
Autor hosta:Andy Mallon (@AMtwo)
Ne, vážně. Co je to DTU?
Když nasazujete jakoukoli aplikaci, jedna z prvních otázek, která se objeví, je „Co to bude stát?“ Většina z nás v určitém okamžiku prošla tímto druhem cvičení pro dimenzování instalace SQL Server, ale co když nasazujete do cloudu? S nasazením Azure IaaS se toho moc nezměnilo – stále vytváříte server na základě počtu CPU, určité velikosti paměti a konfigurování úložiště, abyste měli dostatek IOPS pro vaši pracovní zátěž. Když však přejdete na PaaS, Azure SQL Database má velikost s různými úrovněmi služeb, kde se výkon měří v DTU. Co je to sakra DTU?
Vím, co je BTU. Možná DTU znamená Database Thermal Unit? Je to množství výpočetního výkonu potřebného ke zvýšení teploty datového centra o jeden stupeň? Namísto hádání se podíváme na dokumentaci a uvidíme, co na to Microsoft:
[Database Transaction Unit] je smíšená míra CPU, paměti a dat I/O a I/O protokolu transakcí v poměru určeném zátěží benchmarku OLTP navrženou tak, aby byla typická pro zátěž OLTP v reálném světě. Zdvojnásobení DTU zvýšením úrovně výkonu databáze se rovná zdvojnásobení sady zdrojů dostupných pro tuto databázi.Dobře, to byl můj druhý odhad – ale co je to „smíšené opatření“? Jak mohu převést to, co vím o dimenzování serveru, do dimenzování Azure SQL Database? Bohužel neexistuje žádný přímý způsob, jak převést „2 jádra CPU a 4 GB paměti“ na měření DTU.
Neexistuje kalkulačka DTU?
Ano! Microsoft nám dává DTU Calculator k odhadu správnou úroveň služeb Azure SQL Database. Chcete-li jej použít, stáhněte si a spusťte skript PowerShell (sql-perfmon.ps1) na serveru při spuštění úlohy na serveru SQL Server. Skript vygeneruje CSV, který obsahuje čtyři čítače perfmon:(1) celkové % času procesoru, (2) celkový počet čtení disku/sekundu, (3) celkový počet zápisů na disk za sekundu a (4) celkový počet vyprázdněných bajtů protokolu/sekundu. Tento výstup CSV je poté nahrán do kalkulačky DTU, která odhadne, jaká úroveň služeb bude nejlépe vyhovovat vašim potřebám. Jediná data, která DTU Calculator bere kromě CSV, je počet jader CPU na serveru, který soubor vygeneroval. Kalkulačka DTU je stále trochu černá skříňka – není snadné namapovat to, co známe z našich místních databází, do Azure.
Chtěl bych zdůraznit, že definice DTU je, že jde o „smíšenou míru CPU, paměti a data I/O a I/O protokolu transakcí…“ Žádný z čítačů perfmon používaných kalkulačkou DTU nezohledňuje paměť, ale v definici je jasně uvedena jako součást výpočtu. To nemusí nutně být problém, ale je to důkaz, že kalkulačka DTU nebude dokonalá.
Nahraju nějakou syntetickou zátěž do kalkulačky DTU a uvidím, jestli dokážu zjistit, jak ta černá skříňka funguje. Ve skutečnosti vyrobím CSV úplně, abych mohl zcela ovládat čísla perfmon, která načteme do kalkulačky DTU. Pojďme postupně projít jednu metriku. Pro každou metriku nahrajeme 25 minut (1500 sekund – líbí se mi zaokrouhlená čísla) vyrobených dat a uvidíme, jak jsou tato data perfmon převedena na DTU.
CPU
Vytvořím CSV, který simuluje 16jádrový server a pomalu navyšuje využití CPU, dokud nebude nastaveno na 100 %. Vzhledem k tomu, že budu simulovat náběh na 16jádrovém serveru, vytvořím svůj CSV tak, aby se postupně zvýšil o 1/16 – v podstatě simuluji maxování jednoho jádra, pak druhé maxování a pak třetí, atd. Po celou dobu bude CSV ukazovat nula čtení, zápisy a vyprázdnění protokolu. Server by ve skutečnosti nikdy nevygeneroval takovou pracovní zátěž – ale o to jde. Úplně izoluji využití CPU, abych viděl, jak CPU ovlivňuje DTU.
