SQL Server 2014 přinesl mnoho nových funkcí, které se správci databází a vývojáři těšili na testování a používání ve svých prostředích, jako je aktualizovatelný seskupený index Columnstore, zpožděná trvanlivost a rozšíření fondu vyrovnávací paměti. Funkce, o které se často nemluví, je přírůstková statistika. Pokud nepoužíváte dělení, není to funkce, kterou můžete implementovat. Ale pokud máte v databázi rozdělené tabulky, přírůstkové statistiky mohly být něco, co jste netrpělivě očekávali.
Poznámka:Benjamin Nevarez pokryl některé základy související s přírůstkovou statistikou ve svém příspěvku z února 2014, SQL Server 2014 Incremental Statistics. A přestože se od jeho příspěvku a vydání z dubna 2014 na tom, jak tato funkce funguje, mnoho nezměnilo, zdálo se, že je vhodný čas prozkoumat, jak povolení přírůstkových statistik může pomoci s výkonem údržby.
Přírůstkové statistiky se někdy nazývají statistiky na úrovni oddílu a je to proto, že SQL Server může poprvé automaticky vytvářet statistiky, které jsou specifické pro oddíl. Jedním z předchozích problémů s dělením bylo, že i když jste mohli mít 1 až n oddíly pro tabulku, existovala pouze jedna (1) statistika, která představovala rozložení dat ve všech těchto oddílech. Můžete vytvořit filtrovanou statistiku pro rozdělenou tabulku – jednu statistiku pro každou oblast – a poskytnout tak optimalizátoru dotazů lepší informace o distribuci dat. Ale toto byl ruční proces a vyžadoval skript, který je automaticky vytvořil pro každý nový oddíl.
V SQL Server 2014 používáte STATISTICS_INCREMENTAL možnost nechat SQL Server vytvořit tyto statistiky na úrovni oddílu automaticky. Tyto statistiky se však nepoužívají, jak byste si mohli myslet.
Již dříve jsem zmínil, že před rokem 2014 jste mohli vytvářet filtrované statistiky, aby měl optimalizátor lepší informace o oddílech. Ty přírůstkové statistiky? V současné době je optimalizátor nepoužívá. Optimalizátor dotazů stále používá pouze hlavní histogram, který představuje celou tabulku. (Příspěvek, který to bude demonstrovat!)
Jaký je tedy smysl přírůstkových statistik? Pokud předpokládáte, že se mění pouze data v nejnovějším oddílu, pak v ideálním případě aktualizujete statistiky pouze pro tento oddíl. Můžete to udělat nyní pomocí přírůstkových statistik – a co se stane, je, že informace se poté sloučí zpět do hlavního histogramu. Histogram pro celou tabulku se aktualizuje, aniž byste museli číst celou tabulku, abyste aktualizovali statistiky, což vám může pomoci s prováděním vašich úkolů údržby.
Nastavení
