V tomto článku probereme několik problémů, se kterými se můžete setkat při vytváření, konfiguraci nebo údržbě webu Always on Availability Group.
Než si projdete tento článek, doporučujeme přečíst si předchozí článek Nastavení a konfigurace skupiny Always on Availability na serveru SQL Server, abyste se seznámili s konceptem skupiny Always on Availability Group a průvodci New Availability Group uvedenými v tomto článku.
Vždy zapnutá funkce skupiny dostupnosti není povolena
Předpokládejme, že při pokusu o vytvoření nové skupiny Always on Availability z uzlu Always On High Availability v Průzkumníku objektů SQL Server Management Studio jste narazili na následující chybovou zprávu:
Před vytvořením skupiny dostupnosti v této instanci musí být povolena funkce Always On Availability Groups pro instanci serveru 'SQL1'. Chcete-li tuto funkci povolit, otevřete SQL Server Configuration Manager, vyberte SQL Server Services, klikněte pravým tlačítkem na název služby SQL Server, vyberte Vlastnosti a použijte kartu Always On Availability Groups v dialogovém okně Vlastnosti serveru. Povolení skupin dostupnosti Always On může vyžadovat, aby byla instance serveru hostována uzlem Windows Server Failover Cluster (WSFC). (Microsoft.SqlServer.Management.HadrTasks)

Z chybové zprávy je zřejmé, že funkce AlwaysOn Availability Groups by měla být povolena na každé instanci SQL Serveru, která se účastní webu Always on Availability Group, před vytvořením tohoto webu.
Funkci Always on Availability Group můžete snadno povolit otevřením konzoly SQL Server Configuration Manager, procházením záložky Služby SQL Server a poté kliknutím pravým tlačítkem na službu SQL Server Database Engine a výběrem možnosti Vlastnosti.
V otevřeném okně Vlastnosti SQL Server se přesuňte na kartu Always on High Availability a zaškrtněte políčko vedle Povolit skupinu Always on Availability , přičemž je třeba vzít v úvahu, že tato změna vyžaduje restartování služby SQL Server, aby se projevila, jak je uvedeno níže:

Problém s ověřením požadavků databáze
V předchozích krocích průvodce New Availability Group budete požádáni o zadání databází, které se budou podílet na skupině Always on Availability Group. Před přidáním databáze by databáze měla projít kontrolou ověření předpokladů. V opačném případě nelze databázi vybrat ze seznamů databází, jak ukazuje chybová zpráva níže:
Aby byla tato databáze přidána do skupiny dostupnosti, musí být nastavena na model úplné obnovy. Nastavte vlastnost databáze Model obnovy na Úplné a proveďte úplné nebo rozdílové zálohování databáze. Poté budete muset naplánovat zálohování protokolů v databázi.

Zpráva je jasná. Kde by měla být databáze nakonfigurována s modelem úplné obnovy a v této databázi by měla být provedena úplná nebo rozdílová záloha.
Průvodce vás také varuje, abyste naplánovali zálohu protokolu transakcí pro danou databázi po změně modelu obnovy na Úplný, aby se soubor protokolu transakcí automaticky zkrátil a zabránilo se spuštění tohoto souboru protokolu transakcí z volného místa.
Chcete-li tento problém vyřešit, změňte model obnovy databáze z jednoduchého na úplný na kartě Možnosti v okně vlastností databáze a poté proveďte úplnou zálohu z této databáze, jak je znázorněno níže:

Obnovením okna Vybrat databáze se stav databáze změní na Splnit předpoklady, jak je uvedeno níže:

Problém s oprávněním k umístění sdílené sítě
Při pokusu o konfiguraci webu Always on Availability Group selhal ověřovací krok průvodce New Availability Group s chybovou zprávou níže:
Primární server 'SQL1' nemůže zapisovat do '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Zálohování se nezdařilo pro server 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Nelze otevřít zálohovací zařízení '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Chyba operačního systému 5 (Přístup byl odepřen.).
BACKUP DATABASE se nenormálně ukončuje. (.Net SqlClient Data Provider)
V metodě počáteční synchronizace úplné zálohy databáze a protokolu je vyžadována sdílená složka pro dočasné uchování záložních souborů úplné zálohy a protokolu transakcí za účelem jejich obnovení do všech sekundárních replik. Pokud primární replika není schopna do ní zapisovat záložní soubory nebo sekundární repliky nejsou schopny z ní číst záložní soubory, proces ověření nové skupiny dostupnosti selže, jak je uvedeno níže:

Abychom tento problém vyřešili, musíme udělit účtu SQL Server Service primárním a sekundárním replikám oprávnění ke čtení a zápisu do sdílené složky zobrazené v chybové zprávě a poté znovu spustit proces ověření, abychom se ujistili, že všechny kontroly proběhly úspěšně. , jak je uvedeno níže:

Problém Windows Failover Cluster
Předpokládejme, že kontrolujete stav existujícího webu Always on Availability Group a uvidíte toto:
- Primární role je přesunuta z instance SQL1 do SQL2.
- V SQL2 jsou databáze ve stavu Synchronized.
- V SQL1 nejsou databáze synchronizovány.
- SQL1 je ve stavu Resolving.
Jak můžete jasně vidět z SSMS Object Explorer níže:

Při kontrole chybových protokolů SQL Serveru v problematickém uzlu vidíme, že replika skupiny dostupnosti přejde do režimu offline a skupina dostupnosti přestala fungovat kvůli problému v clusteru Windows Server Failover Cluster, jak je znázorněno v chybách níže:
- Always On Availability Groups:Místní uzel Windows Server Failover Clustering již není online . Toto je pouze informativní zpráva. Není vyžadována žádná akce uživatele.
- Vždy zapnuto:Správce replik dostupnosti přechází do režimu offline, protože místní uzel Windows Server Failover Clustering (WSFC) ztratil kvorum. Toto je pouze informativní zpráva. Není vyžadována žádná akce uživatele.
- Vždy zapnuto:Místní replika skupiny dostupnosti „DemoGroup“ se zastavuje. Toto je pouze informativní zpráva. Není vyžadována žádná akce uživatele.

Totéž lze zjistit z Prohlížeče událostí na serveru Windows, který postupně ukazuje, jak replika mění svůj stav na stav Resolving, jak je uvedeno níže:
- Vždy zapnuto:Místní replika skupiny dostupnosti „DemoGroup“ se připravuje na přechod do role řešení . Toto je pouze informativní zpráva. Není vyžadována žádná akce uživatele.
- Skupina dostupnosti „DemoGroup“ je požádána o zastavení obnovování zapůjčení, protože skupina dostupnosti přechází do režimu offline . Toto je pouze informativní zpráva. Není vyžadována žádná akce uživatele.
- Stav místní repliky dostupnosti ve skupině dostupnosti 'DemoGroup' se změnil z PRIMARY_NORMAL' na 'RESOLVING_NORMAL'. Stav se změnil, protože skupina dostupnosti přechází do režimu offline. Replika přechází do režimu offline, protože přidružená skupina dostupnosti byla odstraněna nebo uživatel převedl přidruženou skupinu dostupnosti do režimu offline v konzole pro správu Windows Server Failover Clustering (WSFC) nebo skupina dostupnosti přebírá selhání na jinou instanci SQL Server. Další informace naleznete v protokolu chyb serveru SQL Server nebo protokolu clusteru. Pokud se jedná o skupinu dostupnosti Windows Server Failover Clustering (WSFC), můžete si také prohlédnout konzolu pro správu WSFC.