Vytvořím soubor CSV, který má jeden řádek za sekundu, a každých 94 sekund zvýším čítač Total % procesorového času o ~6 %. Ostatní tři čítače budou ve všech případech nulové. Nyní nahraji tento soubor do kalkulačky DTU (a řeknu kalkulačce DTU, aby zvážila 16 jader) a zde je výstup:
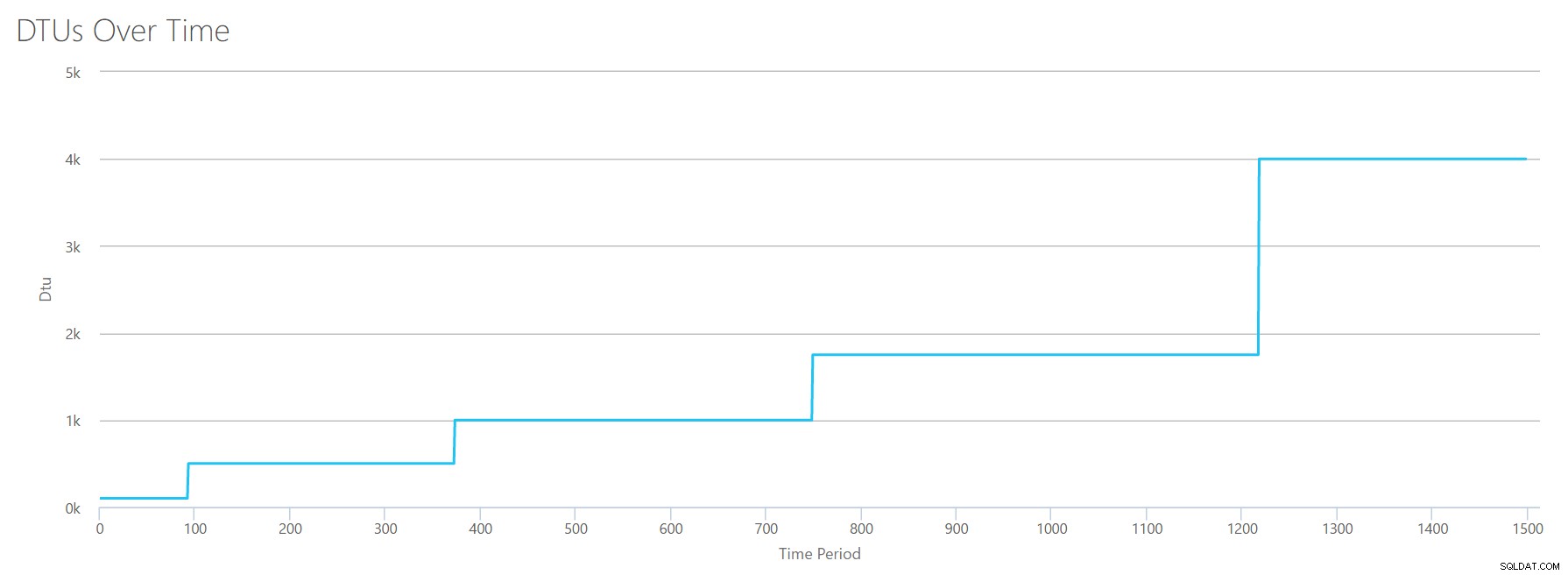
Počkejte? Nezvýšil jsem využití CPU v 16 sudých krocích? Tento graf DTU zobrazuje pouze pět kroků. Asi jsem se popletl. Ne – můj CSV měl 16 sudých kroků, ale to se (zřejmě) nepřevádí rovnoměrně do DTU. Alespoň ne podle kalkulačky DTU. Na základě našeho maximálního testu CPU by naše mapování úrovně CPU-to-DTU-to-Service vypadalo takto:
| Počet jader | DTU | Úroveň služeb |
|---|---|---|
| 1 | 100 | Standardní – S3 |
| 2–4 | 500 | Premium – P4 |
| 5–8 | 1000 | Premium – P6 |
| 9–13 | 1750 | Premium – P11 |
| 14–16 | 4000 | Premium – P15 |
Pohled na tato data nám říká několik věcí:
- Jedno jádro CPU, 100% využití se rovná 100 DTU.
- DTU se trochu zvyšují lineárně, jak CPU roste, ale zdánlivě v záchvatech a spurtech.
