Jako správci databází SQL Serveru jsme slyšeli, že indexové struktury mohou výrazně zlepšit výkon jakéhokoli daného dotazu (nebo sady dotazů). Přesto existují určité detaily, které mnoho správců databází přehlíží, například následující:
- Struktury indexu se mohou fragmentovat, což může vést k problémům se snížením výkonu.
- Jakmile byla pro databázovou tabulku nasazena struktura indexu, SQL Server ji aktualizuje vždy, když pro danou tabulku proběhnou operace zápisu. K tomu dojde, pokud jsou ovlivněny sloupce, které odpovídají indexu.
- Uvnitř serveru SQL jsou metadata, která lze použít ke zjištění, kdy byly statistiky pro konkrétní strukturu indexu naposledy aktualizovány (pokud vůbec). Nedostatečné nebo zastaralé statistiky mohou ovlivnit výkon určitých dotazů.
- Uvnitř SQL Serveru jsou metadata, která lze použít ke zjištění, jak moc byla struktura indexu spotřebována operacemi čtení nebo aktualizována operacemi zápisu samotným SQL Serverem. Tato informace může být užitečná pro zjištění, zda existují indexy, jejichž objem zápisu výrazně převyšuje objem čtení. Potenciálně to může být struktura indexu, kterou není tak užitečné udržovat.*
*Je velmi důležité mít na paměti, že systémový pohled, který obsahuje tato konkrétní metadata, se vymaže při každém restartu instance SQL Serveru, takže nepůjde o informace z jeho koncepce.
Vzhledem k důležitosti těchto podrobností jsem vytvořil uloženou proceduru, abych mohl sledovat informace týkající se indexových struktur v jeho/její prostředí, abych mohl jednat co nejaktivněji.
Počáteční úvahy
- Ujistěte se, že účet spouštějící tuto uloženou proceduru má dostatečná oprávnění. Pravděpodobně byste mohli začít u systémových administrátorů a poté postupovat co nejpodrobněji, abyste se ujistili, že uživatel má minimální oprávnění potřebná pro správné fungování SP.
- Databázové objekty (databázová tabulka a uložená procedura) budou vytvořeny uvnitř databáze vybrané v době, kdy je skript spuštěn, takže vybírejte pečlivě.
- Skript je vytvořen tak, že jej lze spustit vícekrát, aniž by došlo k chybě. Pro uloženou proceduru jsem použil příkaz CREATE OR ALTER PROCEDURE, který je k dispozici od SQL Server 2016 SP1.
- Pokud chcete použít jinou konvenci pojmenování, můžete změnit název vytvořených databázových objektů.
- Pokud se rozhodnete zachovat data vrácená uloženou procedurou, cílová tabulka bude nejprve zkrácena, takže bude uložena pouze nejnovější sada výsledků. Můžete provést potřebné úpravy, pokud chcete, aby se to z jakéhokoli důvodu chovalo jinak (možná kvůli zachování historických informací?).
Jak používat uloženou proceduru?
- Zkopírujte a vložte kód T-SQL (k dispozici v tomto článku).
- SP očekává 2 parametry:
- @persistData:„Y“, pokud si DBA přeje uložit výstup do cílové tabulky, a „N“, pokud chce DBA pouze přímo vidět výstup.
- @db:'all' pro získání informací pro všechny databáze (systém a uživatel), 'user' pro cílové uživatelské databáze, 'system' pro cílení pouze na systémové databáze (kromě tempdb) a nakonec skutečný název konkrétní databázi.
Prezentovaná pole a jejich význam
- dbName: název databáze, kde se nachází objekt indexu.
- název schématu: název schématu, kde se nachází objekt indexu.
- název_tabulky: název tabulky, kde se nachází objekt indexu.
- indexName: název struktury indexu.
- typ: typ indexu (např. Clustered, Non-Clustered).
- allocation_unit_type: určuje typ dat, na která se odkazuje (např. in-row data, lob data).
- fragmentace: míra fragmentace (v %), kterou struktura indexu aktuálně má.
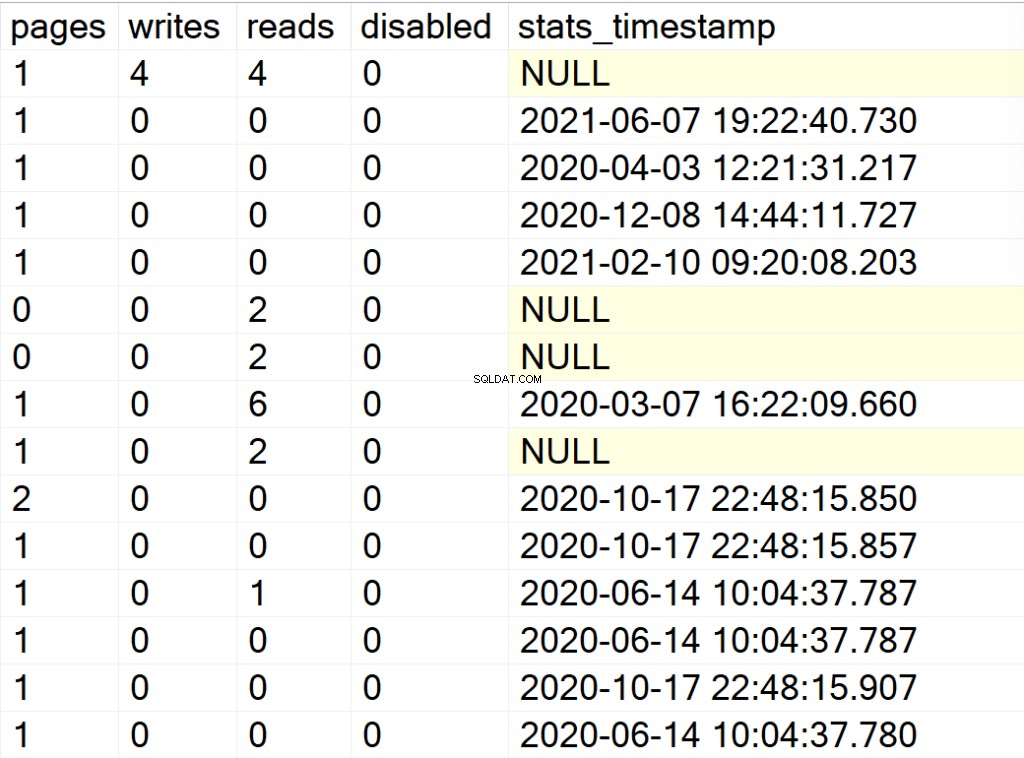
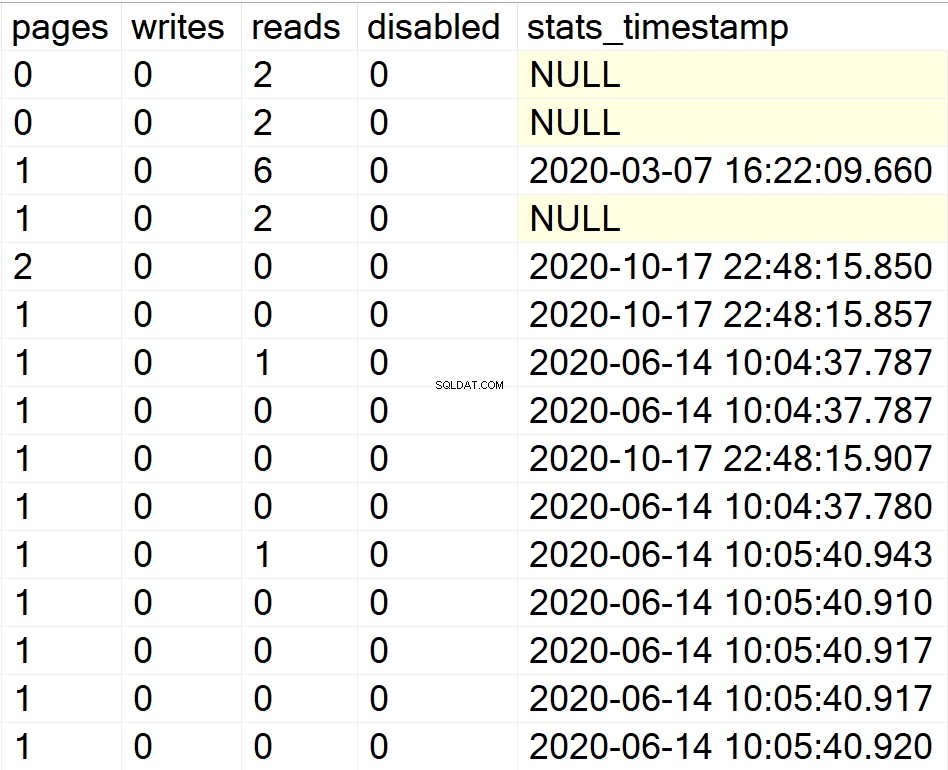
- stránky: počet stránek o velikosti 8 kB, které tvoří strukturu indexu.
- píše: počet zápisů, které struktura indexu zaznamenala od posledního restartování instance SQL Server.
- čte: počet čtení, která struktura indexu zaznamenala od posledního restartování instance SQL Server.
- deaktivováno: 1, pokud je struktura indexu aktuálně zakázána, nebo 0, pokud je struktura povolena.
- stats_timestamp: hodnota časového razítka, kdy byly statistiky pro konkrétní strukturu indexu naposledy aktualizovány (NULL, pokud nikdy).
- data_collection_timestamp: viditelné pouze v případě, že je parametru @persistData předáno „Y“ a používá se ke zjištění, kdy byl SP proveden a informace byly úspěšně uloženy do tabulky DBA_Indexes.
Testy provedení
Předvedu několik provedení uložené procedury, abyste si mohli udělat představu, co od ní očekávat:
*Úplný T-SQL kód skriptu najdete na konci tohoto článku, takže se ujistěte, že jste jej spustili, než přejdete k následující části.
*Výsledková sada bude příliš široká na to, aby se vešla na 1 snímek obrazovky, takže se s vámi podělím o všechny potřebné snímky obrazovky, abych mohl prezentovat úplné informace.
/* Zobrazí všechny informace o indexech pro všechny systémové a uživatelské databáze */
EXEC GetIndexData @persistData = 'N',@db = 'all'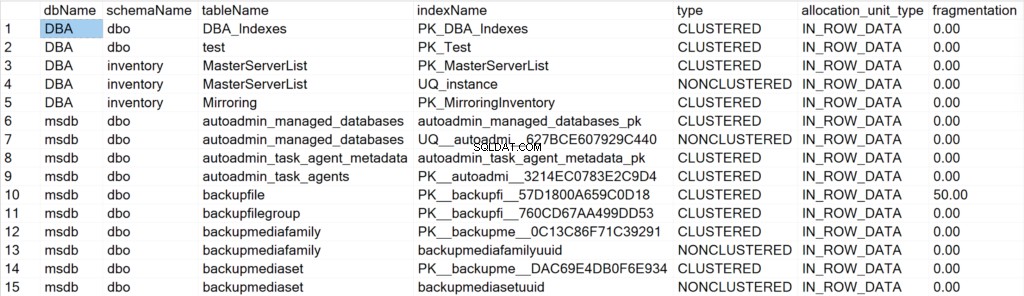
/* Zobrazí všechny informace o indexech pro všechny systémové databáze */
EXEC GetIndexData @persistData = 'N',@db = 'system'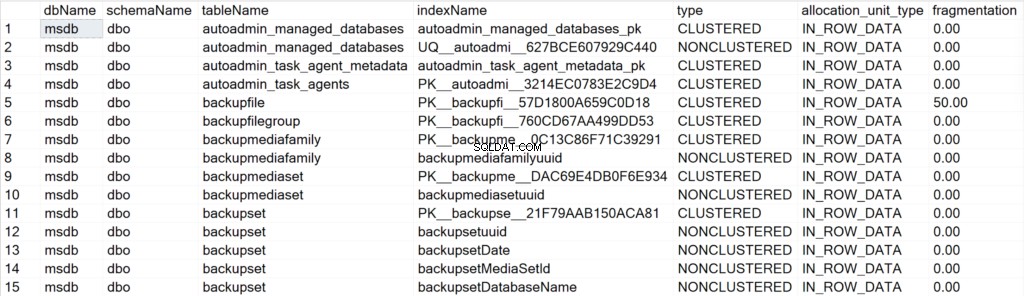
/* Zobrazí všechny informace o indexech pro všechny uživatelské databáze */
EXEC GetIndexData @persistData = 'N',@db = 'user'
/* Zobrazí všechny informace o indexech pro konkrétní uživatelské databáze */
V mých předchozích příkladech se jako moje jediná uživatelská databáze s indexy ukázala pouze databáze DBA. Proto mi dovolte vytvořit indexovou strukturu v jiné databázi, kterou mám ve stejné instanci, abyste viděli, zda SP dělá svou věc nebo ne.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Všechny dosud uvedené příklady demonstrují výstup, který získáte, když nechcete uchovávat data, pro různé kombinace možností pro parametr @db. Výstup je prázdný, když buď zadáte volbu, která není platná, nebo cílová databáze neexistuje. Ale co když DBA chce uchovávat data v databázové tabulce? Pojďme to zjistit.