Začneme vytvořením funkce a schématu oddílu a poté nové tabulky, kterou rozdělíme. Všimněte si, že jsem vytvořil skupinu souborů pro každou funkci oddílu, jako byste mohli v produkčním prostředí. Schéma oddílů můžete vytvořit ve stejné skupině souborů (např. PRIMARY ), pokud nemůžete snadno zrušit testovací databázi. Každá skupina souborů má také velikost několika GB, protože přidáme téměř 400 milionů řádků.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Než přidáme data, vytvoříme seskupený index a všimněte si, že syntaxe obsahuje WITH (STATISTICS_INCREMENTAL = ON) možnost:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Zde je zajímavé poznamenat, že pokud se podíváte na ALTER TABLE záznam v MSDN, tuto možnost neobsahuje. Najdete jej pouze v ALTER INDEX vstup… ale funguje to. Pokud chcete dodržet dokumentaci do puntíku, spustili byste:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Jakmile bude vytvořen seskupený index pro schéma oddílů, načteme naše data a poté zkontrolujeme, kolik řádků existuje na oddíl (všimněte si, že to trvá více než 7 minut na mém notebooku možná budete chtít přidat méně řádků v závislosti na tom, kolik úložného prostoru (a času) máte k dispozici):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
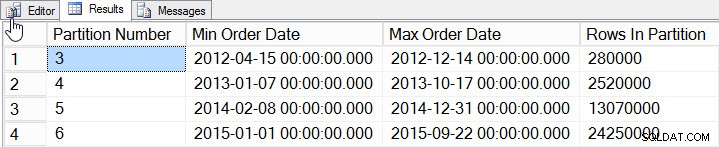 Data na oddíl
Data na oddíl
Přidali jsme data za roky 2012 až 2015, s podstatně více daty v letech 2014 a 2015. Podívejme se, jak vypadají naše statistiky:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
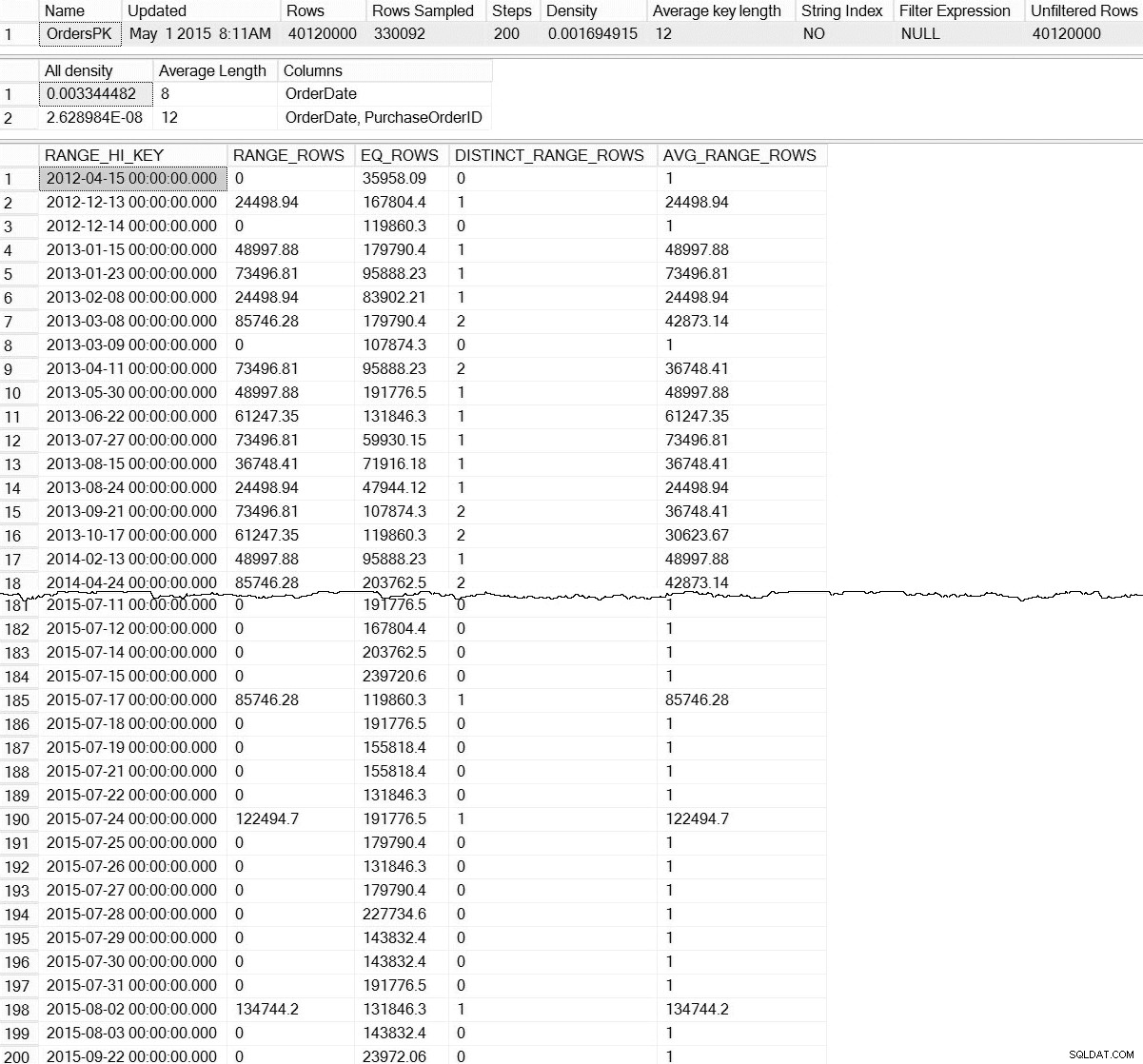 DBCC SHOW_STATISTICS výstup pro dbo.Orders (kliknutím zvětšíte)
DBCC SHOW_STATISTICS výstup pro dbo.Orders (kliknutím zvětšíte)
S výchozím DBCC SHOW_STATISTICS příkazu, nemáme žádné informace o statistikách na úrovni oddílu. Neboj se; nejsme úplně odsouzeni k záhubě – existuje nezdokumentovaná funkce dynamické správy, sys.dm_db_stats_properties_internal . Pamatujte, že nezdokumentovaný znamená, že není podporován (pro DMF neexistuje žádná položka MSDN) a že se může kdykoli změnit bez jakéhokoli upozornění od společnosti Microsoft. To znamená, že je to slušný začátek pro získání představy o tom, co existuje pro naše přírůstkové statistiky:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Informace o histogramu z dm_db_stats_properties_internal (kliknutím zvětšíte)
Informace o histogramu z dm_db_stats_properties_internal (kliknutím zvětšíte)
Tohle je mnohem zajímavější. Zde můžeme vidět důkaz, že statistiky na úrovni oddílu (a další) existují. Protože tento DMF není zdokumentován, musíme provést nějakou interpretaci. Pro dnešek se zaměříme na prvních sedm řádků ve výstupu, kde první řádek představuje histogram pro celou tabulku (všimněte si rows hodnota 40 milionů) a následující řádky představují histogramy pro každý oddíl. Bohužel partition_number hodnota v tomto histogramu není v souladu s číslem oddílu z sys.dm_db_index_physical_stats pro dělení založené na pravé straně (to správně koreluje pro dělení založené na levé straně). Všimněte si také, že tento výstup také obsahuje last_updated a modification_counter sloupců, které jsou užitečné při odstraňování problémů, a lze je použít k vývoji skriptů údržby, které inteligentně aktualizují statistiky na základě stáří nebo úprav řádků.