- Úrovně služeb Basic a Standard se rovnají méně než jednomu jádru CPU.
- Jakýkoli vícejádrový server by se převedl do určité velikosti v rámci úrovně prémiových služeb.
Čtení
Tentokrát použiji stejnou metodiku. Vygeneruji CSV s rostoucími čísly pro čítač čtení/sekundu, přičemž ostatní čítače perfmon budou na nule. Postupem času budu číslo postupně zvyšovat. Tentokrát pojďme zvyšovat po kouscích 2 000, každých 100 sekund, dokud nedosáhneme 30 000. To nám dává stejný celkový čas 25 minut – tentokrát však mám 15 kroků místo 16. (Mám rád zaokrouhlená čísla.)
Když tento soubor CSV nahrajeme do kalkulačky DTU, zobrazí se nám tento graf DTU:
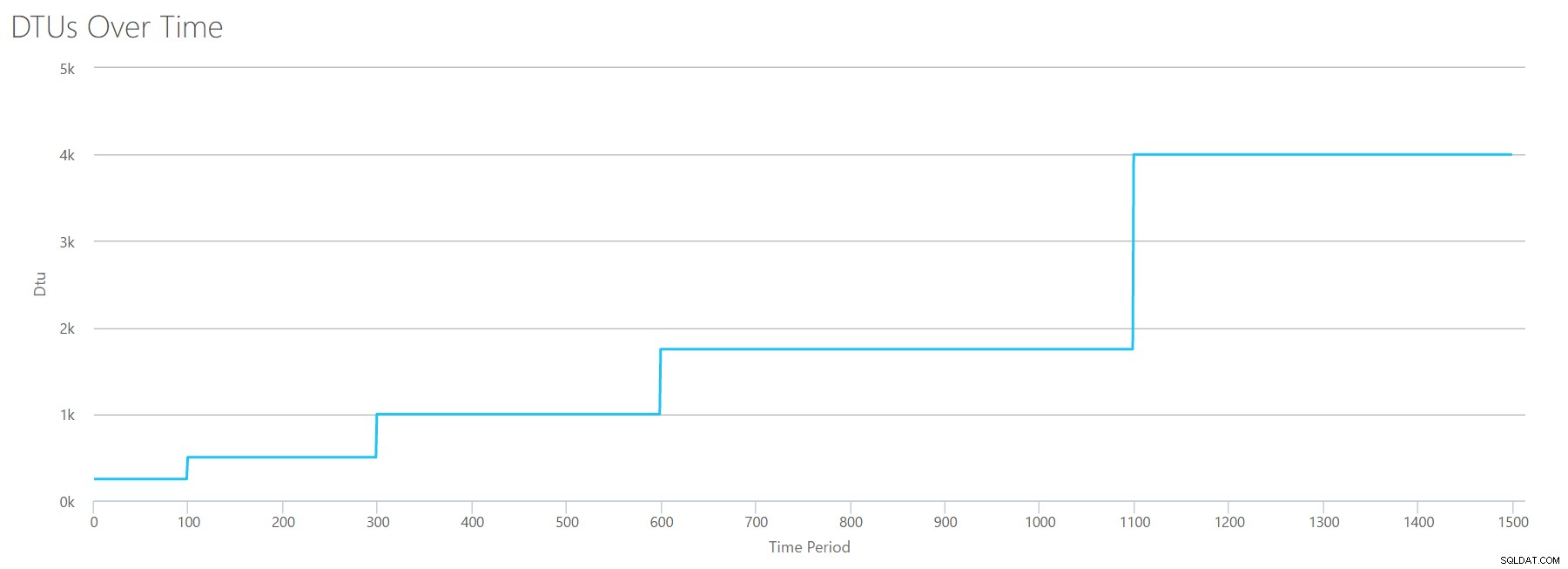
Počkejte chvíli… to vypadá docela podobně jako první graf. Opět se zvyšuje v 5 nerovnoměrných krocích, i když jsem měl v souboru 15 sudých kroků. Podívejme se na to v tabulkovém formátu:
| Čtení/s | DTU | Úroveň služeb |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000–6000 | 500 | Premium – P4 |
| 8000–12000 | 1000 | Premium – P6 |
| 14 000–22 000 | 1750 | Premium – P11 |
| 24 000–30 000 | 4000 | Premium – P15 |
Opět vidíme, že základní a standardní úrovně se přeskakují docela rychle (méně než 2 000 čtení/s), ale potom je úroveň Premium docela široká a zahrnuje 2 000 až 30 000 čtení za sekundu. Ve výše uvedené tabulce by „čtení/s“ mohla být pravděpodobně chápána jako „IOPS“ … Nebo technicky jen „OPS“, protože zde nejsou žádné zápisy, které by tvořily „vstupní“ část IOPS.