Ke kontrole stavu webu Windows Cluster použijeme Správce clusteru s podporou převzetí služeb při selhání, abychom viděli, která část clusteru Windows selhává.
Ale Failover Cluster Manager ukazuje, že celý cluster je mimo provoz, jak je znázorněno níže:

První věc, kterou zde ověříte ze strany Windows Failover Cluster, je Cluster Service, kterou lze zkontrolovat z konzoly Windows Services, jak je uvedeno níže:

Z konzoly Services je zřejmé, že Clusterová služba není spuštěna. Chcete-li tento problém vyřešit, spusťte službu z této konzoly a poté obnovte konzolu Failover Cluster Manager, abyste se ujistili, že je web Windows Cluster v provozu, jak je znázorněno níže:

Když znovu zaškrtnete skupinu Always on Availability Group, uvidíte, že databáze jsou opět synchronizované a stránka Always on Availability Group je opět ve stavu, jak je ukázáno níže:

Soubor protokolu transakcí je plný na primární straně
Předpokládejme, že se při pokusu o provedení nového dotazu v jedné z databází skupiny Always on Availability zobrazí níže uvedená chybová zpráva:

Když zkontrolujete, co blokuje soubor protokolu transakcí a brání jeho zkrácení, uvidíte, že soubor protokolu transakcí této databáze čeká na operaci zálohování protokolu, která má být zkrácena, jak je znázorněno níže:

Proveďte zálohu protokolu transakcí pro tuto databázi pro případ, že byste zapomněli naplánovat úlohu zálohování protokolu transakcí, a to následovně:

A znovu zkontrolujte, co blokuje transakční protokol této databáze, v mém scénáři to ukazuje, že čeká na Availability_Replica. Což znamená, že protokoly čekají na zapsání do sekundární repliky, ale nemohou odeslat tyto protokoly transakcí do sekundárních replik kvůli problému na webu Always on Availability Group, jak je uvedeno níže:

Nejlepším místem pro kontrolu a odstraňování problémů se stránkou Always on Availability Group je stránka Always on Dashboard, kterou lze otevřít kliknutím pravým tlačítkem myši na název skupiny dostupnosti a výběrem možnosti Zobrazit řídicí panel.
Z řídicího panelu můžete vidět, že sekundární replika SQL2 není synchronizována s primární replikou z důvodu problému s připojením, jak je znázorněno níže:

Zkontrolujte sekundární repliku a ujistěte se, že je služba SQL Server Service spuštěna a spuštěna na sekundární straně, a to následovně:

Poté znovu aktualizujte řídicí panel skupiny dostupnosti a uvidíte, že web Always on Availability Group je opět v pořádku. Checking if the transaction logs file is blocked by any operation, we will see that it is pending OLDEST_PAGE, indicating that the oldest page of the database is older than the checkpoint LSN. This issue can be fixed easily by taking another transaction log backup and the transaction log file will be blocked by nothing, as shown clearly below:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
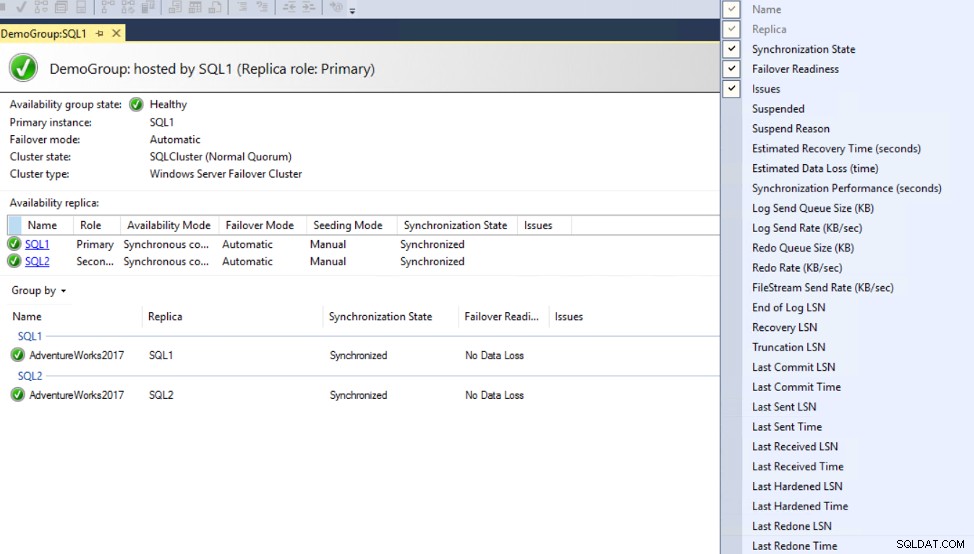
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below:
