Pravděpodobně víte, jak vkládat záznamy do tabulky pomocí jedné nebo více klauzulí VALUES. Víte také, jak provádět hromadné vkládání pomocí SQL INSERT INTO SELECT. Ale stejně jste klikli na článek. Jde o zpracování duplikátů?
Mnoho článků pojednává o SQL INSERT INTO SELECT. Google nebo Bing a vyberte si titulek, který se vám nejvíce líbí – bude to stačit. Nebudu uvádět ani základní příklady toho, jak se to dělá. Místo toho uvidítepříklady, jak jej používat A zároveň zpracovávat duplikáty . Takže ze svého úsilí INSERT můžete udělat tuto známou zprávu:
Msg 2601, Level 14, State 1, Line 14
Cannot insert duplicate key row in object 'dbo.Table1' with unique index 'UIX_Table1_Key1'. The duplicate key value is (value1).
Ale nejdřív.

[sendpulse-form id=”12989″]
Příprava testovacích dat pro SQL INSERT INTO SELECT vzorků kódu
Tentokrát myslím na těstoviny. Použiji tedy údaje o těstovinových pokrmech. Na Wikipedii jsem našel dobrý seznam těstovin, které můžeme použít a extrahovat v Power BI pomocí webového zdroje dat. Zadal jsem URL Wikipedie. Poté jsem specifikoval 2-tabulková data ze stránky. Trochu jsem to vyčistil a zkopíroval data do Excelu.
Nyní máme data – můžete si je stáhnout zde. Je to syrové, protože z toho uděláme 2 relační tabulky. Pomocí INSERT INTO SELECT nám pomůže tento úkol,
Importujte data na SQL Server
K importu 2 listů do souboru Excel můžete použít SQL Server Management Studio nebo dbForge Studio pro SQL Server.
Před importem dat vytvořte prázdnou databázi. Tabulky jsem pojmenoval dbo.ItalianPastaDishes a dbo.NonItalianPastaDishes .
Vytvořit 2 další stoly
Pojďme definovat dvě výstupní tabulky pomocí příkazu SQL Server ALTER TABLE.
CREATE TABLE [dbo].[Origin](
[OriginID] [int] IDENTITY(1,1) NOT NULL,
[Origin] [varchar](50) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_Origin] PRIMARY KEY CLUSTERED
(
[OriginID] ASC
))
GO
ALTER TABLE [dbo].[Origin] ADD CONSTRAINT [DF_Origin_Modified] DEFAULT (getdate()) FOR [Modified]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_Origin] ON [dbo].[Origin]
(
[Origin] ASC
)
GO
CREATE TABLE [dbo].[PastaDishes](
[PastaDishID] [int] IDENTITY(1,1) NOT NULL,
[PastaDishName] [nvarchar](75) NOT NULL,
[OriginID] [int] NOT NULL,
[Description] [nvarchar](500) NOT NULL,
[Modified] [datetime] NOT NULL,
CONSTRAINT [PK_PastaDishes_1] PRIMARY KEY CLUSTERED
(
[PastaDishID] ASC
))
GO
ALTER TABLE [dbo].[PastaDishes] ADD CONSTRAINT [DF_PastaDishes_Modified_1] DEFAULT (getdate()) FOR [Modified]
GO
ALTER TABLE [dbo].[PastaDishes] WITH CHECK ADD CONSTRAINT [FK_PastaDishes_Origin] FOREIGN KEY([OriginID])
REFERENCES [dbo].[Origin] ([OriginID])
GO
ALTER TABLE [dbo].[PastaDishes] CHECK CONSTRAINT [FK_PastaDishes_Origin]
GO
CREATE UNIQUE NONCLUSTERED INDEX [UIX_PastaDishes_PastaDishName] ON [dbo].[PastaDishes]
(
[PastaDishName] ASC
)
GO
Poznámka:Ve dvou tabulkách jsou vytvořeny jedinečné indexy. Zabrání nám to v pozdějším vkládání duplicitních záznamů. Omezení učiní tuto cestu o něco těžší, ale vzrušující.
