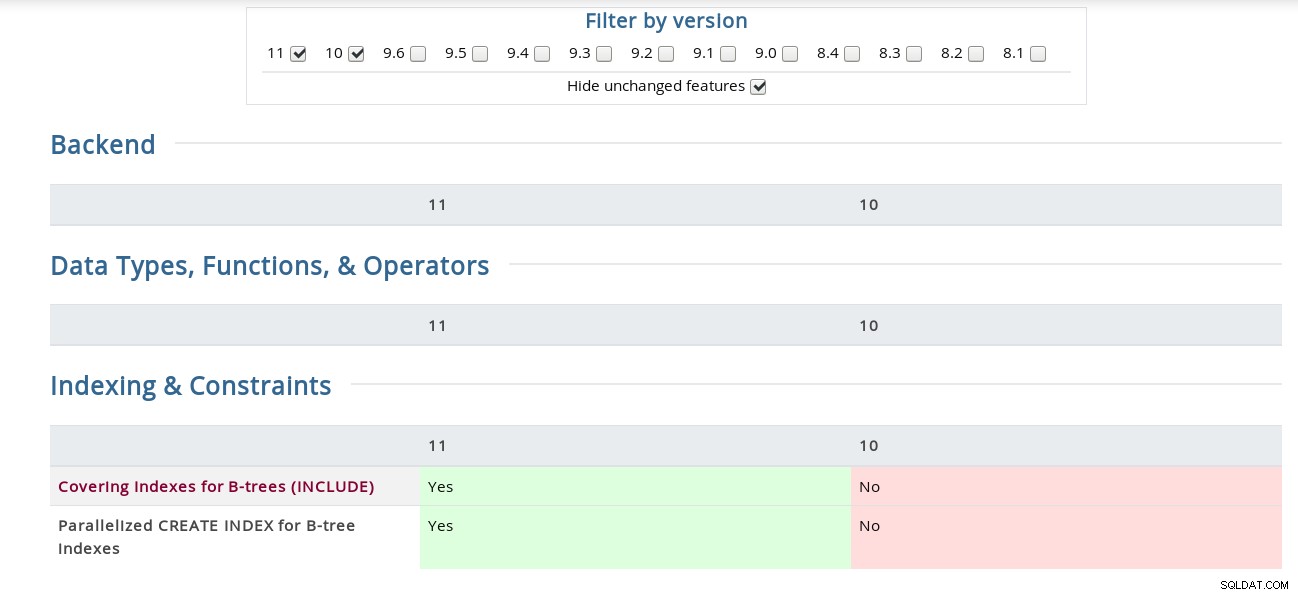 Matice funkcí PostgreSQL
Matice funkcí PostgreSQL Navíc výše odkazovaná stránka Bucardo Postgres Release Notes je svým způsobem užitečná a usnadňuje hledání klíčového slova ve všech verzích.
Co je nového? S doslova stovkami změn projdu rozdíly uvedené v matici funkcí.
Pokrývající indexy pro B-stromy (ZAHRNUTÍ)
CREATE INDEX obdržel klauzuli INCLUDE, která umožňuje indexům zahrnovat neklíčové sloupce . Jeho případ použití pro časté identické dotazy je dobře popsán v commitu Toma Lanea z 22. listopadu, který aktualizuje vývojovou dokumentaci (což znamená, že aktuální dokumentace PostgreSQL 11 ji ještě nemá), takže celý text najdete v sekci 11.9. Pouze indexové skeny a krycí indexy ve vývojové verzi.
Paralelizovaný CREATE INDEX pro indexy B-stromu
Jak je uvedeno v názvu, tato funkce je implementována pouze pro indexy B-stromu a z protokolu odevzdání Roberta Haase se dozvídáme, že implementace může být v budoucnu vylepšena. Jak je uvedeno v dokumentaci CREATE INDEX, zatímco paralelní i souběžné metody vytváření indexů využívají výhody více CPU, v případě CONCURRENT bude paralelně provedeno pouze první skenování tabulky.
S touto novou funkcí souvisí konfigurační parametry maintenance_work_mem a workers_maintenance_parallel_maintenance_workers .
Nakonec lze počet paralelních pracovníků nastavit na tabulku pomocí příkazu ALTER TABLE a zadáním hodnoty pro paralelní_pracovníci .