Minimalizace údržby
Primární hodnotou přírůstkových statistik je v současnosti možnost aktualizovat statistiky pro oddíl a nechat je sloučit do histogramu na úrovni tabulky, aniž by bylo nutné aktualizovat statistiku pro celou tabulku (a tedy číst celou tabulku). Abychom to viděli v akci, nejprve aktualizujeme statistiky pro oddíl, který obsahuje data z roku 2015, oddíl 5, a zaznamenáme čas a pořídíme snímek sys.dm_io_virtual_file_stats DMF před a po, abyste viděli, kolik I/O probíhá:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Výstup:
SQL Server Execution Times:Čas CPU =203 ms, uplynulý čas =240 ms.
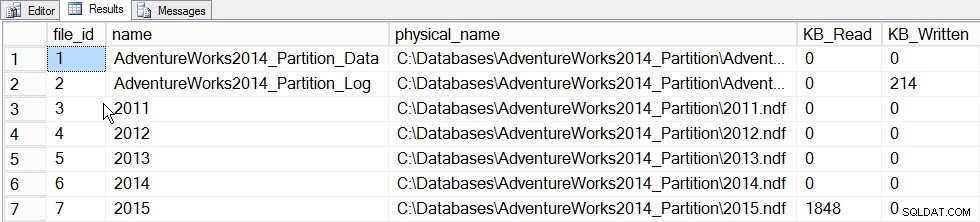 Data statistiky souborů po aktualizaci jednoho oddílu
Data statistiky souborů po aktualizaci jednoho oddílu
Pokud se podíváme na sys.dm_db_stats_properties_internal výstup, vidíme, že last_updated změněno pro histogram 2015 i histogram na úrovni tabulky (a také několik dalších uzlů, což je pro pozdější prozkoumání):
 Aktualizované informace o histogramu z dm_db_stats_properties_internal
Aktualizované informace o histogramu z dm_db_stats_properties_internal
Nyní aktualizujeme statistiky pomocí FULLSCAN pro tabulku a my uděláme snímek file_stats před a po znovu:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Výstup:
Časy spuštění serveru SQL:Čas CPU =12720 ms, uplynulý čas =13646 ms
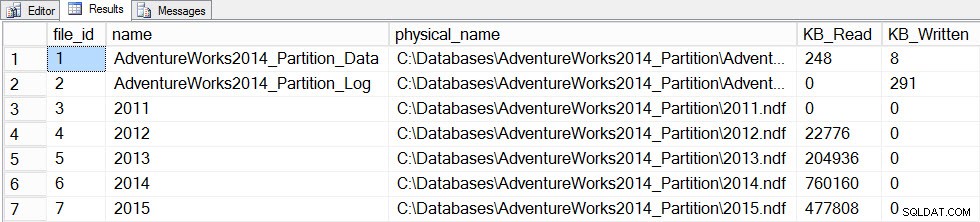 Data statistiky souborů po aktualizaci pomocí úplného skenování
Data statistiky souborů po aktualizaci pomocí úplného skenování
Aktualizace trvala podstatně déle (13 sekund oproti několika stovkám milisekund) a generovala mnohem více I/O. Pokud zaškrtneme sys.dm_db_stats_properties_internal znovu zjistíme, že last_updated změněno pro všechny histogramy:
 Informace o histogramu z dm_db_stats_properties_internal po úplném skenování
Informace o histogramu z dm_db_stats_properties_internal po úplném skenování
Shrnutí
I když přírůstkové statistiky zatím optimalizátor dotazů nepoužívá k poskytování informací o každé oblasti, při správě statistik pro dělené tabulky poskytují výhodu výkonu. Pokud je třeba aktualizovat statistiky pouze pro vybrané oddíly, lze aktualizovat pouze ty. Nové informace jsou pak sloučeny do histogramu na úrovni tabulky, což poskytuje optimalizátoru aktuálnější informace, aniž by to stálo přečtení celé tabulky. Do budoucna doufáme, že tyto statistiky na úrovni oddílu budou být používán optimalizátorem. Zůstaňte naladěni…