Píše
Pokud vytvoříme CSV pomocí stejného vzorce, který jsme použili pro čtení, a nahrajeme tento CSV do DTU Calculator, získáme graf, který je totožný s grafem pro čtení:
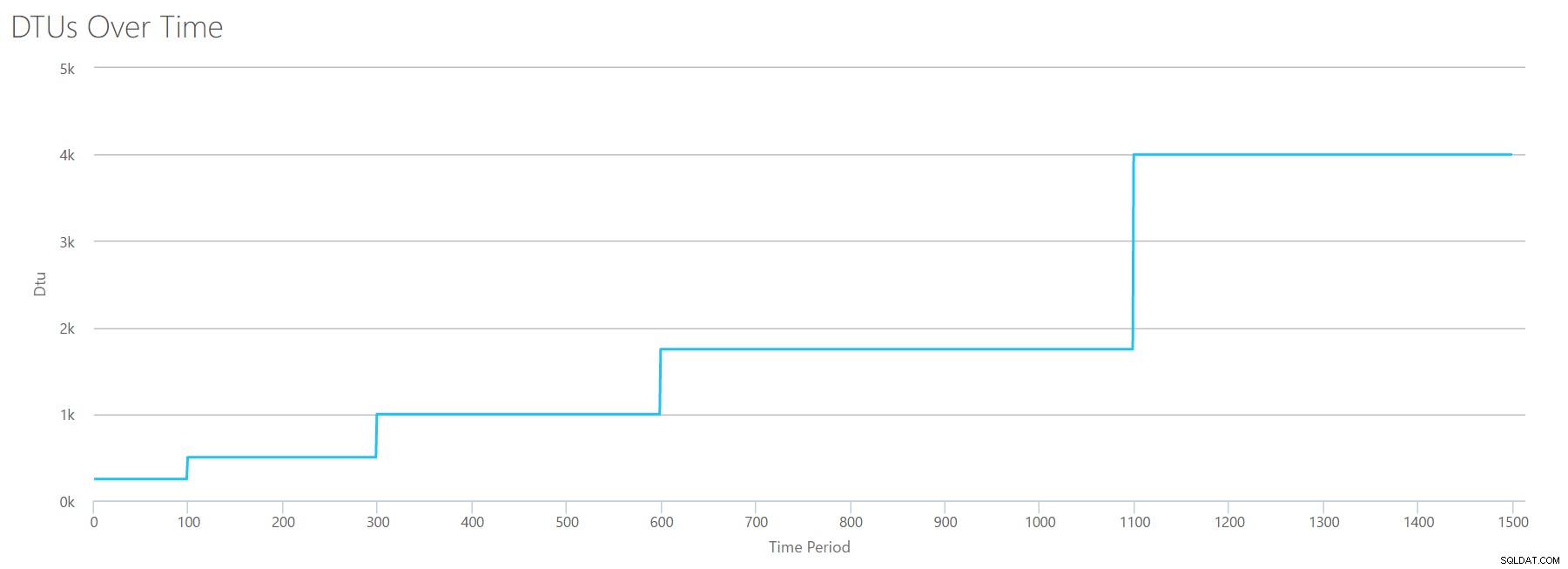
IOPS jsou IOPS, takže ať už jde o čtení nebo zápis, vypadá to, že výpočet DTU to bere stejně. Zdá se, že vše, co víme (nebo si myslíme, že víme) o čtení, platí stejně i pro zápisy.
Bajty protokolu byly vyprázdněny
Jsme u posledního čítače perfmon:log bajtů vyprázdněných za sekundu. Toto je další měření IO, ale specifické pro protokol transakcí SQL Server. V případě, že jste to ještě nepochopili, vytvářím tyto CSV, aby se vysoké hodnoty vypočítaly jako P15 Azure DB, a pak hodnotu jednoduše rozdělím na sudé kroky. Tentokrát postoupíme z 5 milionů na 75 milionů, v krocích po 5 milionech. Stejně jako ve všech předchozích testech budou ostatní čítače perfmonů nulové. Vzhledem k tomu, že tento čítač perfmon je v bajtech za sekundu a měříme v milionech, můžeme si to představit v jednotce, která nám vyhovuje:Megabajty za sekundu.
