Úvod
V databázových kruzích je všeobecně známo, že indexy zlepšují výkon dotazů buď tím, že plně uspokojí požadovanou sadu výsledků (Covering Indexes), nebo fungují jako vyhledávání, která snadno nasměrují Query Engine na přesné umístění požadované datové sady. Jak však zkušení správci databází vědí, člověk by neměl být příliš nadšený z vytváření indexů v prostředích OLTP, aniž by chápal povahu pracovní zátěže. Pomocí Query Store v instanci SQL Server 2019 (Query Store byl představen v SQL Server 2016) je docela snadné ukázat vliv indexu na vkládání.
Vložit bez indexu
Začneme obnovením databáze WideWorldImporters Sample a poté vytvořením kopie prodeje. Tabulka faktur pomocí skriptu ve Výpisu 1. Všimněte si, že ukázková databáze již má povoleno úložiště dotazů v režimu čtení i zápisu.
-- Listing 1 Make a Copy Of Invoices SELECT * INTO [SALES].[INVOICES1] FROM [SALES].[INVOICES] WHERE 1=2;
Všimněte si, že v tabulce, kterou jsme právě vytvořili, nejsou vůbec žádné indexy. Jediné, co máme, je struktura tabulky. Po dokončení provedeme vložení do nové tabulky pomocí dat z její nadřazené tabulky, jak je znázorněno ve výpisu 2.
-- Listing 2 Populate Invoices1 -- TRUNCATE TABLE [SALES].[INVOICES1] INSERT INTO [SALES].[INVOICES1] SELECT * FROM [SALES].[INVOICES]; GO 100
Během této operace úložiště dotazů zachytí plán provádění dotazu. Obrázek 1 stručně ukazuje, co se děje pod kapotou. Při čtení zleva doprava vidíme, že SQL Server provádí vložení pomocí Plan ID 563 – indexové skenování primárního klíče zdrojové tabulky k načtení dat a poté vložení tabulky do cílové tabulky. (Čtení zleva doprava). Všimněte si, že v tomto případě je hlavní část nákladů na tabulce – 99 % z ceny dotazu.
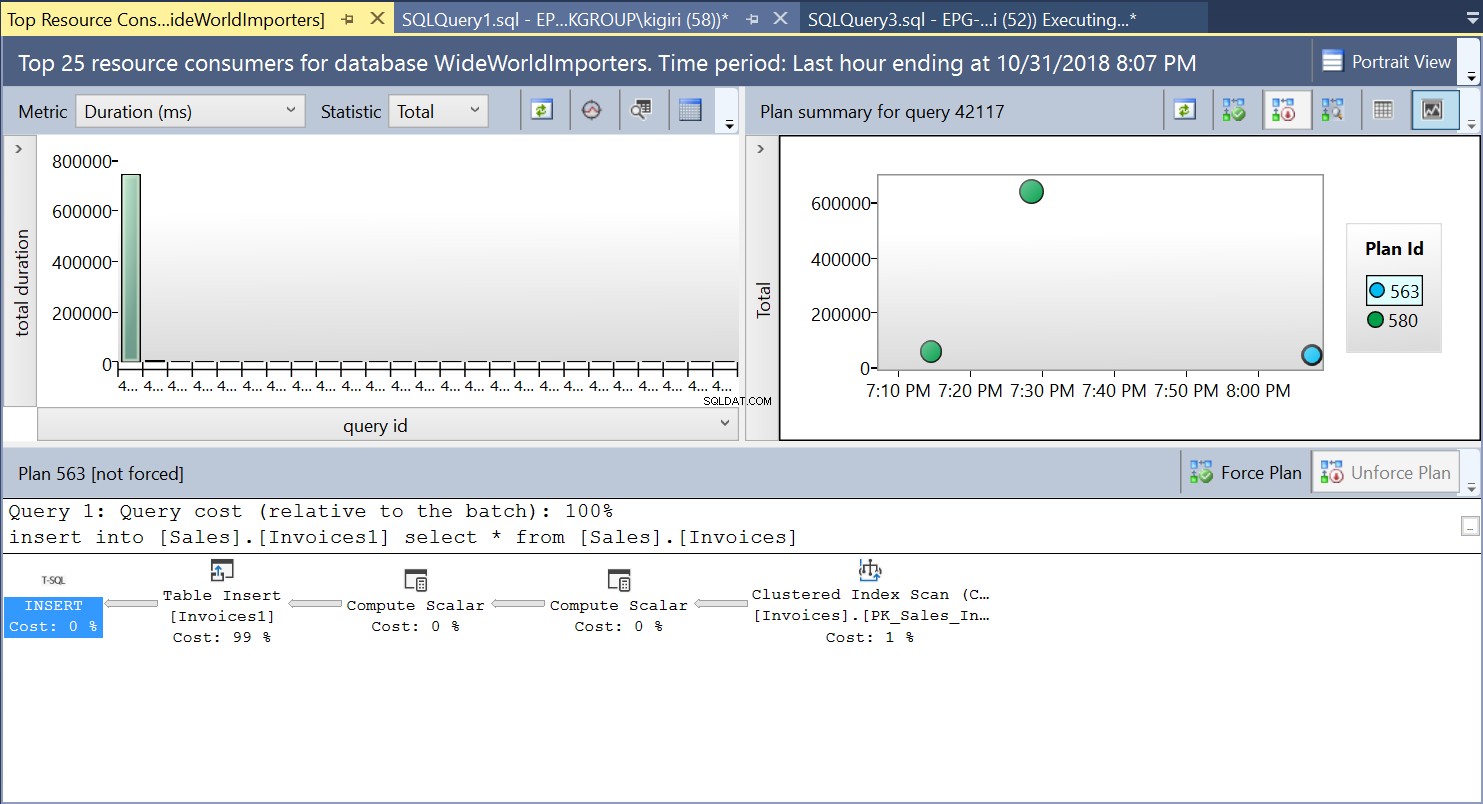
Obr. 1 Prováděcí plán 563
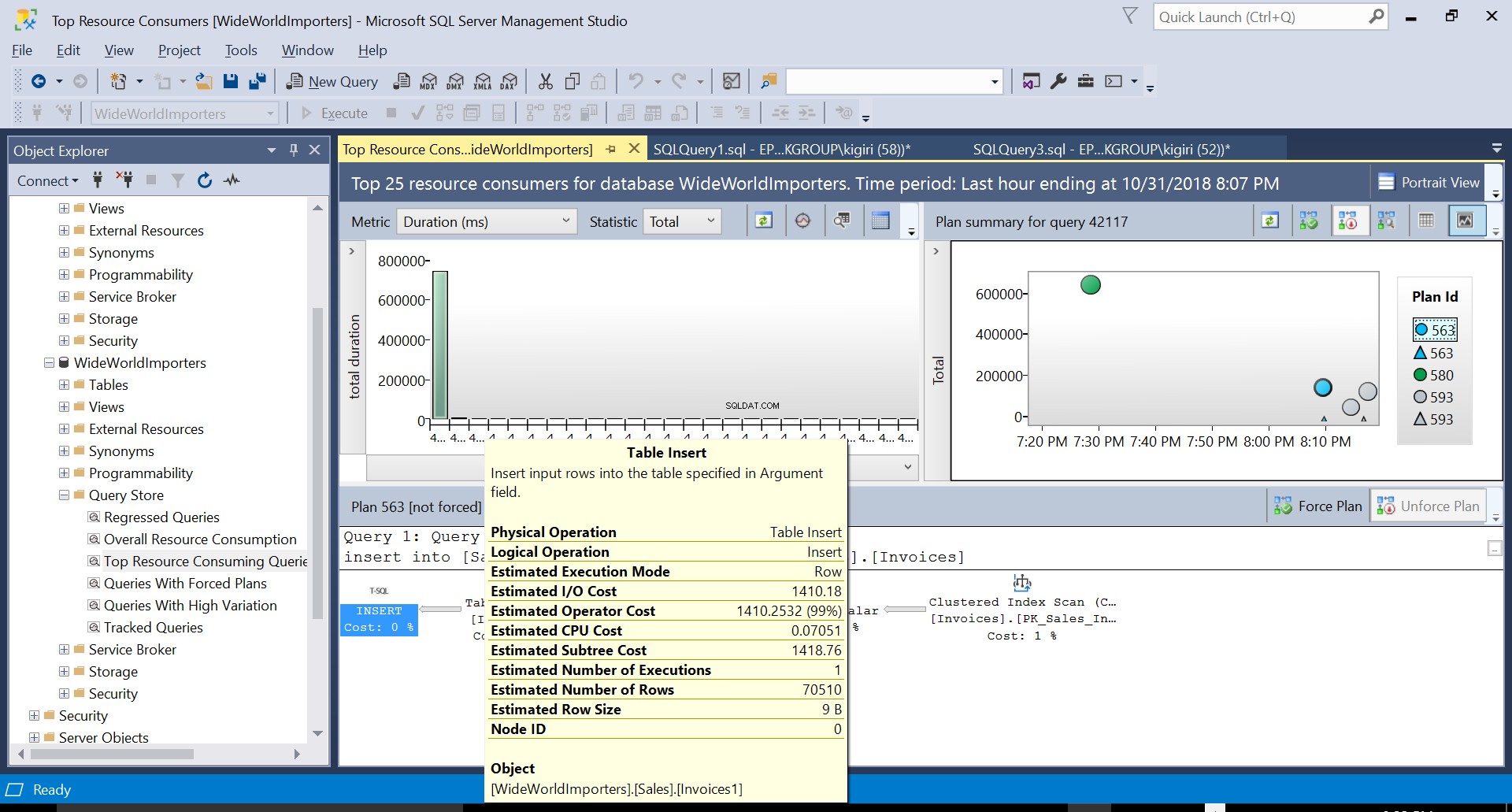
Obr. 2 Vložení tabulky do cíle
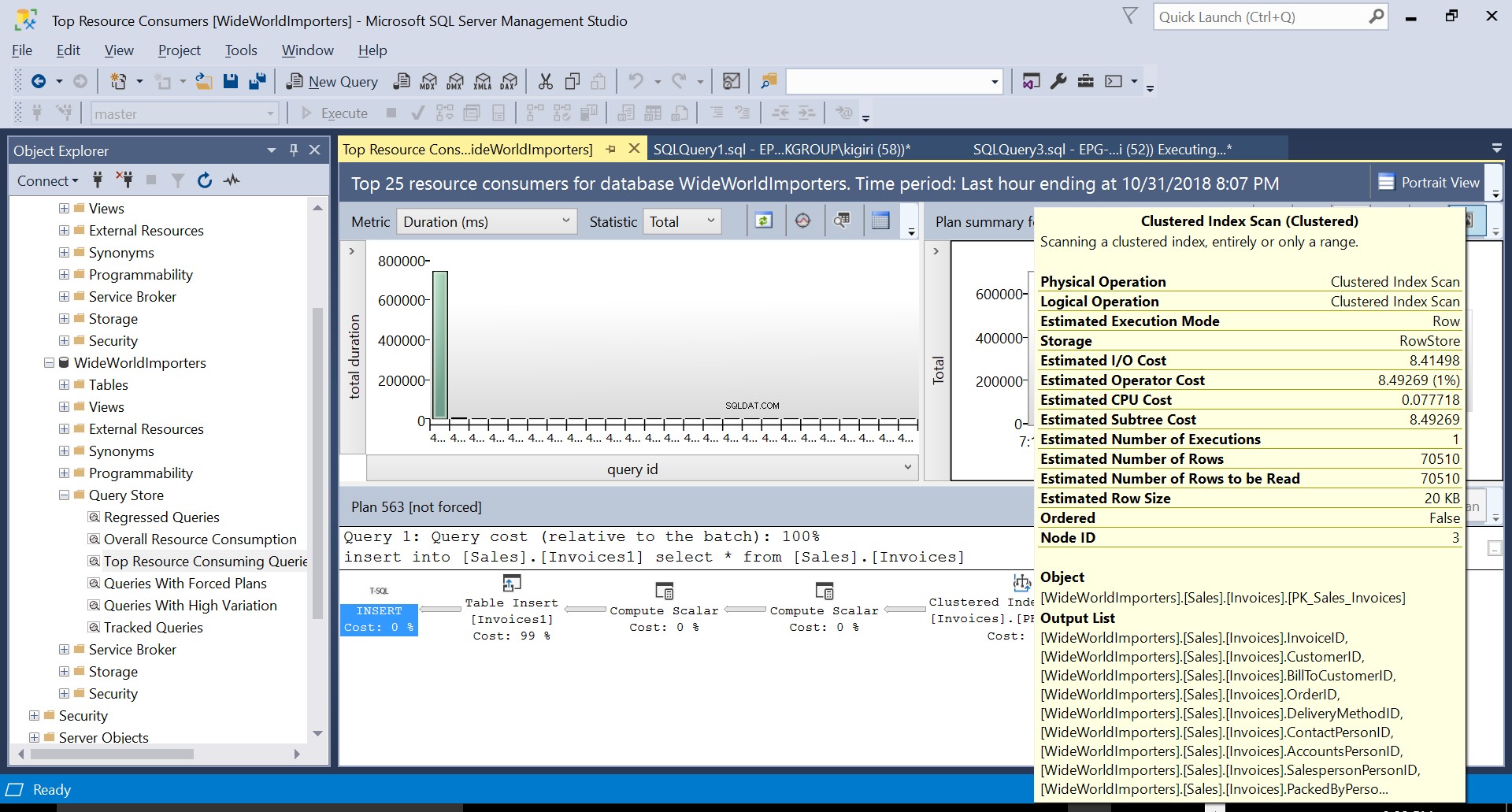
Obr. 3 Seskupené indexové skenování ve zdrojové tabulce
Vložit s indexem
Poté vytvoříme index na cílové tabulce pomocí DDL ve výpisu 3. Když zopakujeme příkaz ve výpisu 2 po zkrácení cílové tabulky, uvidíme mírně odlišný plán provádění (plán ID 593 zobrazený na obr. 4). Stále vidíme vložku tabulky, ale přispívá pouze 58 % k ceně dotazu. Dynamika provádění je trochu zkreslená zavedením řazení a vkládání indexu. V podstatě se děje to, že SQL Server musí zavádět odpovídající řádky do indexu, když jsou do tabulky zaváděny nové záznamy.
-- LISTING 3 Create Index on Destination Table CREATE NONCLUSTERED INDEX [IX_Sales_Invoices_ConfirmedDeliveryTime] ON [Sales].[Invoices1] ( [ConfirmedDeliveryTime] ASC ) INCLUDE ( [ConfirmedReceivedBy]) WITH (PAD_INDEX = OFF , STATISTICS_NORECOMPUTE = OFF , SORT_IN_TEMPDB = OFF , DROP_EXISTING = OFF , ONLINE = OFF , ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON) ON [USERDATA] GO
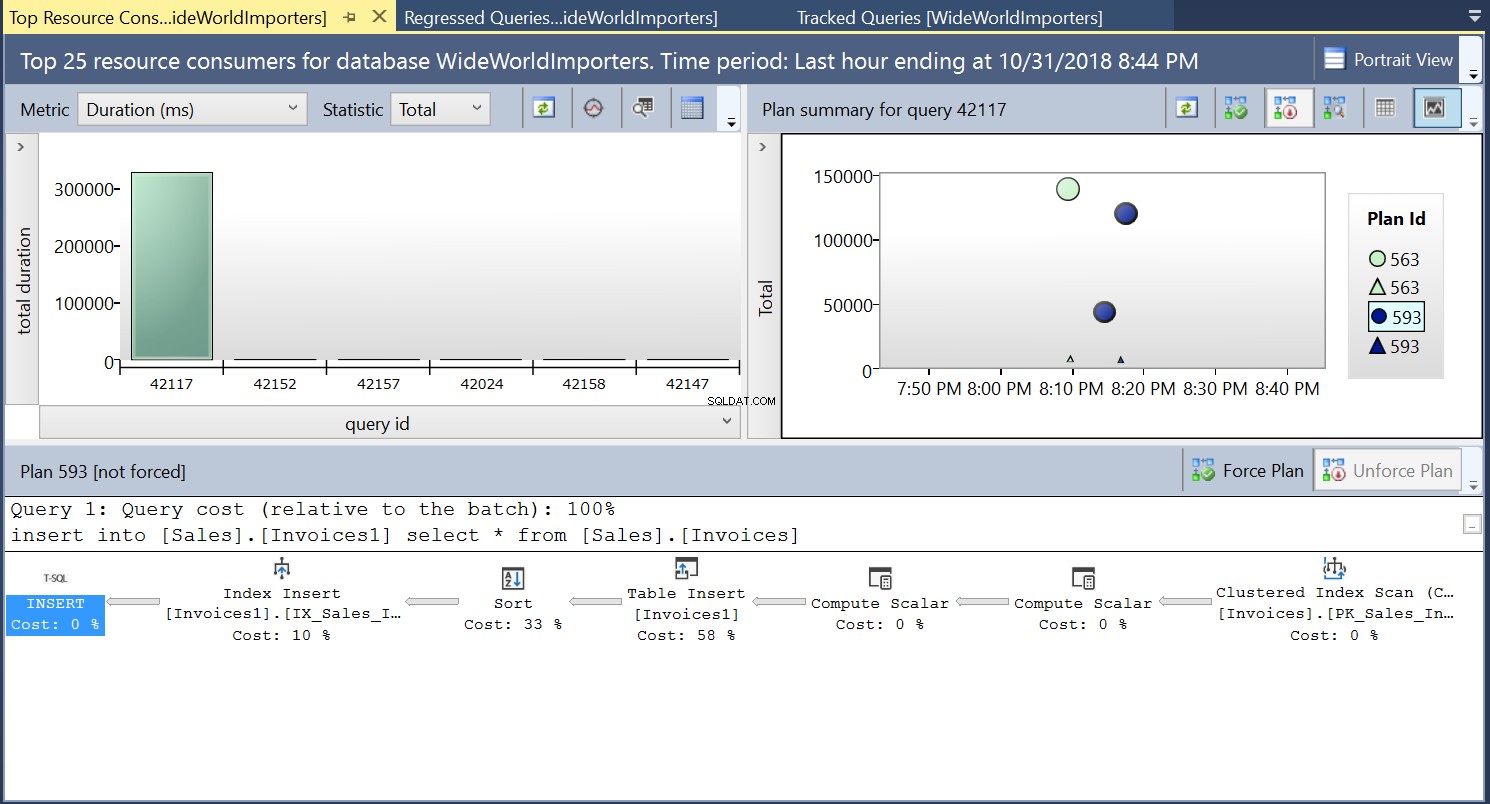
Obr. 4 Prováděcí plán 593
Pohled hlouběji
Můžeme prozkoumat podrobnosti obou plánů a zjistit, jak tyto nové faktory eskalují dobu provedení příkazu. Plán 593 přidává dalších 300 ms k průměrné době trvání výpisu. Při velkém pracovním vytížení v produkčním prostředí může být tento rozdíl významný.
Zapnutí STATISTICS IO při provádění příkazu insert jen jednou v obou případech – s indexem v cílové tabulce a bez indexu v cílové tabulce – také ukazuje, že při vkládání řádků do tabulky s indexy je třeba více práce z hlediska logického IO.
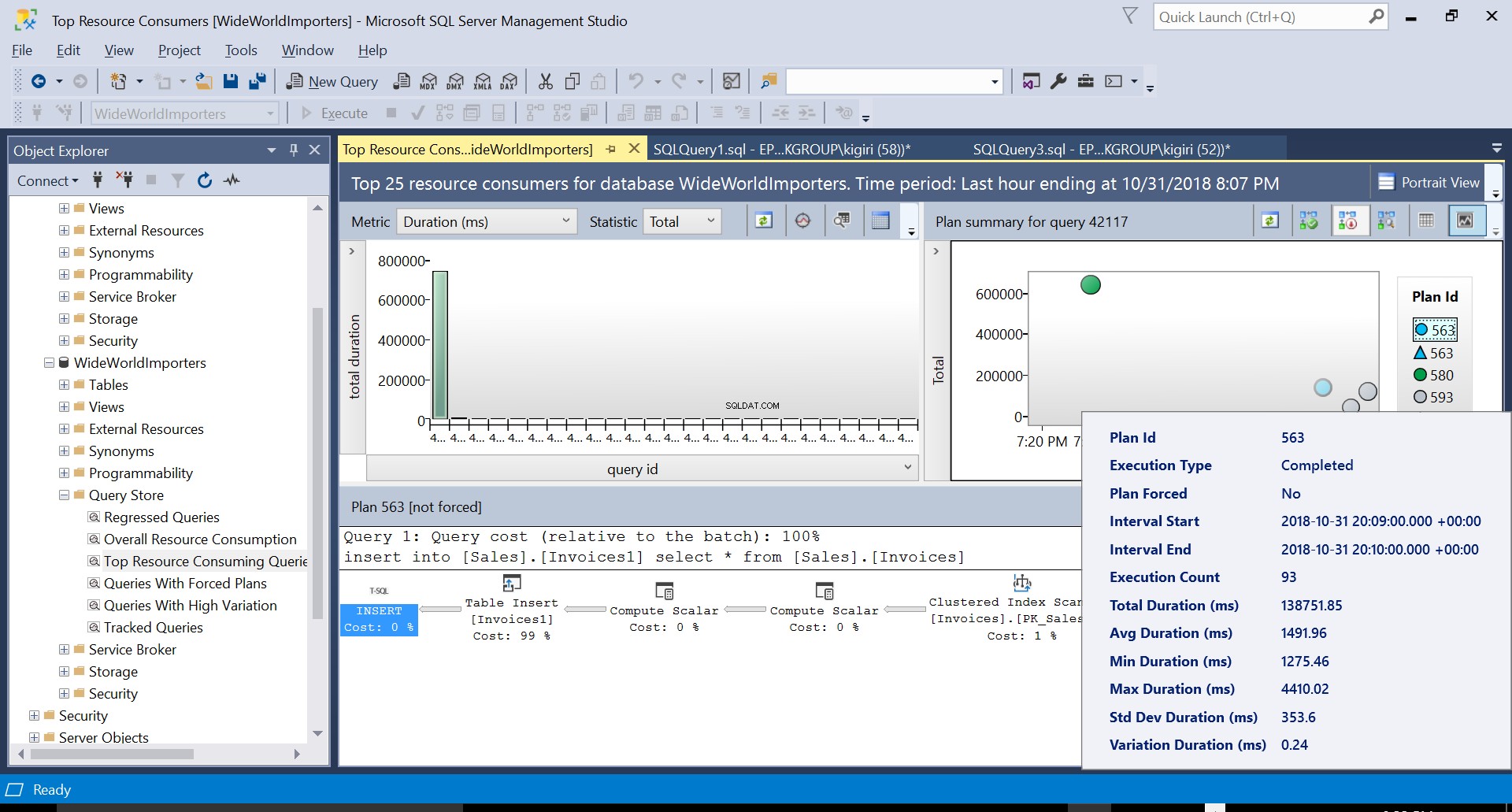
Obr. 5 Podrobnosti prováděcího plánu 563
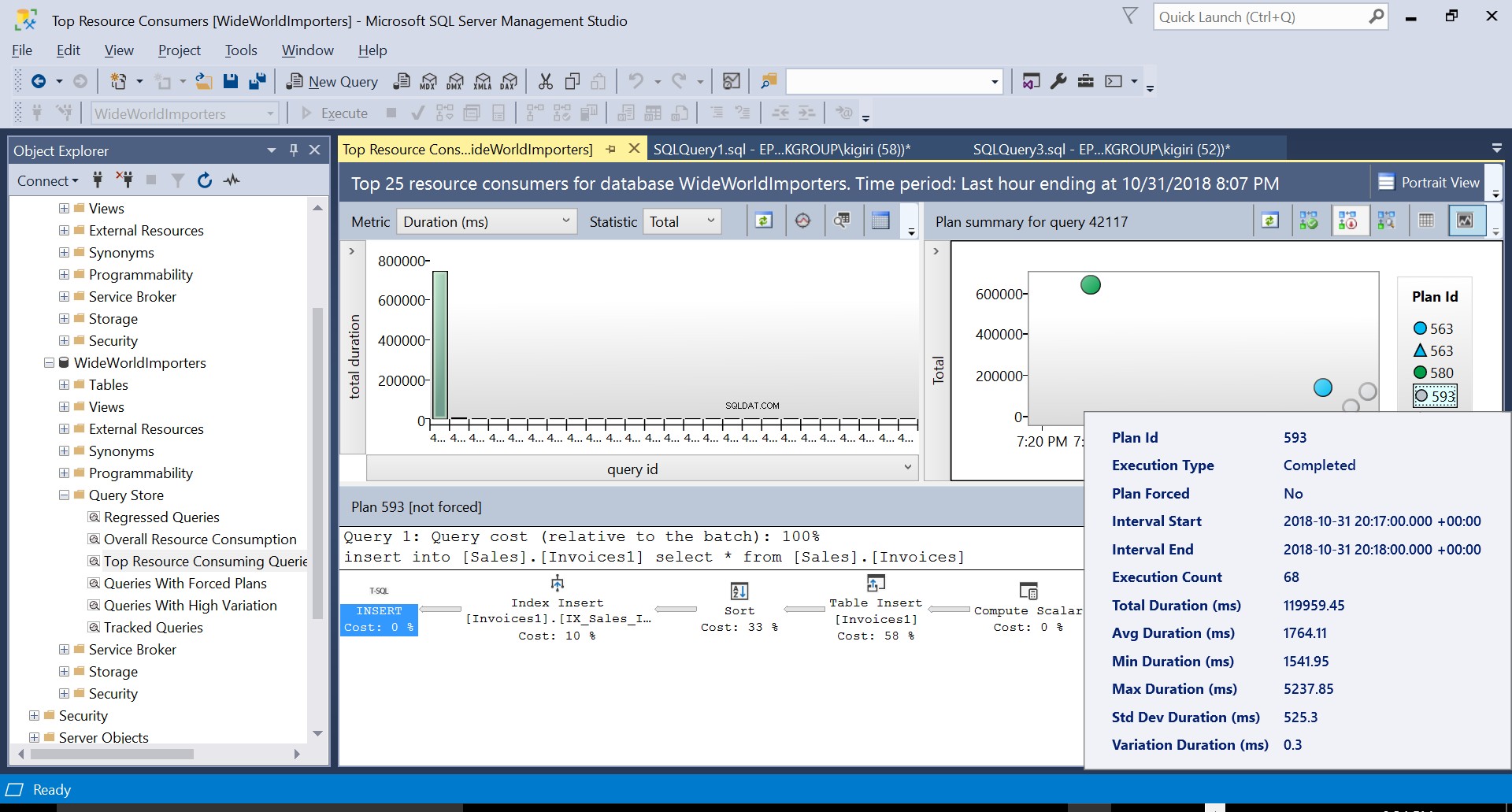
Obr. 4 Podrobnosti prováděcího plánu 593
Žádný index:Výstup se zapnutým STATISTICS IO:
Tabulka ‚Faktury1‘. Počet skenování 0, logická čtení 78372 , fyzické čtení 0, čtení napřed čte 0, logické čtení 0, fyzické čtení 0, lob čtení napřed čte 0.
Tabulka „Faktury“. Počet skenů 1, logická čtení 11400 fyzické čtení 0, předčítání čtení 0, logické čtení 0 lob, fyzické čtení 0, předčítání čtení 0.
(dotčených 70510 řádků)
Index:Výstup se zapnutým STATISTICS IO:
Tabulka ‚Faktury1‘. Počet skenů 0, logická čtení 81119 , fyzické čtení 0, čtení napřed čte 0, logické čtení 0, fyzické čtení 0, lob čtení napřed čte 0.
Tabulka ‚Pracovní stůl‘. Počet skenů 0, logické čtení 0, fyzické čtení 0, čtení napřed 0, logické čtení 0, fyzické čtení 0, lob čtení napřed 0.
Tabulka „Faktury“. Počet skenů 1, logická čtení 11400 , fyzické čtení 0, čtení napřed čte 0, logické čtení 0, fyzické čtení 0, lob čtení napřed čte 0.
