[ Část 1 | Část 2 | Část 3 | Část 4 ]
O porozumění a optimalizaci SELECT toho bylo v průběhu let napsáno mnoho dotazy, ale spíše méně o úpravě dat. Tato série příspěvků se zabývá problémem, který je specifický pro INSERT , UPDATE , DELETE a MERGE dotazy – Halloweenský problém.
Fráze „Halloween problém“ byla původně vytvořena s odkazem na SQL UPDATE dotaz, který měl poskytnout 10% zvýšení každému zaměstnanci, který vydělal méně než 25 000 $. Problém byl v tom, že dotaz neustále zvyšoval o 10 %, dokud všichni vydělal alespoň 25 000 $. Později v této sérii uvidíme, že základní problém se týká také INSERT , DELETE a MERGE dotazy, ale pro tento první záznam bude užitečné prozkoumat UPDATE problém v trochu detailu.
Pozadí
Jazyk SQL poskytuje uživatelům způsob, jak specifikovat změny databáze pomocí UPDATE příkaz, ale syntaxe neříká nic o jak databázový stroj by měl provést změny. Na druhou stranu standard SQL specifikuje, že výsledek UPDATE musí být stejný, jako kdyby byl proveden ve třech samostatných a nepřekrývajících se fázích:
- Vyhledávání pouze pro čtení určuje záznamy, které mají být změněny, a nové hodnoty sloupců
- Změny se použijí na dotčené záznamy
- Omezení konzistence databáze jsou ověřena
Implementace těchto tří fází doslova v databázovém stroji by přinesla správné výsledky, ale výkon nemusí být příliš dobrý. Mezivýsledky v každé fázi budou vyžadovat systémovou paměť, čímž se sníží počet dotazů, které může systém provádět souběžně. Potřebná paměť může také přesáhnout dostupnou paměť, což vyžaduje, aby byla alespoň část sady aktualizací zapsána na diskové úložiště a později znovu načtena. V neposlední řadě je třeba v rámci tohoto prováděcího modelu klepnout na každý řádek v tabulce několikrát.
Alternativní strategií je zpracovat UPDATE po řadě. To má tu výhodu, že se každého řádku dotknete pouze jednou, a obecně to nevyžaduje paměť pro uložení (ačkoli některé operace, jako například úplné řazení, musí zpracovat celou vstupní sadu před vytvořením prvního řádku výstupu). Tento iterativní model je ten, který používá stroj pro provádění dotazů SQL Server.
Úkolem optimalizátoru dotazů je najít iterativní (řádek po řádku) plán provádění, který splňuje UPDATE sémantiku vyžadovanou standardem SQL při zachování výhod výkonu a souběžnosti zřetězeného provádění.
Zpracování aktualizace
Pro ilustraci původního problému použijeme 10% zvýšení na každého zaměstnance, který vydělává méně než 25 000 $ pomocí Employees tabulka níže:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Strategie třífázové aktualizace
První fáze pouze pro čtení najde všechny záznamy, které splňují WHERE predikát klauzule a ušetří dostatek informací pro to, aby druhá fáze mohla pracovat. V praxi to znamená zaznamenat jedinečný identifikátor pro každý oprávněný řádek (sdružené indexové klíče nebo identifikátor řádku haldy) a novou hodnotu platu. Po dokončení první fáze se celá sada aktualizačních informací předá druhé fázi, která vyhledá každý záznam, který má být aktualizován, pomocí jedinečného identifikátoru a změní plat na novou hodnotu. Třetí fáze pak zkontroluje, že konečným stavem tabulky nejsou porušena žádná omezení integrity databáze.
Iterativní strategie
Tento přístup čte jeden řádek po druhém ze zdrojové tabulky. Pokud řádek splňuje WHERE doložný predikát se uplatní zvýšení platu. Tento proces se opakuje, dokud nejsou ze zdroje zpracovány všechny řádky. Vzorový plán provádění využívající tento model je uveden níže:

Jak je obvyklé pro kanál SQL Server řízený poptávkou, provádění začíná u operátora zcela vlevo – UPDATE v tomto případě. Vyžádá si řádek z aktualizace tabulky, která požádá o řádek z výpočetního skaláru, a dále v řetězci k prohledání tabulky:
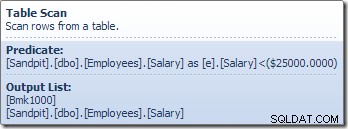
Operátor Table Scan čte řádky jeden po druhém z úložiště, dokud nenajde ten, který splňuje predikát Plat. Výstupní seznam na obrázku výše ukazuje operátor Skenování tabulky, který vrací identifikátor řádku a aktuální hodnotu sloupce Plat pro tento řádek. Jediný řádek obsahující odkazy na tyto dvě informace je předán výpočetnímu skaláru:
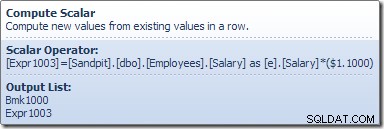
Compute Scalar definuje výraz, který aplikuje zvýšení platu na aktuální řádek. Vrátí řádek obsahující odkazy na identifikátor řádku a upravený plat do aktualizace tabulky, která vyvolá modul úložiště k provedení úpravy dat. Tento iterativní proces pokračuje, dokud prohledávání tabulky nedojde řádků. Stejný základní proces se použije, pokud má tabulka seskupený index:
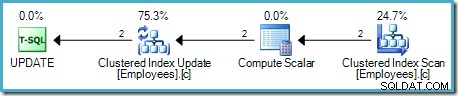
Hlavním rozdílem je, že seskupený indexový klíč (klíče) a uniquifier (pokud existuje) se používají jako identifikátor řádku namísto RID haldy.
Problém
Přechod z logické třífázové operace definované ve standardu SQL na model fyzického iterativního provádění přinesl řadu jemných změn, z nichž pouze jednu se dnes podíváme. V našem běžícím příkladu může nastat problém, pokud je ve sloupci Plat neshlukovaný index, který se optimalizátor dotazů rozhodne použít k nalezení řádků, které splňují podmínky (Mzda <25 000 USD):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Model provádění řádek po řádku nyní může produkovat nesprávné výsledky nebo se dokonce dostat do nekonečné smyčky. Zvažte (imaginární) iterativní plán provádění, který hledá index platu, vracející řádek po jednom do výpočetního skaláru a nakonec na operátor Update:

V tomto plánu je několik dalších výpočetních skalárů kvůli optimalizaci, která vynechává údržbu neshlukovaného indexu, pokud se hodnota platu nezměnila (v tomto případě možné pouze u nulového platu).
Když to ignorujeme, důležitým rysem tohoto plánu je, že nyní máme uspořádané částečné skenování indexu, které předává řádek po řádku operátorovi, který upravuje stejný index (zelené zvýraznění v grafu Průzkumníka plánů SQL Sentry nahoře jasně ukazuje, že Clustered Operátor aktualizace indexu udržuje jak základní tabulku, tak neclusterovaný index).
Problém je každopádně v tom, že při zpracovávání jednoho řádku po druhém může aktualizace posunout aktuální řádek před pozici skenování, kterou používá Index Seek k vyhledání řádků ke změně. Propracováním příkladu by mělo být toto tvrzení o něco jasnější:
Neshlukovaný index je klíčován a seřazen vzestupně podle hodnoty platu. Index také obsahuje ukazatel na nadřazený řádek v základní tabulce (buď haldu RID nebo seskupené indexové klíče plus uniquifier, pokud je to nutné). Aby bylo snazší následovat příklad, předpokládejme, že základní tabulka má nyní jedinečný seskupený index ve sloupci Název, takže obsah neshlukovaného indexu na začátku zpracování aktualizace je:
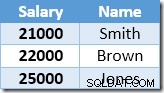
První řádek vrácený Index Seek je plat 21 000 $ pro Smith. Tato hodnota je aktualizována na 23 100 $ v základní tabulce a neclusterovém indexu operátorem Clustered Index. Neklastrovaný index nyní obsahuje:
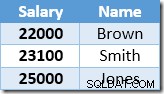
Další řádek vrácený hledáním indexu bude položka 22 000 $ pro Brown, která je aktualizována na 24 200 $:
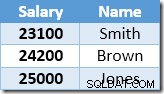
Nyní Index Seek najde hodnotu 23 100 USD pro Smith, která je znovu aktualizována na 25 410 USD. Tento proces pokračuje, dokud všichni zaměstnanci nebudou mít plat alespoň 25 000 $ – což není správný výsledek pro daný UPDATE dotaz. Stejný efekt za jiných okolností může vést k runaway aktualizaci, která se ukončí pouze tehdy, když na serveru dojde místo v logu nebo dojde k chybě přetečení (může nastat v tomto případě, pokud má někdo nulový plat). Toto je Halloweenský problém, který se vztahuje na aktualizace.