Tento soubor CSV nahrajeme do kalkulačky DTU a získáme následující graf:
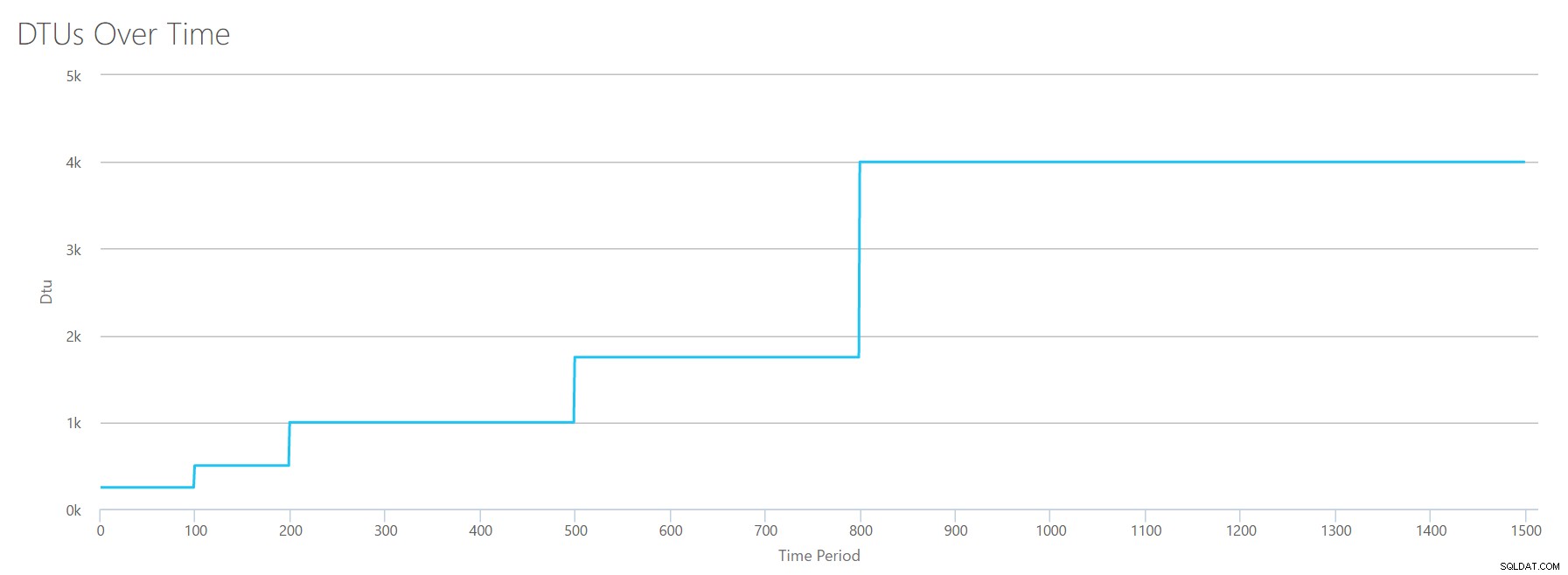
| Protokol vyprázdněných megabajtů/s | DTU | Úroveň služeb |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15–25 | 1000 | Premium – P6 |
| 30–40 | 1750 | Premium – P11 |
| 45–75 | 4000 | Premium – P15 |
Tvar tohoto grafu začíná být docela předvídatelný. Kromě tentokrát postupujeme úrovněmi o něco rychleji a na P15 dosáhneme pouze po 8 krocích (ve srovnání s 11 pro IO a 12 pro CPU). To by vás mohlo vést k myšlence:"Toto bude moje nejužší hrdlo!" ale tím bych si nebyl tak jistý. Jak často generujete 75 MB protokolu za sekundu ? To je 4,5 GB za minutu . To je velká databázová aktivita. Moje syntetická pracovní zátěž nemusí být nutně realistická.
Kombinace všeho
OK, teď, když jsme viděli, kde jsou některé horní limity izolovaně, zkombinuji data a uvidím, jak se porovnávají, když CPU, I/O a IO probíhají najednou – konec konců , ve skutečnosti se tak věci nedějí?