Stáhněte si Whitepaper Today Správa a automatizace PostgreSQL s ClusterControlZjistěte, co potřebujete vědět k nasazení, monitorování, správě a škálování PostgreSQLStáhněte si WhitepaperJust-In-Time (JIT) kompilace pro vyhodnocení výrazů a deformaci n-tice
Tato nová funkce s vlastní kapitolou JIT v dokumentaci spoléhá na to, že PostgreSQL je kompilován s podporou LLVM (pro ověření použijte pg_config).
Téma JIT v PostgreSQL je dostatečně komplexní (viz reference JIT README v dokumentaci), aby vyžadovalo vyhrazený blog, mezitím je blog CitusData na JIT velmi dobrým čtením pro ty, kteří mají zájem ponořit se do tématu hlouběji.
Paralelizované spojení hash
Toto zlepšení výkonu paralelních dotazů je výsledkem přidání sdílené hashovací tabulky, která, jak vysvětluje Thomas Munro ve svém blogu Parallel Hash for PostgreSQL, zamezuje rozdělení hashovací tabulky na oddíly za předpokladu, že se vejde do work_mem , což se zatím pro PostgreSQL jeví jako lepší řešení než algoritmus partition-first. Tentýž blog popisuje překážky architektury PostgreSQL, které musel autor překonat ve své snaze přidat paralelizaci do hash spojení, což vypovídá o složitosti práce, která byla nutná k implementaci této funkce.
Výchozí oddíl
Toto je oddíl catch all pro uložení řádků, které neodpovídají žádnému jinému definovanému oddílu. V případech, kdy je přidán nový oddíl, se doporučuje omezení CHECK, aby se zabránilo skenování výchozího oddílu, které může být pomalé, když výchozí oddíl obsahuje velký počet řádků.
Výchozí chování oddílu je vysvětleno v dokumentaci ALTER TABLE a CREATE TABLE.
Rozdělení pomocí hash klíče
Také se nazývá rozdělování hashů a jak je uvedeno ve zprávě odevzdání, tato funkce umožňuje rozdělování tabulek takovým způsobem, že oddíly budou obsahovat podobný počet řádků. Toho je dosaženo poskytnutím modulu, který se v jednodušším scénáři doporučuje rovnat počtu oddílů a zbytek by měl být pro každý oddíl jiný.
Další podrobnosti a příklad naleznete na stránce dokumentace CREATE TABLE.
Podpora PRIMÁRNÍHO KLÍČE, CIZÍHO KLÍČE, indexů a spouštěčů v dělených tabulkách
Rozdělení tabulek je již velkým krokem ke zlepšení výkonu velkých tabulek a přidání těchto funkcí řeší omezení, která dělené tabulky měly od PostgreSQL 10, kdy bylo zavedeno „deklarativní dělení“ moderního stylu.
Probíhá práce Alvara Herrery, která umožní cizím klíčům odkazovat na primární klíče, a je naplánována na příští hlavní verzi PostgreSQL 12.
AKTUALIZACE klíče oddílu
Jak je vysvětleno v protokolu odevzdání opravy, tato aktualizace zabraňuje PostgreSQL ve vyvolání chyby, když aktualizace klíče oddílu zneplatní řádek, a místo toho bude řádek přesunut do vhodného oddílu.
Vazba kanálu pro ověření SCRAM
Toto je bezpečnostní opatření, jehož cílem je zabránit útokům typu man-in-the-middle v ověřování SASL a je podrobně popsáno v blogu autora. Tato funkce vyžaduje minimálně OpenSSL 1.0.2.
CREATE PROCEDURE a CALL syntaxe pro SQL Stored Procedures
PostgreSQL má CREATE FUNCTION od roku 1996 s verzí 1.0.1 funkce však nemohou zpracovávat transakce. Jak je uvedeno v dokumentaci, příkaz CREATE PROCEDURE není plně kompatibilní se standardem SQL.
Poznámka:Zůstaňte naladěni na nadcházející blog, který se podrobně ponoří do této funkce
Závěr
Hlavní aktualizace PostgreSQL 11 se zaměřují na zlepšení výkonu prostřednictvím paralelního spouštění, dělení a kompilace Just-In-Time. Uložené procedury umožňují plnou kontrolu transakcí a mohou být napsány v různých jazycích PL.