*Spustím SP pouze pro jeden případ, protože ostatní možnosti pro parametr @db byly do značné míry ukázány výše a výsledek je stejný, ale zůstal zachován v databázové tabulce.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
Nyní, po provedení uložené procedury, nezískáte žádný výstup. Chcete-li se dotazovat na sadu výsledků, musíte zadat příkaz SELECT pro tabulku DBA_Indexes. Hlavním lákadlem je zde to, že můžete dotazovat získanou sadu výsledků pro následnou analýzu a přidat pole data_collection_timestamp, které vám dá vědět, jak nedávná/stará jsou data, na která se díváte.
Postranní dotazy
Nyní, abych DBA dodal větší hodnotu, připravil jsem několik dotazů, které vám mohou pomoci získat užitečné informace z dat uložených v tabulce.
*Dotaz k nalezení celkově velmi fragmentovaných indexů.
*Vyberte počet %, který považujete za vhodný.
*Těch 1500 stránek je založeno na článku, který jsem četl, na základě doporučení společnosti Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Dotaz na nalezení zakázaných indexů ve vašem prostředí.
SELECT * FROM DBA_Indexes WHERE disabled = 1;*Dotaz k nalezení indexů (většinou neseskupených), které nejsou tolik využívány dotazy, alespoň ne od posledního restartu instance SQL Server.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';*Dotaz k nalezení statistik, které nebyly nikdy aktualizovány nebo jsou staré.
*Vy určujete, co je ve vašem prostředí staré, takže podle toho upravte počet dní.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Zde je úplný kód uložené procedury:
*Na úplném začátku skriptu uvidíte výchozí hodnotu, kterou uložená procedura předpokládá, pokud není pro každý parametr předána žádná hodnota.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOZávěr
- Tento SP můžete nasadit v každé instanci SQL Serveru pod vaší podporou a implementovat výstražný mechanismus napříč celou vaší hromadou podporovaných instancí.
- Pokud implementujete úlohu agenta, která se dotazuje na tyto informace relativně často, můžete zůstat na vrcholu hry a postarat se o struktury indexů v podporovaných prostředích.
- Ujistěte se, že jste tento mechanismus řádně otestovali v prostředí izolovaného prostoru, a když plánujete produkční nasazení, vyberte období s nízkou aktivitou.
Problémy s fragmentací indexu mohou být složité a stresující. Chcete-li je najít a opravit, můžete použít různé nástroje, jako je dbForge Index Manager, který si můžete stáhnout zde.