K sestavení tohoto CSV jsem jednoduše vzal existující hodnoty, které jsme použili pro každý jednotlivý test výše, a zkombinoval tyto hodnoty do jednoho CSV, což vede k tomuto krásnému grafu:
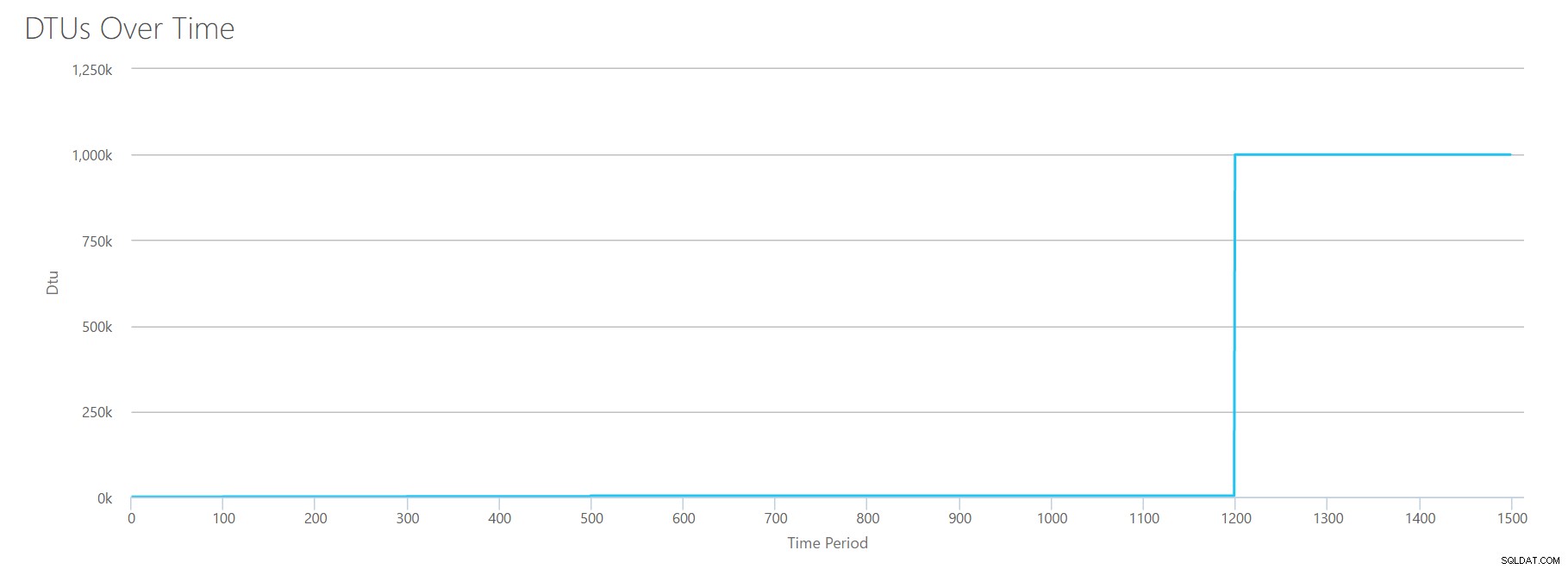
Poskytuje také zprávu:
Na základě vašeho využití databáze je vaše zátěž SQL Serveru Mimo rozsah . V současné době neexistuje úroveň služeb/úroveň výkonu, která by pokrývala vaše využití.Pokud se podíváte na osu Y, uvidíte, že jsme dosáhli „1 000 000“ (tj. 1 milion) DTU na hranici 1200 sekund. To se zdá...uhh...špatně? Pokud se podíváme na výše uvedené testy, 1200 sekundová známka byla, když všechny 4 jednotlivé metriky dosáhly hranice pro 4000 DTU, úroveň P15. Dává to smysl, že bychom byli mimo dosah, ale tvar grafu mi nedává tak docela smysl – myslím, že kalkulačka DTU jen rozhodila rukama a řekla:„Cokoliv, Andy. Je to hodně. hodně. Je to bajillion DTU. Tato pracovní zátěž se nehodí pro Azure SQL Database."
OK, takže co se stane předtím hranici 1200 sekund? Zkrátíme CSV a znovu jej odešleme do kalkulačky pouze s prvních 1200 sekund. Maximální hodnoty pro každý sloupec jsou:81 % CPU (nebo přibližně 13 jader při 100 %), 24 000 čtení/s, 24 000 zápisů/s a 60 MB vyprázdnění protokolu/s.