Nyní, když jsme připraveni, pojďme se ponořit.
5 snadných způsobů, jak zvládnout duplikáty pomocí SQL INSERT INTO SELECT
Nejjednodušší způsob, jak zvládnout duplikáty, je odstranit jedinečná omezení, že?
Špatně!
Po odstranění jedinečných omezení je snadné udělat chybu a vložit data dvakrát nebo vícekrát. To nechceme. A co když máme uživatelské rozhraní s rozevíracím seznamem pro výběr původu těstovin? Udělají duplikáty vaše uživatele šťastnými?
Odstranění jedinečných omezení proto není jedním z pěti způsobů zpracování nebo odstranění duplicitních záznamů v SQL. Máme lepší možnosti.
1. Pomocí INSERT INTO SELECT DISTINCT
První možností, jak identifikovat záznamy SQL v SQL, je použití DISTINCT ve vašem SELECT. Abychom případ prozkoumali, vyplníme Původ stůl. Nejprve však použijeme špatnou metodu:
-- This is wrong and will trigger duplicate key errors
INSERT INTO Origin
(Origin)
SELECT origin FROM NonItalianPastaDishes
GO
INSERT INTO Origin
(Origin)
SELECT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
GO
To spustí následující duplicitní chyby:
Msg 2601, Level 14, State 1, Line 2
Cannot insert a duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (United States).
The statement has been terminated.
Msg 2601, Level 14, State 1, Line 6
Cannot insert duplicate key row in object 'dbo.Origin' with unique index 'UIX_Origin'. The duplicate key value is (Lombardy, Italy).
Při pokusu o výběr duplicitních řádků v SQL došlo k problému. Abych zahájil kontrolu SQL na duplikáty, které existovaly dříve, spustil jsem část SELECT příkazu INSERT INTO SELECT:
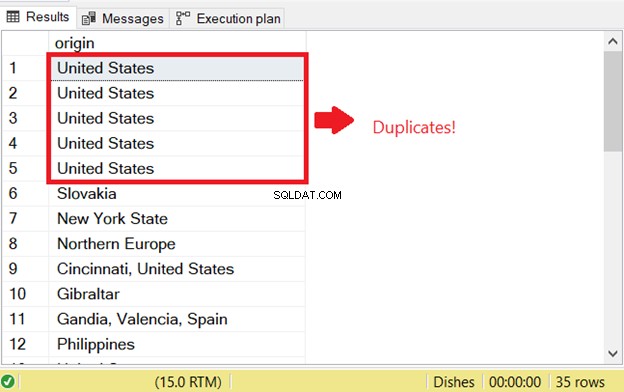
To je důvod první duplicitní chyby SQL. Chcete-li tomu zabránit, přidejte klíčové slovo DISTINCT, aby byla sada výsledků jedinečná. Zde je správný kód:
-- The correct way to INSERT
INSERT INTO Origin
(Origin)
SELECT DISTINCT origin FROM NonItalianPastaDishes
INSERT INTO Origin
(Origin)
SELECT DISTINCT ItalianRegion + ', ' + 'Italy'
FROM ItalianPastaDishes
Úspěšně vloží záznamy. A máme hotovo s Originem tabulka.
Použití DISTINCT vytvoří jedinečné záznamy z příkazu SELECT. Nezaručuje však, že v cílové tabulce neexistují duplikáty. Je dobré, když jste si jisti, že cílová tabulka nemá hodnoty, které chcete vložit.
Proto tyto příkazy nespouštějte více než jednou.
2. Pomocí WHERE NOT IN
Dále vyplníme PastaDishes stůl. K tomu musíme nejprve vložit záznamy z ItalianPastaDishes stůl. Zde je kód:
INSERT INTO [dbo].[PastaDishes]
(PastaDishName,OriginID, Description)
SELECT
a.DishName
,b.OriginID
,a.Description
FROM ItalianPastaDishes a
INNER JOIN Origin b ON a.ItalianRegion + ', ' + 'Italy' = b.Origin
WHERE a.DishName NOT IN (SELECT PastaDishName FROM PastaDishes)
Od ItalianPastaDishes obsahuje nezpracovaná data, musíme se připojit k Originu text namísto OriginID . Nyní zkuste spustit stejný kód dvakrát. Při druhém spuštění nebudou vloženy žádné záznamy. Stává se to kvůli klauzuli WHERE s operátorem NOT IN. Filtruje záznamy, které již existují v cílové tabulce.