(dotčených 70510 řádků)
Další informace
Společnost Microsoft a další zdroje poskytují skripty, které prozkoumají produkční prostředí indexů a identifikují takové situace, jako jsou:
- Nadbytečné indexy – Duplicitní indexy
- Chybějící indexy – Indexy, které by mohly zlepšit výkon na základě pracovní zátěže
- Hromady – Tabulky bez seskupených indexů
- Přeindexované tabulky – Tabulky s více indexy než sloupci
- Využití indexu – Počet hledání, skenování a vyhledávání v indexech
Položky 2, 3 a 5 souvisejí spíše s dopadem na výkon s ohledem na čtení, zatímco položky 1 a 4 souvisejí s dopadem na výkon s ohledem na zápisy. Výpisy 4 a 5 jsou dva příklady těchto veřejně dostupných dotazů.
-- LISTING 4 Check Redundant Indexes
;WITH INDEXCOLUMNS AS(
SELECT DISTINCT
SCHEMA_NAME (O.SCHEMA_ID) AS 'SCHEMANAME'
, OBJECT_NAME(O.OBJECT_ID) AS TABLENAME
,I.NAME AS INDEXNAME, O.OBJECT_ID,I.INDEX_ID,I.TYPE
,(SELECT CASE KEY_ORDINAL WHEN 0 THEN NULL ELSE '['+COL_NAME(K.OBJECT_ID,COLUMN_ID) +']' END AS [DATA()]
FROM SYS.INDEX_COLUMNS AS K WHERE K.OBJECT_ID = I.OBJECT_ID AND K.INDEX_ID = I.INDEX_ID
ORDER BY KEY_ORDINAL, COLUMN_ID FOR XML PATH('')) AS COLS
FROM SYS.INDEXES AS I INNER JOIN SYS.OBJECTS O ON I.OBJECT_ID =O.OBJECT_ID
INNER JOIN SYS.INDEX_COLUMNS IC ON IC.OBJECT_ID =I.OBJECT_ID AND IC.INDEX_ID =I.INDEX_ID
INNER JOIN SYS.COLUMNS C ON C.OBJECT_ID = IC.OBJECT_ID AND C.COLUMN_ID = IC.COLUMN_ID
WHERE I.OBJECT_ID IN (SELECT OBJECT_ID FROM SYS.OBJECTS WHERE TYPE ='U') AND I.INDEX_ID <>0 AND I.TYPE <>3 AND I.TYPE <>6
GROUP BY O.SCHEMA_ID,O.OBJECT_ID,I.OBJECT_ID,I.NAME,I.INDEX_ID,I.TYPE
)
SELECT
IC1.SCHEMANAME,IC1.TABLENAME,IC1.INDEXNAME,IC1.COLS AS INDEXCOLS,IC2.INDEXNAME AS REDUNDANTINDEXNAME, IC2.COLS AS REDUNDANTINDEXCOLS
FROM INDEXCOLUMNS IC1
JOIN INDEXCOLUMNS IC2 ON IC1.OBJECT_ID = IC2.OBJECT_ID
AND IC1.INDEX_ID <> IC2.INDEX_ID
AND IC1.COLS <> IC2.COLS
AND IC2.COLS LIKE REPLACE(IC1.COLS,'[','[[]') + ' %'
ORDER BY 1,2,3,5;
-- LISTING 5 Check Indexes Usage
SELECT O.NAME AS TABLE_NAME
, I.NAME AS INDEX_NAME
, S.USER_SEEKS
, S.USER_SCANS
, S.USER_LOOKUPS
, S.USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS S
INNER JOIN SYS.INDEXES I
ON I.INDEX_ID=S.INDEX_ID
AND S.OBJECT_ID = I.OBJECT_ID
INNER JOIN SYS.OBJECTS O
ON S.OBJECT_ID = O.OBJECT_ID
INNER JOIN SYS.SCHEMAS C
ON O.SCHEMA_ID = C.SCHEMA_ID;
Závěr
Pomocí úložiště dotazů jsme ukázali, že další pracovní zátěž s indexem může zavést do plánu provádění ukázkového příkazu insert. Při výrobě mohou mít nadměrné a nadbytečné indexy negativní dopad na výkon, zejména v databázích určených pro pracovní zátěže OLTP. Je důležité používat dostupné skripty a nástroje ke zkoumání indexů a určování, zda skutečně pomáhají nebo snižují výkon.
Užitečný nástroj:
dbForge Index Manager – praktický doplněk SSMS pro analýzu stavu indexů SQL a řešení problémů s fragmentací indexů.