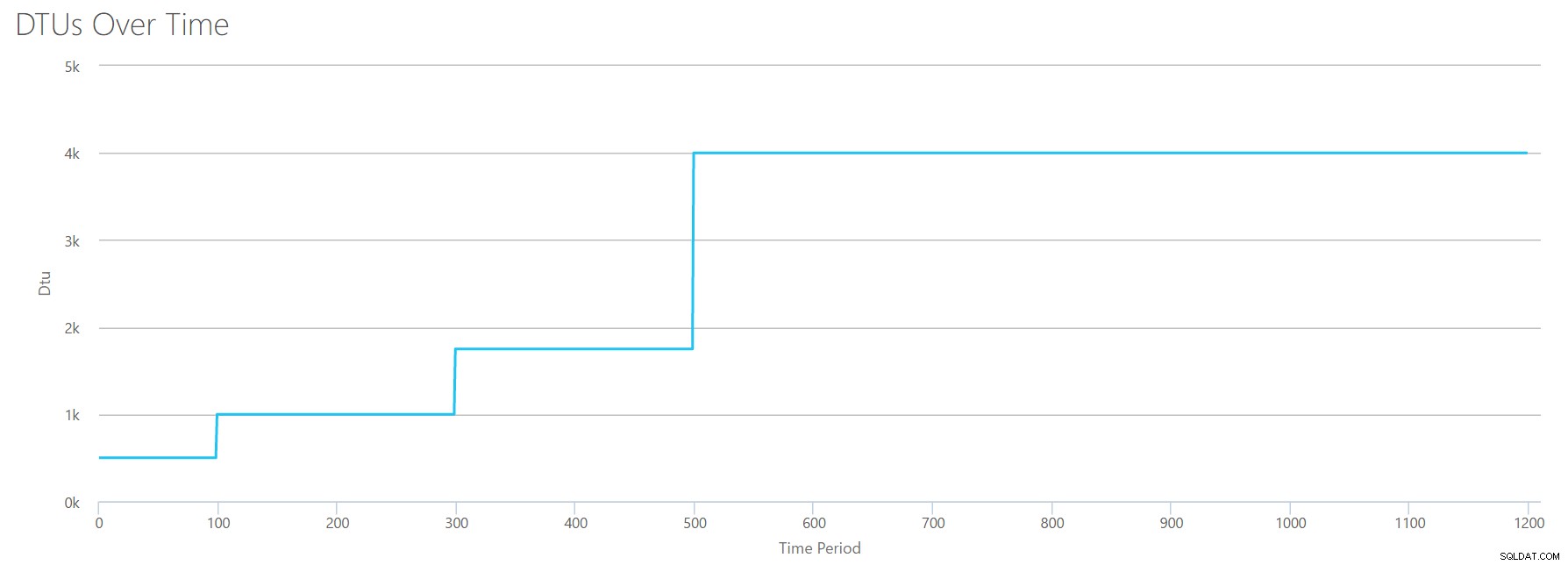
Ahoj, starý příteli... Ten známý tvar je zase zpátky. Zde je souhrn dat z CSV a odhady DTU Calculator pro celkové využití DTU a úroveň služeb.
| Počet jader | Přečtení/s | Zápisy/s | Protokol vyprázdněných megabajtů/s | DTU | Úroveň služeb |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2–3 | 4000–6000 | 4000–6000 | 10 | 1000 | Premium – P6 |
| 4–5 | 8000–10000 | 8000–10000 | 15–25 | 1750 | Premium – P11 |
| 6-13 | 12 000–24 000 | 12 000–24 000 | 30–40 | 4000 | Premium – P15 |
Nyní se podívejme, jak se jednotlivé výpočty DTU (když jsme je vyhodnocovali samostatně) v porovnání s výpočty DTU z této nejnovější kontroly:
| CPU DTU | Přečtěte si DTU | Zapište DTU | Zaznamenat vyprázdnění DTU | Součet celkových DTU | Odhad kalkulačky DTU | Úroveň služeb |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500–1000 | 1000 | 1000 | 1000 | 3500–4000 | 1750 | Premium – P11 |
| 1000–1750 | 1000–1750 | 1000–1750 | 1750 | 4750–7000 | 4000 | Premium – P15 |
Uvidíte, že výpočet DTU není tak jednoduchý jako sčítání jednotlivých DTU. Jak uvádí definice, kterou jsem citoval na začátku, jde o „smíšenou míru“ těchto samostatných metrik. Vzorec používaný pro „míchání“ je komplikovaný a ve skutečnosti tento vzorec nemáme. Vidíme, že odhady DTU Calculator jsou nižší než součet jednotlivých výpočtů DTU.