Dále musíme naplnit PastaDishes stůl z NonitalianPastaDishes stůl. Protože jsme teprve u druhého bodu tohoto příspěvku, nevložíme vše.
Vybrali jsme těstoviny ze Spojených států a Filipín. Tady:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using NOT IN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
AND b.OriginID IN (15,22)
Z tohoto výpisu je vloženo 9 záznamů – viz obrázek 2 níže:
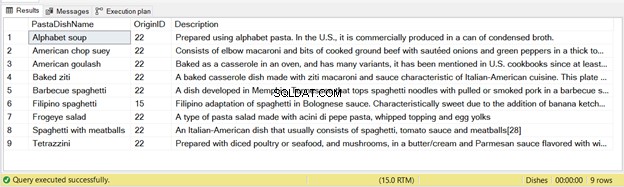
Opět platí, že pokud výše uvedený kód spustíte dvakrát, při druhém spuštění nebudou vloženy žádné záznamy.
3. Pomocí WHERE NOT EXISTS
Dalším způsobem, jak najít duplikáty v SQL, je použít NOT EXISTS v klauzuli WHERE. Zkusme to se stejnými podmínkami jako v předchozí části:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using WHERE NOT EXISTS
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
AND b.OriginID IN (15,22)
Výše uvedený kód vloží stejných 9 záznamů, jaké jste viděli na obrázku 2. Vyhnete se tak vkládání stejných záznamů více než jednou.
4. Pomocí IF NOT EXISTS
Někdy může být potřeba nasadit tabulku do databáze a je nutné zkontrolovat, zda tabulka se stejným názvem již neexistuje, aby se předešlo duplicitám. V tomto případě může být velkou pomocí příkaz SQL DROP TABLE IF EXISTS. Dalším způsobem, jak zajistit, že nebudete vkládat duplikáty, je použití IF NOT EXISTS. Opět použijeme stejné podmínky z předchozí části:
-- Insert pasta dishes from the United States (22) and the Philippines (15) using IF NOT EXISTS
IF NOT EXISTS(SELECT PastaDishName FROM PastaDishes pd
WHERE pd.OriginID IN (15,22))
BEGIN
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
END
Výše uvedený kód nejprve zkontroluje existenci 9 záznamů. Pokud vrátí hodnotu true, INSERT bude pokračovat.
5. Pomocí COUNT(*) =0
A konečně, použití COUNT(*) v klauzuli WHERE může také zajistit, že nebudete vkládat duplikáty. Zde je příklad:
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE b.OriginID IN (15,22)
AND (SELECT COUNT(*) FROM PastaDishes pd
WHERE pd.OriginID IN (15,22)) = 0
Aby se předešlo duplicitám, měl by být COUNT nebo záznamy vrácené výše uvedeným poddotazem nula.
Poznámka :Jakýkoli dotaz můžete navrhnout vizuálně v diagramu pomocí funkce Query Builder v dbForge Studio pro SQL Server.
Porovnání různých způsobů zpracování duplikátů pomocí SQL INSERT INTO SELECT
4 sekce používaly stejný výstup, ale různé přístupy k vkládání hromadných záznamů pomocí příkazu SELECT. Možná vás napadne, jestli je rozdíl jen na povrchu. Můžeme zkontrolovat jejich logická čtení ze STATISTICS IO, abychom viděli, jak se liší.
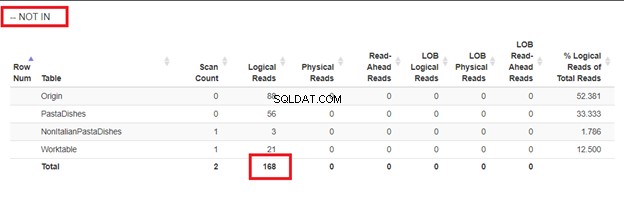
Použití WHERE NOT IN:
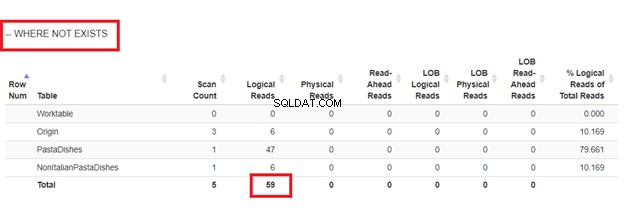
Pomocí NOT EXISTS:
Použití IF NOT EXISTS:
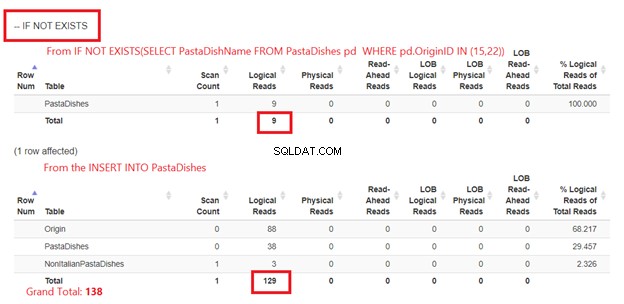
Obrázek 5 je trochu jiný. Pro PastaDishes se zobrazí 2 logická čtení stůl. První je z IF NOT EXISTS (SELECT PastaDishName z PastaDishes KDE OriginID IN (15,22)). Druhý je z příkazu INSERT.
Nakonec pomocí COUNT(*) =0
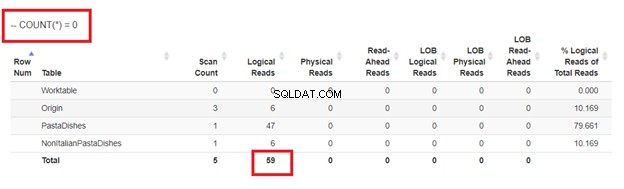
Z logických čtení 4 přístupů, které jsme měli, je nejlepší volbou WHERE NOT EXISTS nebo COUNT(*) =0. Když zkontrolujeme jejich plány provádění, vidíme, že mají stejný QueryHashPlan . Mají tedy podobné plány. Mezitím nejméně efektivní je použití NOT IN.
Znamená to, že KDE NEEXISTUJE je vždy lepší než NE IN? Vůbec ne.
Vždy zkontrolujte logická čtení a plán provádění vašich dotazů!
Než však skončíme, musíme úkol dokončit. Poté vložíme zbytek záznamů a zkontrolujeme výsledky.
-- Insert the rest of the records
INSERT INTO dbo.PastaDishes
(PastaDishName, OriginID, Description)
SELECT
a.PastaDishName
,b.OriginID
,a.Description
FROM NonItalianPastaDishes a
INNER JOIN Origin b ON a.Origin = b.Origin
WHERE a.PastaDishName NOT IN (SELECT PastaDishName FROM PastaDishes)
GO
-- View the output
SELECT
a.PastaDishID
,a.PastaDishName
,b.Origin
,a.Description
,a.Modified
FROM PastaDishes a
INNER JOIN Origin b ON a.OriginID = b.OriginID
ORDER BY b.Origin, a.PastaDishName
Při listování v seznamu 179 těstovinových jídel od Asie po Evropu mám hlad. Podívejte se níže na část seznamu z Itálie, Ruska a dalších:

Závěr
Vyhnout se duplicitám v SQL INSERT INTO SELECT není nakonec tak těžké. Máte po ruce operátory a funkce, které vás dostanou na tuto úroveň. Je také dobrým zvykem zkontrolovat Prováděcí plán a logické čtení, abyste mohli porovnat, co je lepší.
Pokud si myslíte, že z tohoto příspěvku bude mít prospěch někdo jiný, sdílejte jej na svých oblíbených platformách sociálních médií. A pokud chcete přidat něco, co jsme zapomněli, dejte nám vědět v sekci Komentáře níže.