Jak se vyhnout halloweenskému problému kvůli aktualizacím
Čtenáři s orlíma očima si jistě všimli, že odhadovaná procenta nákladů v pomyslném plánu Index Seek nedosahují 100 %. S Plan Explorerem to není problém – záměrně jsem z plánu odstranil klíčového operátora:

Optimalizátor dotazů rozpozná, že tento zřetězený aktualizační plán je zranitelný vůči Halloweenskému problému a zavádí Eager Table Spool, aby k němu nedošlo. Neexistuje žádná nápověda ani příznak trasování, které by bránily zahrnutí zařazování do tohoto plánu provádění, protože je to vyžadováno pro správnost.
Jak jeho název napovídá, zařazování dychtivě spotřebovává všechny řádky od svého podřízeného operátora (index Seek), než vrátí řádek do svého nadřazeného výpočetního skaláru. Výsledkem je úplné oddělení fází – všechny kvalifikující řádky jsou načteny a uloženy do dočasného úložiště před provedením jakýchkoli aktualizací.
To nás přibližuje k třífázové logické sémantice standardu SQL, i když mějte na paměti, že provádění plánu je stále v zásadě iterativní, s operátory napravo od zařazování tvoří kurzor čtení a operátory vlevo tvořící kurzor zápisu . Obsah zařazování se stále čte a zpracovává řádek po řádku (nepředává se hromadně protože srovnání se standardem SQL by vás jinak mohlo vést k domněnce).
Nevýhody separace fází jsou stejné, jak bylo zmíněno dříve. Spool tabulky spotřebovává tempdb prostoru (stránky ve fondu vyrovnávacích pamětí) a může vyžadovat fyzické čtení a zápis na disk pod tlakem paměti. Optimalizátor dotazů přiřadí zařazování odhadované náklady (s výhradou všech obvyklých upozornění ohledně odhadů) a vybere mezi plány, které vyžadují ochranu před Halloweenským problémem, a těmi, které ji nevyžadují na základě odhadovaných nákladů jako obvykle. Přirozeně může optimalizátor nesprávně vybrat mezi možnostmi z jakéhokoli běžného důvodu.
V tomto případě je kompromis mezi zvýšením efektivity přímým hledáním kvalifikačních záznamů (těch, kteří mají plat <25 000 $) a odhadovanými náklady na cívku potřebnou k vyhnutí se Halloweenskému problému. Alternativní plán (v tomto konkrétním případě) je úplné prohledání seskupeného indexu (nebo haldy). Tato strategie nevyžaduje stejnou Halloweenskou ochranu, protože klíče seskupeného indexu se nezmění:

Protože indexové klíče jsou stabilní, řádky se nemohou mezi iteracemi pohybovat v indexu, čímž se v tomto případě vyhýbá Halloweenskému problému. V závislosti na provozních nákladech Clustered Index Scan ve srovnání s kombinací Index Seek plus Eager Table Spool, kterou jsme viděli dříve, se může jeden plán spustit rychleji než druhý. Další úvahou je, že plán s Halloweenskou ochranou získá více zámků než plán plně zřetězený a zámky budou drženy déle.
Poslední myšlenky
Pochopení problému Halloweenu a jeho účinků na plány dotazů na úpravu dat vám pomůže analyzovat plány provádění změn dat a může nabídnout příležitosti, jak se vyhnout nákladům a vedlejším účinkům zbytečné ochrany, pokud je k dispozici alternativa.
Existuje několik forem Halloweenského problému, z nichž ne všechny jsou způsobeny čtením a zápisem do klíčů společného indexu. Halloweenský problém se také neomezuje na UPDATE dotazy. Optimalizátor dotazů má v rukávu další triky, jak se vyhnout Halloweenskému problému, kromě separace fází hrubou silou pomocí Eager Table Spool. Tyto body (a další) budou prozkoumány v dalších dílech této série.
[ Část 1 | Část 2 | Část 3 | Část 4 ]