Mapování DTU na tradiční hardware
Vezměme data z DTU Calculator a pokusme se dát dohromady nějaké odhady, jak by se tradiční hardware mohl mapovat na některé úrovně Azure SQL Database.
Nejprve předpokládejme, že „čtení/s“ a „zápisy/s“ se do IOPS překládají přímo bez nutnosti překladu. Za druhé, předpokládejme, že přidáním těchto dvou čítačů získáme naše celkové IOPS. Zatřetí, přiznejme si, že nemáme ponětí, co je využití paměti, a nemáme žádný způsob, jak v tomto ohledu učinit nějaké závěry.
Zatímco odhaduji hardwarové specifikace, vyberu také možnou velikost virtuálního počítače Azure, která by vyhovovala každé hardwarové konfiguraci. Existuje mnoho podobných velikostí virtuálních počítačů Azure, z nichž každá je optimalizovaná pro různé metriky výkonu, ale já jsem pokračoval a omezil jsem svůj výběr na řadu A a DSv2.
| Počet jader | IOPS | Paměť | DTU | Úroveň služeb | Porovnatelná velikost virtuálního počítače Azure |
|---|---|---|---|---|---|
| 1 jádro, 5% využití | 10 | ??? | 5 | Základní | Standard_A0, téměř nepoužívané |
| <1 jádro | 150 | ??? | 100 | Standardní S0-S3 | Standard_A0, není plně využito |
| 1 jádro | až 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2–3 jádra | až 12 000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4–5 jader | až 20 000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | až 48 000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
Základní úroveň je neuvěřitelně omezená. Je to dobré pro příležitostné/náhodné použití a je to levný způsob, jak „zaparkovat“ databázi, když ji nepoužíváte. Pokud ale provozujete jakoukoli skutečnou aplikaci, základní vrstva pro vás nebude fungovat.
Standardní úroveň je také dost omezená, ale pro malé aplikace je schopna splnit vaše potřeby. Pokud máte 2jádrový server, na kterém je spuštěno několik databází, mohou se tyto databáze jednotlivě hodit do úrovně Standard. Podobně, pokud máte server pouze s jednou databází, na kterém běží 1 jádro CPU na 100 % (nebo 2 jádra běží na 50 %), je to pravděpodobně jen dost koňských sil na to, aby se škála posunula do úrovně služeb Premium-P1.
Pokud byste používali vícejádrový server v místním prostředí (nebo IaaS), hledali byste v rámci úrovně prémiových služeb v Azure SQL Database. Jde jen o to určit, kolik výkonu CPU a I/O potřebujete pro svou pracovní zátěž. Váš 2jádrový, 4GB server vás pravděpodobně přivede někam k P6 Azure SQL DB. Při čisté zátěži CPU (s nulovým I/O) by databáze P15 zvládla zpracování 16 jader, ale jakmile do mixu přidáte IO, nic většího než ~12 jader se do Azure SQL Database nevejde.
Příště vezmu nějaké skutečné pracovní zatížení a porovnám výkon napříč úrovněmi služeb. Budou odhady DTU Calculator přesné? To zjistíme.
O autorovi
 Andy Mallon je SQL Server DBA a Microsoft Data Platform MVP, který spravuje databáze ve zdravotnictví, financích, -obchod a neziskový sektor. Od roku 2003 Andy podporuje velkoobjemová a vysoce dostupná prostředí OLTP s náročnými požadavky na výkon. Andy je zakladatelem BostonSQL, spoluorganizátorem SQLSaturday Boston a bloguje na am2.co.
Andy Mallon je SQL Server DBA a Microsoft Data Platform MVP, který spravuje databáze ve zdravotnictví, financích, -obchod a neziskový sektor. Od roku 2003 Andy podporuje velkoobjemová a vysoce dostupná prostředí OLTP s náročnými požadavky na výkon. Andy je zakladatelem BostonSQL, spoluorganizátorem SQLSaturday Boston a bloguje na am2.co.